
From a Web to a linear HTML document
Martin Gagnon
gagnon@vlsi.polymtl.ca
Michel Dagenais
dagenais@vlsi.polymtl.ca
Department of Electrical and Computer Engineering
Ecole Polytechnique of Montreal
PO Box 6079, Succ Centre-ville
Montreal, Quebec, Canada
H3C 3A7
Abstract
The lingua franca of the World Wide Web is the HyperText Markup
Language (HTML) which presents information as a Web of small
documents linked to each other. While this Web navigation is
convenient when searching for a specific information, it may be
cumbersome when all the information must be read anyway
(like traditional linear texts).
The proposed approach adds linearization hints to a Web of HTML
documents and provides tools to automatically generate a linear
version of a Web. Furthermore, a table of contents, an index and
a list of references are automatically produced for the linear
version.
Introduction
In the past few years, the number of Internet users and
the amount of information available have increased significantly.
The World Wide Web is probably the medium which has enjoyed the most
important growth. It can be defined as a set of protocols
(Hypertext Transfer Protocol) [1], formats
(Hypertext Markup Language, HTML) [2], software tools and conventions.
Hypertext documents are nodes of information linked together. This way,
each separate topic resides in a separate file and may be used
in different contexts. For instance, an HTML document on copying
garbage collection may be pointed to from documents on
algorithms, object oriented programming, or on the Modula-3 language.
Other document processing formats such as LaTeX [19]
may be divided into small sections which are merged into a linear
document with "input" commands. However, these systems have little
support for reusing a file in several documents. Indeed, the
pathnames must be relative to the document root, instead of to the
current file in HTML, and header level must be adequate for the context
of the including document. Other popular document formats such as
GNU info [] and Linux-doc sgml present similar problems.
Moreover, with the importance of the World Wide Web as the most up to
date source of information, and the wide availability of tools such as
Amaya [] for HTML authoring, it is preferable to use HTML as the source
format than to convert from another format (e.g. LaTeX) to HTML.
The flexibility allowed by HTML to split documents into small reusable
nodes is also a source of problems. Indeed, in many cases the information
should be available both as an online Web and as a linear printable
document. Examples include the Modula-3 language definition and
libraries, the Java language definition, libraries and tutorial,
and several documents from the World Wide Web consortium (W3C) and
the Linux documentation project.
Objectives
The objective of the proposed approach is to enter all the information in
HTML, possibly with some linearization hints. Then tools may be used
to point at a HTML Web node and recursively follow the appropriate
links in order to produce a linear HTML document. Converting to another format
(ASCII, LaTeX, Postscript) is a somewhat separate and simpler issue.

Figure 1: Structure of a Web site
A Web site may be represented as a network of nodes where each node
represents an HTML file (see Figure 1). However, A number of issues need
to be examined for producing a linear document from a Web of HTML nodes.
- Which hypertext links must be followed to prune the graph, and at least
break cycles.
- The header level (section, subsection...) must be adjusted based on the
selected root node (the "Graphics library" node may be a chapter or just a
section when the root node is "Modula-3 libraries" or "All of Modula-3").
- HTML tag names (ID) must be unique within a node. When several nodes are
merged into a linear document, IDs must be modified to insure
uniqueness.
- Links to named HTML tags within a node must be modified to account for
the modified IDs. Links to other nodes which are included in
the linearized document must be converted to internal links and IDs
created for each node merged.
- Document wide lists such as table of contents, table of figures,
index and bibliographic references must be constructed for the complete
linearized document.
These issues are discussed below.
Linearization Rules and Issues
An HTML document usually consists of:
<HTML>
<HEAD>
<TITLE> This is the title </TITLE>
</HEAD>
<BODY>
detailed text here
</BODY>
</HTML>
Where only the TITLE is mandatory. The BODY implicitly starts after the
TITLE, if no HEAD or BODY section is tagged.
The linearization of a Web starts at a node specified as root. From
there, hypertext links are followed in a depth first search, with the
following rules.
- Each node reached is assigned a unique identifier (derived from
its URL). A table of nodes visited (storing the node name (URL)
and identifier) is kept. A list of currently visited nodes,
along the path between the root and the currently visited node, is also kept.
- When a node already on the currently visited nodes list is reached,
a cycle exists which must be broken. The link is not followed.
When an already visited node is reached, it may or not be followed,
but at least a warning message should be issued.
- In HTML, sections (chapter, section, subsections...) are delineated
with <DIV> and </DIV>. DIV may be used for all sorts of
hierarchical
containers and must be characterized by their CLASS attribute. The
header level tags (<H1>) thus identify the section title, while the
depth could be inferred from the nesting level of <DIV> elements. In
practice, however, few documents specify <DIV> tags and most rely
solely on the header level. The convention proposed here is that the
effective depth of a header is the nesting depth of <DIV CLASS=SECTION>
elements plus the header level.
- The DIV elements may also be used to identify special portions of a
document (<DIV CLASS=ABSTRACT>...</DIV>
<DIV CLASS=APPENDIX>...</DIV>). If a DIV
element is both a hierarchical level within the sections and identifies
a special portion, the CLASS attribute may accommodate a list of values
(<DIV CLASS=SECTION,ABSTRACT>).
- Links with the attribute REL=INCLUDES are followed. The link is replaced
by a DIV with the node identifier as ID and the node body as content.
For example:
<A REL=INCLUDES HREF="subdir/toto.html"> The essence of foo </A>
is thus replaced by
<DIV ID="...subdir/foo.html">
body of foo.html
</DIV>
- Links with the attribute REL=SUBDOCUMENT are followed. The only difference
with the previous case is that the DIV has the CLASS=SECTION attribute.
- For both REL=SUBDOCUMENT and REL=INCLUDE, sometimes the included node
contains a title which is not appropriate in the context where it is
included. When the link is of CLASS=SKIPTITLE, the first H1 element within
the included node is removed (or replaced with an empty <DIV></DIV>).
When the link is of CLASS=REPLACETITLE, the text within the link
(<A ...> text within the link </A>) is used to replace the first H1 element
within the included node.
- When a node is included, all its IDs are replaced by the concatenation
of the node identifier and the old ID. This way, IDs should remain globally
unique, provided that node identifiers have a special format which would
not be used as ID within a node.
- Other links are not followed. However, if they reference an ID internal
to the node, the HREF is replaced by the concatenation of #, the node
identifier and the old ID with the leading # removed.
- Links to subdocuments are often placed in a list (<UL>). However,
when replacing the links by the nodes, the list should be
removed. Thus, a list which only contains links replaced by nodes
should be removed. A list which contains some but not only such links
may or not be removed but a warning should be issued. Similarly,
other elements may not be wanted in the printable document. They may
be identified by CLASS=SKIPLINEAR.
- As a convenience, it is possible to specify to the linearization
tool a set of mappings to affect the links. Each mapping contains an
HREF and REL pattern (as in the regex library) and an HREF and REL
replacement. This is mostly useful to prune the links to follow
(replacing the REL=SUBDOCUMENT by REL="" for instance) or to
redirect a reference to another document.
- Once the linearization is performed, a second pass is required to adjust
links which became internal. Every link to a node which appears in the
visited nodes table should have its HREF changed to the concatenation
of #, node identifier, and if applicable the ID within the node with the
leading # removed. This is demonstrated in the next two figures.
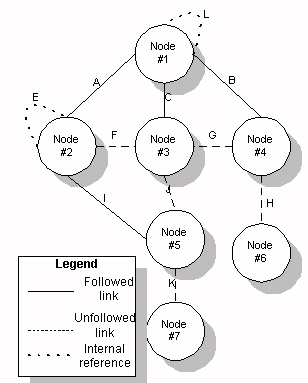
Figure 2: Nonlinear structure
Figure 2 presents the structure of the Web site before the linearization
and Figure 3 after the linearization.
When performing the linearization on the graph, links which
have the label REL=SUBDOCUMENT and REL=INCLUDES are followed. In the
example, this is the case for links a,b,c and i.
Links d,e,f,g,h,j,k and l don't have this label and are treated
as references.
Two types of references exist: internal references and external
references. Some references were already internal to a node. Other references
were external to a node but point to another node included in the linear
document and thus become internal. Finally, some external references remain
external after the linearization.
In the nonlinear structure, links f and
g are initially external references. However, since they point to
nodes 3 and 5 which have been included in the linear document,
they become internal references and their HREF attribute is updated
accordingly in the linear document.
However, links k and h, which were also external references, point to nodes
6 and 7 which are not included in the linear document. Therefore, they remain
unchanged as external references in the linear document.

Figure 3: Linear structure
- Sometimes extra information must be stored in nodes. It may be
indexing terms for an index, short descriptions to add to a
table of contents, or even a bibliographic entry for the document.
As of HTML 3.2, there is no container element which may store but
not display contained elements (e.g. <DIV CLASS=NODISPLAY>).
Therefore, such information may have to be "encoded" within attributes
of other elements, such as the ID of a SPOT element:
<SPOT CLASS=INDEX ID="xxx_key_text">
where "xxx" is the character string to use in the index,
"key" the sorting key, and "text" the text associated with this index entry.
This information may then be used to create an index for a Web site, or for
a linearized document.
Construction of Derived Nodes
Once the linearization is performed, it is useful to construct
derived nodes containing information about the linear document,
or about the web of visited nodes. In the first case, the address within the
linear document is used, while in the second case the original address
within the web is used.
A table of contents lists all the
headers. Nested lists are used to represent the sections hierarchy.
Each list entry is a link containing the section title, and pointing to the
relevant position in the linear document or the web of visited nodes.
Thus, each header should have an ID attribute.
Similarly, a list of figures or tables may be constructed; the FIGURE
element was recently dropped from the newer HTML 3.2 proposal however.
A reference list is another important but slightly more complex
derived node. It should contain a list of all
references external to the linear document.
However, these references are in URL form while most printed documents prefer
traditional bibliographic entries. In some cases the URL may point
to a bibliographic entry:
<DIV ID="Here" CLASS=BIBITEM>
Author,<I>book title</I>, O'Connell, 1995
</DIV>
In other cases, the URL may point to an ordinary document. However,
a bibliographic entry may be deduced:
<TITLE> book title </TITLE>
<H1> book title </H1>
<P>
<DIV CLASS=AUTHOR> Author </DIV>
<P>
<DIV CLASS=BIBITEM.TAIL> O'Connell, 1995 </DIV>
...
If there is no such information to be found, the entry would be simply the
URL.
Conversion to ASCII
To produce an ASCII document, the table of contents may be prepended to the
document, and the reference list and index appended.
The references in the table of contents should be replaced
by the page number of the corresponding section.
The entries in the reference list should have a tag assigned (order of
first occurrence, e.g. [1] [2], or a symbolic name used in anchors,
e.g. [Connolly1996]).
Then, external references in the document must
be replaced by the tag associated with the corresponding entry in the
reference list.
The internal references to figures, sections and tables should be
replaced by the figure/section/table number. There may be cases where
one wants the page number instead. This may be achieved
with the attribute CLASS=PAGEREF in <A HREF=...>.
Producing LaTeX documents
LaTeX can automatically generate the table of contents and the index, and
takes care of \label and \ref, or \pageref, for sections, tables and figures.
Thus, the conversion between HTML and LaTeX is more straightforward.
The major item where special care is required is the reference list.
It must be generated by the linearization tool. However, LaTeX is able to
connect each \cite to the corresponding \bibitem in the reference list.
Implementation
The rules defined earlier in this text, for the linearization of a web,
have been implemented in a HTML processing framework named htmlkit.
Unlike the algorithm of Sharples and Goodlet [3],
which relies solely on heuristics to guide the librarization through the
web, htmlkit uses heuristic rules and linearization hints annotations
(REL attribute in links).
The framework is implemented as a set of reusable Modula-3 [4] libraries.
The low level of coupling between the different modules in the
libraries makes it easy to interchange or upgrade components.
The libraries are decomposed as follows:
Libraries
- Low-Level
-
- HTTP, Gopher, FTP... communication
- HTML parsing
- File access
- Input/Output streams
- Low level data structures
- Text utilities
- Format matching
- Intermediate level
-
- Higher level data structures
- Operations on the data structures
- Link manipulation utilities
- High level
-
- Linearization tools
- ASCII filter
- Latex filter
- Index builder
- Table of contents builder
- Reference list builder.
With this organization, it is relatively easy to build custom tools
for performing various tasks for a Web site. For example one may want to
construct an index or a table of contents of the Web site,
without creating a linearization.
Results
The linearization tool implemented in htmlkit was tested on
a Sun Sparc 5 workstation with 32 Mo of RAM.
In each case, a web was linearized, an index, a table of contents and
a list of references were built, and the output was converted to
ASCII, LaTeX and Postscript.
Table 1 presents the elapsed time as a function of the number of nodes
linearized. The processing time grows linearly with the number of nodes
involved. In the current implementation, the modularity was favored
over the performance. In any case, in typical applications, the network
or disk access delay is likely to be the major limiting factor.
Nevertheless, a large document may be linearized in approximately
one minute.
Table 1: Linearization time versus number of nodes
Nbr. of
nodes | CPU time
(s)
| User delay
(s)
| Size
|
|---|
files
(Ko) | memory
(Ko)
|
| 34 | 28.31 | 31.84 | 34.687 | 2494
|
| 94 | 35.11 | 38.62 | 53.654 | 2536
|
| 125 | 40.81 | 45.84 | 90.132 | 2685
|
| 186 | 52.72 | 71.89 | 101.866 | 2699
|
| 217 | 56.75 | 76.33 | 107.630 | 2703
|
| 248 | 61.17 | 82.66 | 128.856 | 2709
|
| 306 | 71.03 | 110.84 | 166.397 | 2816
|
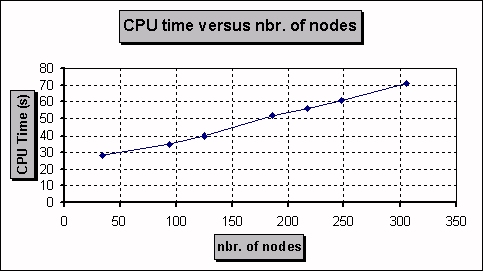
Figure 4: CPU time used versus nbr. of nodes in the network
Figure 5 presents the memory consumption as a function of the number of
nodes linearized. The memory usage grows less than linearly with
the number of nodes involved. The size of the VISITED NODES list and of the
REFERENCES list grows linearly with the number of nodes; the entries in
these lists are quite small though. The size of the memory devoted to
storing complete nodes is proportional to the number of currently visited
nodes, which is typically proportional to the logarithm of the number
of nodes (it represents the depth of the tree formed by the links where the
REL attribute is SUBDOCUMENT or INCLUDE). Again, the memory consumption
for a large document is not a problem, at below 3MB.

Figure 5: Memory used versus nbr. of nodes in the network
Figure 6 presents the memory consumption, for a constant linear document
size, as a function of the node size (which in this case is inversely
proportional to the number of nodes). The effect of enlarging the
granularity of nodes is to slightly reduce the tree depth, and thus
the number of currently visited nodes, but mostly
to enlarge the size of each of visited node. The size of the VISITED NODES
and REFERENCES lists shrinks with the smaller number of nodes but their
contribution to the total memory consumption is small.
The net result is an almost linear increase of the memory
consumption with the node size.
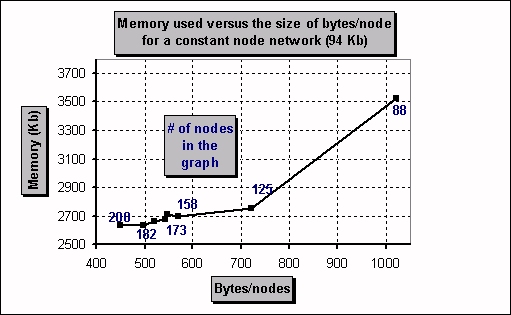
Figure 6: Memory used versus the size of bytes/nodes for a constant graph size (94Kb)
Conclusion
This paper presents a framework to linearize HTML documents. By adding a small
number of hints to web nodes, as attributes in HTML tags, it is possible
to derive automatically a high quality linear printable version from a web.
This way, authors of technical documents such as reference manuals can
benefit from using HTML (hypertext navigation, widely available
browsers and authoring tools, content oriented structure, multi-platform
support) while gaining the possibility of producing high quality books
starting from different possible root nodes in their web.
As this and similar approaches gain acceptance, the tags and attributes
used to annotate links, indexing terms, bibliographic references...
should get better standardized. Further work on the prototype will
be aimed at providing a more thorough customization layer in the conversion
between the linear HTML document and the printable LaTeX/Postscript output.
This may be achieved by allowing the redefinition of the LaTeX command
associated with each HTML construct. It may also be useful to allow
optional LaTeX layout parameters to be annotated in HTML attributes,
although this would overlap with the planned functionality for the style
sheets.
References
- [1] Berners-Lee, T., Hypertext Transfert Protocol,
Internet Draft CERN, 1993.
- [2] Berners-Lee, T., Connolly, D., Hypertext Markup Language,
Internet Draft CERN, 1993.
- [3] Sharples, Mike, Goodlet, James, "A comparison of algorithms for
hypertext notes network linearization", Int. J. Human-Computer
Studies, vol. 40, 1994, pp. 727-752.
- [4] Harbinson, S. Modula-3 Prentice Hall, 1992.
- [5] Nordin, B., Barnard, D.T., Macleod, I.A., "A
review of the Standard Generalized Markup Language (SGML)",
Computer Standards & Interfaces, 15, pp.5-19, 1993.
- [6] Goldforbs, Charles F., The SGML Handbook,
Oxford University Press, New York, 1990.
- [7] Bench-Capon, T.J.M., Dunne, R.J., Staniford, G,
"Linearising Hypertext through Target Graph Specification",
Database and Expert Applications, no.3, pp.173-178, 1992.
- [8] Bench-Capon, T.J.M., Dunne, R.J., Staniford, G,
"Linearisation Shemata for Hypertext",
Database and Expert Applications, pp.697-708, 1993.
- [9] Subbotin, M., ~ubbotin, D.,
"INTELTEXT: Producing Coherent Linear Texts While Navigating in Large
Non-Hierarchical Hypertexts", Proceeding of the 2nd East-West
Int. Conference on Human-Computer Interaction, pp.281-289, 1992.
- [10] Boyle, C., Encarnacion, A.O.,
"Metadoc: An Adaptive Hypertext Reading System", User Modeling
and User-Adapted Interaction, no.4, pp.1-19, 1994.
- [11] Conklin, J., Begeman, M. L.,
"gIBIS: a hypertext tool for exploratory policy discussion",
ACM Transactions on Office Information Systems, vol.6, pp.303-331,
1988.
- [12] Bernstein, M.,
"The bookmarks and the compass: Orientation tools for Hypertext users",
ACM SIGOIS Bulletin, vol.9, pp.34-45,
1988.
- [13] Schnase, J., Legget, J., Kacmar, C., Boyle, C.
"A comparison of hypertext systems",
TAMU Technical reports 88-017, Dept. of computer science, Texas A&M
University, College Station, 1988.
- [14] George, S.,
"Approach to linearising hypertext", Ph.D Dissertation,
Dept. of Comp. Sci., Univer. of Liverpool,
1992.
- [15] Parry, I.,
"A document modification system", M.Sc Dissertation
Dept. of Comp. Sci., Univer. of Liverpool,
1992.
- [16] Stotts, P.D., Furuta, R.,
"Adding browsing semantics to the hypertext model",
Proc. ACM Conference on Documents Processing Systems, pp.43-50,
1988.
- [17] Subbotin, M.M.,
"Hypertext systems with algorithmic navigation",
Proc. of the Int. Colloquium New Information Technology, Moscow,
USSR, October 8-10,
1991.
- [18] Concklin, J.J.,
"Hypertext - An introduction and survey,"
Computer, September, pp.17-41,
1987.
- [19] Lamport, L., A Document Preparation System Latex,
user's guide and reference manual, Addison-Wesley, 1994.
- [20] Knuth, D.E., The TexBook, Addison-Wesley, 1994.
Return to Top of Page
Return to Posters Index