

Journal reference: Computer Networks and ISDN Systems, Volume 28, issues 7–11, p. 893.
Evangelos P. Markatos
Computer Architecture and VLSI Systems Group
Institute of Computer Science (ICS)
Foundation for Research & Technology -- Hellas (FORTH)
P.O.Box 1385
Heraklio, Crete, GR-711-10 GREECE
tel: +30 81 391 655, fax: +30 81 391 661
markatos@csi.forth.gr
We also show that traditional file system cache management methods are inappropriate for managing Main Memory Web caches, and may result in poor performance. Based on trace-driven simulations of several server traces we quantify our claims, and propose a new cache management that dynamically adjusts itself to the clients' request pattern and cache size. We show that our policy is robust over a variety of parameters and results is better overall performance.
Keywords: WWW caching, file caching, prefetching
Results suggest that World Wide Web (hereafter called Web) servers receive an everincreasing amount of requests for documents. Some servers receive up to 25 requests per second at peak times [6]. As more users start using the Web, the number of requests each server is going to see is bound to increase. To be able to respond at these request rates, a Web server should avoid all unnecessary overheads. One of the sources of Web server overhead is related to disk accesses. When a client requests a document from a Web server, the server performs one or more file system calls to open, read, and close the requested file. Depending on the file system cache policy of the server, these system calls may result in one or more disk accesses. To make matters worse, if the document does not reside in a disk local to the server, it has to be fetched through a network file system (e.g. NFS) which makes the server overhead of getting the document even higher.
File system caches may reduce the number of disk accesses by caching the most popular file blocks in the server's main memory. Unfortunately, as we show in this paper, traditional methods for caching like those used in file systems do not perform well for Web traffic for the following reasons:
In this paper we propose and explore Main Memory Caching of frequently requested Web documents on the Web server's memory. That is, if a document is frequently accessed, then it is kept in the Main Memory Cache, inside the Web server's address space. The server accesses its own cache directly, without any help from the file system. When a client requests a document that resides in the server's main memory cache, the document is directly read from the server's cache and sent to the client without making any file system calls to access the document. We believe that main memory caching of Web documents is beneficial today, and will be even more attractive in the near future for the following reasons:
Our work complements traditional Web Caching research. Web Caching systems attempt to reduce a server's load by caching documents close to the clients that request them. Our Main Memory Web Caching system reduces a server's load by keeping the most frequently accessed documents in the server's main memory, thus avoiding disk accesses as much as possible.
To evaluate the performance benefits of main memory Web caching we use trace-driven simulations. We have gathered server traces from several Web servers from a variety of environments that include Universities, Research Institutions, and Supercomputing Centers both from Europe and the States. All traces total more than one million requests. Specifically the traces are from:
We believe that it is very important to use traces from a variety of sources. Since different traces have different characteristics and because the server they are gathered from, provides different documents to its clients. For example, some sophisticated servers that contain lots of images, movies and sounds contain mostly large files. On the other hand, servers connected with slower lines to the outside world provide mostly (highly interconnected) short text files. Our experimental results suggest that the average size of the requested documents plays a significant role in the performance of caching policies and in the choice of the best caching policy.
These traces were fed into a trace-driven simulator that simulates a main memory cache of a given size. The server caches documents according to the following policies:
The ultimate goal of each Web server is to be able to serve client requests at the maximum rate. This rate becomes higher when most of the requested documents are found in the Main Memory Cache. Thus, the Cache Hit Rate is a fundamental factor in the server's performance.
There are two variations of the cache hit rate:
The Document Hit Rate seems to be the most important performance metric, since the higher it is the more client requests will see a low latency. On the other hand, when the Document Hit Rate does not vary significantly, the Byte Hit Rate should be given serious consideration because it represents the number of bytes serviced from the cache, and thus do not have to be read from the disk.
The document requests as a function of their size are shown in figures 1 to 5. The x-axis represents the size of the document, while the y-axis represents the number of references to documents of a given size. For example, figure 1 suggests that more than 100000 accesses request documents of size 1 KByte or less. The traces suggest that small documents (a few Kbytes long) tend to be accessed much more frequently than larger documents. This preference to small-sized documents holds for all different traces studied, and has been observed by other researchers as well [2].
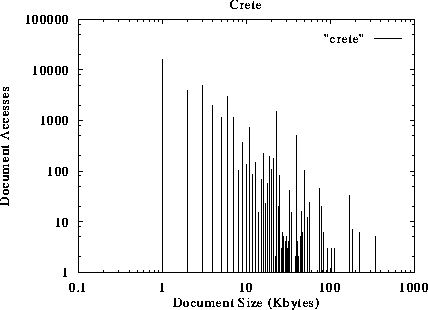
Figure 1: Number of Accesses to documents as a function of their size.
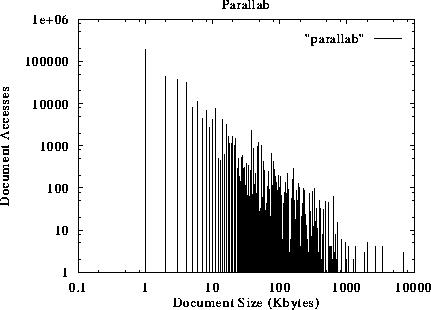
Figure 2: Number of Accesses to documents as a function of their size.
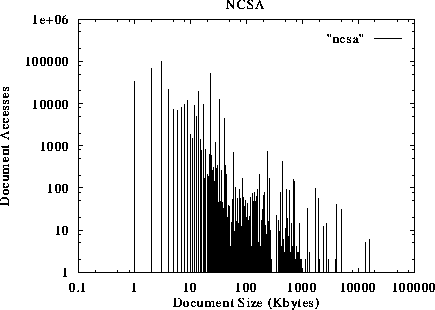
Figure 3: Number of Accesses to documents as a function of their size.
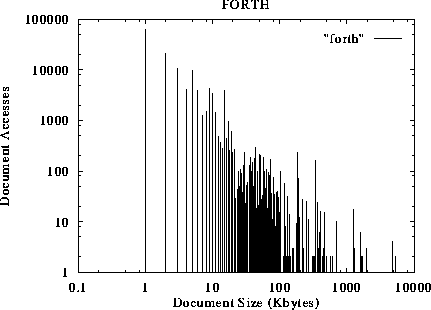
Figure 4: Number of Accesses to documents as a function of their size.
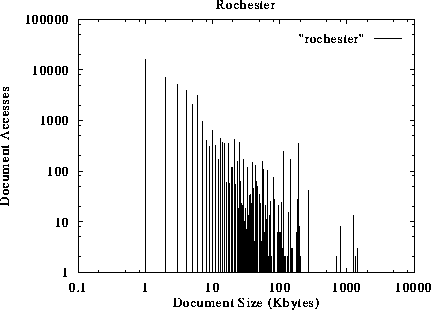
Figure 5: Number of Accesses to documents as a function of their size.
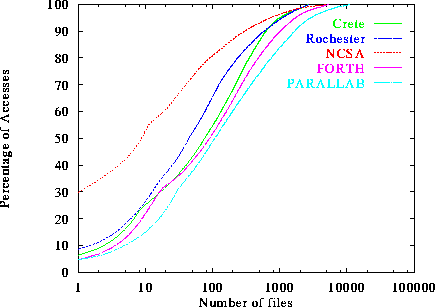
Figure 6: Number of documents responsible for a given percentage of
Web references.
To illustrate the preference to small documents even further, we plotted the cumulative document requests for the various servers as a function of the number of files responsible for this request. Figure 6 shows this cumulative document request for each server studied. We see that for all traces, a small number of files are responsible for a significance percentage of the Web requests. For example as little as 10 files are responsible for 50% of the accesses in the NCSA trace. Similar observations hold (to a lesser extent) for the other traces as well. As little as 100 files are responsible for 35-50% of the traffic in other traces. This trend is particularly encouraging for our work, since it implies that caching a small number of files is enough to service a significant percentage of the requests.
In this first set of experiments we want to explore the effect that the cache size has on the performance of caching policies. We are interested in answering the following questions:
Figure 7 plots the Document Hit Rate as a function of the cache size, for the ALL policy that caches all documents and replaces them from the cache on an LRU basis. Our results suggest that the size of the cache needed to achieve a given hit rate depends on the Web server. We see that a cache as small as 4 MBytes results in 80% hit rate for the NCSA server, but only in 63% hit rate for the Parallab server. Even more, to achieve a 90% document hit rate, 16 Mbytes of cache are enough for almost all servers except the Parallab, which needs 64 Mbytes to achieve the same levels of performance.
We can see the reason why in figure 6 where it can be easily seen that NCSA has very good locality of reference, while Parallab has poor locality. For example, figure 6 shows that the ten most frequently accessed files in NCSA are responsible for almost 50% of the accesses, while the ten most frequently accessed files in Parallab are responsible for about 10% of the accesses. Thus, we expect that in order to achieve similar hit rates with NCSA, the Parallab server needs to cache more files, which will (probably) require a larger cache.
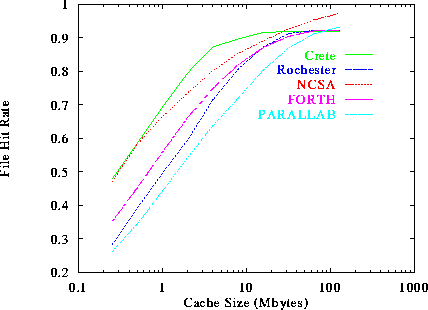
Figure 7: Document Hit Rate as a function of the Cache Size
We reach similar conclusions by looking at figure 8, which displays the byte hit rate as a function of the cache size. We should note, however, that for the same cache size and the same server, the Document Hit Rate is higher than the Byte Hit Rate. The reason is simple: in order to achieve really high byte hit rates, large documents should be cached, which require really large caches. Caching large documents in small caches will evict from the cache lots of more frequently used small documents and will probably be brought back into the cache soon after they are evicted.
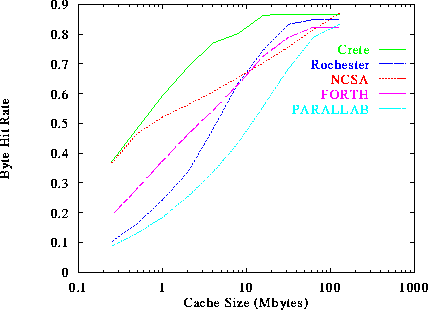
Figure 8: Byte Hit Rate as a function of the Cache Size
One remedy to the problems introduced by caching large documents is not to cache large documents at all. Thus, if a document is larger than a threshold value, the document is not cached. Although it may sound simple, it is really a complicated trade-off to decide which documents are large and should not be cached. If the threshold is chosen too small, then the cache may be underutilized. If the threshold is chosen too large, then the documents may end up thrashing for the same cache space, and no document will stay in the cache long enough to achieve a decent hit rate. To understand the performance implications of this threshold, we simulated the THRESHOLD caching policy that caches documents whose size is less than or equal to the threshold value. The performance of caching in the various Web servers as a function of the caching threshold is shown in figures 9, 10, and 11 for cache sizes of 0.5 Mbytes, 2 Mbytes and 8 Mbytes respectively.
The first thing we observe is that the performance increases with the threshold value up to a maximum and then it starts to decrease, which is in accordance with our intuition: increasing a small threshold makes better use of the cache by bringing in more documents, and thus improves performance. But if the threshold is increased beyond a certain point, too many documents will compete for the same cache space, and they will end up pushing each other out of the cache. Effectively, few documents will manage to stay in the cache long enough to achieve a decent hit rate. By looking closely at figure 9, we see that the optimal threshold and the achievable performance for each Web server is different. For example, the optimal threshold for NCSA is 32 Kbytes, while the optimal threshold for Parallab is 4 Kbytes. This is because NCSA tends to serve larger documents than Parallab. The average size of the requested documents from Parallab is 7.5 KBytes, while the average size from the requested documents from NCSA is 17 KBytes. By comparing figure 9 with figures 10, and 11 we see that the achievable performance and the optimal threshold increases with the available cache size. For example, If we increase the cache size from 512 KBytes to 8 MBytes, the optimal threshold for NCSA moves from 32 KBytes to 128 Kbytes, and for Parallab moves from 4 Kbytes to 32 Kbytes.
Our results suggest that the optimal threshold depends both on the documents requested, and on the cache size. Choosing a threshold that will result in good performance is a delicate procedure. Naively chosen values of the threshold may result is poor performance. For example, figure 9 suggests that in the Rochester trace, the optimal threshold results in 62% Document Hit Rate, while the policy that uses no threshold at all results in only 36% Document Hit Rate. It seems that for any threshold we choose there is a server and a cache size that perform very poorly for this threshold.
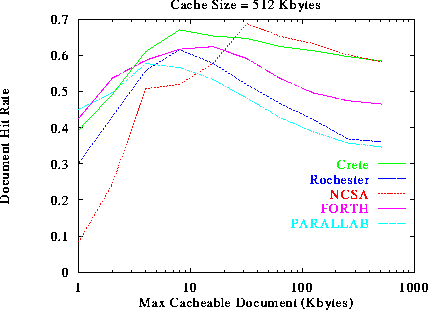
Figure 9: Document Hit Rate as a function of the maximum size of
cacheable documents
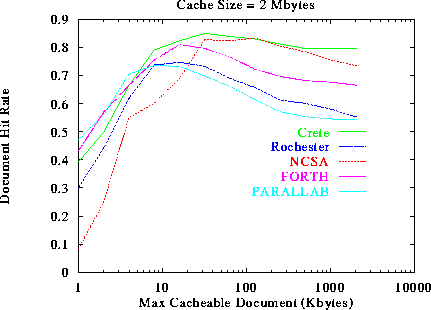
Figure 10: Document Hit Rate as a function of the maximum size of
cacheable documents
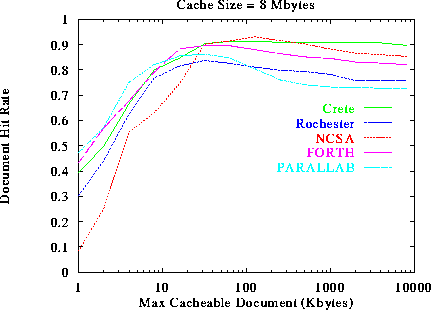
Figure 11: Document Hit Rate as a function of the maximum size of
cacheable documents
To eliminate the need for off-line careful threshold tuning, and to provide responsiveness to varying access patterns, we have developed an ADAPTIVE caching policy that estimates the best threshold at run-time without user intervention. The intuition behind the policy is simple:
In our implementation we used an initial value of 16 Kbytes (which is a reasonable start), and an increment (decrement) of 2 Kbytes. We updated the threshold value every 5000 references. The metric we use to estimate performance improvements is the Document Hit Rate. To make the policy stable, we reverse the direction of changing the threshold from increasing to decreasing (and vice versa) only if the decrease in performance is larger than 1%. We felt that performance decreases lower than 1% are usually due to statistical noise and are not worth changing the direction of the threshold calculation.
The performance of the ADAPTIVE policy is shown in figures 12 and 13 for cache sizes of 512 KBytes and 8 MBytes respectively. We compare the ADAPTIVE policy with the following policies:
We see that in all cases the ADAPTIVE policy is close to the BEST because it manages to approximate the best threshold value based on run-time performance measurements. The performance when NO-THRESHOLD is used is always inferior to the ADAPTIVE policy, sometimes substantially so (see Parallab in figure 12). The difference between ADAPTIVE and NO-THRESHOLD is much more pronounced when the cache size is small (512 KBytes).
To our surprise we saw that in one case, ADAPTIVE was even better then the BEST policy (see Rochester in figure 13). This is because in one part of the traces a small threshold was appropriate, while for another part of the traces a larger threshold was appropriate. Thus no static threshold was able to deliver the best possible performance; a dynamically changing threshold was needed. The ADAPTIVE policy provided exactly the dynamic threshold that was needed for this case. Thus, ADAPTIVE not only adapts to the available cache size and average document requested, but also adapts to a dynamically changing access pattern and is able to choose (almost) the optimal threshold value needed for each case.

Figure 12: Performance of the adaptive policy.
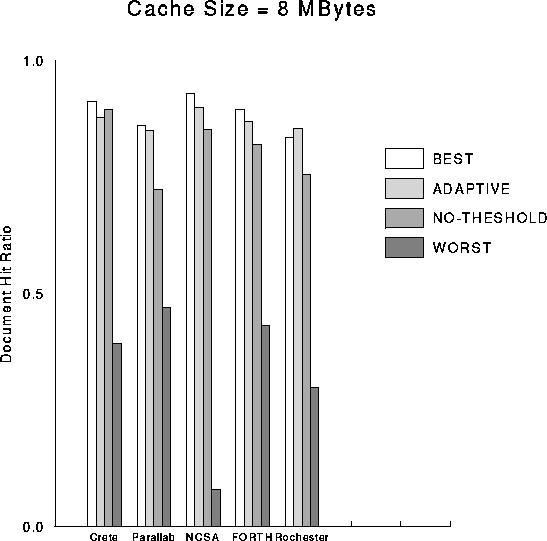
Figure 13: Performance of the adaptive policy.
Several groups have started exploring caching issues on the Web. Some of the well known caches include the Harvest hierarchical Cache [4], the Lagoon system [3], the push-caching approach at Harvard [5], the caching work at Boston University [1,2], the Hensa Archive [8], etc. All these approaches deal with caching of remote documents on a disk that is close to the clients that request the document. Several of them are based on proxy servers that service a community of users ranging from one building to a whole country. When one user asks for a document, the proxy caches it, so that next accesses to the same document by nearby users will receive the cached copy.
Our research however, is complementary to previous caching approaches, and deals with a different form of caching: caching of local documents in a Web server's main memory, so that they can be sent faster to clients that request them.
Our approach is in several ways similar to file system caching [7].o However, Main Memory Caching of Web Documents differs from file system caching mainly because Web access patterns are different from file access patterns: Web clients access entire Web documents, in read-only mode, (usually) only once . On the other hand, file systems access portions of files, usually in read-rite mode, repeatedly .
For the above reasons we believe that caching policies used in file systems should not be used ``per se'' in Main Memory Web caches as well. Our performance results strengthen our point even more.
Recent Web servers receive an ever-increasing amount of Web requests that reach peaks of up to one request every few tens of milliseconds. To be able to serve requests at these rates, a Web server should avoid all unnecessary overheads. In this paper we explore the notion of Main Memory Caching of Web Documents. We propose that each Web server should reserve a (small) amount of its main memory and use it to cache frequently requested Web documents. We show that an amount of main memory as small as 512 Kbytes is enough to hold the most frequently accessed documents of Web servers, resulting in hit rates between 55% and 70%. To make the best use of this limited main memory cache, we propose a caching policy that prefers caching of small documents. The caching policy dynamically adjusts itself to the incoming requests and the available cache size so that it always achieves (almost) optimal hit rates. To quantify the performance of our policy, we used trace-driven simulation of a variety of Web traces. Based on our performance results we conclude:
 Evangelos P. Markatos
is an Assistant professor at ICS-FORTH and
at the University of Crete, Greece. He received his diploma in
Computer Engineering from the University of Patras in 1988, and
the MS and Ph.D. degrees from the University of Rochester, NY
USA, in 1990 and 1993 respectively. His interests include
parallel and distributed systems, operating systems and computer
architecture.
Evangelos P. Markatos
is an Assistant professor at ICS-FORTH and
at the University of Crete, Greece. He received his diploma in
Computer Engineering from the University of Patras in 1988, and
the MS and Ph.D. degrees from the University of Rochester, NY
USA, in 1990 and 1993 respectively. His interests include
parallel and distributed systems, operating systems and computer
architecture.