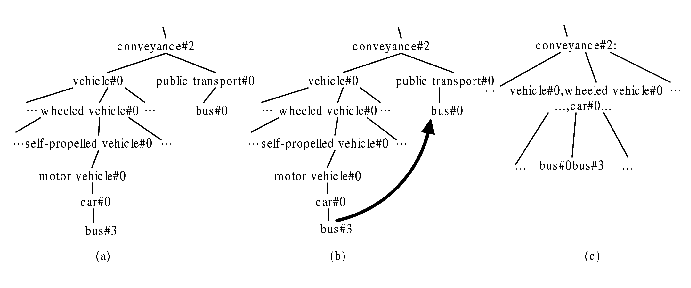
Figure1. Structure of WordNet and Process of Union
Semantic similarity plays important roles in a wide range of applications, e.g. information retrievals and clustering. Existing work [3] on semantic similarity mainly focuses on the semantic similarity between two words, while the semantic similarity between two articles has attracted much less attention. At first glance, it seems to be trivial to extend the semantic similarity between words to the semantic similarity between articles. However, we found that a straightforward extension, e.g. [1], did not work well in our project on context-based video retrieval, where the videos are typically accompanied by text descriptions such as google video. To achieve better performance, we propose a new method of computing semantic similarity between two articles based on WordNet [2], which is a concept ontology having a tree structure as shown in Figure 1(a) (See Section 2). We further improve our method by constructing a Compact Concept Ontology from WordNet by merging the nodes with similar sematic meanings (See Section 3).
Figure1. Structure of WordNet and Process of Union
A straightforward method is given in [1] to combine the semantic similarity
between two words to compute the semantic similarity between two
articles. Given two articles ![]() and
and ![]() , their semantic similarity is computed as
follows in [1]:
, their semantic similarity is computed as
follows in [1]:
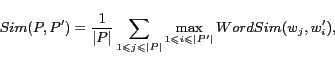
The algorithm in [1] treats each word pair independently, and thus cannot capture the semantic of the article as a whole. For example, a word may have multiple senses and the context will help to identify the real sense in an article. Therefore, we propose a new ontology-based algorithm to calculate the similarity between articles globally. It first builds a weighted tree for each article based on WordNet, and then computes the semantic similarity between two articles using their weighted trees.
Given an article ![]() , we build its weighted tree
, we build its weighted tree ![]() as follows. For
every word
as follows. For
every word ![]() in
in ![]() , we find the corresponding node in WordNet for
each sense of
, we find the corresponding node in WordNet for
each sense of ![]() to get a set
to get a set
![]() of nodes, where
of nodes, where ![]() is the number of
senses of
is the number of
senses of ![]() . Each node
. Each node ![]() in
in ![]() and the corresponding path from
and the corresponding path from
![]() to
the root of WordNet tree will be added to
to
the root of WordNet tree will be added to ![]() (if the path is not
in
(if the path is not
in ![]() ); for
each node from
); for
each node from ![]() to the root, we increase its weight by one. In
this way, we will get the complete weighted tree
to the root, we increase its weight by one. In
this way, we will get the complete weighted tree ![]() for
for ![]() after we process all
words in
after we process all
words in ![]() . The weight tree
. The weight tree ![]() represents the
semantic characteristics of the whole article
represents the
semantic characteristics of the whole article ![]() . The similarity of two
articles can be calculated by comparing the similarity of their
weighted trees. The similarity between two weighted trees
. The similarity of two
articles can be calculated by comparing the similarity of their
weighted trees. The similarity between two weighted trees
![]() and
and
![]() is
defined as follows:
is
defined as follows:
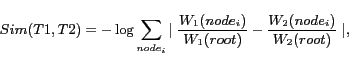
The above similarity definition is a natural extension of the
similarity in [3] that computes
the similarity between two words using WordNet. Compared with the
method in [1], we compute
similarity as a whole. In addition, our method is more efficient.
Suppose the depth of ontology tree and number of tree nodes are
constant. The time complexity of the algorithm in [1] is ![]() , where
, where ![]() and
and ![]() are the number of
words in two articles; The time complexity of our algorithm is
are the number of
words in two articles; The time complexity of our algorithm is
![]() ,
either for calculating the similarity or building the weighted
tree.
,
either for calculating the similarity or building the weighted
tree.
The performance of our algorithm is highly dependent on the
underlying concept ontology from which we generate a weighted
tree for each article. Although the algorithm presented in Sec.
2 adopts WordNet as the concept ontology, we
find that WordNet does not fit very well with our algorithm. For
instance, for two different words, their corresponding nodes in
the tree structure are probably not the same even if they have
similar semantic meaning. Consider three words, e.g. ![]() ,
, ![]() and
and ![]() ,
, ![]() and
and ![]() are semantically
very similar with each other while
are semantically
very similar with each other while ![]() is not relevant to
them. In WordNet, the three words will be matched to three
different nodes and thus the semantic relationship among them
will be ignored in our algorithm. If words
is not relevant to
them. In WordNet, the three words will be matched to three
different nodes and thus the semantic relationship among them
will be ignored in our algorithm. If words ![]() and
and ![]() can be matched to
the same node in the ontology tree, the performance of our
algorithm can be improved. To cope with the closely similar
words, we build a more compact concept ontology from WordNet by
combining nodes that are semantically similar. The Compact
Concept Ontology(CCO) has the following properties:
can be matched to
the same node in the ontology tree, the performance of our
algorithm can be improved. To cope with the closely similar
words, we build a more compact concept ontology from WordNet by
combining nodes that are semantically similar. The Compact
Concept Ontology(CCO) has the following properties:
We next present the WordNet Union Algorithm to build CCO from
WordNet by combining semantically similar nodes. More
specifically, we find semantically similar node pairs
(![]() ,
,
![]() ) and
then the nearest common ancestor node
) and
then the nearest common ancestor node ![]() in WordNet. Then, we
combine all the nodes on the paths between
in WordNet. Then, we
combine all the nodes on the paths between ![]() and
and ![]() ,
,![]() to form a new node
to form a new node
![]() , which
is child node of
, which
is child node of ![]() , and also combine
, and also combine ![]() and
and ![]() to form a new node,
which is the child node of node
to form a new node,
which is the child node of node ![]() . Figure 1(b) and (c)
shows an example. In Figure 1(b), nodes bus#0 and bus#3 are
semantically similar nodes and the nodes between them and their
common ancestor will be combined into one node in Figure 1(c) and
nodes bus#0 and bus#3 are also combined into one node.
. Figure 1(b) and (c)
shows an example. In Figure 1(b), nodes bus#0 and bus#3 are
semantically similar nodes and the nodes between them and their
common ancestor will be combined into one node in Figure 1(c) and
nodes bus#0 and bus#3 are also combined into one node.
The open problem is to find the semantically similar node
pairs (![]() ,
, ![]() ). They need to satisfy the following two
conditions: 1) they represents two senses of the same word, and
2) they are highly semantically similar i.e.
). They need to satisfy the following two
conditions: 1) they represents two senses of the same word, and
2) they are highly semantically similar i.e.
![]() , where
, where ![]() is computed
using the WUP method in [1]. To
determine a reasonable threshold, we choose 300 words and find
their synonyms, and then compute the similarity with their
synonyms using WUP. The average of the similarity will be used as
threshold. The generated CCO contains 2561 nodes, and each of
them presents a concept which is semantically different from
others. Note that, we can generate different CCOs by setting
different thresholds.
is computed
using the WUP method in [1]. To
determine a reasonable threshold, we choose 300 words and find
their synonyms, and then compute the similarity with their
synonyms using WUP. The average of the similarity will be used as
threshold. The generated CCO contains 2561 nodes, and each of
them presents a concept which is semantically different from
others. Note that, we can generate different CCOs by setting
different thresholds.
To evaluate the algorithm and the usefulness of CCO, we
download 100 articles from Google Video and each article
represents the content description of a video. For each article
![]() , we
randomly select 4 articles
, we
randomly select 4 articles ![]() ,
, ![]() ,
, ![]() ,
, ![]() from the left 99 articles. An annotator
is asked to label the 4 articles as relevant or non-relevant to
from the left 99 articles. An annotator
is asked to label the 4 articles as relevant or non-relevant to ![]() . We then compare
our method of computing semantic similarity with the method of
computing semantic similarity in [1] and cosine similarity without
considering similarity. For each
. We then compare
our method of computing semantic similarity with the method of
computing semantic similarity in [1] and cosine similarity without
considering similarity. For each ![]() , we compute its
similarity with the other 4 articles
, we compute its
similarity with the other 4 articles ![]() ,...
,... ![]() respectively and
rank them in terms of similarity. If the similarity of the top 1
is larger than a threshold, the article is relevant to
respectively and
rank them in terms of similarity. If the similarity of the top 1
is larger than a threshold, the article is relevant to ![]() ; otherwise non-relevant. If it is consistent with the human
annotation, it is correct; otherwise, it is wrong.
; otherwise non-relevant. If it is consistent with the human
annotation, it is correct; otherwise, it is wrong.
| CCO | WordNet | [1] | Cosine | |
| Accuracy | 73.6% | 68.18% | 49.09% | 40% |
The results are given in Table 1. The results for all methods are obtained through 10-fold cross validation (to determine the threshold of relevant and non-relevant). The results show that our method outperforms the method of computing semantic similarity in [1]. Moreover, the CCO performs better than WordNet in our algorithm. In addition, the use of CCO can decrease the execution time by 2 times than WordNet, as CCO contains much fewer tree nodes than WordNet and the depth of the tree is much smaller. Our algorithm is almost 28 times faster than the algorithm in [1] when using CCO as ontology.
Our future work includes evaluating on larger datasets, and applying the semantic similarity for context-based video retrieval.