 |
5
Xiaoying Wu
NJIT, USA
Stefanos Souldatos
xw43@njit.edu
Theodore Dalamagas
NTUA, Greece
Timos Sellis
stef@dblab.ece.ntua.gr
Finding the occurrences of structural patterns in XML data is a key operation in XML query processing. Existing algorithms for this operation focus almost exclusively on path-patterns or tree-patterns. Requirements in flexible querying of XML data have motivated recently the introduction of query languages that allow a partial specification of path-patterns in a query. In this paper, we focus on the efficient evaluation of partial path queries, a generalization of path pattern queries. Our approach explicitly deals with repeated labels (that is, multiple occurrences of the same label in a query).
We show that partial path queries can be represented as rooted dags for which a topological ordering of the nodes exists. We present three algorithms for the efficient evaluation of these queries under the indexed streaming evaluation model. The first one exploits a structural summary of data to generate a set of path-patterns that together are equivalent to a partial path query. To evaluate these path-patterns, we extend PathStack so that it can work on path-patterns with repeated labels. The second one extracts a spanning tree from the query dag, uses a stack-based algorithm to find the matches of the root-to-leaf paths in the tree, and merge-joins the matches to compute the answer. Finally, the third one exploits multiple pointers of stack entries and a topological ordering of the query dag to apply a stack-based holistic technique. An analysis of the algorithms and extensive experimental evaluation shows that the holistic algorithm outperforms the other ones.
Categories and Subject Descriptors: H.2.4 [Database Management]: Systems-
query processing, textual databases
General Terms: Algorithms.
Keywords: XPath query evaluation, XML
Since XML gained wide acceptance as the standard for representing web data, it became increasingly important to have a language that provides flexible query capabilities for extracting patterns from XML documents. Traditionally, a structured query language, such as XPath [1] and XQuery [2], is used to specify path-patterns or tree-patterns against XML data. A distinguishing characteristic of these patterns is that they require a total order for the elements in every path of the pattern. Recent applications of XML require querying data where the structure is not fully known to the user, or integrating XML data sources with different structures [11,15,19,27]. In order to deal with these problems, query languages are adopted that relax the structure of a path in a tree pattern. Popular solutions are keyword-based languages for XML [11,15] or structured query languages for XML extended with keyword search capabilities [4,19]. However, the first solution has important limitations: (1) structural restrictions cannot be specified in keyword-based queries, and (2) keyword-based queries return many meaningless answers [29,20]. The drawback of the second solution is that it cannot avoid having a syntax which is complex for the simple user [15,11,23]. In any case, in order for all these languages to be useful in practice, they have to be complemented with efficient evaluation techniques.
In this paper we consider a query language that allows a partial specification of path patterns. The queries of this language are not restricted by a total order for the nodes in the path pattern. This language is flexible enough to allow on the one side keyword-style queries with no path structure, and on the other side fully specified path pattern queries. The language is general enough since in the general case, queries can be represented only as graphs and not mere trees. It is important to know that partial path queries can not be expressed by path-patterns or tree-patterns. Leaving apart the query answer form question, these queries can be expressed in XPath with reverse axes (such as parent axis and ancestor axis).
Partial path queries constitute an important subclass of XPath queries, where previous evaluation algorithms for tree-pattern
queries cannot be applied. Note that Olteanu et al. [24,23] showed that XPath queries with reverse axes can be equivalently rewritten as sets of tree-pattern queries. However, this transformation may lead to a number of tree-pattern queries which is exponential on the query size. Clearly, it is inefficient to evaluate a partial path query by evaluating an exponential number of tree-pattern queries.
Finding all the occurrences of structural patterns in an XML tree is a key operation in XML query processing. A recent approach for evaluating queries on XML data assumes that the data is preprocessed and the position of every node in the XML tree is encoded [32,3,5,18]. Further, the nodes are partitioned, and an index of inverted lists called streams is built on this partition. In order to evaluate a query, the nodes of the relevant streams are read in the pre-order of their appearance in the XML tree. Every node in a stream can be read only once. We refer to this evaluation model as indexed streaming model. Agorithms in this model [32,3,5,9,17,18,21,31,6,7] are based on stacks that allow encoding an exponential number of pattern matches in polynomial space. However, these existing algorithms focus almost exclusively on path-patterns or tree-patterns, therefore they cannot be used directly for partial path queries.
The problem. We address the problem of evaluating partial path queries that may contain repeated labels. This problem is complex because the queries in the general case can be directed acyclic graphs (dags). A straightforward approach for dealing with this problem would be to produce for a given partial path query Q
, a set of path queries that together compute Q
. Such an attempt faces two obstacles: (a) as mentioned above the number of path queries may be exponential on the number of query nodes, and
(b) the best known algorithm for evaluating path queries under the indexed streaming model (PathStack [5]) does not account for repeated labels in a path query. To the best of our knowledge, there are no previous algorithms for this class of queries in the indexed streaming model.
Contribution. The main contributions of this
paper are the following:
In this paper, we focus on the indexed streaming model for the evaluation of queries. Next, we provide an overview on the relevant evaluation techniques on XML data.
Previous papers focused on finding matches of binary structural relationships (a.k.a. structural joins). In [32], the authors presented the Multi-Predicate Merge Join algorithm (MPMGJN) for finding such matches. Al-Khalifa et al. [3] introduced a family of stack-based join algorithms. These algorithms are more efficient compared to MPMGJN, as they do not scan the XML data multiple times. Algorithms for structural join order optimization were introduced in [30]. Structural join techniques can be further improved using various types of indexes [9,17,31].
The techniques above can be exploited to evaluate a path-pattern or a tree-pattern query. This task involves the
following phases: (a) decomposing the query into binary structural relationships,
(b) finding their matches, and (c)
stitching together these matches. This approach is inefficient because it generates a large number of intermediate solutions (that is, solutions do not make it to the answer). To deal with this problem, [5] presented two stack-based join algorithms (PathStack and TwigStack) for the evaluation of path-pattern queries and tree-pattern queries without multiple occurrences of the same node label in the same query path. PathStack is shown optimal for path-pattern queries, while TwigStack is shown optimal for tree-pattern queries without child relationships. Further, [10] shows that without relaxing the indexed streaming model, it is not possible to develop optimal algorithms for the evaluation of tree-pattern queries.
Several papers focused on extending TwigStack. For example, in [21], algorithm TwigStackList evaluates efficiently tree-pattern queries in the presence of child relationships. Chen et al. [6] proposed algorithms that handle queries over graph-structured data. Evaluation methods of tree-pattern queries with OR predicates are developed in [16]. In [18], the XR-tree index [17] is used to avoid processing input that does not participate in the answer of the query.
Recently, algorithm Twig2Stack [7] is suggested to evaluate tree-pattern queries on XML data without decomposing a query into root-to-leaf path patterns, and it can handle queries with repeated labels. Nevertheless, Twig2Stack requires multiple visits to stream nodes, thus, it does not comply with the index streaming model requirements.
Considerable work has been done on the processing of XPath queries when the XML data is not encoded and indexed. For example, [13] suggested polynomial main memory algorithms for answering full XPath queries. Under the XML streaming model, evaluation algorithms for different fragments of XPath, which essentially represent tree-pattern queries, are presented among others in [25,8,14].
Partial tree-pattern queries were initially introduced in [27]. Their containment problem was addressed in [28] and semantic issues were studied in [29]. These papers did not focus on the evaluation of these queries. Evaluation algorithms are provided in [26] but for a restricted class of partial path queries that do not allow multiple occurrences of nodes with the same label. In this paper, we show how to efficiently evaluate partial path queries with repeated labels under the index streaming model.
In this section, we briefly present the XML data model and the partial path query language.
A partial path query specifies a path pattern where the structure (an order among the nodes) may not be fully defined.
Syntax.
In order to define these queries, paths or even trees are not sufficient, and we need to employ directed graphs.
In the rest of the paper, unless stated differently, ``query'' refers to ``partial path query''. Query nodes denote XML tree nodes but we use capital letters for their labels. Therefore, a query node labeled by A denotes XML tree nodes labeled by a . In order to distinguish between distinct query nodes with the same label, we use subscripts. For instance, A3 and A4 denote two distinct nodes labeled by A . If Q is a query, and X and Y are nodes in Q , the expressions X/Y and X//Y are called structural relationships and denote respectively a child and descendant edge from X to Y in Q .
Figure 3 shows four queries. Child (resp. descendant) edges are shown with single (resp. double) arrows. Query Q1
is a partial path query which is also a path query since the
structural relationships in the query induce a total order for the query nodes. Notice that a query graph can be disconnected, e.g. query Q4
in Figure 3(d). Notice also that no order may be defined between two nodes in a query, e.g. between nodes A
and C
in Q3
, or between nodes A1
and A2
in Q4
.
Semantics. The answer of a partial path query on an XML tree is a set of tuples. Each
tuple consists of tree nodes that lie on the same path and preserve the child and descendant relationships of the query. More formally:
An embedding of a partial path query Q
into an XML tree T
is a mapping M
from the nodes of Q
to
nodes of T
such that: (a) a node in Q
labeled by A
is mapped by M
to a node of T
labeled by a
; (b) the nodes of Q
are mapped by M
to nodes that lie on the same path in
T
; (c)
![]() X/Y
(resp. X//Y
) in Q
, M(Y)
is a child (resp. descendant) of M(X)
in T
.
X/Y
(resp. X//Y
) in Q
, M(Y)
is a child (resp. descendant) of M(X)
in T
.
We call image of Q under an embedding M , denoted M(Q) , a tuple that comprises all the images of the nodes of Q under M . Such a tuple is also called solution of Q on T . The answer of Q on T is the set of solutions of Q under all possible embeddings of Q to T .
Consider query Q2 of Figure 3. Notice that Q2 is syntactically similar to a tree-pattern query (twig). However, the semantics of partial path queries is different: when query Q2 is a partial path query, the images of the query nodes R , A1 and C1 should lie on the same path on the XML tree.
Clearly, we can add a descendant edge from node R to every node that does not have incoming edges in a query without altering its meaning. Therefore, without loss of generality, we assume that a query is a connected directed graph rooted at R . Figure 4 shows the queries of Figure 3 in that form.
Obviously, if a query has a cycle, it is unsatisfiable (that is, it does not have a non-empty answer on any database). Detecting the existence of cycle in a directed graph can be done in linear time on the size of the graph. In the following, we assume that a query is a dag rooted at node R .
Given an XML tree T , an index tree I for T is an 1-index 1 [22] without pointers to the XML data (i.e., without extents). Because I has no extents, its size is usually insignicant compared to the data size. Fig. 2(b) shows the index tree for the XML tree of Fig. 2(a).
Given a query Q and an index tree I , we can generate a set P of path queries that is equivalent to Q by finding all the embeddings of Q into I . For example, Fig. 5 shows all the possible mappings of the query Q3 of Fig. 4(c) on the index tree of Fig. 2(b) (there are two of them) and the corresponding path queries. There is a one to one correspondence between the nodes of a path query and the nodes of Q .
The proof is straightforward. Any of the two algorithms presented later in this paper can be used to find the embeddings of a query to an index tree. However, even a naive approach would be satisfactory given the size of an index tree.
![\begin{figure}\center
\scalebox{1}{ \subfigure[embedding 1]{\epsfig{file=figure...
...mbedding 2]{\epsfig{file=figures/mapping2.eps} } }
\vspace*{-2ex}
\end{figure}](fp910-wu-img10.gif) |
In practice, the number of the path queries for the query Q is expected to be small. However, in extreme cases, it can be exponential on the number of nodes in Q . Nevertheless, any one of the path queries represents a pattern that appears in T . Therefore, it will return a non-empty answer when evaluated on T .
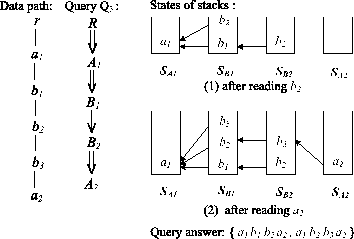
Algorithm PathStack [5] optimally computes answers for path pattern queries under the indexed streaming model (cf. Section 1). However, the class of queries considered is restricted in that nodes in a query are assumed to have unique labels. The PathStack algorithm associates every query node with one stack and one stream of tree nodes. For a path query with repeated labels, extending PathStack with multiple streams for each query label (one for each query node with this label) would violate the indexed streaming model requirements, since one stream node might be visited multiple times during the evaluation. Therefore, we designed Algorithm PathStack-R, which extends PathStack by allowing nodes with the same label to share the same stream.
Notation. Let Q
be a path query, q
be a node in Q
, and l
be a label in Q
. Function nodes(Q
) returns all nodes of Q
; label(q
) returns the label of q
in Q
. Boolean function isLeaf(q
) returns true iff q
is a leaf node in Q
. Function parent(q
) returns the parent of q
in Q
; occur(l
) returns all nodes in Q
labeled by l
; label(Q
) returns the set of node labels in Q
.
With every distinct node label l in Q , we associate a stream Tl of all nodes (positional representation) labeled by l in the XML tree. The nodes in the stream are ordered by the their begin field (cf. Section 3.1). To access sequentially the nodes in Tl , we maintain a cursor Cl , initially pointing to the first node in Tl . For simplicity, Cl may alternatively refer to the node pointed by cursor Cl in Tl . Operation advance(Cl ) moves Cl to the next node in Tl . Function eos(Cl ) returns true if Cl has reached the end of Tl . Cl .begin denotes the begin field in the positional representation of node Cl .
We associate a stack Sq with every query node q in Q . A stack entry in Sq consists of a pair: (positional representation of node from Tlabel(q) , pointer to an entry in the stack of q 's parent). The expression Sq.k denotes the entry at position k of stack Sq . We use the following stack operations: push($Sq$,$entry$) pushes entry on Sq ; pop(Sq ) pops the top entry from Sq ; and top(Sq ) returns the position of the top entry of Sq .
PathStack-R. Algorithm PathStack-R is presented in Algorithm 1. PathStack-R gradually constructs matchings to Q
and compactly encodes them in stacks, by iterating through stream nodes in ascending order of the begin values. Thus, the query nodes are matched from the query root to the query leaf.
In line 2, PathStack-R identifies the stream node to be processed. Line 3 calls cleanStacks to remove partial matchings that cannot become final solutions.
Line 5 (moveStreamToStack) is an important step, which is also the key difference from PathStack. It determines whether the identified stream node Cl qualifies for being pushed on stack Sq , where q is a query node labeled is L . The stream node Cl can be pushed on stack Sq iff (1) q is the root, or (2) q is not the root and the structural relationship between Cl and the top stack entry of q 's parent p satisfies the structural relationship between p and q in the query. This ensures that stream nodes that do not contribute to answers will not be stored in the stacks and processed. Since Q can contain repeated labels, it is possible that l matches more than one node in Q and thus Cl can be pushed to more than one stack. Note that the order of pushing Cl to stacks is important. As discussed, in order to determine if Cl can be pushed on a stack, the parent stack will be checked. In order to prevent Cl from `seeing' its own copy in the parent stack, moveStreamToStack should be called on the matched nodes in their descending order in Q (line 4). We illustrate this by an example below.
Whenever an incoming stream node Cl is pushed onto the stack of the leaf node, procedure showSolutions iteratively produces solutions encoded in stacks (line 6-8). The details are omitted here and can be found in [5].
Analysis of IndexPaths-R. Given a node q
in a path query Q
, we call the path from the root of Q
to q
the prefix
path of q
. Given a stream node x
of an XML tree T
, we say that x
matches q
iff x
is the image of q
under an embedding of the prefix path of q
to T
.
As a result of Proposition 4.2, Algorithm PathStack-R will find and encode in stacks all the partial or complete (q
is a leaf node in Q
) solutions involving x
. When at least one complete solution is encoded in the stacks, procedure
showSolutions
is invoked to output them. Therefore, Algorithm PathStack-R correcly finds all the solutions to Q
.
Given a path query Q and an XML tree T , let input denote the sum of sizes of the input streams, output denote the size of the answers of Q on T , height denote the height of T , and maxOccur denote the maximum number of occurrences of a query label in Q .
The time complexity of PathStack-R depends mainly on the number of calls to moveStreamToStack, and the time to produce answers. For each stream node, procedure moveStreamToStack is invoked at most maxOccur times, and each invocation takes O(1). As Algorithm PathStack-R does not generate any intermediate solutions, the time it spends on producing all the answers is proportional to output . Therefore, PathStack-R has time complexity O(input x maxOccur + output) .
The space complexity of PathStack-R depends mainly on the number of stack entries at any given point in time. Since the worst-case size of any stack in PathStack-R is bounded by min(height , input ), PathStack-R has space complexity O(min(height, input) x | Q|) .
The time complexity of IndexPaths-R is the product of the time complexity of PathStack-R and the number of path queries in P
.
Given a partial path query Q , Algorithm PartialMJ-R extracts a spanning tree of Q . Then, it finds matches for all root-to-leaf paths of the spanning tree against the XML tree by using Algorithm PathStack-R.
The solutions for each path of the spanning tree are merge-joined by guaranteeing that (a) they lie on the same path in the XML tree, and (b) they satisfy the structural relationships that appear in the query graph and not in the spanning tree.
Fig. 7(b) shows the graph of a query Q6 , and Fig. 7(c) shows a spanning tree Qs of Q6 . Edge B5//A6 of Q6 is missing from Qs . Any two solutions from the two root-to-leaf paths of Qs that are on the same path of the XML tree can be merged to produce a solution for Q6 , if they satisfy the identity conditions on R and A1 and the structural condition B5//A6 .
PartialMJ-R is shown in Algorithm 2. Compared to PathStack-R, PartialMJ-R has two additional important steps: (1) Line 1 produces a spanning tree for the given partial path query and records the set of structural relationships presented in the query but are missing in the spanning tree; and (2) whenever a set of solutions for a root-to-leaf path in the spanning tree is produced, they are merge-joined with solutions produced earlier using Procedure joinPathSolutions (line 9). When Q is a path, Algorithm PartialMJ-R reduces to PathStack-R.
Compared to the approach IndexPath-R, Algorithm PartialMJ-R also evaluates the query by populating query stacks in one single pass of input streams. Nevertheless, this approach may generate many intermediate solutions that are not part of any final answer. A solution is called intermediate, if either it cannot be merged with any other solutions on a same data path or it does not satisfy structural conditions in Q that are not present in Qs .
Considering evaluating the query Q6 of Fig. 7(b) on the data of Fig. 7(a), four partial solutions are produced: { ra1c2b3a4 , ra1d5b6 , ra4d5b6 , ra1c2b3a7 } in order of their construction. Among them, the first and fourth are solutions for the path RA1C2B4A6 and the rest are solutions for the path RA1D3B5 . The third solution cannot be merged with the first and fourth solutions, since the identity condition on R and A1 is not satisfied. The first cannot be merged with the second, since the structural relationship between b6 and a4 does not satisfy B5//A6 . Therefore ra1c2b3a4 and ra4d5b6 are intermediate solutions. The answer of Q6 is {ra1c2d5b3b6a7} .
Clearly, the intermediate solutions affect negatively on the worst case time and space complexity for PartialMJ-R.
A partial path query Q can be represented as a dag rooted at R . Let q be a node and l be a label in Q . Since now we are dealing with graphs, we replace the functions isLeaf(q ) and parent(q ) of Section 4.1.2 with the functions isSink(q ) and parents(q ) respectively. An additional function children(q ) returns the set of child nodes of q in Q . The rest of the functions are similar to those defined for Algorithm PathStack-R.
As with PathStack-R, we associate every distinct node label l with a stream Tl and maintain a cursor Cl for that stream. Unlike PathStack-R, we now associate a stack Sl with every distinct node label l . The structures of a stack entry are now more complex in order to record additional information.
Before describing the data structures used by stack entries, we define an important concept, which is key to the understanding of the PartialPathStack-R algorithm.
For every role that a stream node can play, we maintain a chain of pointers and record in the chain the nodes that play this role.
Let
p1,..., pk
be the parent nodes of all nodes labeled by l
in Q
. Note that it is possible that for some or all of these pi
s, label(pi
) = l
. An entry e
in stack Sl
has the following three fields:
(1) nl
: the positional representation of a node from Tl
.
(2) ptrs
: a set of k
pointers labeled by
p1,...pk
. Each pointer denotes a position in a stack. A pointer labeled by pi
points to an entry in stack
Slabel(pi)
. It is possible that a pointer is null. It is also possible that an entry has multiple pointers to the same stack. In this case, these pointers are labeled by different query nodes.
(3) prevPos
: an array of size
| occur(l )|
. Given a node
q ![]() occur(l )
,
prevPos[q]
records the position of the highest entry in Sl
below e
that plays the role of q
(i.e.,
prevPos[q]
points to the previous entry in the chain). If q
is the only node labeled with l
,
prevPos[q]
refers to the entry just below e
.
occur(l )
,
prevPos[q]
records the position of the highest entry in Sl
below e
that plays the role of q
(i.e.,
prevPos[q]
points to the previous entry in the chain). If q
is the only node labeled with l
,
prevPos[q]
refers to the entry just below e
.
The bottom of each stack has position 1. The expression Sl.k denotes the entry at position k of stack Sl . The expression Sl.k.pi refers to the position of the entry in stack Slabel(pi) pointed to by the pointer labeled pi in the entry Sl.k .
With every stack Sl , we associate an array lastPosl of size | occur(l )| . The field lastPosl[q] records the position of the highest stack entry in Sl that plays the role of node q (the beginning of the chain). If q is the only node labeled with l , lastPosl[q] refers to the top entry in stack Sl .
Algorithm PartialPathStack-R calls in line 5 procedure getRoles(l). For a stream node Cl under consideration, getRoles(l) finds all the roles that Cl can play and records the information in an object which is finally returned to the algorithm. More specifically, for each query node q in occur(l ) , Cl plays the role of q iff for each q 's parent p , there exists an entry e in the stack Slabel(p) such that the structural relationship between e and Cl satisfies the structural relationship between p and q in the query (line 8-17). Note that we can efficiently find the entry e through the value of lastPos label(p) [p ] (line 10) without exhaustively visting the stack entries. If Cl plays the role of q , a set of labeled pointers to all q 's parents is generated and recorded (line 19). The values of lastPosl[q] and prevPos[q] are accordingly updated as well (line 20-21).
PartialPathStack-R uses the information returned by getRoles(l ) to determine if the stream node Cl is qualified for being pushed on its stack Sl . The stream node Cl can be pushed on its stack iff it plays at least one role w.r.t a query node in occur(l ) (line 6-7). By populating stacks in this way, we ensure that at any given point in time, the nodes in stacks represent partial solutions that could be further extended to final solutions as the algorithm goes on.
The timing for producing solutions is important in order to avoid generating duplicate solutions. Whenever node Cl that plays the role of a sink node in the query (lines 9-11) is pushed on a stack, and for every sink node in the query there is an entry in the stacks that plays this role (line 12), it is guaranteed that the stacks contain at least one solution to the query. Subsequently, procedure outputSolutions (Procedure 5) is invoked to output all the solutions that involve Cl (lines 14 and 18). Note that since every time solutions are produced, they involve the newly pushed node Cl , PartialPathStack-R does not generate duplicate solutions.
Procedure outputSolutions gradually produces the nodes in each solution in an order that corresponds to the reverse topological order of the query nodes. This way, the image of a query node is produced in a solution after the images of all its descendant nodes in the query are produced. Procedure outputSolutions takes three parameters: outputSinkNodes, curNode, and stackPos. A solution under construction by outputSolutions is recorded in an array solution
indexed by the query nodes. The image of curNode recorded in
solution[curNode]
is the position of an entry in stack
Slabel(curNode)
. WHen recursively processing the next query node curNode-1, denoted as m
, we consider three cases:
(1) If m
is in outputSinkNodes (which implies m
is a sink node), we output solutions that involve the last qualified entry in stack
Slabel(m)
(line 6).
(2) If m
is a sink node not in outputSinkNodes, we output solutions that involve all the qualified entries in stack
Slabel(m)
(line 7-12).
(3) If node m
is an internal query node, the highest entry e
in stack
Slabel(m)
that can be used in a solution as an image of m
is the lowest ancestor in the XML tree of the images of the child nodes of m
in the query. Since the child nodes of m
have already been processed, their images are recorded in solution
. Entry e
is identified by the lowest position in stack
Slabel(m)
pointed to by pointers from stack entries that are images of the child nodes of m
in the solution under construction (line 14). The chain of entries that play the role of m
in stack
Slabel(m)
starting with e
are used as images of m
for constructing solutions (lines 15-18).
Note that if there is a child relationship from m to another node, only a single recursive call to outputSolutions needs to be invoked. We omit the details in the algorithm for the interest of space.
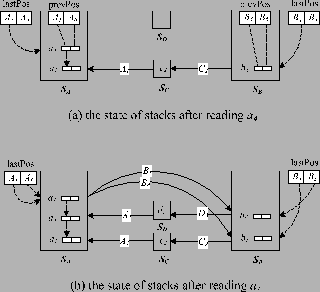
Fig. 8 shows a running example for PartialPathStack-R, where the stack for the query root R is not shown for simplicity. We do not show the lastPos and prevPos of query nodes with a single occurrence in the query. We use for Q6 the topological order: R , A1 , C2 , D3 , B4 , B5 , A6 . The input streams are Ta : {a1, a4, a7} , Tb : {b3, b6} , Tc : {c2} , and Td : {d5} . The initial value for the input stream cursors Ca , Cb , Cc , and Cd in that order is a1 , b3 , c2 , d5 . Fig. 6(a) shows the state of the stacks after a4 is read. At this point, there is no entry in stack Sa that plays the role of A6 . Therefore lastPosa[A6] is 0. Similarly, lastPosb[B5] for stack Sb is 0, since the entry b3 can only play the role of B4 . Since a4 plays the role of A1 , its prevPos[A1] field points to the lower entry a1 in Sa that plays the role of A1 . Fig. 6(b) shows the state of stacks after a7 is read. As a7 plays the role of A6 , the entry for a7 has two outgoing pointers which respectively point to b3 and b4 in stack Sb , and its stack position is recorded in lastPosa[A6] . Since A6 is a sink node of Q6 , a7 triggers the generation of solutions. Note that when A1 is processed by outputSolutions, a1 is chosen as a value for A1 in the solution under construction, since a1 has lower position than a4 in stack Sa (line 13 in outputSolutions). The final answer for Q6 is {ra1c2d5b3b6a7} .
It is easy to see that for each stream node x
stored in stack Sl
, the above proposition along with Definition 4.1 ensures that Algorithm partialPathStack-R will find all solutions in which x
matches one of its roles.
Given a query Q and an XML tree T , let indegree denote the maximum number of incoming edges to a query node and outdegree denote the maximum number of outgoing edges from a query node. Other parameters are the same for the analysis of IndexPaths-R.
Since PartialPathStack-R does not generate any intermediate solutions, the time complexity of PartialPathStack-R depends mainly on the number of calls to getRoles and outputSolutions. For each stream node, getRoles takes time
O(indegree x maxOccur)
. Procedure outputSolutions spends O(outdegree
) on each query node, since in line 13 it computes the lowest stack position among the entries of the children of the query node. Thus it takes
O(outdegree x output)
to produce all the solutions. Therefore, PartialPathStack-R has time complexity
O(input x indegree x maxOccur +
outdegree x output)
.
The space complexity depends mainly on how many entries are stored in stacks at a given point in time and the number of pointers associated with these entries. The total number of stack entries at any time is O(min(height, input)) . For each stack entry, the maximum number of outgoing pointers is O(indegree x maxOccur) . Therefore, the number of pointers in stacks is bounded by min(height, input) x indegree x maxOccur .
Based on the above theorem, PartialPathStack-R is asymptotically optimal if the indegree , outdegree , and maxOccur of the query are bounded by a constant. Clearly, for the case of a query whose dag is a tree, only the outdegree and maxOccur need to be bounded by some constants for PartialPathStack-R to be asymptotically optimal.
We ran a comprehensive set of experiments to measure the performance of IndexPaths-R, PartialMJ-R and PartialPathStack-R. In this section, we report on their experimental evaluation.
Setup. We evaluated the performance of the algorithms on both benchmark and synthetic
data. For benchmark data, we used the Treebank XML document2. The XML tree of Treebank consists of around 2.5
million nodes having 250
distinct element tags, and its depth is 36
. For
synthetic data, we generated random XML trees, using IBM's AlphaWorks XML
generator3.
The number of distinct element tags used in all synthetic trees was fixed to 5
. For each measurement on synthetic
data, five
different XML trees with the same number of nodes were used. Each value displayed in the plots is averaged over these five
measurements.
Fig. 9 shows the queries used in our experiments. Queries Q1 to Q4 include only descendant relationships, while queries Q5 to Q8 include child relationships as well. Our query set comprises a full spectrum of partial path queries, from simple path-pattern queries to complex dag queries. The queries are appropriately modified for the Treebank dataset, so that they can all produce solutions. Thus, node d2 is removed, and node labels r , a , b , c and d are changed to File , S , VP , NP and NN , respectively.
We implemented all algorithms in C++, and ran our experiments on a dedicated Linux PC (AMD Sempron 2600 + ) with 2GB of RAM.
Execution time on fixed datasets. We measured the execution time of IndexPaths-R, PartialMJ-R and PartialPathStack-R for evaluating all queries in Fig. 9 on Treebank and on two synthetic datasets, SD1 and SD2 . All trees in SD1 have depth 12 and consist of 1.5 million nodes. All trees in SD2 have depth 20 and consist of 1 million nodes. For path-pattern queries Q1 and Q5 , we also measured the execution time of PathStack-R.
Fig. 10(a), 10(b) and 10(c) present the evaluation results. Fig. 10(d) shows the number of results obtained per query in each dataset. Algorithm PartialPathStack-R is efficient for all types of queries.
As expected, IndexPaths-R, PartialMJ-R and PartialPathStack-R perform almost as fast as PathStack-R in the case of the path-pattern queries Q1 and Q5 .
The execution time of algorithm IndexPaths-R is high for queries with a large number of path queries generated from the index tree, that is, for queries Q3 , Q4 , Q7 and Q8 .
The performance of both PartialMJ-R and PartialPathStack-R in all datasets is affected by the number of solutions. This confirms our complexity results that show dependency of the execution time on the input and output size. In the case of queries Q2 and Q4 on SD2 (Fig. 10(c)), where the number of solutions is high (Fig. 10(d)), the execution time of PartialMJ-R strongly increases.
Execution time varying the input size. We measured the execution time of
IndexPaths-R, PartialMJ-R and PartialPathStack-R for evaluating queries
Q2
, Q4
and Q8
of Fig. 9 on random XML trees of various sizes. Fig. 11
presents the execution time and the results obtained on XML trees whose node stream sizes vary from 0.5
to 2.5
million nodes. The depth of the XML trees is 12
.
PartialPathStack-R clearly outperforms IndexPaths-R and PartialMJ-R regarding queries Q2 and Q4 (IndexPaths-R is out of range in Fig. 11(b)). For query Q8 , the performance of PartialPathStack-R is similar to that of PartialMJ-R. This is due to the small number of results produced (Fig. 11(f)).
An increase in the input size results in an increase in the output size (Figures 11(d), 11(e) and 11(f)). Also, when the input and the output size go up, the execution time of all algorithms increases (Figures 11(a), 11(b) and 11(c)). This confirms the complexity results that show dependency of the execution time on the input and output size.
In the experimental evaluation of query Q4 , the output size (Fig. 11(e)) increases sharper than in the evaluation of query Q2 (Fig. 11(d)). The execution time of PartialPathStack-R is only slightly higher in the evaluation of Q4 (Fig. 11(b)) than in the evaluation of Q2 (Fig. 11(a)). In contrast, the execution time of PartialMJ-R is strongly affected.
In this paper, we addressed the problem of evaluating partial path queries with repeated labels under the indexed streaming model. Partial path queries generalize path-pattern queries and are useful for integrating XML data sources with different structures and for querying XML documents when the structure is not fully known to the user. Partial path queries are expressed as dags and can be specified in XPath with reverse axes.
We designed three algorithms for evaluating partial path queries on XML data. The first algorithm, IndexPaths-R, exploits a structural summary of data to generate an equivalent set of path patterns of a partial path query and then uses a stack-based algorithm, PathStack-R, for evaluating path-pattern queries with repeated labels. The second algorithm, PartialMJ-R, extracts a spanning tree from the query dag and uses PathStack-R to find the matches of the root-to-leaf paths in the tree. These matches are progressively merge-joined to compute the answer. Finally, the third algorithm, PartialPathStack-R, exploits multiple pointers of stack entries and a topological ordering of the nodes in the query dag to apply a stack-based holistic technique. To the best of our knowledge, PartialPathStack-R is the first holistic algorithm that evaluates partial path queries with repeated labels. We analyzed to the three algorithms and conducted extensive experimental evaluations to compare their performance. Our results showed that PartialPathStack-R has the best theoretical value and has considerable performance superiority over the other two algorithms.
We are currently working on extending our approaches for evaluating partial tree-pattern queries under the indexed streaming model.
![\begin{figure}\center
\scalebox{1}{ \subfigure[]{\epsfig{file=figures/tree.eps}...
...bfigure[]{\epsfig{file=figures/index-tree.eps} } } \hspace*{.1cm}
\end{figure}](fp910-wu-img5.gif)
![\begin{figure}\center
\scalebox{1}{ \subfigure[]{\epsfig{file=figures/q1.eps} }...
...e[]{\epsfig{file=figures/q4.eps} } } \hspace*{.1cm}\vspace*{-2ex}
\end{figure}](fp910-wu-img7.gif)
![\begin{figure}\center
\scalebox{1}{ \subfigure[]{\epsfig{file=figures/q1r.eps} ...
...\subfigure[]{\epsfig{file=figures/q4r.eps} } } \hspace*{.1cm}\par
\end{figure}](fp910-wu-img9.gif)
![\begin{algorithm}
% latex2html id marker 309
[!t]
\begin{small}
\caption{PathSt...
...pointer to $S_p$.top($S_p$)))
\ENDIF
\end{algorithmic}\end{small}\end{algorithm}](fp910-wu-img11.gif)
![\begin{figure}\center
\scalebox{1}{ \subfigure[]{\epsfig{file=figures/path2.eps...
...]{\epsfig{file=figures/q6s.eps} } } \hspace*{.1cm}
\vspace*{-1ex}
\end{figure}](fp910-wu-img13.gif)
![\begin{algorithm}
% latex2html id marker 419
[!t]
\begin{small}
\caption{Partia...
...tructural relationships in $E$
\par
\end{algorithmic}\end{small}\end{algorithm}](fp910-wu-img14.gif)
![\begin{algorithm}
% latex2html id marker 483
[!t]
\begin{small}
\caption{Partia...
...TE advance($C_l$)
\ENDWHILE
\par
\end{algorithmic} \end{small} \end{algorithm}](fp910-wu-img15.gif)
![\begin{algorithm}
% latex2html id marker 502
[!t]
\begin{small}
\floatname{algo...
...DIF
\ENDFOR
\ENDIF
\STATE return $e$
\end{algorithmic}\end{small}\end{algorithm}](fp910-wu-img16.gif)
![\begin{algorithm}
% latex2html id marker 523
[!t]
\begin{small}
\floatname{algor...
...$m$]
\UNTIL{($i$==0)}
\par
\ENDIF
\end{algorithmic} \end{small} \end{algorithm}](fp910-wu-img17.gif)
![\begin{figure}\center
%\vspace*{-0.6cm}
\scalebox{1}{ \subfigure[$Q_1 (Q_5)$]{...
...Q_8)$]{\epsfig{file=figures/exp_q4rep.eps} } }
%
\vspace*{-1ex}
\end{figure}](fp910-wu-img19.gif)
![\begin{figure*}\center
\subfigure[Execution time (Treebank)]{ \scalebox{0.4}{\e...
... $Q_8$\ & 1258 & 6081 & 51583\\
\hline
\end{tabular}\par
}
}
\end{figure*}](fp910-wu-img20.gif)
![\begin{figure*}\center
\subfigure[$Q_2$\ execution time]{ \scalebox{0.4}{\epsfi...
...g{file=gnuplot2/datasize_resultsQ8.eps} } }%\hspace*{0.2cm}
\par
\end{figure*}](fp910-wu-img21.gif)