Nalaka Gooneratne ![]() Zahir Tari
Zahir Tari
School of Computer Science and Information Technology
RMIT University
1
Nalaka Gooneratne ![]() Zahir Tari
Zahir Tari
School of Computer Science and Information Technology
RMIT University
H.3.3Information Search and RetrievalSearch process, Selection process H.3.5Online Information ServicesWeb-based services
Performance, Theory, Algorithms
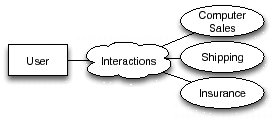
Before providing further details about existing semantic-based approaches, we will first consider the following scenario which will be used in the rest of this paper (to illustrate the use of various concepts). In this scenario, we want to model the ``purchase service", where a user wishes to purchase a (Macintosh) computer online and wants it delivered home. A shipper should be able to pick up this computer from the dispatch location of a seller, and it should be insured from the point at which the computer is picked up. The computer must not be insured until it is assembled (so that the insured period can be maximised), and it should not be picked up by the shipper until it is insured. The (composite) service shown in Figure 1 is formed by locating, co-ordinating and collaborating the constituent services, and executed to satisfy this request.
Locating a composite service (like the one shown in Figure 1) would require accurate specifications of both service descriptions and user requests. Constraints are used in user requests to accurately describe the services that need to be located [2]. They are of two types: local and global constraints. The former restricts the values of a particular attribute of a single service (e.g. type.Computer = MACINTOSH), whereas the latter simultaneously restricts the values of two or more attributes of multiple constituent services. Global constraints can be classified based on the complexity of solving them (i.e. determining the values that should be assigned to their attributes) as either strictly dependent or independent. A (global) constraint is strictly dependent if the values that should be assigned to all the remaining restricted attributes can be uniquely determined once a value is assigned to one. location.Dispatch = location.Pickup ![]() validRegion.Insurance is an example of a strictly dependent global constraint. Once MELBOURNE is assigned to location.Dispatch, the same value has to be assigned to location.Pickup and included in the set of values assigned to validRegion.Insurance. Services that conform to strictly dependent global constraints can be easily located in polynomial time [5].
validRegion.Insurance is an example of a strictly dependent global constraint. Once MELBOURNE is assigned to location.Dispatch, the same value has to be assigned to location.Pickup and included in the set of values assigned to validRegion.Insurance. Services that conform to strictly dependent global constraints can be easily located in polynomial time [5].
Any global constraint that is not strictly dependent, is independent. For example, availableDate.Computer ![]() approvalDate.Insurance
approvalDate.Insurance ![]() date.Pickup is an independent global constraint. In our opinion, the class of composite services that conform to independent global constraints is probably the ``most" interesting to study, as their location is known to be NP-hard [3,12]. Indeed, if a given independent global constraint restricts q attributes, and if service descriptions assign p values to each attribute, then a technique locating a conforming service may have to consider p
date.Pickup is an independent global constraint. In our opinion, the class of composite services that conform to independent global constraints is probably the ``most" interesting to study, as their location is known to be NP-hard [3,12]. Indeed, if a given independent global constraint restricts q attributes, and if service descriptions assign p values to each attribute, then a technique locating a conforming service may have to consider p![]() combinations of values. As a consequence most of the existing matching techniques (for locating composite services) do not consider independent global constraints [1,8]. Nonetheless, there are some that consider them [9,11,12] and they use integer programming solutions focusing on local optimisations [12] and AI planners [9,11] to efficiently locate conforming composite services. However, all the techniques of the latter type are syntactic-based approaches. None of the current semantic-based composite matching approaches consider independent global constraints.
combinations of values. As a consequence most of the existing matching techniques (for locating composite services) do not consider independent global constraints [1,8]. Nonetheless, there are some that consider them [9,11,12] and they use integer programming solutions focusing on local optimisations [12] and AI planners [9,11] to efficiently locate conforming composite services. However, all the techniques of the latter type are syntactic-based approaches. None of the current semantic-based composite matching approaches consider independent global constraints.
This paper proposes a semantic-based matching technique that locates services conforming to independent global constraints. A two dimensional data structure, called a slot list, is designed to efficiently find services. Available services are indexed based on the values they assign to the attributes restricted by a global constraint. This index enables the quick retrieval of services that assign a particular value to their restricted attribute. Then, tuples of conforming values are determined using either a greedy approach or derived using domain rules [2]. Finally, services that assign these conforming values to their restricted attributes are retrieved from the slot list and combined to form conforming composite services. Experiments were performed to compare the proposed techniques against a syntactic-based composite matching technique [11] and a relevant semantic-based matching technique [2]. The proposed technique that incorporates a greedy algorithm performs 76% better than the existing techniques. Experimental results also show that the proposed approaches achieve a higher recall than syntactic-based approaches.
The rest of his paper is organized as follows. In the remaining sections we will refer to composite services simply as ``services" (because the focus of this paper is only on the discovery of such services). Section 2 overviews some background needed to understand the various parts of the paper. In Section 3 we provide concise guidelines on how requests for services should be specified. Section 4 details the proposed composite matching techniques and Section 5 provides a summary of advantages/limitations of the proposed approaches. Details of the experiments are given in Section 6. In Section 7, we review existing composite matching techniques. Finally, we summarize and conclude in Section 8.
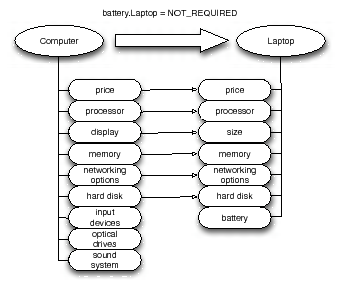
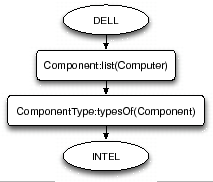
The relationships between the elements of an ontology are specified with substitution graphs and transformation graphs. In a substitution graph, the contextual aspect of a relationship is specified with a substitution condition. Each (substitution) graph defines a set of attribute mappings. Figure 2 depicts an example of a substitution graph which specifies the relationship between Computer and Laptop. A transformation graph models a relationship requiring the meta-model of an element to be changed. It is specified with one or more consecutive operations. Figure 3 shows a transformation graph modeling the relationship between Dell and Intel (which are brand names of a Computer and a Processor). This is specified with an operation that lists components and another that returns the type of one.
These two data structures (i.e. substitution and transformation graphs) are specified for every element of an ontology (i.e. concept, operations, roles). The meta-ontology requires any transitive relationship to be explicitly specified with the data structures. For example, if Calculator can be substituted with Laptop, and Laptop can be substituted with Computer, there is a transitive substitution relationship between Calculator and Computer. Then, a substitution graph which allows the concept Calculator to be substituted with Computer should be explicitly included in the ontological descriptions.
An WS-
![]() 's operation (used to describe the purpose of a service) is constrained by the role it performs in a domain and the concepts it affects. For example, a Computer Sales service performs the operation Sales(), affects the concept Computer and performs the role of an Sales_Assistant. The data transformations are described with inputs and outputs. ``in-constraints" and ``out-constraints" restrict the values used as inputs and outputs. State transitions are described with pre-conditions and post-conditions.
's operation (used to describe the purpose of a service) is constrained by the role it performs in a domain and the concepts it affects. For example, a Computer Sales service performs the operation Sales(), affects the concept Computer and performs the role of an Sales_Assistant. The data transformations are described with inputs and outputs. ``in-constraints" and ``out-constraints" restrict the values used as inputs and outputs. State transitions are described with pre-conditions and post-conditions.
The conditions (specifying the in-constraints, out-constra- ints, pre-conditions and post-conditions) model a relationship between an attribute and a value. A condition explicitly reduces the scope of an attribute to a particular domain. The scope of an attribute is the set of values that can be assigned to the attribute. It is defined by associating an attribute with a concept. For example, the scope of the attribute dispatchTime cannot be determined unless it is specified as dispatchTime.Computer. Then any value (specifying the time taken to dispatch a computer) can be assigned to the attribute dispatchTime. When an attribute is used in a condition, its scope is reduced to a particular domain. For example, in a condition of the form dispatchTime.Computer![]() 24_HOURS, the scope of dispatc- hTime.Computer is reduced to a value less than 24 hours.
24_HOURS, the scope of dispatc- hTime.Computer is reduced to a value less than 24 hours.
The attribute Computer.display is semantically related to Laptop.size according to the substitution graph given in Figure 2, because Computer substitutes Laptop and the substitution results in display being mapped to size.
![\begin{displaymath}
\begin{array}{l}
\{[Sales(), Computer, Sales\_Assistant],\\ ...
...\\
\ [Insure(), Computer, Sales\_Representative]\}
\end{array}\end{displaymath}](fp051-gooneratne-img15.png)
The proposed approach employs both a local optimisation technique and derivation-based technique (that uses domain rules) to determine values that conform to a given constraint. The reasons for using these techniques will be described in the next section. Both of these techniques determine the values that should be assigned to all the attributes based on a value assigned to one. Hence, they use the values assigned to one particular attribute as a starting point. This attribute is referred to as the ``free attribute''. Unlike the values assigned to the non-free attributes, all the values assigned to this attribute will be considered by the proposed approach when determining conforming values.
Since an independent global constraint is a collection of binary attribute comparisons, the relationships between the attributes are specified with a set of binary operators. Each one of them is specified with two attributes and relational operator, which can be either =, ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() or
or ![]() . Following is the description of availableDate.Computer
. Following is the description of availableDate.Computer ![]() approvalDate.Insurance
approvalDate.Insurance ![]() date.Pickup.
date.Pickup.

The proposed approach consists of three phases: (1) candidate acquisition, (2) service indexing and (3) composite service acquisition. The first phase locates services of the different types in a composite service template. The second phase identifies restricted attributes of services and indexes them based on the assigned values. The final phase retrieves the values that conform to a given constraint and combines services that assign those values to their restricted attributes (to form conforming composite services).
Let S![]() be a service type and s
be a service type and s![]() a given service. We also denote by o
a given service. We also denote by o![]() , c
, c![]() and r
and r![]() the operation, the affected concept and the role that describe S
the operation, the affected concept and the role that describe S![]() . For
. For ![]() we denote its elements by
we denote its elements by ![]() ,
, ![]() and
and ![]() . The service s
. The service s![]() is a candidate of type S
is a candidate of type S![]() if o
if o![]() substitutes o
substitutes o![]() , c
, c![]() substitutes c
substitutes c![]() , and r
, and r![]() substitutes r
substitutes r![]() . The substitutions are performed with the substitution graphs in a meta-ontology [2]. Each candidate s
. The substitutions are performed with the substitution graphs in a meta-ontology [2]. Each candidate s![]() of type S
of type S![]() is placed in a list of candidates
is placed in a list of candidates
![]() . Given the available services W and a composite service template CST (defined with the service types S
. Given the available services W and a composite service template CST (defined with the service types S![]() ,
, ![]() , S
, S![]() ), this phase generates a set of candidate lists Candidates, where Candidates={
), this phase generates a set of candidate lists Candidates, where Candidates={
![]() ,
, ![]() ,
,
![]() }.
}.
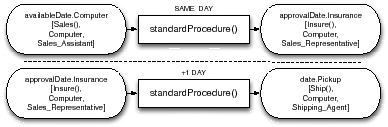
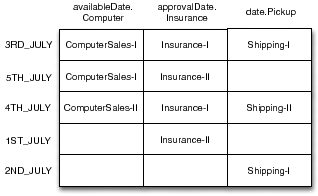
Consider the constraint availableDate.Computer ![]() appro- valDate.Insurance
appro- valDate.Insurance ![]() date.Pickup described in Section 3. This restricts the attributes availableDate.Computer, approvalDate.Insurance and date.Pickup of services of types Sales(C- computer), Insure(Computer) and Ship(Computer)1. A service ComputerSales-I of type Sales(Computer) described with date.Dispatch exists. date.Dispatch is semantically related to availableDate.Computer according to the ontological relationships. In such a situation, the restricted attribute time.Assemble of ComputerSales-I is a restricted attribute, because the values assigned to it are restricted by date.Dispa- tch
date.Pickup described in Section 3. This restricts the attributes availableDate.Computer, approvalDate.Insurance and date.Pickup of services of types Sales(C- computer), Insure(Computer) and Ship(Computer)1. A service ComputerSales-I of type Sales(Computer) described with date.Dispatch exists. date.Dispatch is semantically related to availableDate.Computer according to the ontological relationships. In such a situation, the restricted attribute time.Assemble of ComputerSales-I is a restricted attribute, because the values assigned to it are restricted by date.Dispa- tch ![]() approvalDate.Insurance
approvalDate.Insurance ![]() date.Pickup.
date.Pickup.
Candidate services need to be indexed based on the values assigned to such attributes because of two reasons.
| Service | Type | Assigned Values | |
| ComputerSales-I | Sales(Computer) | 183-2007, 185-2007 | |
| ComputerSales-II | Sales(Computer) | 4TH_JULY | |
| Insurance-I | Insure(Computer) | 3RD_JULY, 4TH_JULY | |
| Insurance-II | Insure(Computer) | 1ST_JULY, 5TH_JULY | |
| Shipping-I | Shipping(Computer) | 4TH_JULY | |
| Shipping-II | Shipping(Computer) | 2ND_JULY, 3RD_JULY |
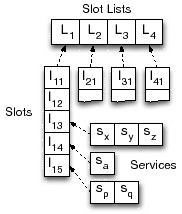
The proposed approach generates a set of Slot Lists to index candidate services based on the values they assign to restricted attributes. Figure 6 provides a global view of this data structure. It depicts a set of Slot Lists {L![]() , L
, L![]() , L
, L![]() , L
, L![]() } generated for a global constraint that restricts the attributes
} generated for a global constraint that restricts the attributes ![]() a
a![]() , a
, a![]() , a
, a![]() , a
, a![]() . Note that a Slot List L
. Note that a Slot List L![]() is generated for every attribute a
is generated for every attribute a![]() . A slot l
. A slot l![]() is included in a list L
is included in a list L![]() for each value v
for each value v![]() that can be assigned to attribute a
that can be assigned to attribute a![]() . Each slot contains a set of services. A service s
. Each slot contains a set of services. A service s![]() is included in a slot l
is included in a slot l![]() if it is able to assign the value v
if it is able to assign the value v![]() to a
to a![]() . That means, the service description of s
. That means, the service description of s![]() is specified using either
is specified using either
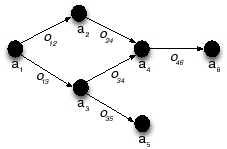
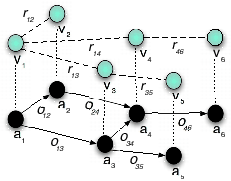
The proposed approach models an independent global constraint as a directed acyclic graph G=(V, E), where V is a set of nodes and E is a set of arcs. The nodes of such a graph represent the attributes and the arcs model the relationships between the attributes. Each arc and the two connected attributes model a binary attribute comparison of a constraint. Figure 7 depicts a graph modeling a constraint that restricts a![]() -a
-a![]() , where the binary attribute comparison are specified with the operators {o
, where the binary attribute comparison are specified with the operators {o![]() , o
, o![]() , o
, o![]() , o
, o![]() , o
, o![]() , o
, o![]() }.
}.
Values that conform to a constraint are identified by generating instances of such graphs. A tuple of values assigned to the nodes of a graph is an instance. For example, the values ![]() v
v![]() , v
, v![]() , v
, v![]() , v
, v![]() , v
, v![]() , v
, v![]() , where each value v
, where each value v![]() is assigned to an attribute a
is assigned to an attribute a![]() , forms an instance of the graph depicted in Figure 7. Such an instance conforms to a given constraint if each of its values conform to the binary attribute comparisons represented by the arcs. A value that conforms to the binary attribute comparisons is referred to as an Arc Consistent Value.
, forms an instance of the graph depicted in Figure 7. Such an instance conforms to a given constraint if each of its values conform to the binary attribute comparisons represented by the arcs. A value that conforms to the binary attribute comparisons is referred to as an Arc Consistent Value.
An instance of a graph that consists of arc consistent values is a tuple of conforming values. Such tuples are referred to as Arc Consistent Instances.
Identifying an arc consistent instance is NP-Hard. If a given relational constraint restricts n attributes and m arc consistent values can be assigned to each attribute, then m![]() combinations of values may have to be considered to identify an arc consistent instance. The proposed technique defines two separate approaches to perform this task. The first approach uses a basic greedy algorithm (backtrack-free search algorithm [3]) to identify arc consistent instances. The second approach derives them using domain rules [2]. The reason for proposing two separate approaches will be given later. We will refer to the first one as the optimised approach, and the second as the derivation-based approach.
combinations of values may have to be considered to identify an arc consistent instance. The proposed technique defines two separate approaches to perform this task. The first approach uses a basic greedy algorithm (backtrack-free search algorithm [3]) to identify arc consistent instances. The second approach derives them using domain rules [2]. The reason for proposing two separate approaches will be given later. We will refer to the first one as the optimised approach, and the second as the derivation-based approach.
Once an instance is located, the services in the slots that correspond to the arc consistent values are combined. Let us consider a constraint gc that restricts the attributes a![]() ,
, ![]() , a
, a![]() of services of types S
of services of types S![]() ,
, ![]() , S
, S![]() . We also assume that a set of Slot Lists SL has been generated for gc. A slot at a location
. We also assume that a set of Slot Lists SL has been generated for gc. A slot at a location ![]() a
a![]() , v
, v![]() , which corresponds to an attribute a
, which corresponds to an attribute a![]() and a value v
and a value v![]() , contains services of type S
, contains services of type S![]() which assign the value v
which assign the value v![]() to attribute a
to attribute a![]() . Therefore, if
. Therefore, if ![]() v
v![]() ,
, ![]() , v
, v![]() is an arc consistent instance, then the services at the slots
is an arc consistent instance, then the services at the slots ![]() a
a![]() , v
, v![]() ,
, ![]() ,
, ![]() a
a![]() , v
, v![]() would form conforming composite services. In the above scenario, when
would form conforming composite services. In the above scenario, when ![]() 3RD_JULY, 3RD_JULY, 3RD_JULY
3RD_JULY, 3RD_JULY, 3RD_JULY![]() is located, the services at the slots
is located, the services at the slots ![]() availableDate.Computer.3RD_JULY
availableDate.Computer.3RD_JULY![]() ,
, ![]() approvalDate.Insura- nce.3RD_JULY
approvalDate.Insura- nce.3RD_JULY![]() and
and ![]() date.Pickup.3RD_JULY
date.Pickup.3RD_JULY![]() are combined to form the conforming composite service
are combined to form the conforming composite service ![]() ComputerSale-I, Insurance-I, Shipping-I
ComputerSale-I, Insurance-I, Shipping-I![]() .
.
![\begin{algorithm}
% latex2html id marker 671
[!h]
\BlankLine
\SetAlFnt{\small\sf...
...}
}
\caption{Locating Services - Greedy Approach}
\vspace{0.3cm}
\end{algorithm}](fp051-gooneratne-img88.png)
First, the empty slots are removed from the Slot Lists (line 2). These slots need to be removed because the corresponding values are not assigned to the relevant restricted attributes by any candidate service. Then, this algorithm attempts to generate an arc consistent instance for each value that is assigned to the free attribute (lines 5-17). Once the instances are generated, the services at the indicated slots are retrieved (lines 20-22) and combined to conforming composite services (lines 23-28). The time complexity of Algorithm 1 is exponential. If a given constraint restricts p attributes, there are m conforming value tuples, and each slot (in the set of Slot Lists) contains q services, then m*(p![]() ) composite services would be generated. However, this technique is ``generally'' polynomial since Algorithm 1 does not retrieve any non-conforming composite services. This algorithm identifies tuples of arc consistent values in polynomial time and only combines services that assign those values to their restrict attributes. Those that do not assign arc consistent values are not considered.
) composite services would be generated. However, this technique is ``generally'' polynomial since Algorithm 1 does not retrieve any non-conforming composite services. This algorithm identifies tuples of arc consistent values in polynomial time and only combines services that assign those values to their restrict attributes. Those that do not assign arc consistent values are not considered.
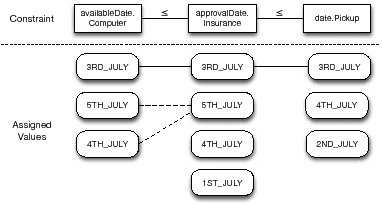
The main drawback of this approach is that it may return false negatives. That means, it may not retrieve all the conforming composite services. In the scenario described in Figure 5, ![]() ComputerSale-I, Insurance-I, Shipping-I
ComputerSale-I, Insurance-I, Shipping-I![]() ,
, ![]() Compute- rSale-I, Insurance-I, Shipping-II
Compute- rSale-I, Insurance-I, Shipping-II![]() and
and ![]() ComputerSale-II, Ins- urance-I, Shipping-II
ComputerSale-II, Ins- urance-I, Shipping-II![]() are conforming composite services, because
are conforming composite services, because ![]() 3RD_JULY, 3RD_JULY, 3RD_JULY
3RD_JULY, 3RD_JULY, 3RD_JULY![]() ,
, ![]() 3RD_JULY, 3RD_JULY, 4TH_JULY
3RD_JULY, 3RD_JULY, 4TH_JULY![]() ,
, ![]() 3RD_JULY, 4TH_JULY, 4TH_J- ULY
3RD_JULY, 4TH_JULY, 4TH_J- ULY![]() and
and ![]() 4TH_JULY, 4TH_JULY, 4TH_JULY
4TH_JULY, 4TH_JULY, 4TH_JULY![]() are consistent instances. However, only
are consistent instances. However, only ![]() 3RD_JULY, 3RD_JULY, 3RD_JULY
3RD_JULY, 3RD_JULY, 3RD_JULY![]() is located by the optimised approach since it employs a greedy algorithm.
is located by the optimised approach since it employs a greedy algorithm.
When generating an arc consistent instance, values are derived for the non-free attributes based on one that is assigned to the free attribute. Since we assume that a rule is a function that derives a value for a derived attribute based on one that is assigned to a determinant attribute, a set of rules can be used to uniquely determine the values that should be assigned to the non-free attributes based on one that is assigned to the free attribute. That means, the domain rules are used to approximate an independent global constraint to a strictly dependent global constraint.
Let us consider the constraint depicted in Figure 7. This could be considered as an approximatable (see Figure 9). The constraint is approximatable if the values ![]() v
v![]() -v
-v![]() assigned to the attributes
assigned to the attributes ![]() a
a![]() -a
-a![]() are derived using the rules {r
are derived using the rules {r![]() , r
, r![]() , r
, r![]() , r
, r![]() , r
, r![]() }, based on the value v
}, based on the value v![]() assigned to a
assigned to a![]() , and
, and ![]() v
v![]() -v
-v![]() form an arc consistent instance.
form an arc consistent instance.
The algorithm that determines whether a given constraint is approximatable is given below (see Algorithm 2). This algorithm requires an independent global constraint, the available domain rules and a set of Slot Lists. A given constraint is considered to be approximatable if at-least one value tuple (i.e an arc consistent instance) to be derived based on a value that is assigned to its free attribute. This algorithm attempts to generate such an instance for each value assigned to the free attribute (lines 4-6). When generating an instance, it iterates through the available rules (line 9) and attempts to derive an arc consistent value (lines 10-20) for each non-free attribute (line 7). If a derived value is arc consistent, both the value and the rule used to derive it are stored in a temporary array (lines 13 and 16). If not, the corresponding elements of the two arrays are reset and another value is derived using a different rule (line 19). Finally, every derived arc consistent instance is placed in a list along with the rules used for the derivations (line 26). The complexity of Algorithm 2 is polynomial (i.e. v*x*y*z, where v is the number of values assigned to the free-attribute, x is the number of non-free attributes, y is the number attributes semantically related to a given restricted attribute and z is the number of rules). This algorithm assumes that (i) each attribute is semantically related to a bounded number of attributes, and (ii) a finite number of domain rules are available.
Once Algorithm 2 is executed, the derived arc consistent instances are obtained from derived_values_list. If it is not empty, the services in the slots (of the Slot Lists) that correspond to the values in the instances are combined (like the proposed optimised approach) to form composite services. The rules used to derive an arc consistent instance are returned with each corresponding composite service.
Let gc be a global constraint that restricts the attributes a![]() ,
, ![]() , a
, a![]() , where the services s
, where the services s![]() ,
, ![]() , s
, s![]() are able to assign the values
are able to assign the values ![]() v
v![]() ,
, ![]() , v
, v![]() and
and ![]() v
v![]() ,
, ![]() , v
, v![]() to the restricted attributes. If both tuples of values conform to gc (i.e. they are arc consistent instances), one duplicate entry would be retrieved. In a situation in which n conforming value tuple can be assigned to the restricted attributes by a tuple of services, where n
to the restricted attributes. If both tuples of values conform to gc (i.e. they are arc consistent instances), one duplicate entry would be retrieved. In a situation in which n conforming value tuple can be assigned to the restricted attributes by a tuple of services, where n![]() 1, n-1 duplicate entries would be retrieved by these techniques.
1, n-1 duplicate entries would be retrieved by these techniques.
However, the number of these duplicate entries only increases at a polynomial rate. If there are p conforming composite services, the number of duplicate entries that can be generated would be p*q, where q is the number of conforming value tuples assigned to each tuple of restricted attributes.
Up to our knowledge, there is no standard data set that can be used to evaluate semantic-based service discovery techniques. We were unable to obtain a real-world data set of semantic-based web service descriptions. None of the composite matching techniques that we came across [1,8,9,11,12] defined an approach to generate test data. We have therefore tried to generate our own test data set using a ``appropriate" methodology which uses the following steps. Even though this may not be the best way, we believe that it will give us good indication about the quality of the proposed approaches (when compared to existing ones).
Details were extracted from sample ontologies and an ontology that consists of 157 concepts, 19 roles and 27 operations was randomly generated. 2000 substitution graphs and transformations graphs were generated to define ontological relationships. Service descriptions were created with elements that were randomly selected from the ontology. Each description had an operation, an affected concept, a role and between 20 to 30 pre-conditions and post-conditions.
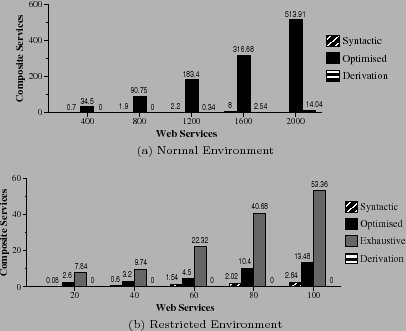
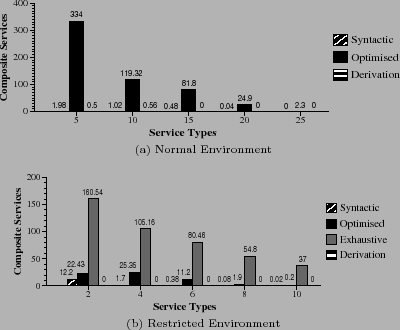
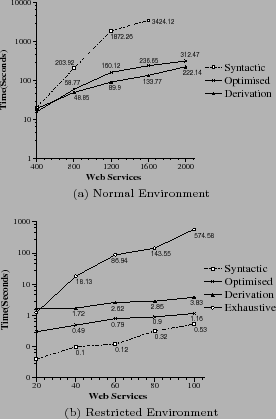
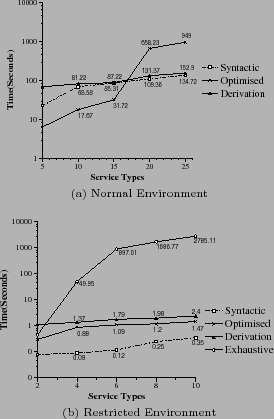
A similar approach was used in [2] to generate test data to evaluate implementations of their semantic-based matching techniques. Experiments were conducted by varying the number of available service descriptions and service types in composite service templates. Between 400 to 2000 service descriptions and composite service templates which include between 5 to 25 service types were considered. Since the technique proposed in [2] employed an exponential algorithm, it was not feasible to execute it in such an environment. Hence, the experiments that included the exhaustive approach were conducted in a restricted environment, which contained between 20 to 100 service descriptions and composite service templates that include between 2 to 10 service types.
The recall levels achieved by the exhaustive and the proposed optimised approach were higher than that achieved by the syntactic approach. Unlike the later approach, the semantic-based approaches matched syntactically heterogeneous service descriptions and user requests using ontological relationships. The exhaustive approach considered all the possible combination of services; and for each combination it employed an exhaustive algorithm to evaluate the values assigned to the restricted attributes (i.e. it checks if the values assigned to the restricted attributes conform to a given constraint). The proposed approach only considered a limited number of values. Hence, the exhaustive approach retrieved more services than the proposed approach. The number of services retrieved by all the techniques decreased, as the number of service types increased. The values assigned to the restricted attributes of candidate services had to conform to an increasing number of binary attribute comparisons. The derivation-based approach did not retrieve many services because the rules required to approximate a given constraint were not available. The used random process did not generate the required rules.
The performance of the optimised technique was 76% better than that of the syntactic approach in the experiments varied the number of available services. The syntactic approach used JSHOP, which performs a combinatorial depth-first search to locate conforming composite services. On the other hand, the proposed local optimisation-based approach determined the values that conform to a given constraint in polynomial time and only combined services that assign those values. The performance of the syntactic approach was 32% better in the experiments that increased the number of service types in a composite service template. Since the optimised approach is semantic-based it retrieved more candidate services than the syntactic approach. The time taken by the devised approach to index services in the Slot Lists increased at a rapid rate with an incrementing number of service types. The exhaustive approach was the least efficient in the restricted environment. In the two worst cases (with 100 available services and 10 service types) it took around 9 minutes 35 seconds, and and 46 minutes and 25 seconds respectively, whereas the proposed approach only took 1.16 seconds and 1.47 seconds.
Wu et al. in [11] and Sirin et al. in [9] considered both local and global constraints. Their approaches require service descriptions and user requests to be specified with OWL-S. SHOP-2 (Simple Hierarchical Planner-2) is used to locate an orchestration of services that form a conforming composite service. First, a ``SHOP method'' is generated according to the OWL-S process in a request. Then, the request and available service descriptions are converted to operator instances. Both approaches directly used the unification functions of SHOP-2 to match domain instances to operators. Therefore basic string matching functions were used to match user requests to service descriptions. The approach in [9] extends [11] by incorporating a Description Logic reasoner. However, this is only used to check whether the pre-conditions of a given operator (in the hierarchy) are entailed by the state of the planner. Therefore, the approach in [9] locates conforming composite services when a constraint in a request is specified with attributes that have different scopes, but not when requests and service descriptions are syntactically heterogeneous.
Zeng et al. [12] introduced an approach requiring a request (for a composite service) to be specified with a state chart diagram, where each state models a service type. Services were described with a quality of service model that consists of attributes such as execution price, execution duration, reliability, availability, and reputation. Both local and global constraints were considered in their approach. However, these constraints were limited to those that can be specified with an attribute of the quality of service model. A syntactic-based integer programming technique that focuses on local optimisation is used to match the user requests to the service descriptions.
![\begin{algorithm}
% latex2html id marker 958
[!h]
\BlankLine
\SetAlFnt{\small\sf...
...ion{Approximating Independent Global Constraints}
\vspace{0.3cm}
\end{algorithm}](fp051-gooneratne-img99.png)