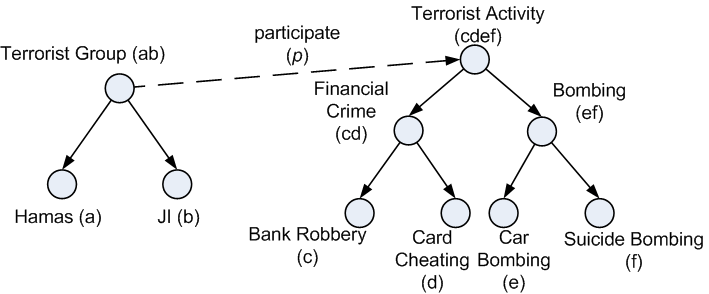
Figure 1: A sample RDF vocabulary with one predicate participate and two taxonomies of entities.
In this paper, we present a novel frequent generalized pattern mining algorithm, called GP-Close, for mining generalized associations from RDF metadata. To solve the over-generalization problem encountered by existing methods, GP-Close employs the notion of generalization closure for systematic over-generalization reduction.
H.2.8 [Database Applications]: Data mining
Algorithms
RDF Mining, Association Rule Mining
Resource Description Framework (RDF) [4] is a specification proposed by the World Wide Web Consortium (W3C) for describing and interchanging semantic metadata on the Semantic Web [2]. Due to the continual popularity of the Semantic Web, in a foreseeable future, there will be a sizeable amount of RDF-based content available on the web, offering tremendous opportunities in discovering useful knowledge from large RDF databases. As one of the key data mining techniques in the area of Knowledge Discovery in Database (KDD), Association Rule Mining (ARM) [1] can play an important role for RDF based data mining in the Semantic Web era. With the use of the taxonomies of RDF entities (classes and instances) and RDF statements defined by RDF vocabularies, association rules can be extracted in a generalized form conveying knowledge in a compact manner. The discovered associations may have many applications, such as
Figure 1: A sample RDF vocabulary with one predicate participate and two taxonomies of entities.
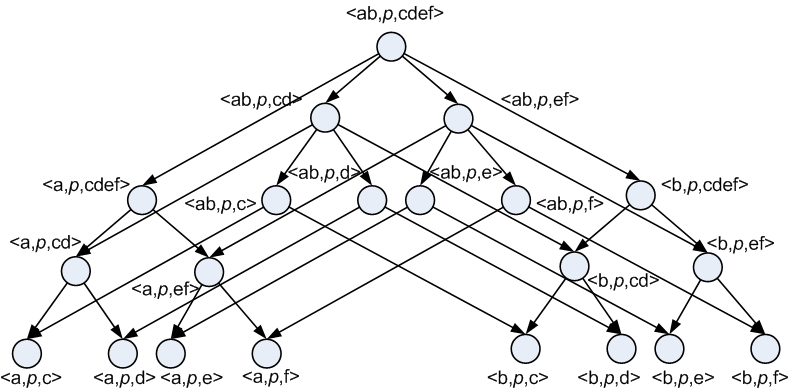
Figure 2: RDF statement hierarchy inferred from the RDF vocabulary in Figure 1.

Figure 3: Illustration of over-generalization and generalization closure.
RDF data sets are documents of RDF statements, each of which is a triplet in the form of <subject, predicate, object>. The unique characteristics of RDF data sets lie in the relatively large sizes of RDF documents and the complex taxonomic structures of the RDF statement hierarchies, wherein an RDF statement can be generalized in many ways, e.g. by generalizing its subject, object, predicate, or any combination of them (see Figure 1 and 2). In ARM, frequent pattern mining (FPM) is the most time-consuming part. For RDF data sets, traditional generalized association rule mining algorithms that extract all frequent generalized patterns (RDF statement sets) do not work efficiently due to the fact that a large portion, if not most, of frequent generalized patterns are over-generalized. A frequent generalized pattern is said over-generalized if all RDF documents that contain the pattern also contain a same specialized pattern of it. For example, in Figure 3, the pattern X2 is an over-generalization of X1. In such a case, the pattern can always be inferred from its specialized pattern. Therefore, over-generalized patterns are redundant.
For accelerating the mining process, we employ the notion of
generalization closure for full over-generalization
reduction. A generalization closure of a pattern X,
denoted as
![]() X, is
an RDF statement set containing all statements in X and
all their generalized statements (see Figure 3). A generalization closure is said to be
closed if it does not have any superset of statements such
that they are subsumed by the same set of RDF documents.
X, is
an RDF statement set containing all statements in X and
all their generalized statements (see Figure 3). A generalization closure is said to be
closed if it does not have any superset of statements such
that they are subsumed by the same set of RDF documents.
Generalization closures have the following key
features:
We develop the GP-Close (Closed Generalized Pattern Mining) algorithm (Algorithm 1 and 2) that discovers the set of closed generalization closures instead of all frequent generalized patterns to minimize computation cost.
Our experiments are conducted based on two real world RDF data sets, namely the foafPub data set provided by UMBC eBiquity Research Group1 and the ICT-CB data set extracted from an online database of International Policy Institute for Counter-Terrorism (ICT)2. foafPub is a set of RDF files that describe peoples and their relationships with the use of the FOAF vocabulary3. The contents of the ICT-CB documents are descriptions of car bombing events. We also implemented the original generalized association rule mining algorithm, Cumulate [3], as a reference of performance evaluation and comparison.
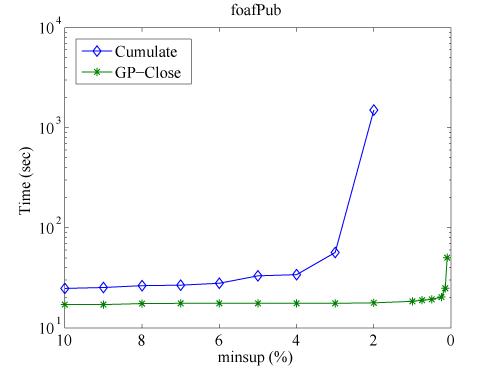
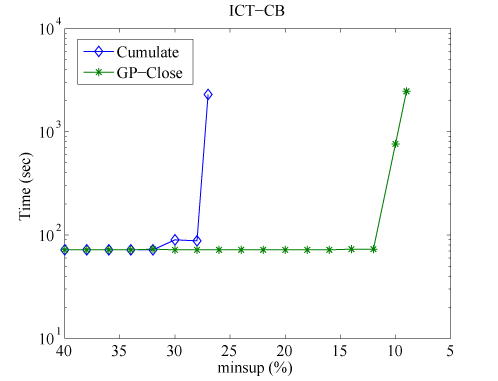
Figure 4: Execution time of GP-Close compared with Cumulate.
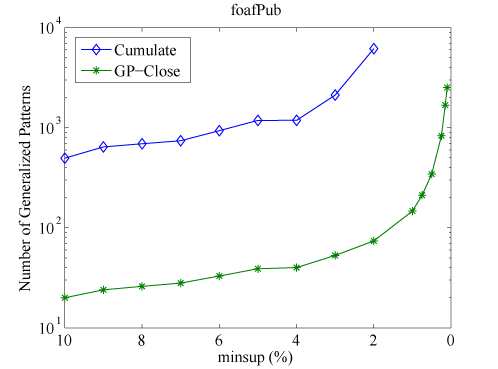
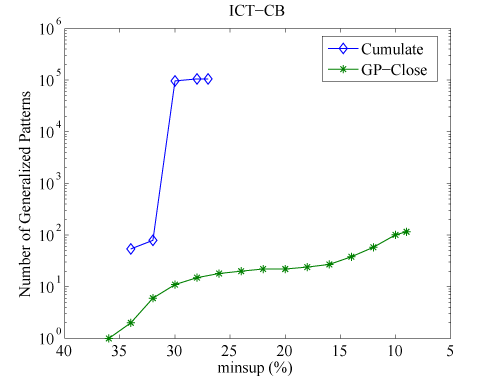
Figure 5: Number of patterns extracted by GP-Close compared with Cumulate.
Figure 4 shows the computation time of the two algorithms, Cumulate and GP-Close, with respect to the minimum support (minsup). We find that Cumulate can work properly only with high minsup. When the minsup is low, the GP-Close algorithm performs more than an order of magnitude faster than Cumulate.
The number of patterns discovered by the GP-Close and Cumulate are depicted in Figure 5. The number of closed generalization closures is almost one to two orders of magnitude smaller than the number of all frequent patterns discovered by Cumulate. Note that a Log scale is used in Figure 5. Therefore, the stable margin between the two curves actually implies an exponential growth in the difference between the numbers of all frequent patterns and the closed generalization closures.
[1] R. Agrawal, T. Imielinski, and A. N. Swami. Mining association rules between sets of items in large databases. In SIGMOD '93, pages 207-216, 1993.
[2] T. Berners-Lee, J. Hendler, and O. Lassila. Semantic web. Scientific American, 284(5):35-43, 2001.
[3] R. Srikant and R. Agrawal. Mining generalized association rules. In VLDB '95, pages 407-419, San Francisco, 1995.
[4]W3C. W3C RDF Specification.

