We propose novel use of image data on the Web. So far, much work regarding Web image search has been proposed as well as commercial services However, most of them focused on only ``search''. On the other hand, our purpose is ``Web image mining''[3,2], which means searching the Web for images and then using them as visual knowledge for some applications. In this paper, we describe a new method and experiments to measure ``visualness'' of word concepts with Web images as a case study of ``Web image mining''.
Regarding text data, there are many studies about how to gather data from the Web and use it as ``knowledge'' effectively. While such Web text mining is an active research area, mining image data on the Web poses additional challenges and has seen less research activity. The problem with mining images for knowledge is that it is not known how to reliably automatically determine semantics from image data. This has been refereed to as the semantic gap. To solve it, it is indispensable to introduce sophisticated image recognition methods into Web mining regarding images.
In [3,2], we proposed gathering a training data set for generic image recognition from the Web automatically, and have revealed that we could use Web images as ``visual knowledge''. In this paper, we propose yet another new application of ``Web image mining''.
In this paper, we describe how to measure ``visualness'' of word concepts using Web images, that is, what extent concepts have visual characteristics. We have many words to annotate images with. However, not all words are appropriate for image annotation, since some words are not related to visual properties of images. To know which word concept has visually discriminative power is important for image recognition task, especially automatic image annotation by generic image recognition systems. For example, ``animal'' and ``vehicle''. They are not tied with the visual properties represented in their images directly, because there are many kinds of animals and vehicles which have various appearance in the real world. Generic image recognition systems should first recognize the concepts which have much visual properties.
So far, most of the work related to image annotation or image classification has either ignored the suitability of the vocabulary, or selected concepts and words by hand. The popularity of ``sunset'' images in this domain reflects such choices, often made implicitly. We propose that increasing the scale of the endeavor will be substantively helped with automated methods for selecting a vocabulary which has visual correlates.
Web images are as diverse as real world scenes, since Web images are taken by a large number of people for various kinds of purpose. This property is completely different from commercial or personal photo collections built by one or a few persons. It can be expected that such diverse images on the Web enable us to measure general ``visualness'' of a concept by analyzing Web images associated with the word concept.
To gather images associated with a certain word concept, we use Google Image Search as the first step. However, the precision of the results are not good in general, since Google Image Search rely on text associated with the images as determined from surrounding HTML data by a variety of heuristics. To select only relevant images to the given word concept from output of Google Image Search, we perform a probabilistic region selection method, and then we compute a measure of the entropy of the selected regions based on a Gaussian mixture model for regions. Intuitively, if such an entropy is low, then the concept in question can be linked with image features. Alternatively, if the entropy is more like that of random regions, then the concept has some other meaning which is not captured by image features.
To estimate ``visualness'' of concepts, we can use precision and recall diagram. However, to compute precision and recall, we need a ground truth set, namely, labeled images. In general, no labeled images are available for general ``X'', while ``image region entropy'' do not need labeled images or annotation of images by human at all. In that sense, ``image region entropy'' is a very useful measure to examine many kinds of concepts and compare their ``visualness''.
To investigate these ideas, we collected forty thousand images from the World-Wide Web using the Google Image search for 150 adjectives. We examined which adjectives are suitable for annotation of image contents.
To compute the ``image region entropy'' associated to a certain concept, we begin by gathering images related to the concept. While it is difficult to manually collect large numbers of images related to one concept, we can gather images likely associated to a certain concept using Web image search engines such as Google Image Search. Of course, raw results from the Web image search engines, usually include irrelevant images. Moreover, the images usually include backgrounds as well as objects associated with a concept. Therefore, we need to eliminate irrelevant images and pick up only the regions strongly associated with the concept in order to calculate the image entropy correctly. We use only the regions expected to be highly related to the concepts to compute the image entropy. To select regions associated with concepts, we use a probabilistic method.
To find regions related to a certain concept we use an iterative algorithm.
Initially, we do not know which region is associated with a concept ``X'', since
an image with an ``X'' label just means the image contain ``X'' regions. In
fact, with the images gathered from the Web, even an image with an ``X'' label
sometimes contain no ``X'' regions at all. So at first we have to find regions
which are likely associated with ``X''. To find ``X'' regions, we also need a
model for ``X'' regions. Here we adopt a probabilistic generative model, namely
a mixture of Gaussian, fitted using the EM algorithm.
In short, we need to know a probabilistic model for ``X'' and the
probability of ``X'' over each region, ![]() , simultaneously.
However, each one
depends on each other, so we proceed iteratively.
The detail of the algorithm to obtain
, simultaneously.
However, each one
depends on each other, so we proceed iteratively.
The detail of the algorithm to obtain ![]() is described in
[4].
is described in
[4].
After obtaining ![]() for each region,
we estimate the entropy of the image features of all the regions
weighted by
for each region,
we estimate the entropy of the image features of all the regions
weighted by ![]() with respect to a generic model for image
regions obtained by the EM in advance. It is ``image region entropy'',
which corresponds to ``visualness'' of the concept. To represent a
generic model, we use the Gaussian mixture model (GMM).
with respect to a generic model for image
regions obtained by the EM in advance. It is ``image region entropy'',
which corresponds to ``visualness'' of the concept. To represent a
generic model, we use the Gaussian mixture model (GMM).
We need to obtain a generic base in advance by the EM for computing the entropy. To get a generic base, we used about fifty thousand regions randomly picked up from the images gathered from the Web.
The entropy for ``X'' is given by
![]()
![]() where
where ![]() is the probability of
is the probability of ![]() -th component computed by
the formula of the Gaussian, and
-th component computed by
the formula of the Gaussian, and ![]() is the number of the
components of the base. In the experiment, we set 250 to
is the number of the
components of the base. In the experiment, we set 250 to ![]() .
.
Table 1 shows the 10 top adjectives and their image entropy. In this case, the entropy of ``dark'' shown is the lowest, so in this sense ``dark'' is the most ``visual'' adjective among the 150 adjectives under the condition we set in this experiment. Figure 1 shows part of ``dark'' images. Most of the region labeled with ``dark'' are uniform black ones. Regarding other highly-ranked adjectives, ``senior'' and ``beautiful'' includes many human faces, and most of ``visual'' are not photos but graphical images such as screen shots of Windows or Visual C++.
We show the ranking of color adjectives in the lower part of Table 1. They are relatively ranked in the upper ranking, although images from the Web included many irrelevant images. This shows the effectiveness of the probabilistic region selection method we proposed. Initially we expected that all of them were ranked in the nearly top, but they weren't. This is because all the images we used are collected from the Web automatically, and the test image sets always include some irrelevant images. So we could not obtain ideal results in this experiment. Note that the ranking varies if the condition of the experiment such as some parameters, image features and image search engine to gather Web images are changed.
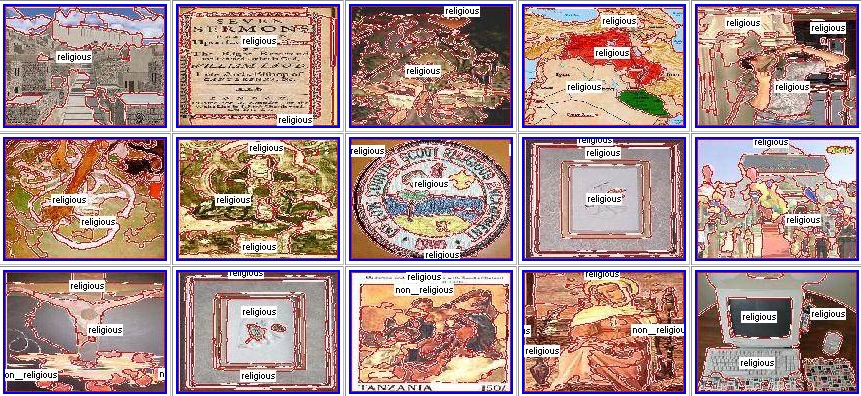
Table 2 shows the 10 bottom adjectives. In case of ``religious'' shown in Figure 2, which is ranked in the 145-th, the region selection did not work well and the entropy got relatively larger, since the image features of the regions included in ``religious'' images have no prominent tendency. So we can say that ``religious'' has no or only a few visual properties.
|
|
|
|
In fact, this result is not always consistent with our intuition, since region selection sometimes did not work well for some adjectives. As future work, we plan to improve the region selection method so that ``image region entropy'' represents ``visualness'' of concepts more precisely. As advanced work, we will develop an image annotation model to integrate nouns and adjectives by extending our image annotation models [1], and examine if adjectives improve image annotation task in which only nouns have been used so far.