2. DEFINITIONS
We present the definitions of key terminologies in this section.
Query Record: A query record represents the submission of one single query from a user to the search engine at a certain time. It can be represented as a set of triplets Ii = (qi, ipi, ti), where qi is the submitted query (i.e. terms), ipi is the IP address of the host from which the user issues the query, and ti represents the timestamp when the user submits that query.
Query Transaction: A query transaction is the search process 1) with the search interest focusing on the same topic or strongly related topics, 2) in a bounded and consecutive period, and 3) issued by the same user. It is represented as a series of query records in temporal order, i.e. Tj = {Ij1, Ij2, …, Ijm} = {(qj1, ipj1, tj1), (qj2, ipj2, tj2), …, (qjm, ipjm, tjm)} where ipj1 = ipj2 = … = ipjm and tj1 ≤ tj2 ≤ … ≤ tjm.
User Session: A user session contains the history of all query records that belong to the same user, in the query log. It can be represented as a series of query records in temporal order, i.e. Sk = {Ik1, Ik2, …, Ikn} = {(qk1, ipk1, tk1), (qk2, ipk2, tk2), …, (qkn, ipkn, tkn)} where ipk1 = ipk2 = … = ipkn, tk1 ≤ tk2≤ … ≤ tkn and n ≥ m.
Given these definitions, we have the following constraints:
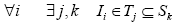 (1)
(1)
![]() (2)
(2)
![]() (3)
(3)
![]() (4)
(4)
3. LEVENSHTEIN DISTANCE SIMILARITY
Because search engine users often reformulate their input queries by adding, deleting or changing some words of the original query string, we use Levenshtein distance [3], which is a special type of edit distance, to measure the degree of matching between query strings. It defines a set of edit operations, such as insertion or deletion of a word, together with a cost for each operation. The distance between two query strings then is defined to be the sum of the costs in the cheapest chain of edit operations transforming one query string into the other. For example, the Levenshtein distance between "adobe photoshop" and "photoshop" is 1.
Hence the similarity between two queries can be measured by the Levenshtein distance similarity between them and defined as:
![]() (5)
(5)
where wn(.) is the number of words (or characters for Chinese queries) in a query.
The Levenshtein distance similarity is seldom applied to finding related queries because it retrieves only highly matching queries and thus fails to discover those related queries that are dissimilar in their terms, e.g. "search engine" and "google".
4. SEGMENTATION ALGORITHM
Our proposed model is based on the traditional association rule mining technique. For mining association rules of queries, we need to statistically measure the co-occurrences between queries in query transactions; so the quality of segmenting user sessions into query transactions is critical for mining related queries.
We developed a dynamic sliding window segmentation algorithm that adopts three time interval constraints, i.e. 1) the maximum interval length allowed between adjacent query records in a same query transaction (α), 2) the maximum interval length of the period during which the user is allowed to be inactive (β), and 3) the maximum length of the time window the query transaction is allowed to span (γ) (α ≤ γ ≤ β). It also sets a lower bound for the Levenshtein distance similarity between adjacent queries, i.e. θ, to justify the borders of query transactions. We empirically set the values of α, β, γ, and θ to be 5 minutes, 24 hours, 60 minutes and 0.4 respectively in our experiments. The complexity of this algorithm is O(n). Figure 1 shows the pseudo-codes for this segmentation algorithm.
|
Input:
A set of user sessions S
= {S1, S2, S3, …, Sn}
where Sk is a series of query records in
temporal order, i.e. {Ik1, Ik2,
…, Ikn} = {(qk1, ipk1,
tk1), (qk2, ipk2,
tk2), …, (qkn, ipkn,
tkn)}
Output: A set of query transactions T = {T1, T2, T3, …, Tn}.
Procedure SEGMENT
transaction set T
sort S in temporally ascending order for each Sk in S
transaction t
append t to T
timestamp of previous query
record tpre
start time of current transaction
t tcur_trans
for each Iki in Sk if tki - tpre ≤ α and tki - tcur_trans ≤ γ then append Iki to t else if tki - tpre > β then
t
append t to T append Iki to t
tcur_trans
else find the last query record Ilast_in_t in t, i.e. closest to Iki compare the query qlast_in_t of query record Ilast_in_t to the query qki of query record Iki if qlast_in_t ≠ qki then calculate similarityLevenshtein(qlast_in_t, qki) if similarityLevenshtein(qlast_in_t, qki) < θ then
t
append t to T
tcur_trans
end end append Iki to t end
tpre
end end return T |
Figure 1.Dynamic Sliding Window Segmentation Algorithm
5. MINING RELATED QUERIES
Our model is a modified-confidence version of the traditional approach of mining association rules. Here we define Q = {q1, q2, q3, …, qn} as the set of unique queries from query log files and T is the set of query transactions t. For each t there is a binary vector t[k] such that t[k] = 1 if query transaction t contains query record Ii that searched for query qk, and t[k] = 0 otherwise. Let X be a non-empty subset of Q. A transaction t satisfies X if for all queries qk in X, t[k] = 1.
The association rule is redefined to mean an implication X
![]() qj,
where X
qj,
where X
![]() Q,
and qj
Q,
and qj
![]() X. As we are interested only in finding related queries given an
initial input query, the set X contains only the initial input
query qi, i.e. X = {qi}.
Therefore the association rule in this problem becomes qi
X. As we are interested only in finding related queries given an
initial input query, the set X contains only the initial input
query qi, i.e. X = {qi}.
Therefore the association rule in this problem becomes qi
![]() qj,
where qi
qj,
where qi
![]() Q,
qj
Q,
qj
![]() Q
and i ≠ j. Mining related queries is simplified as finding
the statistical associations between the input query and any other
queries, hence.
Q
and i ≠ j. Mining related queries is simplified as finding
the statistical associations between the input query and any other
queries, hence.
The association rule qi
![]() qj
has a support factor of s if s% of the transactions in
T satisfy both {qi} and {qj},
notated as qi
qj
has a support factor of s if s% of the transactions in
T satisfy both {qi} and {qj},
notated as qi
![]() qj
| s. We define the raw confidence factor of the association rule
qi
qj
| s. We define the raw confidence factor of the association rule
qi
![]() qj
to be rc if rc% of the
transactions in T' satisfy {qj}, given that
T' is the set of all transactions in T that satisfy {qi},
and is notated as qi
qj
to be rc if rc% of the
transactions in T' satisfy {qj}, given that
T' is the set of all transactions in T that satisfy {qi},
and is notated as qi
![]() qj
| rc. Then we combine the raw confidence factor with the
Levenshtein distance similarity between qi and qj.
The final confidence factor of qi
qj
| rc. Then we combine the raw confidence factor with the
Levenshtein distance similarity between qi and qj.
The final confidence factor of qi
![]() qj
is calculated as:
qj
is calculated as:
![]() (6)
(6)
Assuming the input query is qi, we calculate the
support factor qi
![]() qj
| s and confidence factor qi
qj
| s and confidence factor qi
![]() qj
| c of any hypothesized association rule qi
qj
| c of any hypothesized association rule qi
![]() qj
(qj
qj
(qj
![]() Q,
i ≠ j). Then we first set a threshold min_support
for the support factors to filter away those association rules that are
not statistically strong enough. Next we rank the list of association
rules according to their confidence factors. Finally we select the top
K queries (if available) in the list and return
them as the most related queries to the input
query qi.
Q,
i ≠ j). Then we first set a threshold min_support
for the support factors to filter away those association rules that are
not statistically strong enough. Next we rank the list of association
rules according to their confidence factors. Finally we select the top
K queries (if available) in the list and return
them as the most related queries to the input
query qi.
The Levenshtein distance similarity is introduced as a non-penalizing decaying factor in (6), which is non-linear. We found that the traditional association rule mining model favors frequent queries and often fail to retrieve infrequent queries that are highly similar to the input query. The non-linear non-penalizing decaying factor promotes the positions of those queries in the ranked list without penalizing others significantly.
6. EXPERIMENTS
We have tested our method on a dataset collected from the query logs of Tianwang (www.tianwang.com) search engine. It covers 4 months from March 2003 to June 2003 and about 80% of the queries in it contain Chinese words. Approximately 14 million query records and 3 million distinct queries are identified.
We selected 100 test input queries randomly according to the overall frequency distributions. The frequencies of these test input queries range from 50 to 75,975 evenly. For each input query we selected the top 20 returned queries, if available, for experimental evaluations. Overall precision rates were calculated after the relatedness of retrieved queries was evaluated by a group of three human annotators.We compare our improved association rule mining model with three rivalry models including 1) temporal correlation model [2] (TCM) as the baseline, 2) association rule mining model [1] (ARM), and 3) our improved association rule mining model (ARM_LDS). We also compare our dynamic sliding window segmentation algorithm (DSW SA) with the naďve segmentation algorithm (Naďve SA) proposed in Fonseca, et al. [1]. The experimental results are presented in Table 1 below.Table 1. The Precision Rates of Our Experiment Results
|
Top K Queries |
TCM |
Naive SA |
DSW SA |
||
|---|---|---|---|---|---|
|
ARM |
ARM_LDS |
ARM |
ARM_LDS |
||
|
1 |
56.65 |
91.86 |
94.65 |
95.35 |
97.65 |
|
5 |
60.47 |
85.60 |
89.73 |
90.88 |
93.64 |
|
10 |
54.88 |
81.11 |
85.44 |
88.45 |
90.59 |
|
15 |
50.63 |
75.76 |
80.88 |
86.05 |
89.88 |
|
20 |
44.32 |
71.66 |
76.29 |
83.29 |
88.44 |
7. CONCLUSIONS
In this paper we propose a method of automatically discovering related queries from web search engine query logs. This method first segments the user sessions identified in query logs into query transactions, and then mines association rules of related queries using an improved association rule mining model which utilizes not only the co-occurrences between distinct queries but also the Levenshtein distance similarity between them. The experimental result shows that our method obtained approximate gains (in precision rates with K = 20) 17% and 44% compared with rival models and the baseline respectively.REFERENCES
[1]. B. M. Fonseca, P. Golgher, B. Pôssas, et al. Concept-based interactive query expansion. In Proceedings of the 14th ACM International Conference on Information and Knowledge Management (CIKM05), Bremen, Germany, 2005.
[2]. S. Chien, and N. Immorlica. Semantic similarity between search engine queries using temporal correlation. In Proceedings of the 14th International Conference on World Wide Web (WWW05), Chiba, Japan, 2005.
[3]. M. Gilleland. Levenshtein Distance, in Three Flavors. URL: http://www.merriampark.com/ld.htm.