Marcus Herzog and Riccardo Peratello
Information Systems Institute
Vienna University of Technology
A - 1040 Vienna, Austria
[herzog,peratel]@dbai.tuwien.ac.at
This paper analysis the concepts of digital archive applications on the World-Wide Web. We start by investigating the role of archives and related institutions for the preservation of cultural heritage. We then define services that will be expected from digital archives. We relate these services to current Web technology and discuss an implementation of a distributed digital archive currently under development in an European research project. Special emphasis is given on the application methodology, the user interface design, and the automatic generation process.
Archives have always played an important role as sources of information and knowledge. Their primary purpose is the preservation of important objects. For this end physical objects are collected and organized according to rules established by the archivists; hopefully to be found again when they are needed for consultation purposes. Archives usually contain diverse objects including textual documents (e.g., handwritten manuscripts), graphical objects (e.g., paintings and drawings),or three-dimensional objects (e.g., sculptures). In short archives are collections of artifacts.
Libraries are related institutions which can be assumed as special cases of archives, focusing on books and allied media as objects of interest. In contrast to archives libraries follow a well established procedure to organize items, and this organization is in general more detailed and documented than that found in archives. In archives only the archivists usually know where to find relevant objects.
A third type of organizations concentrating on the collection of items are museums. In contrast to archives museums very carefully select artifacts and present them to the interested audience. Museums sometimes have associated archives where objects not at display at the very moment are stored. Also the number of items kept in museums is usually much smaller than that found in archives.
What is the connection between the issue of digital archives and the Web in particular? Besides preservation the major problem in archives is the accessibility of records. First of all it is hard to locate relevant items in the huge number of collected items, or to understand if there are relevant records at all. Once one has located relevant records, the searcher has to go and fetch the record. A time-consuming and costly procedure, and sometimes not possible at all because of the sheer value or the physical condition of the record. And finally to work on original documents one has to stay at the archive. Digital archives are the solution to these problems. Digital material is easy to search on, easy to transport, and easy to work with.
Although there have been digital information systems long before the World-Wide Web project has come into existence the Web has brought a tremendous impetus into this field. Originally conceived as rather simple document representation and transportation mechanism the Web technology has evolved into a universal information space. The Web has demonstrated the power of networked information sources in combination with simple-to-use access mechanisms. A number of research initiatives such as the digital libraries initiative [4] will further explore the potentials of networked information.
Digital archives will be a major class of applications in this research field. In the reminder of this paper we will characterize digital archive services. We will discuss related technological issues and give concrete examples of an implementation currently under development in the VENIVA Esprit research project. Finally we will give some concluding remarks.
The primary service of digital archives is the guaranteed preservation of the digital material contained in the archive. This is of course a non-trivial task in the light of changing technology and continuous thread of technological obsolescence. In contrast to paper-based documents digital media can only be accessed in combination with matching reader software and underlying hardware environments. This is known as the ``refreshing problem'' [1]. A solution to this problem is the use of encoding formats that are independent of particular hardware and software implementations. Still such formats can only guarantee the conservation of the data per se, but not the software used to manipulate the data. To ensure the preservation of digital media, both digital information and software have to be transferred from one generation of computer technology to the next one, a costly and time-consuming endeavor.
Besides the preservation mechanism the promotion of access to the digital media is the most prominent service of digital archives. Means of access are highly different from conventional archives. Through the usage of digital technologies all kinds of media (e.g., text, picture, video, audio) are converted into bit-streams that can be easily transported over digital media channels. Moreover, not only original material but also all associated meta information (e.g., descriptions, catalogues, indices) can be uniformly accessed in the resulting information space. In a distributed network environment such as the World-Wide-Web access is available from every connected point, leveraging the accessibility of the stored material. Digital archives can serve much larger user communities than traditional ones. Only such a large audience can justify the costs of large scale efforts.
On the other hand the ability of nearly universal access calls for a very deliberated approach to access control. The fear of copyright infringement is on top of the list of all stakeholders. This is of course not a sole technical problem but much more a legal one. As long as the copyright laws tend to reflect the properties of the analogous world no technical approach such as watermarking [5] or other forms of authentication can solve this problem. Digital archives thus need to formulate and implement policies and practices for copyright clearance and intellectual property rights management including mechanisms for transactions between right holders and buyers.
Providing access to digital archives also includes appropriate search and retrieval capabilities that help to locate relevant items in the large digital repository. To this end search mechanisms rely on information on the content of the archive items in machine readable form. Both generation and exploitation of meta information in the retrieval process are subjects of active research in computer science. At large there are two different approaches: automatically (e.g., inverted index) and manually (e.g., keywords) generated descriptions. While automatic generation is well established on text-based documents it is less probed on image, audio, or video information. For automatic processing each type of media requires its own feature extraction mechanism to receive meaningful descriptions and often the resulting mechanisms are bound to certain media characteristics. Manual descriptions usually use media-independent high-level concepts to characterize items. The disadvantage is that the manual process is less objective (due to human judgment) and complete than the automatic one.
On top of these basic services a number of ``added-value'' services can be defined and implemented. Added-value services reflect the individual purpose of the digital archive. A simple example of such a service might be the ability to print the selected documents found in the archive. More advanced services would include possibilities to personalize the archive through annotation services. Added-value services will be tailored to the necessities of different user groups and security levels. Implementations of digital archives need to provide an interface layer which enables extern services to communicate with the core archive service to retrieve digital objects. The presentation of these objects can then be in the realm of the external services.
We will now discuss technological issues relevant for the implementation of digital archives as described in the previous section. We will relate the discussion to current Web technology. What exactly do we understand by Web technology? The core technology is the definition of the HTTP protocol and the HTML document description language together with server and client software implementations. During the last years numerous extensions have been proposed. Current Web browser software supports scripting and programming facilities, exceeding the capabilities of first generation client software by far. Also server software capabilities can be extended by, e.g., use of the CGI interface. This shows that there is no clear-cut boarder of Web technology. Instead one could speak of Web-enabled technology.
If we speak of persistent storage as primary goal of digital archives it is clear that core Web technology does not provide means to this end. If we regard the Web as a repository of digital objects we have a rather high flux with no means to track the life-cycle of individual objects. There is neither the ability to assign unique identifiers to digital objects nor to support structured objects beyond the specification of HTML. HTML does not allow for the storage management of objects themselves but for a certain limited presentation of those objects. Digital archives thus rely on additional facilities to manage persistent storage.
The same holds for search and retrieval facilities. Still a large amount of research work has been done on these subjects in the line of Web technology. Search engines are a major topic in Web research. This might stem from the need for organization and finding aids in the rather chaotic ``Web repository''. Both manual (e.g., Yahoo) and automatic index mechanisms (e.g., Altavista) are in use. So far automatic indexing is mostly limited to text-based mechanisms with some support for structure-based searching (e.g., searching for information in titles of pages). No broadly applicable concept for meta information generation has been devised. This is still a topic of further research.
The strongest impact of Web technology can be found in the information presentation and dissemination aspect of digital archives. The Web has demonstrated the possibilities of networked document access mechanisms. Through the hyperlink concept supported in a simple document format large amounts of networked information have been generated in a short time. The Web has shown a tremendous growth rate and Web services account for the largest amount of network traffic today [3]. The strength of Web applications is the independence of hardware configurations coupled with their distributed nature. Web applications have the potentially to reach all users on the Internet. The Web has set the standard that allows the building of front-end interfaces to general networked information system applications. With the support for Java applets in Web Client software the capabilities of these front-end interfaces are further extensible.
To summarize, Web technology is important to digital archives as information transport mechanisms. Digital objects residing in digital archives can be composed to documents using HTML and can be transported using HTTP. Furthermore the front-end user interface to the archive application can be based on HTML, thus ensuring a uniform access mechanism independent of hardware and software operating environments. Digital archives play an important role to ensure the longevity of digital information. The Web supplements this technology in terms of accessibility and transport of information over the network.
The VENIVA (Venetian Virtual Archive) Esprit project [6]aims both at the development of digital archive technology as well as on large-scale digitizing trial efforts on historical documents. Partners in the project include archives, research institutes, publishing and software companies. The digital archive will span three archives, physically located in Austria, Italy, and Greece, containing historical documents on the Venetian State dating from the 15th century to the early 18th century.
The rational behind the project is the idea to bring virtually together material now situated in geographically disperse location and make it accessible to researchers, scholars, and publishers world-wide. This would allow for an accessibility that has never existed before, including the following advantages:
The digital archive is implemented in a relational database. To this end a data model covering both archive and library needs has been developed. We use the MEM [2] methodology to model the hypermedia presentation of the relational data model. The MEM methodology comprises the following steps:
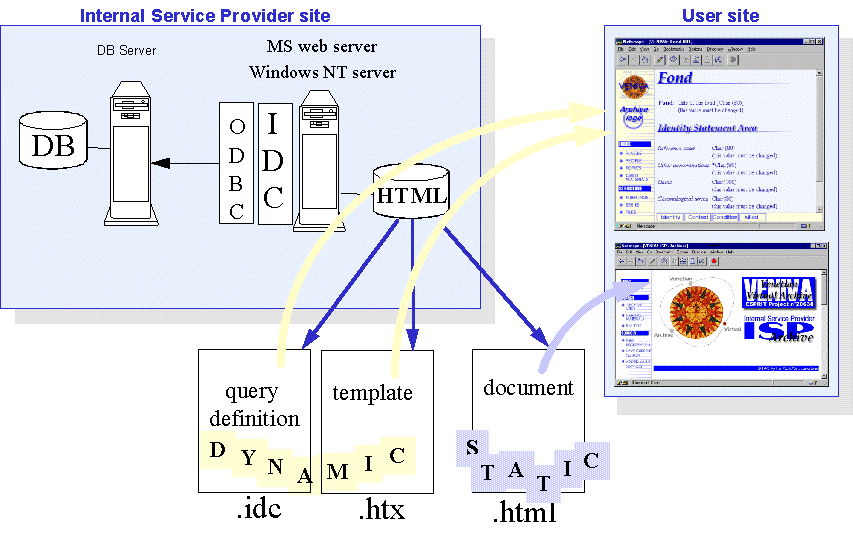
The MEM methodology for the design of hypermedia applications is supported by a number of tools. The HyxSchema editor allows for the modeling of a hypermedia application according to the MEM methodology. The output of the HyxSchema editor is a relational database holding information on the entities and relationships of the hypermedia application. The HyxInstance editor is used to instantiate this database. The HyxScreen editor supports the definition of user interfaces for the hypermedia application. The HyxMapper&Generator application takes the specifications of the hypermedia application schema, the instances, and the user interface definitions and generates the corresponding HTML application. Figure 1 shows the schematic transformation of the MEM model to the HTML interface documents.
Within the VENIVA system architecture two conceptual service classes have been defined: internal services and external services. Internal services reflect the usual functionalities found in archives and archive reading rooms. External services are tailored for value-added third-party providers. Through this services external publishers can ,e.g., acquire copy-rights of certain digital objects and retrieve them for usage in their electronic publications.
There are two basic classes of interfaces: the Information Management System (IMS) and the VENIVA Accessing System (VAS). The objective of the IMS is to manage the data at each individual archive site in the network. The data will then be replicated throughout the network. The VAS handles the interaction with archive users. The functionalities include user registration, navigation and search capabilities, and object interactions such as printing or high-quality reproduction ordering.
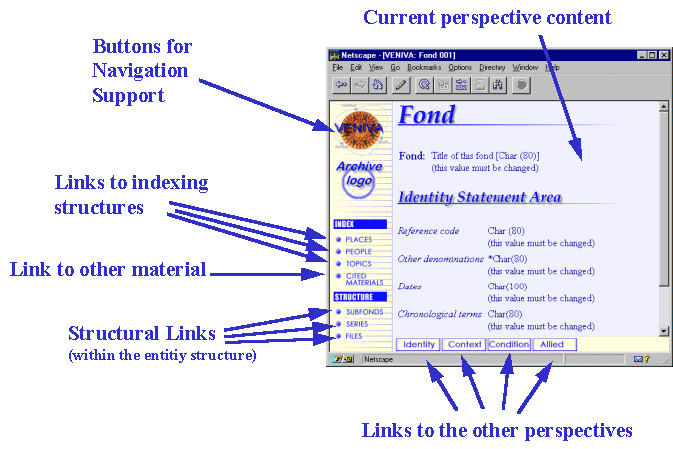
Figure 2 shows a screenshot of the VAS interface. The display is structured in two panels: the navigation panel on the left-hand side and the content panel on the right-hand side. The structure of both the navigation and the content panel is defined in the MEM model. The HTML pages representing the interfaces are generated automatically applying the mechanism depicted in Figure 3.
On top of the navigation panel the Buttons for Navigation Support provide the basic navigation facilities to navigate between the distributed archives. Below that, links to indexing structures concerning Places, People, and Topics can be followed. The Link to other material points to digital archive objects that are referenced through the description displayed in the content panel. The Structural Links represent the hierarchical model of the archive content description, including Fonds, Subfonds, Series, and Files. The File is the smallest structural collection of individual digital objects. This model follows the structuring schema of conventional archives.
The content panel displays both the description of digital objects and the digital objects themselves. It is a seamless integration of meta-information and the actual information through the usage of hyperlink capabilities in the interface. At the bottom of the content panel, four buttons represent available perspectives on the information. This perspectives structure the descriptive information in four categories: Identity, Context, Condition, and Allied. Identity gives the information necessary to uniquely identify each individual object in the virtual archive. Context gathers the information on the historical context of the object. Condition talks about physical characteristics of the object and Allied points to related material in the archive.
All interface documents are generated automatically using the MEM methodology and the accompanying tools. This guarantees a consistent and complete presentation of the content of the digital archives. The underlying data model is extensible, ensuring the capability to cope with needs of individual archives. We are currently testing the usability of these interfaces in the individual archives.
The rise of the information society places a new demand on our ability to preserve the cultural memory that becomes digital in an ever increasing rate. All audio recording uses digital technology and video is on the move to follow up. Numerous digital repositories are coming into existence without a clear concept how they can be preserved for future generations. On the other hand a large amount of records stored on analogues media are endangered due to the limited life-time of their physical existence. Digital storage techniques can solve both the access and the preservation problem of conventional archives.
Digital technology, however, does not come for free. How can the high cost associated with large digital archives be justified? The key to this question lies in the accessibility of material. Generating material from scratch is very expensive. If material needed is already available in digital format and ready to be re-used (both on a technological as well as legal basis) costs for archiving will be justified. Moreover, if the potential user community is world-wide the demand will be high enough for a self-sustaining process.
Research in this field will be very active in the years to come. The World-Wide Web has initiated research through the demonstration of the potential of networked information systems. Although the underpinning technology will eventually change, the spirit of the Web will remain.
This work has been partially funded by the EU Commission under Esprit contract Nr. 20638. The authors would like to thank all members of the VENIVA consortium for their contributions to the project.
A Postscript version of this paper is available at
http://www.dbai.tuwien.ac.at/ftp/papers/herzog/WWW6.ps.gz