
This paper presents a mixed-initiative Browse Guide that assists a person browsing the Web. The Browse Guide operates proactively in real time to construct a dynamic conceptual index of documents visited by the browser and documents from the immediate neighborhood of those documents. The conceptual index is a hierarchically organized taxonomy of word and phrase concepts found in the indexed material. The Browse Guide provides tools to query and browse the incrementally-built conceptual index, which can be seen as a sophisticated "bookmark" structure linking concepts found along the path with the places where they occur. The evolving conceptual index provides two important functions: (1) an automatically assembled conceptual logbook of the user's path through the Web and (2) a facility for conceptual "peripheral vision" that displays concepts in documents one step ahead of the browser while navigating the Web. Early uses of this tool have shown it to be a powerful adjunct to existing Web search engines as well as a way to structure a personal bibliography of explored web pages.
This paper starts with a brief introduction to conceptual indexing and then describes the Browse Guide and an example of its use. It concludes with a discussion of usage patterns of the tool and a few thoughts for future work.
Conceptual indexing of text involves:
For example, if we encounter a phrase "graphic workstation," we may need to look up "workstation" in the lexicon, learn that it is a kind of "computer," and thus assimilate the relation "workstation" ISA "computer" into the taxonomy. The process may recurse on "computer" to uncover more general relationships, all of which are added to the taxonomy. Thus the phrase "graphic workstation" builds the following taxonomy fragment (neglecting for simplicity any concepts more general than "computer"):
computer
|-- workstation
|-- graphic workstation
This example presents a portion of the taxonomy as a tree structure,
with more specific concepts indented under their more general parents.
Note that the taxonomy does not contain all of the information from the
lexicon, but only the information for words and concepts extracted from
the indexed text or from other phrases assimilated into the taxonomy.
After indexing a collection of text, the taxonomy recorded for the concept "computer" might look like:
computer
|
|-- new computer
| |-- recent toshiba laptop
|
|-- toshiba computer
| |-- recent toshiba laptop
|
|-- workstation
| |-- graphic workstation
|
|-- server
| |-- web server
| | |-- www server
| |
| |-- sun's new netra-j server
|
|-- laptop
|-- recent toshiba laptop
Please note how some of the subsumption relations come from the lexicon:
computer |-- workstation |-- server |-- laptopand
new |-- recentwhile others from structural relationships in phrases:
workstation |-- graphic workstationand still others from a combination of structural and lexical evidence:
new computer |-- recent toshiba laptopGlancing at the tree of the "computer" taxonomy, a user will get a good idea of what is to be found in the underlying documents on the topic of computers. This is similar to walking up to a shelf in a library and, in addition to finding the book we came for (or not finding it), finding other books on similar topics that may attract our attention. Perhaps one of the other books will better meet our needs. Whereas the organization of a library translates topical proximity into physical proximity, the conceptual taxonomy display automatically provides similar groupings, with more conceptual organization and without the one-dimensional constraints of a physical bookshelf.
The taxonomy also aids in formulating queries. In querying the index, terms are treated as concepts and are expanded by their more specific children in the taxonomy. So, for instance, a query for a "fast computer" will also be looking for "fast graphic workstation" because "graphic workstation" is a more specific form of "computer." Moreover, a search for "new Japanese computers" would also find mentions of "recent toshiba laptop." Although all the words in "new Japanese computers" are different from the words of "recent toshiba laptop," a user who formulated his query at a general level will undoubtedly recognize the finding of "recent toshiba laptop" as a perfectly valid and even an obvious one.
This last example illustrates how conceptual indexing can provide a partial solution to the "paraphrase problem," which occurs when a query uses quite different terminology than the documents being searched. The conceptual taxonomy is also useful in other ways to help refine and sort hits that result from queries [Woods2].
The taxonomy is displayed as one or more Active Views which are updated dynamically as the index expands. An Active View may be either:
Active Views have controls that let them create other Active Views. For instance, an Active Query may be created to display continuously a list of hits for a concept extracted from a Concept Browser. Active Views can also direct the browser to display a particular document.
Concept Browsers have controls that tailor the information they present. The user may change the selection of "root" concept that the browser displays. The user may also request that certain concepts and their descendants not be displayed. For instance a concept of a "mainframe" may be pruned from the "computer" taxonomy. The display will continue to show information about workstations, servers, and laptops, but no more mainframes. These tools allow a user to select just those parts of a taxonomy to track during a browsing session.
Active Queries have similar pruning controls. In a session with an Active Query, a user may "delete" a query hit in order to make room on the display for other high-scoring hits.
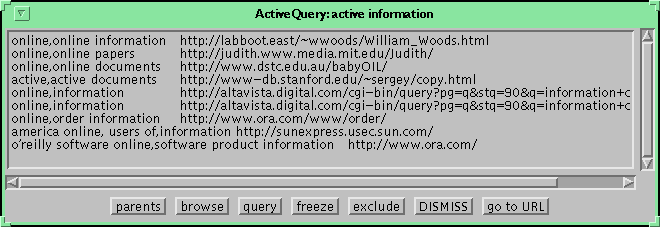
This is an example Active Query for "active information". The window shows a list of top-rated hits. Each line contains concepts on which the query matched, and URL location of the hit. The user may select a URL and press "go to URL" button to make the Navigator display the page with the hit. The page might have already been visited by the user or only proactively scanned by the Guide.
As an illustration, a user interested in the topic of "cryptography" accessed AltaVista using Netscape Navigator and the Browse Guide. The taxonomy displayed by the Concept Browser:
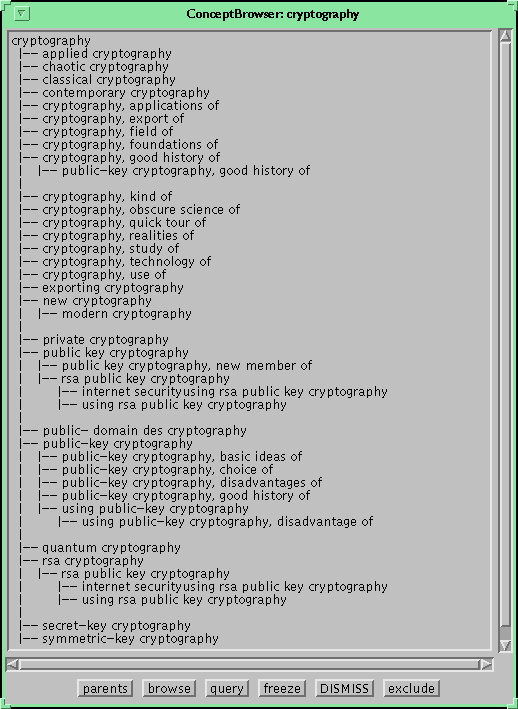
In response to the "cryptography" query, AltaVista returned a response page with 10 hits, each a hyperlink to a relevant document, and a link to more hit pages. Within a few seconds of receiving this results page, the active view for the "cryptography" taxonomy was automatically updated to include the new information from the hit pages themselves. Any concept in this taxonomy that attracts the user's attention can be used by the Guide to make Netscape jump to the page or pages that contain that concept.
Conceptual bookmarks. The Browse Guide is a convenient way to organize information for a specific topic of interest to either a person or a group project. The Guide can be saved for later reference or augmentation by additional Web searching. Or a person interested in cryptography might obtain a copy of a cryptography guide collected and edited by an expert. Guides are thus a form of structured bookmarks for organizing reference information. One could imagine augmenting a Web site with a conceptual index of that site, allowing visitors a different way to find information embedded within the site's web.
The Browse Guide is an example of a mixed-initiative tool: the user provides important information, but the tool is operating somewhat autonomously as well. It has the feeling of an assistant who is keeping a constant index of your travel through the Web. And because you are steering the search, the taxonomy is rich in concepts you care about; the amount of "noise" in the index seems small and unintrusive.
The technology underlying the Browse Guide can also be refined. The current indexing software was designed for batch indexing, and requires some reworking to do efficient incremental work.
Finally, there may be ways to direct the initiatives of the Guide. It performs "research" on behalf of the user by proactively visiting text pages accessible in one step from the current page. We hope to investigate different strategies for exploring the hyper-neighborhood. For example, it may be possible to recognize patterns of links in pages and use different strategies in different cases: search results, document table of contents, home pages, etc. Other systems have ideas to offer in this regard [IBM, Lieberman].
Much of the appeal of the Browse Guide appears to stem from its mixed-initiative character: the user is charting the direction of exploration, but the Guide is providing a concise map of detail that a human can obtain only by lots of tedious "clicking around," scrolling, and skimming.
[Keller] Arthur M. Keller, "CommerceNet Smart Catalogs," http://cit.stanford.edu/cit/commercenet.html
[Lieberman] Henry Lieberman "Letizia: An Agent That Assists Web Browsing," International Joint Conference on Artificial Intelligence, Montreal, August 1995 http://lcs.www.media.mit.edu/people/lieber/Lieberary/Letizia/Letizia.html
[Woods1] William A. Woods, "Understanding Subsumption and Taxonomy: A Framework for Progress," in
John Sowa (ed.), Principles of Semantic Networks: Explorations in the Representation of Knowledge, San Mateo: Morgan Kaufmann, 1991.
[Woods2] William A. Woods, "Conceptual Indexing: a better way to organize knowledge,"
forthcoming technical report, Sun Microsystems Laboratories. See also
http://www.sunlabs.com/research/knowledge