
Rainer Puittinen
Mika Silander
Eero Tervonen
Juho Nikkola
Ari-Pekka Hameri
Helsinki Institute of Physics,
FIN-02150 Espoo, Finland,
and
CERN, Division PPE,
CH-1211 Geneva 23, Switzerland.
Phone: +41.22.767.6195,
Fax: +41.22.767.3600,
Email: {puittinen,silander,tervonen,nikkola,hameri}@cern.ch.
The original spirit of the World Wide Web is losing ground to a diversity of information technology solutions that utilize the underlying common protocols but fail to share a common user interface. We present a lightweight and modular system that provides users with a uniform way of finding, accessing, storing and monitoring usage of documents regardless of their physical storage system: a WWW server, a proprietary electronic document management system, or a database. The concepts presented in this paper are validated in real-world case examples that show the diversity of environments where our system is applicable.
WWW, uniform access, document management, Computer Supported Co-operative Work.
Consider the fact that the World Wide Web emerged from the field of high energy physics. In this field, heterogeneous collaborations form to build scientific instrumentation in a scale that would not be reachable by any nation alone. The organization in such projects resembles a bring-a-dish party. Everyone who joins the convention is expected to bring something voluntarily. Typically the contributions are based on latest research and technical development results, and further innovations are being made even when the party is warming up. It is then essential for each partner to provide others with current information on the status of its activities. Collaborative work of this kind is very difficult without universal low cost access to information across information technological borders.
For instance, a considerable amount of engineering data is available from the WWW at CERN. Several design groups use the Web extensively for these purposes. In most of these cases, remote data is input via ftp into separate Internet addresses, from where the files are the transferred to the right places by the administrators [1]. In addition, new links are created and new browsing structures are created as the needs emerge. As anybody experienced in creating and maintaining WWW sites, these tasks are rather laborious, and each and every group has its own ideas about how to arrange these sites.
Now that the technology has matured for utilization in the commercial sectors, many unsolved and tricky questions still remain related to organising, maintaining, and sharing the universally accessible information in a systematic way. A lot of effort is being allocated to building WWW interfaces by engineering data and document management system vendors. As a result, proprietary interfaces or WWW add-ons are emerging, which are based on the core technologies of the WWW. Due to commercial reasons, the WWW implementations look very much like their non-WWW versions and thus appear to users as incompatible as the pre-WWW era applications themselves. It seems that a maximum in accessibility has been passed and the original spirit of the WWW as a tool for uniform access to heterogeneous information is quickly fading.
It is within the scope of this article to study alternative and practical solutions that would revive the WWW as a global groupware, where documents can be exchanged across geographical and organizational boundaries. At the same time, the information structure should be clear and easy to maintain in order to achieve coherence of information. From the user's point of view, attention paid to detailed features of different storage systems is unwelcome. At CERN, for example, engineers', physicists', and managers' interest is to leave system specifics in the background and concentrate on working with their documents. Thus the main concern is to ensure
We feel that the divergence in interface design needs to be counteracted with a universal access tool that can replace or augment the vendor specific front-ends. Therefore we have decided to build a lightweight and modular system that can provide a universal WWW interface to engineering information regardless of the physical storage system that actually hosts it. The system consists of modules that bring a selected set of generic functions available on the WWW, thus separating the users from the underlying storage system specifics. We target our system as a working tool for heterogeneous, distributed working environments, not as a casual browsing tool for the World Wide Web.
Experience has shown that in most cases it is wise to classify users of Engineering Data Management Systems (EDMS) into several categories. From our point of view the most important ones are:
It is, on the other hand, clear that the usage of EDM systems can be segmented into basic functions for documents and their organisation:
The user classes presented above clearly have different requirements. We will try to map them onto system functionality and architecture as presented in the rest of the paper. We feel that the mapping, presented schematically in Figure 1, makes it evident that a number of separate issues and priorities exist in making a set of generic functions accessible on the WWW.
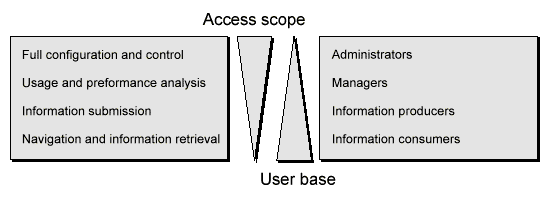
Figure 1. User base classification and the respective requirements.
The user base greatly expands toward the bottom of Figure 1. In a distributed environment, only a small fraction of users will ever be allowed to configure and control the system. The vast majority of users map under one or both of the last user categories. Their need for a universal interface that separates them from the diverging, and possibly confusing, features of various EDM systems needs most attention.
We start the rest of the paper by defining data models and functional requirements for a set of generic operations that should be accessible regardless of the actual information storage system. We will then continue to describe our system's architecture and focus on its modularity - the roles of the various modules and the relations between them. The two final chapters discuss a number of system implementations according to the different needs of our pilot projects and the lessons one should learn from them in future WWW software development.
Our work started out from the document management needs of an engineering community. From the start it was apparent that a flat data model was not enough for managing the mass of documents in large engineering undertakings. Thus we chose do adopt a layered data model in order to provide means for dealing with documents at different levels of granularity:
The purpose of the layered and hierarchical data-model is to deal with Documents in terms of higher-level, familiar abstractions like folders or work packages. Distributed hierarchies of Collections can be defined on top of the layered document model to build complex data models. These are useful for organizing Documents into parent-child relationships such as a product breakdown structure (PBS) [2]. Collection hierarchies are defined manually or as results of queries on Collection attributes.
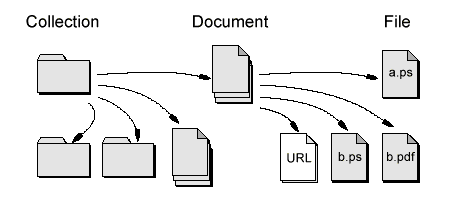
Figure 2. Three level data model: Collection, Document, File.
Meta-data play a central role in the system. The three level data-model described above is reflected in meta-data that we attach to Documents and Collections. Furthermore, the runtime binding of program modules is defined by the meta-data. One could say that the system is 'meta-data driven' since the meta-data attached to an entity specifies the modules that will be used to manipulate the entity and the meta-data itself. In this respect, the system can be considered object oriented.
Two kinds of meta-data can be attached to a Collection or Document entity. A set of fields have been pre-defined to carry system specific information and provide a basis for the meta-data driven functionality. These static fields are always present. They are described in more detail below. Based on the static fields a set of dynamic fields can be appended to the meta-data.
Some of the static fields can be used as selectors for defining a set of dynamic fields. A dynamic field definition consists of a field name, its type, a range of allowed values and ordering among other dynamic fields. For example a Document of type "Publication" might contain the dynamic field "Author" of type string with allowed value "not empty" that is defined as a regular expression.
The role of meta-data in runtime module binding is to specify the external link layer for accessing an external information storage system.
Functionality of the system is geared towards the user classes defined above. Functionality can be grouped similarly into two categories according to whether a given function targets a Collection or a Document.
The functionality for Collections is mainly used by system administrators who are in charge of maintaining the document model structure. Although the typical information consumer will browse the collection hierarchy quite frequently, functionality for managing collections will be used by only a small user group:
Documents are the entities that typical users will manipulate most. Thus it is natural that most system functionality is bound to them. The core set of functions on Documents is defined by the initial user requirements:
A unique degree of freedom is built in to the universal access interface. Since the Document identifier determines how the attached Files should be accessed, the actual physical storage system can be chosen individually for each Document. Thus a view to a particular Collection may freely mix Documents that are hosted by a WWW server and those that are stored in a proprietary EDMS. The advantage of this freedom is obvious, for example, when a drawing database is made visible to the WWW. Even in the case that the database only accepts files in some proprietary format, the universal access interface allows one to add other types of documents (notes, specifications, test reports, etc.) by using the WWW server for alternative storage.
The list of functionality presented above is just a core set of the full set of functions that are available in most, if not all, EDM systems. In our view, however, it represents well the functionality that is relevant to the majority of users.
The most important factor in designing the present system architecture is modularity. The system consists of Authentication, Access control, Operation dispatcher, Subsystem, and External link layer modules. Their relations are illustrated in Figure 3.

Figure 3. Schematic drawing of the TuoviWDM modular architecture.
Every user of the system has to authenticate himself so that the access to system functionality can be verified. User authentication is taken care of by the WWW server's authentication mechanisms.
Access to system functionality is managed by the TuoviWDM. The meta-data of each Document and Collection records which operations different types of users (owner, group, guest) are allowed to carry out. The access control module dynamically assigns the user an access right vector according to his type (authenticated, guest) and the groups he belongs to. When an operation is requested, the vector is searched for the corresponding tag. If the tag is found, the operation can be completed, otherwise it is blocked.
Accepted operations are forwarded to an operation dispatcher module. It takes care of loading the appropriate subsystem modules according to the meta-data attached to the specified entity. Once the appropriate modules are in place, the request is forwarded to the subsystem level. Typically only one subsystem is active at any given time. It is the operation dispatcher that provides a framework for easy system extension. The runtime binding of subsystem modules keeps every given instance of the system light.
Generic system functionality is implemented by the following subsystems:
The search subsystem builds views to stored information by collecting entities based on their meta-data attributes. For queries that span multiple collections, the subsystem uses the glimpse search engine for picking up the appropriate documents from different branches of the collection hierarchy.
The presentation subsystem is the part users see. It translates query results, collection contents, and various views into HTML pages and specifies a page layout. The presentation subsystem also implements a meta-data editor that enables users to edit meta-data attributes provided that the document's access rights do not prevent it.
The file upload subsystem takes care of attaching Files to Documents. The upload subsystem is also responsible for detaching Files from Documents. The upload feature uses standard multi-part MIME encoding that has been implemented by Netscape in their Navigator since version 2.
The meta-data subsystem maps user functions to operations on document meta-data. Consider as an example the user action "Put file", which translates to meta-data operations "add file name, type and size to Document meta-data" and "adjust Document modification time and modifier".
The Collection hierarchy subsystem is responsible for maintaining the Collection hierarchy tree. We have implemented a simple tree editor, which is very similar to the editor used in the presentation subsystem. Adding, deleting, and editing of Collections imply modifications to their meta-data.
Meta-data and associated files have to be stored physically on either the WWW server file system or in an external document storage system. The purpose of the external link layer is to provide an abstraction to them. It reads Files from, writes them to, and updates meta-data on local and external systems. The pilot implementations next demonstrate the use of several external link layers.
In this chapter we document some of the currently active implementations of our universal interface. Some implementations originally started as pilot projects, but they are all now used as the principal working tool in the respective projects. We start with an introduction to our original target, a WWW server based document management system for a small distributed collaboration. This is followed by descriptions of later implementations according to varying needs.
About 20 physicists and engineers from CERN and two national research institutes developed a functional prototype of one detector subsystem for technology evaluation in one of the LHC experiments. They needed a universal interface for managing documents and accessing them through a single URL. Previously, the documents were made available through manually edited HTML pages that were not necessarily up to date. The project now uses the system as a daily tool for storing and retrieving design documents. The WWW server's local file system is used as a document repository, and the system hosts approximately 100 MB worth of design information.

Figure 4. The TuoviWDM universal interface used by a sub-detector collaboration.
Concurrently with the development and deployment of our original implementation, CERN was evaluating EDMS technology for supporting the enormous design efforts associated with the LHC accelerator and its experiments. One commercial system was selected for further reviews in three separate pilot projects. However, a WWW interface was not available as the EDMS vendors are, in general, just in the process of building them to their products. Thus we launched an effort to connect the TuoviWDM to the piloted proprietary system. The work was carried out rather quickly but it was not totally painless. The vendor was cooperative, but information on technical details was never obtained.
The problems were overcome, however, and our exercise resulted in an improved toolset, which can provide a universal access and easy navigation to a proprietary EDMS from the WWW. Considering the three EDMS pilot projects, the WWW access eventually turned out to be one of their main success factors.
Naturally, the access system provides only a subset of the full functionality that will later be provided by the vendor's own WWW interface. Our opinion is that even once the full interface exists, the vast majority of the user base will be best served with a relatively simple universal access tool like the TuoviWDM. This would, for example, allow a new project to start with a WWW server based system and transparently move to a larger capacity storage system later.
Some of the CERN specific engineering functions depend on an electronic drawing repository with formal approval procedures. Euclid and Autocad are the main tools for creating technical drawings and the repository is based on an Oracle database. The system converts the original images into HPGL format for the approval procedure and they are organized according to the product structure. The TuoviWDM is connected to the database through SQL, making the documents universally accessible and retrievable from the WWW.
Because the system can store URLs as special Documents, it can be used for archiving links to CGI URLs that retrieve drawings from the drawing repository. For example, if specification documents for a particular project are hosted by TuoviWDM, related drawings can be accessed through CGI URLs.
One of the LHC experiments uses the universal interface for making the Project Breakdown Structure (PBS) visible to the whole collaboration. This implementation of TuoviWDM takes advantage of the collection hierarchy module for navigation and modifications to the structure, which is stored on the WWW server's local filesystem.
Easy universal access to the most current version of the PBS encouraged the pilot project to require more comprehensive project management capabilities. Thus, in order to collect schedules and resource estimates, a number of user defined meta-data fields were defined at Collection level. These can be used to store the scheduled dates and planned resources of the project, for example. Presently, the system collects project break-down information for the global collaboration. Additional benefit from this user driven development effort has been the enhanced meta-data handling capabilities of the current system.
We emphasized at the beginning that global scale is hard to avoid. Thus we felt that the universal interface would be a limb unless Collection hierarchies could be distributed among several WWW servers as naturally as Documents can be distributed among different storage systems. A pilot case for this extended concept is our own home institute, Helsinki Institute of Physics (HIP), which runs a number of research projects both in Helsinki and at CERN in Geneva. The distributed system piloted by one of the HIP projects consists of two independent WWW servers, one each location. Basically, the only extension that was needed was the modification of the Collection hierarchy subsystem to fetch remote information at runtime.
The first level of distribution is implemented through queries that span multiple TuoviWDM installations. The second level consists of linking Collections to remote TuoviWDM installations.
The development team of TuoviWDM is using the same toolset for archiving and distributing documents within the project. Meeting minutes, system definitions, visit reports etc. are available through the universal interface.
Our experience has shown that there is a clear need to revive the original spirit of the WWW and provide users within distributed collaborations with a uniform way of navigating, finding, accessing, and uploading documents through the WWW. The issue of diverging WWW technologies needs attention. We have proposed a solution that separates a set of generic document management operations from the features of the actual storage system.
Rainer Puittinen graduated from the Department of Computer Sciences at Helsinki University of Technology in 1996. He is currently a postgraduate student with the Helsinki Institute of Physics pursuing his PhD studies in distributed data management and online project support software.
Mika Silander is a graduate student with the Department of Computer Sciences at Helsinki University of Technology. He is working with the Helsinki Institute of Physics on distributed data management and online project support software.
Eero Tervonen received his PhD degree from the Department of Technical Physics at Helsinki University of Technology in 1994. Since then, he has been active in applied physics research and, most lately, in information management and visualization techniques with the Helsinki Institute of Physics.
Juho Nikkola received his MSc degree from the Department of Industrial Management at Helsinki University of Technology in 1990. He is currently a project manager with the Helsinki Institute of Physics and concentrates on large scale document management .
Ari-Pekka Hameri received his PhD degree from the Department of Industrial Management at Helsinki University of Technology in 1993. Since then, he has headed the Institute for Industrial Automation with HUT and a technology program with Helsinki Institute of Physics.