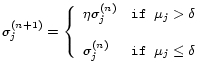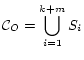
|
In general, for any given topic (e.g., a product), there are often two kinds of opinions: the first is opinions expressed in some well-structured relatively complete review typically written by some expert about the topic and the second is fragmental opinions scattering around in all kinds of sources such as blog articles and forums. For convenience of discussion, we will refer to the first kind as expert opinions and the second ordinary opinions. The expert opinions are relatively easy for a user to access through some opinion search website such as CNET. Because a comprehensive product review is often written carefully, it is also easy for a user to digest expert opinions. However, finding, integrating, and digesting ordinary opinions pose significant challenges as they are scattering in many different sources, and are generally fragmental and not well structured. While expert opinions are clearly very useful, they may be biased and often out of date after a while. In contrast, ordinary opinions tend to represent the general opinions of a large number of people and get refreshed quickly as people dynamically generate new content. For example, a query ``iPhone'' returns 330,431 matches in Google's blogsearch (as of Nov. 1, 2007), suggesting that there are many opinions expressed about iPhone in blog articles within a short period of time since it hit the market. To enable a user to benefit from both kinds of opinions, it is thus necessary to automatically integrate these two kinds of opinions and present an integrated opinion summary to a user.
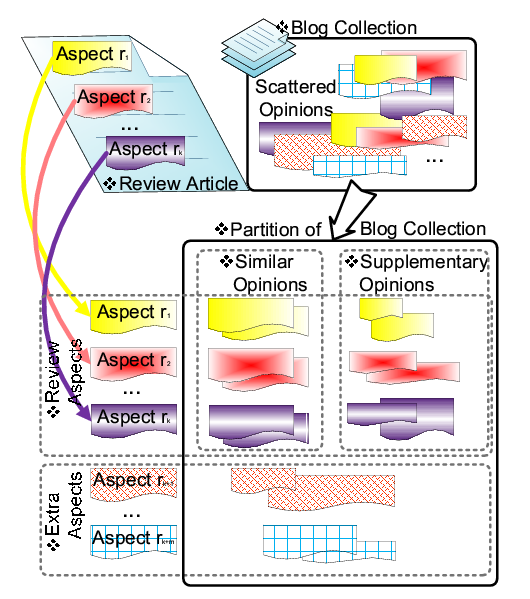
To the best of our knowledge, such an integration problem has not been studied in the existing work. In this paper, we study how to integrate a well-written expert review about an arbitrary topic with many ordinary opinions expressed in a text collection such as blog articles. We propose a general method to solve this integration problem in three steps: (1) extract ordinary opinions from text using information retrieval; (2) summarize and align the extracted opinions to the expert review to integrate the opinions; (3) further separate ordinary opinions that are similar to expert opinions from those that are not. Our main idea is to take advantage of the high readability of the expert review to structure the unorganized ordinary opinions while at the same time summarizing the ordinary opinions to extract representative opinions using the expert review as guidance. From the viewpoint of text data mining, we are essentially to use the expert review as a ``template'' to mine text data for ordinary opinions. The first step in our approach can be implemented with a direct application of information retrieval techniques. Implementing the second and third steps involves special challenges. In particular, without any training data, it is unclear how we should align ordinary opinions to an expert review and separate similar and supplementary opinions. We propose a semi-supervised topic modeling approach to solve these challenges. Specifically, we cast the expert review as a prior in a probabilistic topic model (i.e., PLSA[6]) and fit the model to the text collection with the ordinary opinions with Maximum A Posterior (MAP) estimation. With the estimated probabilistic model, we can then naturally obtain alignments of opinions as well as additional ordinary opinions that cannot be well-aligned with the expert review. The separation of similar and supplementary opinions can also be achieved with a similar model. We evaluate our method on integrating opinions about two quite different topics. One is a popular product ``iPhone'', and the other is a popular political figure Barack Obama. Experiment results show that our method can effectively integrate the expert review (a produce review from CNET for iPhone and a short biography from Wikipedia for Barack Obama) with ordinary opinions from blog articles.
This paper makes the following contributions:
Collecting and digesting opinions about a topic is critical for many tasks such as shopping, medical decision making, and social interactions. Our proposed method is quite general and can be applied to integrate opinions about any topic in any domain, thus potentially has many interesting applications.
The rest of the paper is organized as follows. In Section 2, we formally define the novel problem of opinion integration. After that, we present our Semi-supervised Topic Model in Section 4. We discuss our experiments and results in Section 5. Finally, we conclude in Section 7.
In this section, we define the novel problem of opinion integration.
Given an expert review about a topic ![]() (e.g., ``iPhone'' or ``Barack Obama'') and a collection of text articles (e.g., blog articles), our goal is to
extract opinions from text articles and integrate them with those in the expert review to form
an integrated opinion summary.
(e.g., ``iPhone'' or ``Barack Obama'') and a collection of text articles (e.g., blog articles), our goal is to
extract opinions from text articles and integrate them with those in the expert review to form
an integrated opinion summary.
The expert review is generally well-written and coherent, thus we can view
it as a sequence of semantically coherent segments, where a segment could be a sentence,
a paragraph, or other meaningful segments (e.g., paragraphs corresponding to product features)
available in some semi-structured review.
Formally, we denote the expert review by
![]() where
where ![]() is a segment.
Since we can always treat a sentence as a segment, this definition is quite general.
is a segment.
Since we can always treat a sentence as a segment, this definition is quite general.
The text collection is a set of text documents where ordinary opinions are expressed and
can be represented as
![]() where
where
![]() is a document
and
is a document
and ![]() is a sentence. To support opinion integration in a general and robust manner,
we do not rely on extra knowledge to segment documents to obtain opinion regions; instead,
we treat each sentence as an opinion unit. Since a sentence has a well-defined meaning, this assumption
is reasonable. To help a user interpret any opinion sentence, in real applications, we would
link each extracted opinion sentence back to the original document to facilitate navigating into the original
document and obtaining context of an opinion.
is a sentence. To support opinion integration in a general and robust manner,
we do not rely on extra knowledge to segment documents to obtain opinion regions; instead,
we treat each sentence as an opinion unit. Since a sentence has a well-defined meaning, this assumption
is reasonable. To help a user interpret any opinion sentence, in real applications, we would
link each extracted opinion sentence back to the original document to facilitate navigating into the original
document and obtaining context of an opinion.
We would like our integrated opinion summary to include both opinions in the expert review and
those most representative opinions in the text collection. Since the expert review is well written,
we keep their original form and leverage its structure to organize the ordinary opinions extracted
from text. To quantify the representativeness of an ordinary opinion sentence, we will compute a
``support value'' for each extracted ordinary opinion sentence. Specifically, we would like to
partition the extracted ordinary opinion sentences into groups that can be potentially
aligned with all the review segments
![]() . Naturally, there may also be some groups
with extra ordinary opinions that are not alignable with any expert opinion segment, and these opinions
can be very useful to augment the expert review with additional opinions.
. Naturally, there may also be some groups
with extra ordinary opinions that are not alignable with any expert opinion segment, and these opinions
can be very useful to augment the expert review with additional opinions.
Furthermore, for opinions aligned to a review segment ![]() , we would like to further separate
those that are similar to
, we would like to further separate
those that are similar to ![]() from those that are supplementary for
from those that are supplementary for ![]() ; such separation
can allow a user to digest the integrated opinions more easily.
; such separation
can allow a user to digest the integrated opinions more easily.
Finally, if ![]() has multiple sentences, we can further align each ordinary opinion sentence
(both ``similar'' and ``supplementary'') with a sentence in
has multiple sentences, we can further align each ordinary opinion sentence
(both ``similar'' and ``supplementary'') with a sentence in ![]() to increase the readability.
to increase the readability.
This problem setup is illustrated in Figure 1. We now define the problem more formally.
Since ordinary opinions tend to be redundant and we are primarily interested in extracting representative opinions, the support can be very useful to assess the representativeness of an extracted opinion.
Let
![]() be all the possible representative opinion sentences in
be all the possible representative opinion sentences in
![]() . We can now define the integrated
opinion summary that we would like to generate as follows.
. We can now define the integrated
opinion summary that we would like to generate as follows.
Note that we define ``opinion'' broadly as covering all the discussion about a topic in opinionate sources such as blog spaces and forums. The notion of ``opinion'' is quite vague; we adopt this broad definition to ensure generality of the problem set up and its solutions. In addition, any existing sentiment analysis technique could be applied as a post-processing step. But since we only focus on the integration problem in this paper, we will not cover sentiment analysis.
The opinion integration problem as defined in the previous section
is quite different from any existing problem setup for opinion extraction
and summarization, and it presents some special challenges: (1)
How can we extract representative opinion sentences with support information?
(2) How can we distinguish alignable opinions from non-alignable opinions?
(3) For any given expert review segment, how can we distinguish similar
opinions from those that are supplementary? (4) In the case when a review
segment ![]() has multiple sentences, how can we align a representative opinion to a sentence in
has multiple sentences, how can we align a representative opinion to a sentence in ![]() ?
In this section, we present our overall approach to solving all these challenges, leaving
a detailed presentation to the next section.
?
In this section, we present our overall approach to solving all these challenges, leaving
a detailed presentation to the next section.
At a high level, our approach primarily consists of two stages and an optional third stage: In the first stage, we retrieve only
the relevant opinion sentences from
![]() using the topic description
using the topic description ![]() as a query. Let
as a query. Let
![]() be the
set of all the retrieved relevant opinion sentences.
In the second stage, we use probabilistic topic models to cluster sentences in
be the
set of all the retrieved relevant opinion sentences.
In the second stage, we use probabilistic topic models to cluster sentences in
![]() and
obtain
and
obtain ![]() ,
, ![]() and
and ![]() . When
. When ![]() has multiple sentences, we have a third stage, in which we again use
information retrieval techniques to align any extracted representative opinion to a sentence of
has multiple sentences, we have a third stage, in which we again use
information retrieval techniques to align any extracted representative opinion to a sentence of ![]() .
We now describe each of the three stages in some detail.
.
We now describe each of the three stages in some detail.
The purpose of the first stage is to filter out irrelevant sentences and opinions in our collection.
This can be done by using the topic description as a keyword query to retrieve relevant opinion sentences.
In general, we may use any retrieval method. In this paper, we used a standard language modeling approach
(i.e., the KL-divergence retrieval model [20]). To ensure coverage of opinions, we perform
pseudo feedback using some top-ranked sentences; the idea is to expand the original topic description query
with additional words related to the topic so that we can further retrieve opinion sentences that do not necessarily match the original topic description ![]() . After this retrieval stage, we obtain a set of
relevant opinion sentences
. After this retrieval stage, we obtain a set of
relevant opinion sentences
![]() .
.
In the second stage, our main idea is to exploit a probabilistic topic model, i.e., Probabilistic Latent Semantic Analysis (PLSA) with conjugate prior [6,11] to cluster opinion sentences in a special way so that there will be precisely one cluster
corresponding to each segment ![]() in the expert review. These clusters are to collect opinion sentences
that can be aligned with a review segment. There will also be some clusters that are not
aligned with any review segments, and they are designed to collect extra opinions. Thus the model provides
an elegant way to simultaneously partition opinions and align them to the expert review.
Interestingly, the same model can also be adapted to further partition opinions aligned to a review segment
into similar and supplementary opinions. Finally, a simplified version of the model (i.e., no prior, basic PLSA) can be used to cluster any group of sentences to extract representative opinion sentences. The support
of a representative opinion is defined as the size of the cluster represented by the opinion sentences.
in the expert review. These clusters are to collect opinion sentences
that can be aligned with a review segment. There will also be some clusters that are not
aligned with any review segments, and they are designed to collect extra opinions. Thus the model provides
an elegant way to simultaneously partition opinions and align them to the expert review.
Interestingly, the same model can also be adapted to further partition opinions aligned to a review segment
into similar and supplementary opinions. Finally, a simplified version of the model (i.e., no prior, basic PLSA) can be used to cluster any group of sentences to extract representative opinion sentences. The support
of a representative opinion is defined as the size of the cluster represented by the opinion sentences.
Note that what we need in this second stage is semi-supervised clustering in the sense that we would like
to constrain many of the clusters so that they would correspond to the segments ![]() s in the expert review. Thus a direct application of any regular clustering algorithm would not be able to solve our problem. Instead of doing clustering, we can also imagine using each expert review segment
s in the expert review. Thus a direct application of any regular clustering algorithm would not be able to solve our problem. Instead of doing clustering, we can also imagine using each expert review segment ![]() as a query to retrieve similar sentences. However, it would be unclear how to choose a good cutoff point on the ranked list of retrieved results. Compared with these alternative approaches, PLSA with conjugate prior provides a more principled and unified way to tackle all the challenges.
as a query to retrieve similar sentences. However, it would be unclear how to choose a good cutoff point on the ranked list of retrieved results. Compared with these alternative approaches, PLSA with conjugate prior provides a more principled and unified way to tackle all the challenges.
In the optional third stage, we have a review segment ![]() with multiple sentences and we would like to
align all extracted representative opinions to the sentences in
with multiple sentences and we would like to
align all extracted representative opinions to the sentences in ![]() . This can be achieved
by using each representative opinion as a query and retrieve sentences in
. This can be achieved
by using each representative opinion as a query and retrieve sentences in ![]() . Once again, in general,
any retrieval method can be used. In this paper, we again used the KL-divergence retrieval method.
. Once again, in general,
any retrieval method can be used. In this paper, we again used the KL-divergence retrieval method.
From the discussion above, it is clear that we leverage both information retrieval techniques and text mining techniques (i.e., PLSA), and our main technical contributions lie in the second stage where we repeatedly exploit semi-supervised topic modeling to extract and integrate opinions. We describe this step in more detail in the next section.
Probabilistic latent semantic analysis (PLSA) [6] and its extensions [21,13,11] have recently been applied to many text mining problems with promising results. Our work adds to this line yet another novel use of such models for opinion integration.
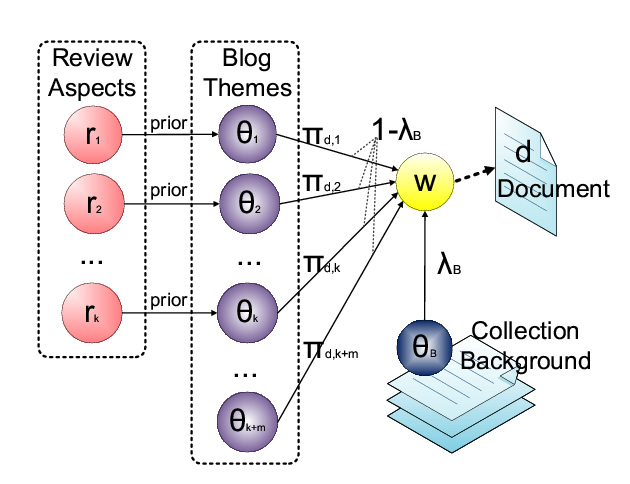
As in most topic models, our general idea is to use a unigram language model (i.e., a multinomial word distribution) to model a topic. For example, a distribution that assigns high probabilities to words such as ``iPhone'', ``battery'', ``life'', ``hour'', would suggest a topic such as ``battery life of iPhone.'' In order to identify multiple topics in text, we would fit a mixture model involving multiple multinomial distributions to our text data and try to figure out how to set the parameters of the multiple word distributions so that we can maximize the likelihood of the text data. Intuitively, if two words tend to co-occur with each other and one word is assigned a high probability, then the other word generally should also be assigned a high probability to maximize the data likelihood. Thus this kind of model generally captures the co-occurrences of words and can help cluster the words based on co-occurrences.
In order to apply this kind of model to our integration problem, we assume that each review segment
corresponds to a unigram language model which would capture all opinions that can be aligned
with a review segment. Furthermore, we introduce a certain number of unigram language models to capture the extra opinions. We then fit the mixture model to
![]() , i.e., the set of all the relevant opinion sentences generated using information retrieval as described in the previous section. Once the parameters are estimated,
they can be used to group sentences into different aspects corresponding to the different review segments
and extra aspects corresponding to extra opinions. We now present our mixture model in detail.
, i.e., the set of all the relevant opinion sentences generated using information retrieval as described in the previous section. Once the parameters are estimated,
they can be used to group sentences into different aspects corresponding to the different review segments
and extra aspects corresponding to extra opinions. We now present our mixture model in detail.
We first present the basic PLSA model as described in [21]. Intuitively, the words in our text collection
![]() can be classified into two categories (1) background words that are of relatively high frequency in the whole collection. For example, in the collection of topic ``iPhone'', words like ``iPhone'', ``Apple'' are considered as background words. (2) words related to different aspects which we are interested in. So we define
can be classified into two categories (1) background words that are of relatively high frequency in the whole collection. For example, in the collection of topic ``iPhone'', words like ``iPhone'', ``Apple'' are considered as background words. (2) words related to different aspects which we are interested in. So we define ![]() unigram language models:
unigram language models: ![]() as the background model to capture the background words,
as the background model to capture the background words,
![]() as
as ![]() theme models, each capturing
one aspect of the topic and corresponding
to the
theme models, each capturing
one aspect of the topic and corresponding
to the ![]() review segments
review segments
![]() . A document
. A document ![]() in
in
![]() (in our problem it is actually a sentence) can then be regarded as a sample of the following mixture model.
(in our problem it is actually a sentence) can then be regarded as a sample of the following mixture model.
![$\displaystyle p_d(w) = \lambda_B p(w\vert\theta_B) + (1-\lambda_B)\sum_{j=1}^k[\pi_{d,j}p(w\vert\theta_j)]$](fp743-lu-img21.png) |
(1) |
where ![]() is a word,
is a word, ![]() is a document-specific mixing weight for the
is a document-specific mixing weight for the ![]() -th aspect (
-th aspect (
![]() ), and
), and ![]() is the mixing weight of the background model
is the mixing weight of the background model ![]() . The log-likelihood of the collection
. The log-likelihood of the collection
![]() is
is
![\begin{displaymath}\begin{array}{cc} &\verb''log''p(\mathcal{C}_O\vert\Lambda) =...
...lambda_B)\sum_{j=1}^k[\pi_{d,j}p(w\vert\theta_j)]\} \end{array}\end{displaymath}](fp743-lu-img28.png) |
(2) |
where ![]() is the set of all the words (i.e., vocabulary),
is the set of all the words (i.e., vocabulary), ![]() is the count of word
is the count of word ![]() in document
in document ![]() , and
, and ![]() is the set of all model parameters. The purpose of using a background model is to ``force'' clustering to be
done based on more discriminative words, leading to more informative and more discriminative theme models.
is the set of all model parameters. The purpose of using a background model is to ``force'' clustering to be
done based on more discriminative words, leading to more informative and more discriminative theme models.
The model can be estimated using any estimator. For example, the Expectation-Maximization (EM) algorithm [3] can be used to compute a maximum likelihood estimate with the following updating formulas:
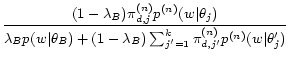 |
|||
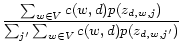 |
|||
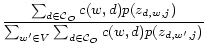 |
We could have directly applied the basic PLSA to extract topics from
![]() .
However, the extracted topics in this way would generally not be well-aligned to the expert review.
In order to ensure alignment, we would like to ``force'' some of the multinomial distribution component models
(i.e., language models) to be ``aligned'' with all the segments in the expert review. In probabilistic models, this can
be achieved by extending the basic PLSA to incorporate a conjugate prior defined based on the expert review segments and using the Maximum A Posterior (MAP) esatimator instead of the Maximum Likelihood estimator as we did
in the basic PLSA. Intuitively, a prior defined based on an expert review segment would tend to make
the corresponding language model similar to the empirical word distribution in the review segment, thus
the language model would tend to attract opinion sentences in
.
However, the extracted topics in this way would generally not be well-aligned to the expert review.
In order to ensure alignment, we would like to ``force'' some of the multinomial distribution component models
(i.e., language models) to be ``aligned'' with all the segments in the expert review. In probabilistic models, this can
be achieved by extending the basic PLSA to incorporate a conjugate prior defined based on the expert review segments and using the Maximum A Posterior (MAP) esatimator instead of the Maximum Likelihood estimator as we did
in the basic PLSA. Intuitively, a prior defined based on an expert review segment would tend to make
the corresponding language model similar to the empirical word distribution in the review segment, thus
the language model would tend to attract opinion sentences in
![]() that are similar to the expert review segment. This ensures the alignment of the extracted opinions with the original review segment.
that are similar to the expert review segment. This ensures the alignment of the extracted opinions with the original review segment.
Specifically, we build a unigram language model
![]() for each review segment
for each review segment ![]()
![]() and define a conjugate prior (i.e., a Dirichlet prior) on each multinomial distribution topic model, parameterized as
and define a conjugate prior (i.e., a Dirichlet prior) on each multinomial distribution topic model, parameterized as
![]() , where
, where ![]() is a confidence parameter for the prior. Since we use a conjugate prior,
is a confidence parameter for the prior. Since we use a conjugate prior, ![]() can be interpreted as the ``equivalent sample size'' which means that the effect of adding the prior would be equivalent to adding
can be interpreted as the ``equivalent sample size'' which means that the effect of adding the prior would be equivalent to adding
![]() pseudo counts for word
pseudo counts for word ![]() when we estimate the topic model
when we estimate the topic model
![]() . Figure 2 illustrates the generation process of a word W in such a semi-supervised PLSA where the prior serves as some ``training data'' to bias the clustering results.
. Figure 2 illustrates the generation process of a word W in such a semi-supervised PLSA where the prior serves as some ``training data'' to bias the clustering results.
The prior for all the parameters is given by
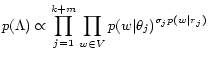 |
(3) |
Generally we have ![]() , because we may want to find extra opinion topics other than the corresponding segments in the expert review. So we set
, because we may want to find extra opinion topics other than the corresponding segments in the expert review. So we set
![]() for
for
![]() .
.
With the prior defined above, we can then use the Maximum A Posterior (MAP) estimator to estimate all the parameters as follows
| (4) |
The MAP estimate can be computed using essentially the same EM algorithm as presented above with only slightly different updating formula for the component language models. The new updating formula is:
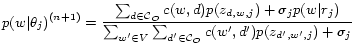 |
(5) |
We can see that the main difference between this equation and the previous one for basic PLSA is that
we now pool the counts of terms in the expert review segment with those from the opinion sentences in
![]() , which is essentially to allow the expert review to serve as some training data for the corresponding
opinion topic. This is why we call this model semi-supervised PLSA.
, which is essentially to allow the expert review to serve as some training data for the corresponding
opinion topic. This is why we call this model semi-supervised PLSA.
If we are highly confident of the aspects captured in the prior, we could empirically set a large ![]() . Otherwise, if we need to ensure the impact of the prior without being over restricted by the prior, some regularized estimation techniques are necessary. Following the similar idea of regularized estimation [19], we define
a decay parameter
. Otherwise, if we need to ensure the impact of the prior without being over restricted by the prior, some regularized estimation techniques are necessary. Following the similar idea of regularized estimation [19], we define
a decay parameter ![]() and a prior weight
and a prior weight ![]() as
as
| (6) |
So we could start from a large ![]() (say 5000) (i.e., starting with perfectly alignable opinion models) and gradually decay it in each EM iteration by equation 7, and we stop the decaying of
(say 5000) (i.e., starting with perfectly alignable opinion models) and gradually decay it in each EM iteration by equation 7, and we stop the decaying of ![]() until the weight of the prior
until the weight of the prior ![]() is below some threshold
is below some threshold ![]() (say
(say ![]() ). Decaying allows the model to gradually pick up words from
). Decaying allows the model to gradually pick up words from
![]() . The new updating formulas are
. The new updating formulas are
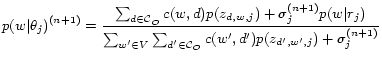 |
(8) |
We propose to use review aspects as priors in the partition of
![]() into aspects. We could have used the whole expert review segment to construct the priors. But if so, we could only get the opinions that are most similar to the review opinions. However, we would like extract not only opinions supporting the review opinions but also supplementary opinions on the review aspect. So we use only the ``aspect words'' to estimate the prior. We use a simple heuristic: opinions are usually expressed in the form of adjectives, adverbs and verbs while aspect words are usually nouns. And we apply a Part-of-Speech tagger1 on each review segment
into aspects. We could have used the whole expert review segment to construct the priors. But if so, we could only get the opinions that are most similar to the review opinions. However, we would like extract not only opinions supporting the review opinions but also supplementary opinions on the review aspect. So we use only the ``aspect words'' to estimate the prior. We use a simple heuristic: opinions are usually expressed in the form of adjectives, adverbs and verbs while aspect words are usually nouns. And we apply a Part-of-Speech tagger1 on each review segment ![]() and further filter out the opinion words to get a
and further filter out the opinion words to get a ![]() . The prior
. The prior
![]() is estimated by Maximum Likelihood:
is estimated by Maximum Likelihood:
Given these priors constructed from the expert review
![]() ,
,
![]() , we could estimate the parameters for the semi-supervised topic model according to Section 4.2. After that, we have a set of theme models extracted from the text collection
, we could estimate the parameters for the semi-supervised topic model according to Section 4.2. After that, we have a set of theme models extracted from the text collection
![]() , and we could group each sentence
, and we could group each sentence ![]() in
in
![]() into one of the
into one of the ![]() themes by choosing the theme model with the largest probability of generating
themes by choosing the theme model with the largest probability of generating ![]() :
:
If we define ![]() if
if ![]() is grouped into
is grouped into
![]() , then we have a partition of
, then we have a partition of
![]() :
:
Thus each ![]() ,
, ![]() , corresponds to the review aspect
, corresponds to the review aspect ![]() and each
and each ![]() ,
,
![]() , is the set of sentences that supplements the expert review with additional aspects. Parameter
, is the set of sentences that supplements the expert review with additional aspects. Parameter ![]() , the number of additional aspects, is set empirically.
, the number of additional aspects, is set empirically.
such that ![]() contains sentences that is similar to the opinions in the review while
contains sentences that is similar to the opinions in the review while
![]() is a set of sentences that supplement the review opinions on the review aspect
is a set of sentences that supplement the review opinions on the review aspect ![]() .
.
We assume that each subset of sentences ![]() ,
, ![]() , covers two themes captured by two subtopic models
, covers two themes captured by two subtopic models
![]() and
and
![]() . We first construct a unigram language model
. We first construct a unigram language model
![]() from review segment
from review segment ![]() using both the feature words and opinion words. This model is used as a prior for extracting
using both the feature words and opinion words. This model is used as a prior for extracting
![]() . After that, we estimate the model parameters as described in Section 4.2. And then, we could classify each sentence
. After that, we estimate the model parameters as described in Section 4.2. And then, we could classify each sentence
![]() into either
into either ![]() or
or
![]() in the way similar to equation 10.
in the way similar to equation 10.
Now we need to further summarize each block ![]() in the partition
in the partition
![]() by extracting representative opinions
by extracting representative opinions ![]() . We take a two-step approach.
. We take a two-step approach.
In the first step, we try to remove the redundancy of sentences in ![]() and group the similar opinions together by unsupervised topic modeling. In detail, we use PLSA (without any prior) to do the clustering and set the number of clusters proportional to the size of
and group the similar opinions together by unsupervised topic modeling. In detail, we use PLSA (without any prior) to do the clustering and set the number of clusters proportional to the size of ![]() . After the clustering, we get a further partition of
. After the clustering, we get a further partition of
![]() where
where ![]() and
and ![]() is a constant parameter that defines the average number of sentences in each cluster. One representative sentence in
is a constant parameter that defines the average number of sentences in each cluster. One representative sentence in ![]() is selected by the similarity between the sentence and the cluster centroid (i.e. a word distribution) of
is selected by the similarity between the sentence and the cluster centroid (i.e. a word distribution) of ![]() . If we define
. If we define ![]() as the representative sentenced of
as the representative sentenced of ![]() , and
, and
![]() as the support, we have a representative opinion of
as the support, we have a representative opinion of ![]() which is
which is
![]() . Thus
. Thus
![]() .
.
In the second step, we aim at providing some context information for each representative opinion ![]() of
of ![]() to help the user to better understand the opinion expressed. What we propose is to compare the similarity between opinion sentence
to help the user to better understand the opinion expressed. What we propose is to compare the similarity between opinion sentence ![]() and each review sentence in segment corresponding to
and each review sentence in segment corresponding to ![]() and assign
and assign ![]() to the review sentence with the highest similarity. For both steps, we use KL-Divergence as the similarity measure.
to the review sentence with the highest similarity. For both steps, we use KL-Divergence as the similarity measure.
``Theme Extraction from Text Collection'' makes one invocation of semi-supervised PLSA on the whole collection
![]() , where the number of cluster is
, where the number of cluster is ![]() . So the complexity is
. So the complexity is
![]() .
.
There are ![]() invocations of semi-supervised PLSA in ``Further Separation of Opinions'', each on a subset of the collection
invocations of semi-supervised PLSA in ``Further Separation of Opinions'', each on a subset of the collection
![]() with only two clusters. And we know from equation 11 that
with only two clusters. And we know from equation 11 that
![]() . Suppose
. Suppose ![]() is the total number of words in
is the total number of words in ![]() . So the total complexity is
. So the total complexity is
![]() which in the worst case is
which in the worst case is
![]() .
.
Finally, ``Generation of Summaries'' makes ![]() invocations of PLSA, each on a subset of the collection
invocations of PLSA, each on a subset of the collection
![]() . In each invocation, the number of clusters is
. In each invocation, the number of clusters is
![]() , and
, and ![]() is the total number of words in
is the total number of words in ![]() . So the total complexity in this stage is
. So the total complexity in this stage is
![]() , which in the worst case is
, which in the worst case is
![]() .
.
Thus, our whole process is bounded by the computational complexity
![]() . Since
. Since ![]() ,
, ![]() , and
, and ![]() are usually much smaller than
are usually much smaller than
![]() , the running time is basically bounded by
, the running time is basically bounded by
![]() .
.
We need two types of data sets for evaluation. One type is expert reviews. We construct this data set by leveraging the existing services provided by CNET and wikipedia, i.e., we submit queries to their web sites and download the expert reviews on ``iPhone'' written by CNET editors2 and the introduction part of articles about ``Barack Obama'' in wikipedia3. The composition and basic statistics of this data set (denoted as ``REVIEW'') is shown in Table 1.
The other type of data is a set of opinion sentences related to certain topic. In this paper, we only use Weblog data, but our method can be applied on any kind of data that contain opinions in free text. Specifically, we firstly submit topic description queries to Google Blog Search4 and collect the blog entries returned. The search domain are restricted to spaces.live.com, since schema matching is not our focus. We further build a collection of ![]() opinion sentences
opinion sentences
![]() which are highly relevant to the given topic
which are highly relevant to the given topic ![]() using information retrieval techniques as described as the first stage in Section 3. The basic information of these collections (denoted as ``BLOG'' is shown in Table 2. For all the data collections, Porter stemmer [18] is used to stem the text and stop words in general English are removed.
using information retrieval techniques as described as the first stage in Section 3. The basic information of these collections (denoted as ``BLOG'' is shown in Table 2. For all the data collections, Porter stemmer [18] is used to stem the text and stop words in general English are removed.
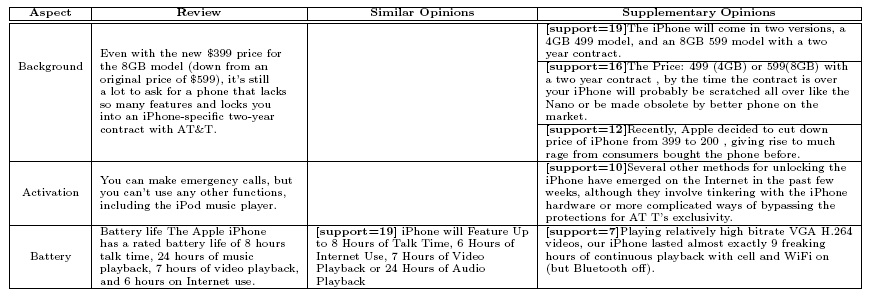
Due to the limitation of the spaces, only part of the integration with review aspects are show in Table 3. We can see that there is indeed some interesting information discovered.
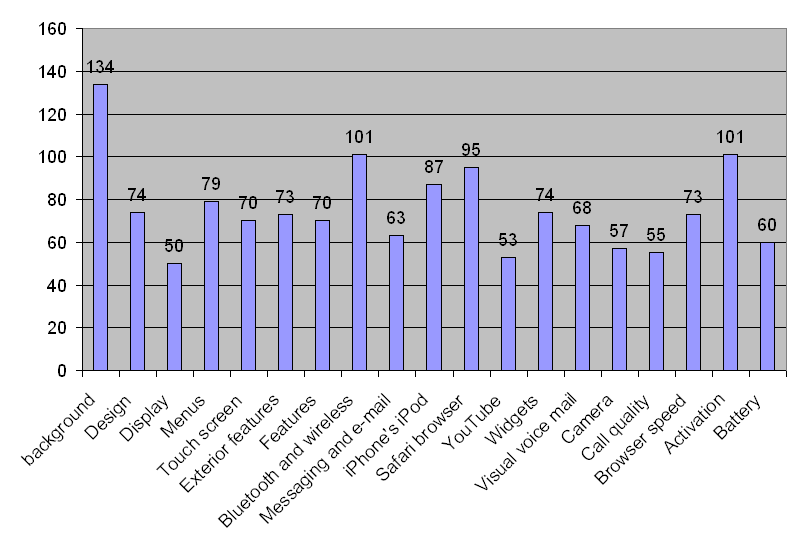
Furthermore, we may also want to know which aspects of iPhone people are most interested in. If we define the support of an aspect as the sum of the support of representative opinions in this aspect, we could easily get the support statistics for each review aspects in our topic modeling approach. As can be seen in Figure 3, the ``background'' aspect attracts the most discussion. This is mainly caused by the mention of the price of iPhone in the background aspect. The next two aspects with highest support are ``Bluetooth and Wireless'' and ``Activation'' both with support . As stated in the iPhone review ``The Wi-Fi compatibility is especially welcome, and a feature that's absent on far too many smart phones.'', and our support statistics suggest that people do comment a lot about this unique feature of iPhone. ``Activation'' is another hot aspect as discovered by our method. As many people know, the activation of iPhone requires a two-year contract with AT&T, which brings much controversy among customers.
In addition, we show three of the most supported representative opinions in the extra aspects in Table 4. The first sentence points out another way of activating iPhone, while the second sentence brings up the information that Cisco was the original owner of the trademark ``iPhone''. The third sentence expresses a opinion in favor of another smartphone, Nokia N95, which could be useful information for a potential smartphone buyer who did not know about Nokia N95 before.
In Table 5, we display part of the opinion integration with the aspects in the review. Since there is no short description of each aspect in this example, we use ID in the first column of the table to distinguish one aspect from another.
After further summing up the support for each aspect, we display two of the most supported aspects and one least supported aspect in Table 6. The most supported aspect is aspect 0 with , which as mentioned above is a brief introduction of the person and his position. Aspect talking about his heritage ranks as the second with , which agrees with the fact that he is special among the presidential candidates because of his Kenyan origin and indicates that people are interested in it. The least covered aspect is aspect about his family, since the total support is only .
In the first designed task, we aims at evaluating the effectiveness of our approach in identifying the extra aspects in addition to review aspects. Towards this goal, we generate a big set of sentences
by mixing all the sentences in
with seven most supported sentences in
. There are
sentences in
in total. The users are asked to select seven sentences from randomly permutated
that do not fit into the ![]() review aspects. In this way, we could see how is the human consensus on this task and how our approach could recover the choice of human.
review aspects. In this way, we could see how is the human consensus on this task and how our approach could recover the choice of human.
Table 7 displays the selection of the seven sentences on extra aspects by our method and the three users. The only sentence out of seven that all three users agree on is sentence number , which suggests that grouping sentences into extra aspects is quite a subjective task so it is difficult to produce results satisfactory to each individual user. However our method is able to recover of the user's choices on average.
In the second task, we try to evaluate the performance of our approach in grouping sentences into ![]() review aspects. we randomly permutate all the sentences in
to construct a
and remove the aspect assigned to each sentence. For each of the
sentences, the users are asked to assign one of the
review aspects to it. In essence, this is a multi-class classification problem where the number of classes is
.
review aspects. we randomly permutate all the sentences in
to construct a
and remove the aspect assigned to each sentence. For each of the
sentences, the users are asked to assign one of the
review aspects to it. In essence, this is a multi-class classification problem where the number of classes is
.
The results turn out to be
where . When , the probability is only around ; (2) the expected number of sentences recovered would be
Again, this task is subjective, and there is still much controversy among human users. But our approach performs reasonably : in the sentences with human consensus, our method achieves the accuracy of .
In the third task, our goal is to see how well we can separate similar opinions from supplementary opinions in the semi-supervised topic modeling approach. We first select review aspects out of which our method has identified both similar and supplementary opinions; then for each of the aspects, we mix one similar opinion with several supplementary opinions; the users are supposed to select one sentence which share the most similar opinion with the review aspect. On average, our method could recover of the choices of human users. Among the different choices between our method and the users, only one aspect has achieved consensus of three users. That is to say, this is a ``true'' mistake of our method, while other mistakes do not have agreement in the users.
Recently there has been a lot of work in opinion mining and summarization especially on customer reviews. In [2], sentiment classifiers are built from some training corpus. Some papers [8,7,10,17] further mine product features from reviews on which the reviewers have expressed their opinions. Zhuang and others focused on movie review mining and summarization [22]. [4] presented a prototype system, named Pulse, for mining topics and sentiment orientation jointly from customer feedback. However, these techniques are limited to the domain of products/movies, and many are highly dependent on the training data set, so are not generally applicable to summarize opinions about an arbitrary topic. Our problem setup aims at shallower but more robust integration.
Weblogs mining has attracted many new research work. Some focus on sentiment analysis. Mishne and others used the temporal pattern of sentiments to predict the book sales [14,15]. Opinmind[16] summarizes the weblog search results with positive and negative categories. On the other hand, researchers also extract the subtopics in weblog collections, and track their distribution over time and locations [12]. Last year, Mei and others proposed a mixture model to model both facets and opinions at the same time [11]. These previous work aims at generating sentiment summary for a topic purely based on the blog articles. We aim at aligning blog opinions to an expert review. We also take a broader definition of opinions to accommodate the integration of opinions for an arbitrary topic.
Topic model has been widely and successfully applied to blog articles and other text collections to mine topic patterns [5,1,21,9]. Our work adds to this line yet another novel use of such models for opinion integration. Furthermore, we explore a novel way of defining prior.