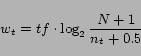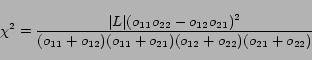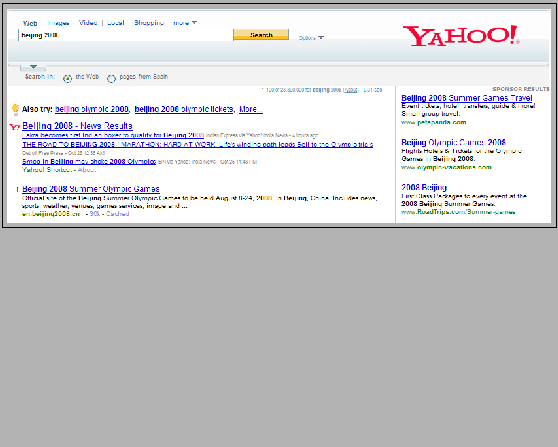
Figure 1: Example of sponsored search advertisements on the search engine results page of Yahoo! for the query ``Beijing 2008''. Ads are shown on the right side under the label ``SPONSOR RESULTS''
Figure 1: Example of sponsored search advertisements on the search engine results page of Yahoo! for the query ``Beijing 2008''. Ads are shown on the right side under the label ``SPONSOR RESULTS''
Sponsored search is the task of placing ads that relate to the user's query on the same page as the search results returned by the search engine. Typically sponsored search results resemble search result snippets in that they have a title, and a small amount of additional text, as in Figure 1. When the user clicks on the title he is taken to the landing page of the advertiser. Search engine revenue is generated in large part by the sponsored results. Of the $16.9 billion generated by online advertising in 2006, 40% was generated by search advertising [12]. Clearly it is an advantage to the search engine to provide ads users will click.
While the final ranking takes into account the amount bidded by the advertiser and, more generally, the micro-economic model adopted by the search engine to maximize revenue, relevance, or quality of the ads returned is a crucial factor. Users are more likely to click ads that are relevant to their query. In fact, there is evidence that the level of congruence between the ad and its context has a significant effect even in the absence of a conscious response such as a click [34]. If we assume that congruency equates to topical similarity or ``relevance'', the task is to show the ads that are most similar to the user's query in the sponsored results. With this in mind we would like to place ads in the sponsored results that are a good match for the user's query. In this paper we abstract from the economic aspects of the problem and focus on the issue of improving the quality of the ads proposed as relevant to the query. Information about the quality of match at the content level can be taken into account later, including the micro-economic model, to compile the final list of ads to be displayed. While the publisher goal is maximizing profit, we stress the fact that maximizing ads quality or relevance is a crucial factor in this process.
Aside from the difficulties in assessing the similarity of an ad to a query that stem from the sparseness of the representation of both the query and the ad, the task of placing ads is complicated by the fact that users click on ads for a wide variety of reasons that are not reflected in the similarity of an ad to a query. For example, there is a strong positional bias to user clicks. Users are much more likely to click on items at the top of a ranked list of search results than items lower in the ranking [11,14]. This makes using the click data to learn a ranking function over the ads and to evaluate the system more difficult. Specifically, user clicks are not an indication of absolute relevance. Rather, as Joachims proposed [13], the user click mainly indicates the clicked item is more relevant than the those items which were ranked higher but were not clicked. This observation implies that positive and negative examples can be extracted from query logs in a meaningful way, avoiding the complexities and noise of click-through rate estimation. Building on Joachims' suggestion we create a training set from the query logs of a real sponsored search system.
We propose that this type of data can be also used directly for evaluating a learning model. A few studies have already shown that click feedback from users can be used to improve machine learned ranking [32,1]. However, this type of information has not been used for both training and evaluation. Previous work [32,1] has ultimately relied on editorial data for evaluation. We show that consistent results are obtained in this way across different ranking methods and different feature sets.
We formulate the problem of ranking a set of ads given a query as a learning task and investigate three learning methods of increasing complexity based on the perceptron algorithm: a binary linear classifier, a linear ranking model and a multilayer perceptron, or artificial neural net. Specifically, we focus on online learning methods which suit the task of learning from large amounts of data, or from a stream of incoming feedback from query logs. As hoped, we find that accuracy increases with the complexity of the model.
Retrieving ads is complex in part because the text is sparse. In addition, features based on link structure that have been shown to benefit retrieval in a Web setting cannot be applied to ads because they lack an obvious link organization. Exploiting our setup we investigate several classes of features which have been proposed recently for content match, the task of ranking ads with respect to the context of a Web page, rather than a query. We start from the cosine similarity between query and ad. We decompose the ad and use as features the similarity of individual components of the ad and the query, and also properties of the degree of overlapping between the query and the ad [25]. Next we investigate a class of language-independent, knowledge free, features based on the distributional similarity of pairs of words which have been used successfully in content match [6], and can be extracted from any text collection or query log. These features measure the similarity between two texts independently of exact matches at the string level and are meant to capture indirect semantic associations. In content match there are many words that can be extracted from a Web page to compute such features, while in sponsored search there are only the terms in the query. We show that across all learning methods these features produce the best results. Overall, with a compact set of just twelve features we improve significantly over all traditional models.
This paper presents the following primary contributions. First, we show that click-data can be used directly for evaluation purposes which is a desirable property in the context of large scale systems that otherwise have to rely exclusively on editorial data, or carry out noisy estimations of click-through rates. Second, we show empirically that different methods of increasing complexity can be applied to the task and generate consistent results. This is important because it supports the hypothesis that the evaluation is consistent across different methods. On the learning side, it also shows that taking into account pairwise information in training is beneficial in machine-learned ranking, even in noisy settings. Finally, we provide empirical evidence on the utility of a class of simple features for ranking ads based on lexical similarity measures, which has possible applications to other query-based ranking tasks such as document retrieval and search in general.
The rest of the paper is organized as follows. In Section 2 we introduce the method for unbiasing click logs. Section 3 introduces several approaches to learning from click data for sponsored search. Section 4 describes the features evaluated in our experiments, which are discussed in Sections 5 and 6. Section 7 provides an overview of related work.
Employing user clicks to train and to evaluate a sponsored search system is a natural choice, since the goal in sponsored search is maximizing the number of clicks. However, user clicks cannot be used in a straight-forward manner because they have a strong positional bias [11,14], and they only provide a relative indication of relevance [13]. There is a strong positional bias as highly ranked results or ads may be clicked because of their rank and not their relevance. For example, a user may click on the top ranked ad and then click on the third ad in the ranking, even if the third ad may be more relevant to his query. The reason for this bias is that users are likely to sequentially scan the ranked list of items and may click on an item before scanning the whole list, or may never scan the whole list at all.
To investigate how to employ user clicks to train and evaluate a sponsored search system, we have collected a set of queries and the ads that had been shown with them on the right-hand side of the search engine results page, from the logs of the Yahoo! Web search engine. We sampled queries until we collected a sufficiently large number of distinct clicked ads. We sampled only queries with three or more query terms because longer queries are more likely to lead to higher conversion rates [24]. In other words, users issuing longer queries are more likely to visit a Web site and perform a transaction. We also considered only one click for a query-ad pair from one user per day.
Following Joachims [13], we make a conservative assumption that a click can only serve as an indication that an ad is more relevant than the ads ranked higher but not clicked, but not as an absolute indication of the ad relevance. In this setting, the clicks on the top ranked ad do not carry any information, because the top ranked ad cannot be ranked any higher. In other words, there is no discriminative pairwise information associated with a click at position one. Hence, we do not consider such clicks in the remainder of our experiments. For each clicked ad, we create a block which consists of the clicked ad and the non-clicked ads that ranked higher, for a total of 123,798 blocks. In each block, we assign a score of ``+1'' to the clicked ad and ``-1'' to the ads that were ranked higher but were not clicked.
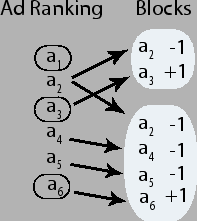
Figure 2: Illustrative example of how blocks are generated from the clicked and non-clicked ads for a query.
Figure 2 shows an example
of the score assignment process. On the left-hand side of the
figure, we show the ranking of six ads for a query. The ellipses
around ads ![]() ,
, ![]() and
and ![]() denote that these ads were clicked by the user who
submitted the query. The ``gold-standard'' blocks of ads, shown on
the right-hand side of the figure, are generated in the following
way. First we ignore the click on ad
denote that these ads were clicked by the user who
submitted the query. The ``gold-standard'' blocks of ads, shown on
the right-hand side of the figure, are generated in the following
way. First we ignore the click on ad ![]() since this ad was already ranked first and it was clicked.
Then, we form one block of ads with
since this ad was already ranked first and it was clicked.
Then, we form one block of ads with ![]() and
and ![]() , assigning scores of
``-1'' and ``+1'', respectively. Next, we form a second block of
ads consisting of
, assigning scores of
``-1'' and ``+1'', respectively. Next, we form a second block of
ads consisting of ![]() ,
, ![]() ,
, ![]() with scores ``-1'' and
with scores ``-1'' and ![]() with score ``+1''. In Figure 2 blocks of ads are shown with shaded
areas.
with score ``+1''. In Figure 2 blocks of ads are shown with shaded
areas.
From the example above we obtain two gold standard blocks from one user session. Alternatively, one could generate a single vector of binary values including all the positive and negative examples. One potential problem is that in such a way one introduces effectively an equivalence of relevance between clicked ads (positive points), while according to our conservative assumption we cannot really say anything about the relative relevance of two clicks in different blocks, because we do not have reliable means of interpreting clicks in an absolute way. As a matter of fact, in some of the ranking models we propose (classification and multilayer perceptron) the block structure is effectively ignored in training. However training on local pairwise preferences can be beneficial, as we show in the experimental section going from a global binary classification model to a ranking model which exploits the block structure. The block-based encoding is compatible with both approaches and defines a robust and intuitive learning task.
The perceptron has received much attention in recent years for its simplicity and flexibility. Among other fields, the perceptron is popular in natural language processing, where it has been successfully applied to several tasks such as syntactic parsing, tagging, information extraction and re-ranking [7,29,30,31]. We preferred the perceptron over other popular methods, such as SVM, for which incremental formulations have been proposed [5,17], because accurately-designed perceptrons (i.e., including regularization, margin functions, etc.) often performs as well as more complex methods at a smaller computational cost. Moreover, the simplicity of the algorithm allows easy customization, which is crucial in large scale settings. In Section 3.4, we benchmarked one of our perceptron models on a ranking task, yielding results comparable to SVM and Boosting.
We investigate three approaches to learning to rank ads based on
click data: classification, ranking, and non-linear regression. The
general setting involves the following elements. A pattern
![]() is a
vector of features extracted from an ad-query pair
is a
vector of features extracted from an ad-query pair ![]() . Each pattern
. Each pattern ![]() is associated
with a response value
is associated
with a response value
![]() . In
classification we associate a vector for a pair which has not been
clicked with -1, also referred to as class
. In
classification we associate a vector for a pair which has not been
clicked with -1, also referred to as class ![]() , and a vector for a pair which has been clicked with +1,
also referred to as class
, and a vector for a pair which has been clicked with +1,
also referred to as class ![]() .
The goal of learning is to find a set of parameters, or weights,
.
The goal of learning is to find a set of parameters, or weights,
![]() used to assign a
score
used to assign a
score
![]() to
patterns such that
to
patterns such that
![]() is
close to the actual value
is
close to the actual value ![]() .
In particular, we are interested in predicting the clicked ad in a
block of ads.
.
In particular, we are interested in predicting the clicked ad in a
block of ads.
The basic classifier is a binary perceptron. We extend the basic
model by averaging and adding an uneven margin
function. Averaging is a method for regularizing the classifier
by using - for prediction after training - the average weight
vector of all perceptron models posited during training [10]. The
uneven margin function is a method for learning a classifier with
large margins for cases in which the distribution of classes is
unbalanced [20]. Since non-clicked ads
are more numerous than clicked ads we face an unbalanced learning
task. The uneven margin function pushes learning towards achieving
a larger margin on the positive class. The binary perceptron uses
the sign function as a discriminant:
| (1) |
We learn ![]() from the training
data. The model has two adjustable parameters. The first is the
number of instances
from the training
data. The model has two adjustable parameters. The first is the
number of instances ![]() to use in
training, or the number of passes (epochs) over the training data.
The second concerns the uneven margin function, for which we define
a constant
to use in
training, or the number of passes (epochs) over the training data.
The second concerns the uneven margin function, for which we define
a constant ![]() used in training
to define a margin on the positive class. While training, an error
is made on a positive instance
used in training
to define a margin on the positive class. While training, an error
is made on a positive instance ![]() if
if
![]() ; the parameter on the
negative class
; the parameter on the
negative class ![]() and is
effectively ignored. The learning rule is:
and is
effectively ignored. The learning rule is:
| (2) |
The ranking function defined on the binary classifier is simply
the inner product between the pattern and the weight vector:
| (3) |
Given a weight vector ![]() , the
score for a pattern
, the
score for a pattern ![]() is
again the inner product between the pattern and the weight
vector:
is
again the inner product between the pattern and the weight
vector:
| (5) |

Figure 3: Examples of decision boundaries that can be learned by the linear, on the left, and non-linear models, on the right, in a two-dimensional case. X denotes positive (clicked) patterns while circles denote negative (non-clicked) patterns. The linear classifier depicted on the left correctly classifies the positive examples, but misclassifies a negative one. The non-linear classifier can find complex decision boundaries to solve such non-linearly separable cases.
One possible drawback of the previous methods is that they are limited to learning linear solutions. To improve the expressive power of our ranking functions, within the online perceptron approach, we experimented also with multilayer models. The topology of multilayer perceptrons includes at least one non-linear activation layer between the input and the output layers. Multi-layer networks with sigmoid non-linear layers can generate arbitrarily complex contiguous decision boundaries [8], as shown in Figure 3, and have been used successfully in several tasks, including learning to rank [3]. The multilayer perceptron is a fully connected three-layer network with the following structure:
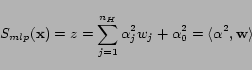
|
(6) |
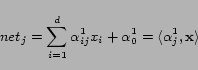
|
(7) |
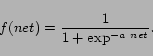
|
(8) |
Supervised training begins with an untrained network with
randomly initialized parameters. Training is carried out with
backpropagation [27]. An input
pattern ![]() is selected,
its score computed with a feedforward pass and compared to the true
value
is selected,
its score computed with a feedforward pass and compared to the true
value ![]() . Then the parameters are
adjusted to bring the score closer to the actual value of the input
pattern. The error
. Then the parameters are
adjusted to bring the score closer to the actual value of the input
pattern. The error ![]() on
a pattern
on
a pattern ![]() is the
squared difference between the guessed score
is the
squared difference between the guessed score
![]() and
the actual value
and
the actual value ![]() of
of ![]() , or for brevity
, or for brevity
![]() ; thus
; thus
![]() . After each iteration
. After each iteration
![]() ,
, ![]() is updated component-wise to
is updated component-wise to ![]() by taking a step in weight space which lowers the
error function:
by taking a step in weight space which lowers the
error function:
| (9) | |||
| (10) |
| (11) |
|
|||||||||||||||||||||||||||||||||||||||||
| (12) |
The second feature has a value of one if some of the query terms
are present in the ad:
| (13) |
The third feature has a value of one if none of the query terms
are present in the ad:
| (14) |
The fourth feature is the percentage of the query terms that have an exact match in the ad materials.
Prior to computing the features, both the query and the ad were normalized for case. For the purpose of word overlap, we chose to stem and stop less aggressively than we would do with functions that are smoothed. For this reason we used a Krovetz stemmer [18], and only single characters were removed.
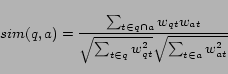
|
(15) |
The ![]() weight
weight ![]() of term
of term ![]() in
in ![]() is computed in the same way. We have also computed the
cosine similarity between
is computed in the same way. We have also computed the
cosine similarity between ![]() and
each of the fields of the ads, that is, the ad title
and
each of the fields of the ads, that is, the ad title ![]() , the ad description
, the ad description ![]() and its bidded terms
and its bidded terms ![]() . In all cases, we have
applied Porter's stemming algorithm and we have removed stop
words.
. In all cases, we have
applied Porter's stemming algorithm and we have removed stop
words.
Cosine similarity has been used effectively for ranking ads to place on Web pages in the setting of contextual advertising [25,6]. A difference with our setting is that in the case of contextual advertising, the cosine similarity is computed between the Web page and ad. While there are more complex similarity functions that have been developed and applied for the case of computing the similarity between short snippets of text [28], we use cosine similarity because it is parameter free and inexpensive to compute.
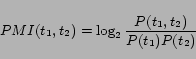
|
(17) |
We form the pairs of ![]() and
and ![]() by extracting the query
terms and the bidded terms of the ad. We only consider pairs of
terms consisting of distinct terms with at least one letter. For
each pair
by extracting the query
terms and the bidded terms of the ad. We only consider pairs of
terms consisting of distinct terms with at least one letter. For
each pair ![]() we use two
features: the average PMI and the maximum PMI, denoted by AvePMI
and MaxPMI, respectively.
we use two
features: the average PMI and the maximum PMI, denoted by AvePMI
and MaxPMI, respectively.
|
|
An overview of the features we use is shown in Table 1. All feature values were
normalized by column across the entire dataset with a ![]() , in order to have
zero mean and unit standard deviation, thus each feature
, in order to have
zero mean and unit standard deviation, thus each feature ![]() was standardized
as:
was standardized
as:
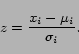
|
(19) |
Before continuing, it is important to observe that all the features we described in this section can be computed efficiently. For example, the word overlap and cosine similarity features can be computed online, when a user query is received. The correlation features can also be computed online efficiently by using a look-up table with word co-occurrence information for pairs of words.
We split the dataset into one training set, 5 development sets and 5 test sets, so that all the blocks for a given query are in the same set. The exact number of blocks for each of the development and test sets is given in Table 3. The training set consists of 109,560 blocks.
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
A ranking algorithm produces a score for each query-ad pair. The ads are ranked according to this score. Because of the way the data is constructed to account for the relative position of clicks, each block has only one click associated with it. For this reason we evaluate the precision at rank one, which tells us how many clicked ads were placed in the first position by the ranker, and the mean reciprocal rank, which tells us the average rank of the clicked ad in the output of the ranker. The mean reciprocal rank is computed as:
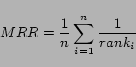
|
(20) |
In the classification case we set the parameters ![]() and
and ![]() . We tried three values
for
. We tried three values
for ![]() , 1, 10 and 100, and
found 100 to give the best results. As for the number of
iterations, we found that all models (not only in classification)
tended to converge quickly, rarely requiring more than 20
iterations to find the best results.
, 1, 10 and 100, and
found 100 to give the best results. As for the number of
iterations, we found that all models (not only in classification)
tended to converge quickly, rarely requiring more than 20
iterations to find the best results.
In the ranking model, in addition to the number of iterations
![]() we optimize the positive
learning margin
we optimize the positive
learning margin ![]() . We obtained
the best results with the value
. We obtained
the best results with the value ![]() , which we used in all experiments with ranking
perceptron.
, which we used in all experiments with ranking
perceptron.
The multilayer model has a number of adjustable parameters, some
of the parameters were kept with default values; e.g., the sigmoid
parameter ![]() [8]. Following [8] we initialized the network
weights for the hidden-to-output units uniformly at random in the
interval
[8]. Following [8] we initialized the network
weights for the hidden-to-output units uniformly at random in the
interval
![]() , the input-to-hidden weights were initialized randomly in the
interval
, the input-to-hidden weights were initialized randomly in the
interval
![]() . On the development data we found that hidden layers with 50
units, and
. On the development data we found that hidden layers with 50
units, and ![]() , produced
fast training and stable results, we kept these values fixed on all
experiments involving the multilayer model. The number of
iterations was set on the development set, running a maximum of 50
iterations2.
, produced
fast training and stable results, we kept these values fixed on all
experiments involving the multilayer model. The number of
iterations was set on the development set, running a maximum of 50
iterations2.
The baseline model has only one feature, the cosine similarity
between the ad and the query with ![]() weights. Table 4
shows the results for classification, ranking, and multilayer
regression for each of the five test sets concatenated. That is,
for the five test folds evaluated as one dataset, in order to
compute the significance of the mean reciprocal rank results. For
mean reciprocal rank we used a paired t-test. Results indicated
with a star are significant at the
weights. Table 4
shows the results for classification, ranking, and multilayer
regression for each of the five test sets concatenated. That is,
for the five test folds evaluated as one dataset, in order to
compute the significance of the mean reciprocal rank results. For
mean reciprocal rank we used a paired t-test. Results indicated
with a star are significant at the ![]() level with respect to the baseline. Most of the
significant results are significant at the
level with respect to the baseline. Most of the
significant results are significant at the ![]() level with respect to the baseline. The
precision at one results were not tested for statistical
significance. The significance for this metric is not computed
because it is not appropriate for binary data.
level with respect to the baseline. The
precision at one results were not tested for statistical
significance. The significance for this metric is not computed
because it is not appropriate for binary data.
We see that multilayer regression outperforms both classification and ranking, and further that the correlation features are a significant improvement over the other models. For one third of the examples in the evaluation, the predictor correctly identifies that the first result was clicked, and an MRR of 0.60 indicates that on average the clicked result was between rank one and rank two.
Although the standard deviation is high, around ![]() for each model, this is
to be expected because MRR can take values of 1, 0.5, 0.34, 0.25,
0.20, 0.18, etc. An average MRR of 0.6 indicates that most clicked
ads were at positions 1, 2 and 3. If half of the results had an MRR
of 1, and the other half had an MRR of 0.34, the mean would be
0.67, resulting in a standard deviation of 0.34. Thus the high
standard deviation in this case is an artifact of the metric.
for each model, this is
to be expected because MRR can take values of 1, 0.5, 0.34, 0.25,
0.20, 0.18, etc. An average MRR of 0.6 indicates that most clicked
ads were at positions 1, 2 and 3. If half of the results had an MRR
of 1, and the other half had an MRR of 0.34, the mean would be
0.67, resulting in a standard deviation of 0.34. Thus the high
standard deviation in this case is an artifact of the metric.
We also compute the averages and standard deviation across the five test sets, shown in Table 5. As indicated by the standard deviation for the trials, the method is robust to changes in the data set, even for precision at 1 which is in general a much less stable evaluation metric. As already shown for content match [25,19,6] weighting the similarity of each component separately and adding features about the degree of overlapping between query and ad improve significantly over the baseline. The best result for each model are achieved adding the term correlation features.
The non-linear multilayer perceptron outperforms both linear models. Interestingly, both linear models when using also the correlation features seem to perform better when only use one (PMI or chi-squared) rather than both, (see Table 5). This might depend on the fact that the features are strongly correlated and the linear classifier does not posses enough information to prefer one over the other in case of disagreements. Thus it finds a better solution by trusting always one over the other. The non-linear model instead has enough expressive power to capture subtler interactions between features and achieves the best results using both features. Another interesting aspect is that, although there are only two possible rankings, and thus the problem boils down to a binary classification task, the linear ranking perceptron outperforms the simpler classifier. The difference seems to lie in the way training is performed, by considering pairwise of patterns. Previous work on learning to rank [3] has proposed methods for training on pairs of patterns in multilayer architectures. This is a natural direction for further investigation of this type of model.
In terms of the features, even the simple word overlap features produced statistically significant results over the baseline model. Since we are effectively re-ranking ad candidates retrieved by a retrieval system which we treat as a black box, candidates are biased by the initial ad placement algorithm, and it is possible that the initial retrieval system preferred ads with a high degree of lexical overlap with the query, and the word overlap features provided a filter for those ads. The correlation features, which capture related terms rather than matching terms, added a significant amount of discriminative information. Such features are particularly promising because they are effectively language-independent and knowledge free. Similar statistics can be extracted from many resources simple to compile, or even generated by a search engine. Overall these findings suggest both that relevant ads contain words related to the query, and that related terms can be captured efficiently with correlation measures such as pointwise mutual information and the chi-squared statistic. There are several opportunities for further investigation of this type of features, for example by machine translation modeling [23].
One limitation of the current way of modeling click data is that ``relevance'' judgments induced by the logs are strictly binary. We have seen that using pairwise information is useful in training and it may be desirable to generate more complex multi-valued feedback. Joachims et al. [14] proposed manipulating the presentation of candidates to users by swapping the order of contiguous candidates to obtain likelihood ratios. An interesting question is how such information might be automatically extracted from query logs.
Advertisements are represented in part by their keywords. In one model of Online advertising, ads are matched to queries based on the keywords, and advertisers bid for the right to use the keywords to represent their product. So a related task is keyword suggestion, which can be applied to sponsored search or to its sister technology, contextual advertising, which places an ad in a Web page based on the similarity between the ad and the Web page content. Carrasco et al. [4] approach the problem of keyword suggestion by clustering bi-partite advertiser-keyword graphs. Yih et al. [33] extract keywords from Web pages using features such as the term frequency, the inverse document frequency, and the presence of terms in the query logs. They stop short of using the keywords in an application.
Although we do not consider economic factors in our work,
implicit in the task of ranking ads to improve the relevance at the
top of the list, is the desire to increase user clicks. Feng et
al. [9]
investigate the effects of four different ranking mechanisms for
advertisements in sponsored search on revenue. Two of the
mechanisms depend wholly on the bid price of the terms. Of the
remaining two, one proposes ranking ads by their expected
clickthrough rate, and the other by a function of the bid price and
the expected clickthrough rate. The focus of this work is on the
economic impact of the advertising placement mechanism, and uses a
simulated environment which treats as a variable the degree of
correlation between the advertiser's willingness to pay for
advertising slots, and the amount of traffic they attract. They
find that ranking ads by a function of the bid price and the
clickthrough rate outperforms other ranking mechanisms. They
further explore using the clickthrough rate to dynamically update
the ranking mechanism. They investigate two weighting schemes for
user clicks. In the unweighted scheme, an ad's clickscore is
increased by 1 every time it is clicked. In the weighted scheme the
ad's clickscore is increased by ![]() where
where ![]() is the rank
of the clicked ad, which has the effect of damping the scores of
clicks in the top positions, and boosting the scores of ads in
lower positions, which is one way of addressing the positional bias
in user clicks. There are several key differences between this work
and ours. First, the evaluation metric in Feng et al. is the
expected revenue, whereas we evaluate the relevance of the ads. The
work by Feng et al. is done in a simulated environment,
whereas ours is performed on data from the search engine. They use
the clickthrough data as a measure of absolute relevance, rather
than as a measure of relevance relative to other ads that were not
clicked. Finally, and most importantly, they are assessing the
intrinsic relevance of an ad, independent of the context of the
user's query.
is the rank
of the clicked ad, which has the effect of damping the scores of
clicks in the top positions, and boosting the scores of ads in
lower positions, which is one way of addressing the positional bias
in user clicks. There are several key differences between this work
and ours. First, the evaluation metric in Feng et al. is the
expected revenue, whereas we evaluate the relevance of the ads. The
work by Feng et al. is done in a simulated environment,
whereas ours is performed on data from the search engine. They use
the clickthrough data as a measure of absolute relevance, rather
than as a measure of relevance relative to other ads that were not
clicked. Finally, and most importantly, they are assessing the
intrinsic relevance of an ad, independent of the context of the
user's query.
Contextual advertising is a sister technology to sponsored search, and many of the techniques used to place ads in Web pages may be used to place ads in response to a user's query. As with sponsored search, contextual advertising is usually a pay-per-click model, and the ad representations are similar in both sponsored search and contextual advertising. The primary difference is that rather than matching an ad to a query, the system matches the ad to a Web page.
Contextual advertising also suffers from the vocabulary mismatch problem. To compensate for this, Ribeiro-Neto et al. [25] augment the representation of the target page using additional Web pages. As a follow-on to this work, Lacerda et al. [19] select ranking functions using genetic programming, maximizing the average precision on the training data. Broder et al. [2] use a semantic taxonomy to find topically similar terms, to facilitate the match between an ad and a Web page.
The current paper is a follow-on to work in contextual advertising, presented in [6] and [23]. Key differences in the current work are the use of click data in place of human edited relevance judgments, both for learning a ranking function and for evaluation, the application to sponsored search rather than content match, and the use of several different types of classifiers.
Joachims [13] proposes that user
clicks can be used to learn ranking functions for search engine
results by considering that a user click is an indicator of
relative relevance. That is, a click at rank ![]() indicates that the document
at rank
indicates that the document
at rank ![]() is more relevant than
unclicked documents that preceded it in the ranked list. We adopt
this ranking mechanism directly in our work, as described in
Sections 2 and 5, however in addition to using it for
training, we also use this ranking mechanism for evaluation. Also,
Joachims [13] is the first in a
series of work investigating using implicit user feedback, such as
user clicks, for learning ranking functions. An overview of using
implicit user feedback as surrogates for editorial relevance
judgments can be found in [16].
is more relevant than
unclicked documents that preceded it in the ranked list. We adopt
this ranking mechanism directly in our work, as described in
Sections 2 and 5, however in addition to using it for
training, we also use this ranking mechanism for evaluation. Also,
Joachims [13] is the first in a
series of work investigating using implicit user feedback, such as
user clicks, for learning ranking functions. An overview of using
implicit user feedback as surrogates for editorial relevance
judgments can be found in [16].