A typical search engine of today usually allows a user to submit a bunch of keywords as a query. This simple user interface greatly eases use of the search engine, and is sufficient for the traditional bag-of-words retrieval model, where query and document are assumed to be composed of individual words neither related nor ordered. In the quest for higher retrieval accuracy, however, it is necessary to understand the user's search intent beyond the simple bag-of-words query model. At a minimum, we would like to know whether some words comprise an entity like an organization name, which makes it possible to enforce word proximity and ordering constraints on document matching, among other things.
A partial solution provided by many search engines is that a user can put double quotes around some query words to mandate they appear together as an inseparable group in retrieved documents. Aside from sometimes being overly limiting, this double-quote proximity operator requires additional efforts from the user. However, a typical user may be unaware of the syntax, or reluctant to make this clarification unless really dissatisfied with the results. It would be desirable if the structural relationship underlying the query words could be automatically identified.
Query segmentation is one of the first steps in this direction. It aims to separate query words into segments so that each segment maps to a semantic component, which we refer as a ``concept''. For example, for the query ``new york times subscription'', [new york times] [subscription] is a good segmentation, while [new] [york times] [subscription] and [new york] [times subscription] are not, as segments like [new york] and [york times] greatly deviate from the intended meaning of the query.
Ideally, each segment should map to exactly one ``concept''. For segments like [new york times subscription], the answer of whether it should be left intact as a compound concept or further segmented into multiple atomic concepts depends on the connection strength of the components (i.e. how strong / often are ``new york times'' and ''subscription'' associated) and the application (e.g., whether query segmentation is used for query understanding or document retrieval). This leaves some ambiguity in query segmentation, as we will discuss later.
Query segmentation could help a retrieval system to improve its accuracy, as segments carry implicit word proximity / ordering constraints, which may be used to filter documents. For example, we would expect ``new'' to be near (and probably just before) ``york'' in matching documents. Query segmentation should also be useful in other query processing tasks such as query rewriting and query log analysis, where one would be able to work on semantic concepts instead of individual words [2,8,21].
Interestingly, there is little investigation done of query segmentation, in spite of its importance. To our knowledge, two approaches have been studied in previous works. The first is based on (pointwise) mutual information (MI) between pairs of query words. In [23,14], if the MI value between two adjacent words is below a predefined threshold, a segment boundary is inserted at that position. The problem with this approach is that MI, by definition, cannot capture correlations among more than two words, thus it cannot handle long entities like song names, where MI may be low in certain positions (e.g., between ``heart'' and ``will'' in ``my heart will go on''). Another problem with this approach, which is also true with most unsupervised learning methods, is its heavy reliance on corpus statistics. In some cases highly frequent patterns with incomplete semantic meaning may be produced. For example, ``leader of the" is a fairly frequent pattern, but it is certainly not a self-contained semantic concept.
The second approach [4] uses supervised learning. At
each word position, a binary decision is made whether to create a
segment boundary or not. The input features to the decision
function are defined on words within a small window at that
position. The features include part-of-speech tags, position, web
counts, etc., with their weights learned from labeled training
data. Although the window size is set to 4 to capture a certain
degree of long-range dependencies, the segmentation decisions are
still local in essence. Moreover, their features are specifically
designed for noun-phrase queries (queries comprised of multiple
noun phrases). For example, one feature is the web count of
``![]() and
and ![]() '' for two adjacent words
'' for two adjacent words ![]() and
and ![]() , which is not helpful for
general queries. Another problem with this approach, and with all
supervised learning methods, is that it requires a significant
number of labeled training samples and well designed features to
achieve good performance. This makes it hard to adapt to other
languages, domains, or tasks.
, which is not helpful for
general queries. Another problem with this approach, and with all
supervised learning methods, is that it requires a significant
number of labeled training samples and well designed features to
achieve good performance. This makes it hard to adapt to other
languages, domains, or tasks.
In this paper, we propose an unsupervised method for query segmentation that alleviates the shortcomings of the current approaches. Three characteristics make our approach unique. First, we use a statistical language modeling approach that captures the high-level sequence generation process rather than focusing on local between-word dependencies as mutual information does. Second, in order to avoid running expectation-maximization (EM) algorithm on the whole dataset, which is quite expensive, we propose an EM algorithm that performs optimization on the fly for incoming queries. Third, instead of limiting to use query logs, we combine resources from the Web. In particular, we use Wikipedia to provide additional evidence for concept discovery, which proves to be quite successful. In our experiments, we test our method on human annotated test sets, and find language modeling, EM optimization and Wikipedia knowledge each brings improvement to query segmentation performance.
In the rest of the paper, we will first describe other related work in Section 2. We then in Section 3 describe the generative language model for query segmentation. Section 4 discusses the techniques for parameter optimization, including a method for estimating long n-gram's frequency and an EM learning algorithm. In Section 5, we describe how to incorporate additional knowledge such as Wikipedia into our segmentation model. Practical system implementation is discussed in in Section 6. We present experiment results in Section 7 and its discussions in Section 8. Finally, we conclude the paper in Section 9.
In natural language processing, there has been a significant amount of research on text segmentation, such as noun phrase chunking [22], where the task is to recognize the chunks that consist of noun phrases, and Chinese word segmentation [5,18,25], where the task is to delimit words by putting boundaries between Chinese characters. Query segmentation is similar to these problems in the sense that they all try to identify meaningful semantic units from the input. However, one may not be able to apply these techniques directly to query segmentation, because Web search query language is very different (queries tend to be short, composed of keywords), and some essential techniques to noun phrase chunking, such as part-of-speech tagging [6], can not achieve high performance when applied to queries. Thus, detecting noun phrase for information retrieval has been mainly studied in document indexing [3,11,26,24] rather than query processing.
In terms of unsupervised methods for text segmentation, the expectation maximization (EM) algorithm has been used for Chinese word segmentation [19] and phoneme discovery [16], where a standard EM algorithm is applied to the whole corpus. As pointed out in [19,16], running EM algorithm over the whole corpus is very expensive. To avoid this costly procedure, for each incoming query, we run an EM algorithm on the fly over the affected sub-corpus only. Since a query is normally short and the sub-corpus relevant to it is also quite small, this online procedure is very fast. A second difference is that we augment unsupervised learning with Wikipedia as external knowledge, which dramatically improves query segmentation performance. We combine multiple evidence using the minimum description length principle (MDL), which has been applied widely to problems such as grammar induction [13] and word clustering [15]. To some extent, utilizing external knowledge is similar to having some seed labeled data for unsupervised learning as used in [1], only that Wikipedia is readily available.
Wikipedia has been used in many applications in NLP, including named entity disambiguation [7,9], question answering [10], text categorization [12], and conference resolution [20]. To our knowledge, this is the first time that it is used in query segmentation.
When a query is being formulated in people's mind, it is natural to believe that the building blocks in the thinking process are ``concepts'' (possibly multi-word), rather than single words. For example, with the query ``new york'', the two words must have popped into one's brain together; if they were come up separately, the intended meaning would be vastly different. It is when the query is uttered (e.g., typed into a search box) that the concepts are ``serialized'' into a sequence of words, with their boundaries dissolved. The task of query segmentation is to recover the boundaries which separate the concepts.
Given that the basic units in query generation are concepts,
we make the further assumption that they are independent and
identically-distributed (I.I.D.). In other words, there is a
probability distribution ![]() of
concepts, which is sampled repeatedly, to produce
mutually-independent concepts that construct a query. This is
essentially a unigram language model, with a "gram" being not a
word, but a concept / segment.
of
concepts, which is sampled repeatedly, to produce
mutually-independent concepts that construct a query. This is
essentially a unigram language model, with a "gram" being not a
word, but a concept / segment.
The above I.I.D. assumption carries several limitations. First, concepts are not really independent of each other. For example, we are more likely to observe ``travel guide'' after ``new york'' than ``new york times''. Second, the probability of a concept may vary by its position in the text. For example, we expect to see ``travel guide'' more often at the end of a query than at the beginning. We could tackle the above problems by using a higher-order model (e.g., the bigram model) and adding a position variable, but this will dramatically increase the number of parameters that are needed to describe the model. Thus for simplicity the unigram model is used, and it proves to work reasonably well for the query segmentation task.
Let
![]() be a piece
of text of
be a piece
of text of ![]() words, and
words, and
![]() be a
possible segmentation consisting of
be a
possible segmentation consisting of ![]() segments, where
segments, where
![]()
For a given query ![]() , if it is
produced by the above generative language model, with concepts
repeatedly sampled from distribution
, if it is
produced by the above generative language model, with concepts
repeatedly sampled from distribution ![]() until the desired query is obtained, then the
probability of it being generated according to an underlying
sequence of concepts (i.e., a segmentation of the query)
until the desired query is obtained, then the
probability of it being generated according to an underlying
sequence of concepts (i.e., a segmentation of the query)
![]() is
is
The unigram model says
Thus we have
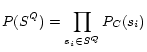
And the cumulative probability of generating ![]() is
is
For two segmentations ![]() and
and ![]() of the same piece of text
of the same piece of text
![]() , suppose they differ at only
one segment boundary, i.e.,
, suppose they differ at only
one segment boundary, i.e.,
Naturally, we will favor segmentations with higher probability
of generating the query. In the above case,
![]() (thus is
preferred) if and only if
(thus is
preferred) if and only if
![]() , i.e., when
, i.e., when
![]() and
and ![]() are negatively correlated. In other words, a
segment boundary is justified if and only if the pointwise mutual
information between the two segments resulting from the split is
negative:
are negatively correlated. In other words, a
segment boundary is justified if and only if the pointwise mutual
information between the two segments resulting from the split is
negative:
If we enumerate all possible segmentations, the ``best''
segmentation will be the one with the highest likelihood to
generate the query. We can also rank them by likelihood and
output the top ![]() . Having multiple
possibly correct segmentations is desirable if the correct
segmentation cannot be easily determined at query preprocessing
time: with a small number of candidates one can afford to ask the
user for feedback, or re-score them by inspecting retrieved
documents.
. Having multiple
possibly correct segmentations is desirable if the correct
segmentation cannot be easily determined at query preprocessing
time: with a small number of candidates one can afford to ask the
user for feedback, or re-score them by inspecting retrieved
documents.
In practice, segmentation enumeration is infeasible except for
short queries, as the number of possible segmentations grows
exponentially with query length. However, the I.I.D. nature of
the unigram model makes it possible to use dynamic programming
(Algorithm 1) for computing top
![]() best segmentations. The
complexity is
best segmentations. The
complexity is
![]() , where
, where
![]() is query length, and
is query length, and
![]() is maximum allowed segment
length.
is maximum allowed segment
length.
The central question that needs to be addressed is: how to determine the parameters of our unigram language model, i.e., the probability of the concepts, which take the form of variable-length n-grams. As this work focuses on unsupervised learning, we would like the parameters to be estimated automatically from provided textual data.
The primary source of data we use is a text corpus consisting
of a 1% sample of the web pages crawled by the Yahoo! search
engine. We count the frequency of all possible ![]() -grams up to a certain length (
-grams up to a certain length (
![]() ) that
occur at least once in the corpus. It is usually impractical to
do this for longer n-grams, as their number grows exponentially
with
) that
occur at least once in the corpus. It is usually impractical to
do this for longer n-grams, as their number grows exponentially
with ![]() , posing difficulties for
storage space and access time. However, for long n-grams
(
, posing difficulties for
storage space and access time. However, for long n-grams
(![]() ) that are also
frequent in the corpus, it is often possible to approximate their
counts using those of shorter n-grams.
) that are also
frequent in the corpus, it is often possible to approximate their
counts using those of shorter n-grams.
We compute lower bounds of long n-gram counts using set inequalities, and take them as approximation to the real counts. For example, the frequency for ``harry potter and the goblet of fire'' can be determined to lie in the reasonably narrow range of [5783, 6399], and we just use 5783 as an estimate for its true frequency. A dynamic programming algorithm is given next.
If we have frequencies of occurrence in a text corpus for all n-grams up to a given length, then we can infer lower bounds of frequencies for longer n-grams, whose real frequencies are unknown. The lower bound is in the sense that any smaller number would cause contradictions with known frequencies.
Let ![]() denote n-gram
denote n-gram
![]() 's frequency. Let
's frequency. Let ![]() be arbitrary n-grams,
and
be arbitrary n-grams,
and
![]() be their
concatenations. Let
be their
concatenations. Let
![]() denote the
number of times
denote the
number of times ![]() follows
follows
![]() or is followed by
or is followed by ![]() in the corpus. We
have
in the corpus. We
have
(1) follows directly from a basic equation on set cardinality:
Since
![]() , (2) holds.
, (2) holds.
Therefore, for any n-gram
![]() (
(![]() ), if we define
), if we define
(3) allows us to compute the frequency
lower bound for ![]() using
frequencies for sub-n-grams of
using
frequencies for sub-n-grams of ![]() ,
i.e., compute a lower bound for all possible pairs of
,
i.e., compute a lower bound for all possible pairs of ![]() , and choose their
maximum. In case
, and choose their
maximum. In case
![]() or
or
![]() is
unknown, their lower bounds, which are obtained in an recursive
manner, can be used instead. Note that what we obtain are not
necessarily greatest lower bounds, if all possible frequency
constraints are to be taken into account. Rather, they are
best-effort estimates using the above set inequalities.
is
unknown, their lower bounds, which are obtained in an recursive
manner, can be used instead. Note that what we obtain are not
necessarily greatest lower bounds, if all possible frequency
constraints are to be taken into account. Rather, they are
best-effort estimates using the above set inequalities.
In reality, not all ![]() pairs need
to be enumerated: if
pairs need
to be enumerated: if
![]() ,
then
,
then
(4) means that there is no need to
consider
![]() in the computation
of (3) if there is a sub-ngram
in the computation
of (3) if there is a sub-ngram
![]() longer than
longer than
![]() with known
frequency. This can save a lot of computation.
with known
frequency. This can save a lot of computation.
Algorithm 2 gives the frequency lower
bounds for all n-grams in a given query, with complexity
![]() , where
, where
![]() is the maximum length of
n-grams whose frequencies we have counted (5, in our case).
is the maximum length of
n-grams whose frequencies we have counted (5, in our case).
Next we explore several possible ways to estimate the n-gram probabilities given that their frequencies are known to us.
With the bag-of-words assumption that word occurrences are I.I.D., word frequencies in a piece of text follow a multinomial distribution. Given a set of word frequencies, the Maximum Likelihood Estimate (MLE) for the words' probabilities (parameterizing the multinomial distribution) is
It is easy to adapt the above equation to compute n-gram probabilities in the concept distribution:
There are two serious problems with this approach, however.
First, it is unclear what should be included in ![]() , the set of n-grams whose frequency sum is used
for normalization (so that probabilities sum up to 1). Obviously,
we cannot include arbitrarily long n-grams, as there is an
astronomical number of them. One way is to limit to n-grams up to
a certain length, for example, all n-grams whose exact
frequencies have been counted (in our case,
, the set of n-grams whose frequency sum is used
for normalization (so that probabilities sum up to 1). Obviously,
we cannot include arbitrarily long n-grams, as there is an
astronomical number of them. One way is to limit to n-grams up to
a certain length, for example, all n-grams whose exact
frequencies have been counted (in our case, ![]() ). But it is hard to justify why the other
n-grams should be excluded from the normalization sum.
). But it is hard to justify why the other
n-grams should be excluded from the normalization sum.
More importantly, the probability of an n-gram in the concept distribution should describe how likely the n-gram is to appear in a piece of text as an independent concept. However, this cannot be captured by the raw frequencies. For example, since it is always true
Suppose we have already segmented the entire text
corpus into concepts in a preprocessing step. We can then use
(5) without any problem: the frequency of
an n-gram will be the number of times it appears in the corpus
as a whole segment. For example, in a correctly
segmented corpus, there will be very few ``york times'' segments
(most ``york times'' occurrences will be in the ``new york
times'' segments), resulting in a small value of
![]() ,
which makes sense. However, having people manually segment the
documents is only feasible on small datasets; on a large corpus
it will be too costly.
,
which makes sense. However, having people manually segment the
documents is only feasible on small datasets; on a large corpus
it will be too costly.
An alternative is unsupervised learning, which does not need human-labeled segmented data, but uses large amount of unsegmented data instead to learn a segmentation model. Expectation maximization (EM) is an optimization method that is commonly used in unsupervised learning, and it has already been applied to text segmentation [16,19]. The EM algorithm goes like this: In the E-step, the unsegmented data is automatically segmented using the current set of estimated parameter values, and in the M-step, a new set of parameter values are calculated to maximize the complete likelihood of the data which is augmented with segmentation information. The two steps alternate until a termination condition is reached (e.g. convergence).
The major difficulty is that, when the corpus size is very large (in our case, 1% of crawled web), it will still be too expensive to run these algorithms, which usually require many passes over the corpus and very large data storage to remember all extracted patterns.
To avoid running the EM algorithm over the whole corpus, we propose an alternative: running EM algorithm on the fly, only on a partial corpus that is specific to a query. More specifically, when a new query arrives, we extract parts of the corpus that overlap with it (we call this the query-relevant partial corpus), which are then segmented into concepts, so that probabilities for n-grams in the query can be computed. All non-relevant parts unrelated to the query of concern are disregarded, thus the computation cost is dramatically reduced.
We can construct the query-relevant partial corpus in a procedure as follows. First we locate all words in the corpus that appear in the query. We then join these words into longer n-grams if the words are adjacent to each other in the corpus, so that the resulting n-grams become longest matches with the query. For example, for the query ``new york times subscription'', if the corpus contains ``new york times'' somewhere, then the longest match at that position is ``new york times'', not ``new york'' or ``york times''. This longest match requirement is effective against incomplete concepts, which is a problem for the raw frequency approach as previously mentioned. Note that there is no segmentation information associated with the longest matches; the algorithm has no obligation to keep the longest matches as complete segments. For example, it can split ``new york times'' in the above case to ``new york'' and ``times'' if corpus statistics make it more reasonable to do so. However, there are still two artificial segment boundaries created at each end of a longest match (which means, e.g., ``times'' cannot associate with the word ``square'' following it but not included in the query). This is a drawback of our query-specific partial-corpus approach.
Because all non-query-words are disregarded, there is no need to keep track of the matching positions in the corpus. Therefore, the query-relevant partial corpus can be represented as a list of n-grams from the query, associated with their longest match counts:
The partial corpus represents frequency information that is most directly related to the current query. We can think of it as a distilled version of the original corpus, in the form of a concatenation of all n-grams from the query, each repeated for the number of times equal to their longest match counts, with other words in the corpus all substituted by a wildcard:
Practically, the longest match counts can be computed from raw frequencies efficiently, which we have either counted or approximated using lower bounds. The procedure is described below:
Given query ![]() , let
, let ![]() be an n-gram in
be an n-gram in ![]() ,
,
![]() be the set of
words that precede
be the set of
words that precede ![]() in
in ![]() , and
, and
![]() be the set of
words that follow
be the set of
words that follow ![]() in
in ![]() . For example, if
. For example, if ![]() is ``new york times new
subscription'', and
is ``new york times new
subscription'', and ![]() is ``new'',
then
is ``new'',
then
![]() and
and
![]() .
.
The longest match count for ![]() is
essentially the number of occurrences of
is
essentially the number of occurrences of ![]() in the corpus not preceded by any word from
in the corpus not preceded by any word from
![]() and not followed
by any word from
and not followed
by any word from
![]() , which we
denote as
, which we
denote as ![]() .
.
Let ![]() be the total number of
occurrences of
be the total number of
occurrences of ![]() , i.e.,
, i.e., ![]() .
.
Let ![]() be the number of occurrences
of
be the number of occurrences
of ![]() preceded by any word from
preceded by any word from
![]() .
.
Let ![]() be the number of occurrences
of
be the number of occurrences
of ![]() followed by any word from
followed by any word from
![]() .
.
Let ![]() be the number of occurrences
of
be the number of occurrences
of ![]() preceded by any word from
preceded by any word from
![]() and at the same
time followed by any word from
and at the same
time followed by any word from
![]() .
.
Then it is easy to see
![]()
Algorithm 3 computes the longest match
count. Its complexity is ![]() , where
, where ![]() is the query length.
is the query length.
If we treat the query-relevant partial corpus
![]() as a source of
textual evidence, we can use maximum a posteriori estimation
(MAP), choosing parameters
as a source of
textual evidence, we can use maximum a posteriori estimation
(MAP), choosing parameters ![]() (the set of concept probabilities) to maximize the posterior
likelihood given the observed evidence:
(the set of concept probabilities) to maximize the posterior
likelihood given the observed evidence:
The above equation can also be written as
For the corpus description length, we have the following
according to the distilled corpus representation in (6):
The probability of text ![]() being
generated can be summed over all of its possible
segmentations:
being
generated can be summed over all of its possible
segmentations:
For the description length of prior parameters ![]() , we compute it as
, we compute it as
To estimate the n-gram probabilities with the above minimum
description length set-up, we use the variant Baum-Welch
algorithm from [16]. We
also follow [16] to
delete from the lexicon all n-grams that reduce the total
description length when deleted. The complexity of the algorithm
is
![]() , where
, where
![]() is the number of different
n-grams in the partial corpus, and
is the number of different
n-grams in the partial corpus, and ![]() is the number of deletion phases (usually quite small). In
practice, the above EM algorithm converges quickly and can be
done without user's awareness.
is the number of deletion phases (usually quite small). In
practice, the above EM algorithm converges quickly and can be
done without user's awareness.
The main problem with the above minimum description length approach is that it only tries to optimize the statistical aspects of the concepts; there is no linguistic consideration involved to guarantee that the output concepts are well-formed ones. For example, for the query ``history of the web search engine'', the best segmentation is [history of the][web search engine]. This is because ``history of the'' is a relatively frequent pattern in the corpus, helping to reduce the corpus description length quite much when it is assigned a high probability. Clearly we need to resort to some external knowledge to make sure that the output segments are well-formed concepts, not just frequent patterns. Many such knowledge resources are available from the NLP works, for example, named entity recognizer and noun phrase models, each shedding unique insight on what a well-formed concept should look like. In this paper, we explore a new approach, using Wikipedia to guide query segmentation.
Wikipedia, the largest encyclopedia on the Internet, is known for its high-quality collaboratively edited page contents. We find the Wikipedia article titles particularly suitable to our needs: First, the articles span a huge number of topics with extremely wide coverage, ranging from persons to locations, from movies to scientific theorems, able to match the great diversity of web search queries. Second, most articles are about well-established topics that are known to a reasonably-sized community, thus we can avoid dealing with large numbers of infrequently used concepts (e.g. the name of a local business, which is more easily handled by a specialized name identifier). Third, the articles are updated very fast, thus one can keep the concept dictionary up with the latest trend.
There are two difficulties with Wikipedia titles. First, the titles are mostly canonicalized. For example, plural form of nouns are rarely seen in titles. To allow other forms to be used, we include anchor texts / aliases pointing to a page as alternatives to its title, if the frequency is not low. For example, our vocabulary includes both ``U.S.A'' and ``United States'', despite that only the latter is an article title. Second, some pages are about topic involving multiple entities, e.g., ``magical objects in harry potter''. In this case, we set a threshold on the number of in-links (eliminating those pages whose counts are beneath it, which tend to be discussing rare topics) and allow long titles to be segmented into shorter concepts. For example, we can get two concepts, ``magical objects'' and ``harry potter'' from the previous title. In August 2007, we extract a total of 2.3 million ``concepts'' from 1.95 million articles in the English Wikipedia.
To use Wikipedia titles, we introduce a third term in our description length minimization scheme:
To use the parameter estimation algorithms for query segmentation, which is a task usually demanding real-time response, it is critical to have fast access to arbitrary n-grams' frequencies. According to Algorithm 2, long n-grams' frequencies can often be approximated using those of shorter ones, but there are still a lot of n-grams whose frequencies need to be maintained. In our case, we count frequencies for all n-grams with length up to 5 and non-zero occurrences in the web corpus. Due to the huge corpus size (33 billion words in length), we choose to accumulate counts using a simple map-reduce procedure that is run on a Hadoop1 cluster. The resulting ngram number is 464 million, which makes it almost impossible to store the entire ngram-to-frequency dictionary in memory. We tackle this using Berkeley DB2, which is a high-performance storage engine for key/value pairs. Berkeley DB enables us to maintain an in-memory cache, from which the most frequent n-grams can be looked up quickly (without reading from disk). We use BTree as the access method. We sort the ngram-frequency pairs before inserting them into DB, so that the resulting database file is highly compact. The cache size is set to 1GB.
Figure 1 illustrates the architecture of our system. With such an implementation, our system can segment 500 queries per second on a single machine.
We experiment on the data sets previously used by [4] for supervised query segmentation, so that it is easy to make performance comparison between our work and theirs. According to [4], the queries were sampled from the AOL search logs [17], each of length four or greater, with only determiners, adjectives and nouns as query words, and having at least one clicked results.
There are three sets, each containing 500 queries, one for training, one for validation, and another for testing. One annotator (we call him/her A) manually segmented all three sets, and two additional annotators (B and C) segmented the testing set to provide alternative judgments. Since our work is unsupervised query segmentation, we have no need for the training set, and we are able to test against all three annotators. We use the combined training and validation sets for parameter tuning, and evaluate on the testing set.
As will be discussed later, the inter-annotator agreement is found to be quite low. For example, A gives an identical segmentation only to 58% of all queries when checking with B, and 61% with C. This vast inconsistency arises largely from the difficulty in appropriately defining a segment. For example, one might think ``bank manager'' should be kept in a single segment, but when retrieving documents, it is advantageous to separate them to two segments, to match such text as ``manager of ABC bank''. We evaluate our results against all three annotators as a result of this segmentation ambiguity. As in [4], we pick out all queries for which the three annotators make a unanimous segmentation decision. This set of 219 queries is referred as Intersection. We make another derived test set called Conjunction, on which it is considered correct when a segmentation matches what is given by any of the three annotators.
We adopt three different evaluation metrics:
Bergsma and Wang [4] view query segmentation as a classification problem: at each position between two words, one makes a binary decision on whether to insert a segment boundary or not. Thus one can measure the accuracy of the classification decisions. The metric is known as Seg-Acc in [4].
If we treat the human-annotated segmentation as a set of
``relevant'' segments, we can measure how well the predicted
segmentation recovers these segments. Using Information
Retrieval terminology, we compute precision (percentage of
segments in the predicted segmentation that are relevant),
recall (percentage of relevant segments that are found in the
predicted segmentation) and F measure ( 2 ![]() precision
precision
![]() recall / (
precision + recall ) ).
recall / (
precision + recall ) ).
This is the percentage of queries for which the predicted segmentation matches the human-annotated one completely. It is the same as Qry-Acc in [4].
We see that from classification accuracy to segment accuracy, to query accuracy, the metrics become more strict in judging how well the predicted segmentation matches the human-annotated one.
We use mutual information based segmentation as our baseline (referred as MI), whose parameters are tuned on the training + validation query set. Our methods include the language modelling approach using MLE on raw n-gram frequencies (referred as LM), LM approach optimized by the EM algorithm (EM), LM approach augmented by Wikipedia knowledge (LM+Wiki), and EM approach augmented by Wikipedia knowledge (EM+Wiki).
We set ![]() (weight on
parameter description length) to 10, and
(weight on
parameter description length) to 10, and ![]() (weight on Wikipedia knowledge) to 100000. Both are
tuned on the training + validation set.
(weight on Wikipedia knowledge) to 100000. Both are
tuned on the training + validation set.
| MI | LM | EM | LM+Wiki | EM+Wiki | ||
| Annotator A | query accuracy | 0.274 | 0.356 | 0.414 | 0.500 | 0.526 |
| classification accuracy | 0.693 | 0.741 | 0.762 | 0.801 | 0.810 | |
| segment precision | 0.469 | 0.502 | 0.562 | 0.631 | 0.657 | |
| segment recall | 0.534 | 0.473 | 0.555 | 0.608 | 0.657 | |
| segment F | 0.499 | 0.487 | 0.558 | 0.619 | 0.657 | |
| Annotator B | query accuracy | 0.244 | 0.436 | 0.440 | 0.508 | 0.494 |
| classification accuracy | 0.634 | 0.776 | 0.774 | 0.807 | 0.802 | |
| segment precision | 0.408 | 0.552 | 0.568 | 0.625 | 0.623 | |
| segment recall | 0.472 | 0.539 | 0.578 | 0.619 | 0.640 | |
| segment F | 0.438 | 0.545 | 0.573 | 0.622 | 0.631 | |
| Annotator C | query accuracy | 0.264 | 0.394 | 0.416 | 0.492 | 0.494 |
| classification accuracy | 0.666 | 0.754 | 0.759 | 0.797 | 0.796 | |
| segment precision | 0.451 | 0.528 | 0.558 | 0.622 | 0.634 | |
| segment recall | 0.519 | 0.507 | 0.561 | 0.608 | 0.642 | |
| segment F | 0.483 | 0.517 | 0.559 | 0.615 | 0.638 | |
| Intersection | query accuracy | 0.343 | 0.468 | 0.528 | 0.652 | 0.671 |
| classification accuracy | 0.728 | 0.794 | 0.815 | 0.867 | 0.871 | |
| segment precision | 0.510 | 0.580 | 0.640 | 0.744 | 0.767 | |
| segment recall | 0.550 | 0.560 | 0.650 | 0.733 | 0.782 | |
| segment F | 0.530 | 0.569 | 0.645 | 0.738 | 0.774 | |
| Conjunction | query accuracy | 0.381 | 0.570 | 0.597 | 0.687 | 0.692 |
| classification accuracy | 0.758 | 0.846 | 0.856 | 0.890 | 0.891 | |
| segment precision | 0.582 | 0.680 | 0.715 | 0.787 | 0.797 | |
| segment recall | 0.654 | 0.663 | 0.721 | 0.775 | 0.807 | |
| segment F | 0.616 | 0.671 | 0.718 | 0.781 | 0.801 |
Table 1 presents the evaluation results of different query segmentation algorithms on the test sets, with the best performance of segment F on each dataset in bold. There are some interesting observations from Table 1. The first thing to note is that all three types of segmentation accuracy are highly consistent: the Pearson's linear correlation coefficients is 0.91 between segment F and classification accuracy, and 0.89 between segment F and query accuracy.
For web search, it is particularly important to be able to identify query concepts, which is directly measured by segment accuracy. Thus we place special emphasis on this metric in the following discussion. We also draw a bar chart (Figure 2) comparing segment F of different algorithms across the test sets.
From Table 1 (or Figure 2), we observe a consistent trend of segment F increasing from left to right, with the only exception on dataset A, where there is a slight decrease from MI (0.499) to LM (0.487) (statistically insignificant with p-value of t-test being 0.47).
Comparing LM with MI, LM has much higher query accuracy (increases range from 30% (on A) to 78% (on B)) and classification accuracy (increases range from 7% (on A) to 22% (on B)), with all increases being statistically significant (p-value of t-test is close to 0). For segment accuracy, LM tends to have balanced precision and recall, while MI tends to have higher recall than precision. This is because MI, being a local model that does not capture long dependencies, tends to create more segments, thus producing high recall yet low precision. Overall (with the F measure), the LM model achieves higher segment accuracy, up to a 24% increase (on B). The fact that the language modeling approach performs significantly better than the mutual information approach shows the advantage of modeling query structure with the concept generation process.
The performance of LM is further improved with EM optimization. Comparing to LM, segment F has an additional improvement of 5% - 15% on different datasets. This confirms the benefit of the iterative optimization algorithm to produce more accurate concept probabilities.
With the addition of Wikipedia knowledge, segmentation
performance is dramatically improved. Comparing LM+Wiki
with LM, segment F increases significantly from 14% to
30% on different datasets. Comparing EM+Wiki with
EM, there is also a segment F increase from 10% to 20%
on different datasets. The merit of Wikipedia being a
high-quality repository of concepts is also seen in the fact that
its weight ![]() is tuned to a large
number 100000 on the training + validation sets (which means that
any n-gram found as a concept in Wikipedia would receive 100000
``bonus'' frequency in corpus). The effect of Wikipedia even
overshadows that of the EM algorithm: the segment F improvement
from LM+Wiki to EM+Wiki is in the range of only
1.4% to 6%.
is tuned to a large
number 100000 on the training + validation sets (which means that
any n-gram found as a concept in Wikipedia would receive 100000
``bonus'' frequency in corpus). The effect of Wikipedia even
overshadows that of the EM algorithm: the segment F improvement
from LM+Wiki to EM+Wiki is in the range of only
1.4% to 6%.
The effectiveness of Wikipedia data makes us to wonder if such a good resource will render our language model unnecessary. We have tried a simple longest string match segmentation algorithm using Wikipedia as the dictionary. The result is summarized in Table 2 for the Intersection dataset, which turns out to be rather poor. Therefore, Wikipedia knowledge is not the only contributor to the good performance we have obtained; language modeling and the EM optimization algorithm are also very important.
The supervised method [4] reported 0.892 of classification accuracy and 0.717 of query accuracy on the Intersection dataset. Segment accuracy was not measured. In comparison, we obtain a 0.871 classification accuracy and a 0.671 query accuracy on this dataset using EM+Wiki. Since we do not have the segmentation output of the supervised method, we can not perform significance test on the performance difference. On the other hand, it is difficult to have a head to head comparison between the supervised and unsupervised methods because different resources and methods are used. Their method relies on a good POS tagger and the features are specifically designed for noun phrase queries (many of those features would be of little use to other types of queries). On the other hand, our method makes no such assumptions. Also, their classifier was specifically tuned to the peculiarities of annotator A; it was mentioned that ``results are lower'' for the other two annotators, while our unsupervised method produces similar performance with different annotators.
One of the major reasons why query segmentation is difficult is its inherent ambiguity. Among the 500 queries, there are only 219 queries for which the 3 annotators give identical segmentation. Table 3 reports the inter-agreement among the annotators, evaluating the segmentations by one annotator against those of another. A and C has the highest agreement, yet still it is poor: using A as the golden truth, C has only query accuracy of 0.606, classification accuracy of 0.847, and segment accuracy of 0.718. Considering this intrinsic difficulty, our segmentation accuracy is quite encouraging: our performance on Conjunction is as high as 0.801 for segment F, which means we can correctly identify more than 80% of the concepts from the queries. Comparing to the baseline MI with segment F of 0.616, our approach achieves 30% improvement.
| A | B | C | ||
| Annotator A | query accuracy | 0.580 | 0.606 | |
| classification accuracy | 0.842 | 0.847 | ||
| segment precision | 0.698 | 0.723 | ||
| segment recall | 0.676 | 0.713 | ||
| segment F | 0.687 | 0.718 | ||
| Annotator B | query accuracy | 0.580 | 0.604 | |
| classification accuracy | 0.842 | 0.842 | ||
| segment precision | 0.677 | 0.691 | ||
| segment recall | 0.699 | 0.701 | ||
| segment F | 0.688 | 0.696 | ||
| Annotator C | query accuracy | 0.610 | 0.604 | |
| classification accuracy | 0.849 | 0.842 | ||
| segment precision | 0.716 | 0.701 | ||
| segment recall | 0.725 | 0.691 | ||
| segment F | 0.720 | 0.696 |
The biggest limitation to the current dataset provided by [4] is that the queries only contain noun phrases. But general web search queries has many other types, and a method specifically tailored to noun phrase queries would not work for an arbitrary query. To test our unsupervised method, we internally sampled a small random set of 160 queries and manually segmented them. Experiments (details not reported) confirm the high performance of our approach compared to the mutual information based one.
We have performed an error analysis of the segmentations from the EM + Wiki method that do not agree with Intersection, and categorize them as follows:
There are many phrases composed of nouns, which can be either treated as composite concepts, or segmented into smaller ones. Examples include ``NCAA bracket'', ``salt deficiency'' and ``dirt bike parts''. Both ways of doing segmentation are reasonable when a phrase is the combination of its components without much altering in meaning. A composite concept may be more useful for query understanding (as component words are grouped together), while separate smaller concepts are more flexible in retrieval (as component words do not have to appear adjacent to each other in a matching document). These constitute the largest proportion of disagreements. A good solution to this problem, which we are considering as a future extension to this work, is to build a concept hierarchy or graph that models the dependency between concepts.
These are patterns that occur so frequently in the corpus that our method choose to keep them in segments, even if they are not good concepts. For example, for ``lighted outdoor palm tree'', our method puts the first two words in a segment, since they are highly correlated in the corpus. Some form of linguistic analysis is needed to identify and correct these cases.
When a part of the query happens to match in Wikipedia, the result can sometimes be undesirable. For example, for ``the bang bang gang'' (a movie title), we mistakenly make ``bang bang`` a segment, which is a title of a Wikipedia article. The mistake wouldn't have happened, however, if the correct segment were frequent enough in the corpus.
For the query ``hardy county virginia genealogy'', our incorrect segmentation is [hardy county][virginia genealogy]. [virginia genealogy] may be an acceptable segmentation for a query containing just these two words, but certainly not for the current query, where ``genealogy'' is about ``hardy county''. To solve this, we need a higher-order model which can capture the dependence between the non-adjacent [hardy county] and [genealogy].
We have proposed a novel unsupervised approach to query segmentation based on a generative language model. To estimate the parameters (concept probabilities) efficiently, we use a novel method to estimate frequencies of long n-grams, and an EM algorithm that does optimization on the fly. We also explore additional evidence from Wikipedia to augment unsupervised learning. Experiments demonstrate the effectiveness and efficiency of our approach, with segment accuracy increasing to 0.774 from 0.530 of the traditional mutual information based approach.
For the future work, the first thing to explore is higher order language models. Currently we only use the unigram language model, and we expect a higher order language model would capture dependencies in long queries better.
Second, since our minimum description length framework allows additional knowledge to be incorporated easily, we would like to use more resources, especially noun phrase and named entity models. We are not going to directly apply noun phrase chunking to queries, as this would not work well for general queries. Instead, we can run a noun phrase chunker on the Web documents, and collect all extracted noun phrases, which we can then use to estimate the probability of a segment being a noun phrase.
Finally, we want to evaluate our methods in the context of Web search, to see how well they can be used to improve proximity matching and query expansion. After all, improving Web search is our major motivation of developing better query segmentation techniques and thus the ultimate evaluation standard.
We would like to thank Nawaaz Ahmed for his insightful discussions during our study and his comments on the draft, Benoit Dumoulin, Yumao Lu and Chengxiang Zhai for their comments on the draft.
![\begin{algorithma} % latex2html id marker 174\par \framebox{ \parbox[b]{3.2 in... ...mming algorithm to compute top $k$\ segmentations} \par }} \par \end{algorithma}](fp592-tan-img29.gif)
![\begin{algorithma} % latex2html id marker 248\par \framebox{ \parbox[b]{3.2 in... ...gorithm to compute lower bounds for n-gram frequencies} \par }} \end{algorithma}](fp592-tan-img70.gif)
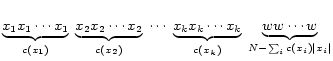
![\begin{algorithma} % latex2html id marker 318\par \framebox{ \parbox[b]{3.2 in... ...ption{Algorithm to compute n-gram longest match counts} \par }} \end{algorithma}](fp592-tan-img99.gif)
![\includegraphics[width=0.6\columnwidth]{arch.eps}](fp592-tan-img121.gif)
![\includegraphics[width=1\columnwidth]{bar.eps}](fp592-tan-img123.gif)