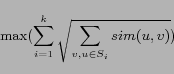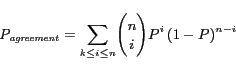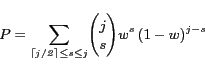Query-Sets: Using Implicit Feedback and Query
Patterns
to Organize Web Documents
Copyright is held by the World Wide Web
Conference Committee (IW3C2). Distribution of these papers is
limited to classroom use, and personal use by others.
WWW 2008, April 21-25, 2008, Beijing, China.
ACM ???.
ABSTRACT
In this paper we present a new document representation model based on implicit user feedback obtained from search engine queries. The main objective of this model is to achieve better results in non-supervised tasks, such as clustering and labeling, through the incorporation of usage data obtained from search engine queries. This type of model allows us to discover the motivations of users when visiting a certain document. The terms used in queries can provide a better choice of features, from the user's point of view, for summarizing the Web pages that were clicked from these queries. In this work we extend and formalize as query model an existing but not very well known idea of query view for document representation. Furthermore, we create a novel model based on frequent query patterns called the query-set model. Our evaluation shows that both query-based models outperform the vector-space model when used for clustering and labeling documents in a website. In our experiments, the query-set model reduces by more than 90% the number of features needed to represent a set of documents and improves by over 90% the quality of the results. We believe that this can be explained because our model chooses better features and provides more accurate labels according to the user's expectations.
Categories & Subject Descriptors
H.3.3 Information Search and Retrieval:
Clustering
H.2.8 Information Systems: Data Mining
H.4.m Information Systems Applications: Miscellaneous
General Terms
Algorithms, Experimentation, Human Factors
Keywords
Feature Selection, Labeling, Search Engine Queries, Usage Mining, Web Page Organization
1 Introduction
As the Web's contents grow, it becomes increasingly difficult to manage and classify its information. Optimal organization is especially important for websites, for example, where classification of documents into cohesive and relevant topics is essential to make a site easier to navigate and more intuitive to its visitors. The high level of competition in the Web makes it necessary for websites to improve their organization in a way that is both automatic and effective, so users can reach effortlessly what they are looking for. Web page organization has other important applications. Search engine results can be enhanced by grouping documents into significant topics. These topics can allow users to disambiguate or specify their searches quickly. Moreover, search engines can personalize their results for users by ranking higher the results that match the topics that are relevant to users' profiles. Other applications that can benefit from automatic topic discovery and classification are human edited directories, such as DMOZ1 or Yahoo!2. These directories are increasingly hard to maintain as the contents of the Web grow. Also, automatic organization of Web documents is very interesting from the point of view of discovering new interesting topics. This would allow to keep up with user's trends and changing interests.
The task of automatically clustering, labeling and classifying documents in a website is not an easy one. Usually these problems are approached in a similar way for Web documents and for plain text documents, even if it is known that Web documents contain richer and, sometimes, implicit information associated to them. Traditionally, documents are represented based on their text, or in some cases, also using some kind of structural information of Web documents.
There are two main types of structural information that can be found in Web documents: HTML formatting, which sometimes allows to identify important parts of a document, such as title and headings, and link information between pages [15]. The formatting information provided by HTML is not always reliable, because tags are more often used for styling purposes than for content structuring. Information given by links, although useful for general Web documents, is not of much value when working with documents from a particular website, because in this case, we cannot assume that this data has any objectiveness, i.e.: any information extracted from the site's structure about that same site, is a reflection of the webmaster's criteria, which provides no warranty of being thorough or accurate, and might be completely arbitrary. A clear example of this, is that many websites that have large amounts of contents, use some kind of content management system and/or templates, that give practically the same structure to all pages and links within the site. Also, structural information does not reflect what users find more interesting in a Web page. It only reflects what webmasters find interesting.
Since neither content or structural data seem to be complete information sources for the task of clustering, labeling and classification of Web documents, we propose the incorporation of usage data, obtained from the usage logs of the site. In particular, we suggest to use the information provided by user queries in search engines. This information is very easy to retrieve, from the referer3 field of the usage log, and provides a very precise insight into what user's motivations are for visiting certain documents. Terms in queries can be used to describe the topic that users were trying to find when they clicked on a document. These queries provide implicit user feedback that is very valuable. For example, we can learn that if many users reach a document using certain keywords, then it is very likely that the important information in this document can be summarized by those keywords.
Following this motivation, we propose a different document representation model, mainly for clustering and labeling, but that can also be used for classification. Traditional models for document representation use the notion of a bag of words, the vector space model being the most well known example of this. Our approach is based on these models but selects features using what seems more appropriate to refer to as a bag of query-sets idea. The representation is very simple, yet intuitive, and it reduces considerably the number of features for representing the document set. This allows to use all of the document features for clustering, and in our experiments this shows to be very effective for grouping and labeling documents in a website.
The main contributions of this paper are,
- to present two document models which use implicit user
feedback from search queries:
- a model that formalizes and extends the previously existing concept of query view [9] into a more general query document model,
- a new document representation based only on frequent sets of clicked queries, the query-set model, that improves the previous model,
- propose a new methodology based in known algorithms for clustering and labeling Web documents, using the query-set model. This model can be applied to organize documents within a website, general Web documents and search engine results.
- We also present an initial experimental evaluation to corroborate our models.
This paper is organized as follows: Section 2 presents related work. Section 3 describes the query-based document models. Section 4 discusses the evaluation and results, and finally in Section 5 we present conclusions and future work.
2 Related Work
Web mining [31] is the process of discovering knowledge, such as patterns and relations, from Web data. Web mining generally has been divided into three main areas: content mining, structure mining and usage mining. Each one of these areas are associated mostly, but not exclusively, to these three predominant types of data found in the Web:
- Content:
- The real data that the document was designed to give to its users. In general this data consists mainly of text and multimedia.
- Structure:
- This data describes the organization of the content within the Web. This includes the organization inside a Web page, internal and external links and the website hierarchy.
- Usage:
- This data describes the use of a website or search engine, reflected in the Web server's access logs, as well as in logs for specific applications.
Web usage mining has generated a great amount of commercial interest [12]. There is an extensive list of previous work using Web mining for improving websites, most of which focuses on supporting adaptive websites [21] and automatic personalization based on Web Mining [20]. Amongst other things, using analysis of frequent navigational patterns, document clustering, and association rules, based on the pages visited by users, to find interesting rules and patterns in a website [8,30,11,19].
Web usage mining is a valuable way of discovering data about Web documents, based on the information provided implicitly by users. For instance, [36] combines many information sources to solve navigation problems in websites. The main idea is to cluster pages based on their link similarities using visitor's navigation paths as weights to measure semantic relationships between Web pages. In [28] they create implicit links for Web pages by observing different documents clicked by users from the same query. They use this information to enhance Web page classification based on link structure.
Document clustering, labeling, automatic topic discovery and classification, have been studied in previous work with the purpose of organizing Web content. Organizing Web pages is very useful withing two areas, search engine enhancement, and improving hierarchical organization of documents. Search engines can benefit greatly from effective organization of their search results into clusters. This allows users to navigate into relevant documents quickly [33]. In a similar way, automatic organization of Web content can improve human edited directories.
In general, all existing clustering techniques must rely on four important components [16]: a data representation model, a similarity measure, a cluster model, and a clustering algorithm that uses the data model and this similarity measure. In particular, Web documents pose three main challenges for clustering [7]:
- very high dimensionality of data,
- very large size of collections, and
- the creation of understandable cluster labels.
Many document clustering and classification methods are based on the vector space document model. The vector space model [26] represents documents as vectors of terms, in an Euclidean space. Each dimension in the vector represents a term from the document collection, and the value of each coordinate is weighted by the frequency in which that term appears in the document. The vector representations are usually normalized according to tf-idf weighting scheme used in Information Retrieval [2]. The similarity between documents is calculated using some measure, such as the cosine similarity. The vector space model does not analyze the co-occurrence of terms inside a document or any type of relationship amongst words.
There are several approaches that try to improve the vector space model with the purpose of improving Web document clustering. In general, they are based in discovering interesting associations between words in the text of the document. In [16] they propose a system for Web clustering based on two key concepts: the use of weighted phrases as features for documents, and an incremental clustering of documents that watches the similarity distribution inside each cluster. A similar notion is developed in [7] where they define a document model based on frequent terms obtained from all the words in a document, aiming at reducing the dimensionality of the document vector space. In [23] they also use term sets in what they call a set-based model, which is a technique for computing term weights for index terms in Information Retrieval that uses sets of terms mined by using association rules on the full text of documents in a collection. Another type of feature selection from document contents is done by using compound words [34] provided by WordNet4. In [32] they use a document model for clustering based on the extraction of relevant keywords for a collection of documents. The keyword with the highest score within each cluster is used as the label. The application described in [14] also uses extraction of keywords based on frequency and techniques such as using a inlinks and outlinks. All of these methods use the information provided by the contents of Web pages, or their structure, but they do not incorporate actual usage information (i.e., implicit user feedback) into their models.
Implicit user feedback, such as clicked answers for queries submitted to search engines are a valuable tool for improving websites and search results. Most of the work using queries has been focused on enhancing website search [35] and to make more effective global Web search engines [3,17,29,25]. Also, queries have been studied to improve clustering of Web documents. This idea, to the best of our knowledge, has only been considered previously in [6], [9] and [24]. In [6] they represent a query log as a bipartite graph, in which queries are on one side of the graph and URLs clicked from queries are on the other. They use an agglomerative clustering technique to group similar queries and also similar documents. This algorithm is content-ignorant as it makes no use of the actual content of the queries or documents, but only how they co-occur within the click through data. In [9] they present the idea of using a query view for document representation, which mines queries from a site's internal search engine as features to model documents in a website. The goal of this research was to improve an on-line customer support system. The third work, described in [24] introduces a document representation called query vector model. In this approach they use query logs to model documents in a search engine collection to improve document selection algorithms for parallel information retrieval systems. The model represents each document as a vector of queries (extracted from the search engine query log) weighted by the search engine rank of the document for each particular query in the feature space. Although this work is similar to [9] and [6], due to the fact that both base their clustering models on queries, they differ in the fact that in [24] the query log is only used to extract queries but does not use the click through information of the documents clicked for each query. Whether or not users clicked on a particular document from the result set of a query, is not taken into account for the document model and by doing so [24] only considers the search engine rank algorithm output, even if no users considered the results as appropriate for their query.
User feedback to search engine queries has also been considered in other document representation models. In [25] they rank search results using feature vectors for documents, which are learned from query chains or queries with similar information needs. Using a learning algorithm they incorporate different types of preference judgments that were mined from query chains into their document model. This model takes advantage of user query refinement. Another approach that considers user feedback to search queries is [33]. In [33] they classify search results into categories discovered using a pseudo document representation of previous related queries to the input query. The pseudo representation of related queries incorporates user feedback by including the text from snippets of previously clicked documents for the related queries. In [33] the terms of queries are considered as a brief summary of its pseudo document. The idea that queries can be good descriptors for their clicked documents is also discussed in detail in the query mining model described in [5].
Our work is based on idea that search queries and their clicked results provide valuable user feedback about the relevance of documents to queries. In this way, our work is similar to [6], [25] and [33]. Nevertheless, our approach differs because we consider that the queries from which documents are clicked are good summaries of user's intent when viewing a document. Hence, in our model we use global search engine queries (and not only internal searches as in [9]) as surrogate text for documents and choose the document's features from the terms of the queries from which it was clicked from. Our model extends this notion by mining frequent sets from queries in a similar way to [7] and [23], with the difference that they mine patterns from the original full text of the document (and not considering user feedback from queries).
3
Document Clustering and
Labeling
Search engines play a key role in finding information on the Web. They are responsible directly, or indirectly, for a large part of the traffic in websites, and documents visited as a result of queries compose the actual visible pages of the site. Furthermore, we can say that for many websites the only important documents are the ones that are reachable from search engines. Due to the significance of queries for aiding users to find content on the Web, in this section we discuss the issue of using queries to understand and model documents.
The traditional vector model representation for documents, although it can be used to model Web documents, lacks a proper understanding on what are the most relevant topics of each document from the user's point of view and which are the best words (or features) for summarizing these topics. It is important to note that a visitor's perception of what is relevant in a document is not necessarily the same as the site author's perception of relevance. Thus, a webmaster's organization of documents of a website can be completely different of what user's would expect. This would make navigation difficult and documents hard to find for visitors, see [22]. Also, what users find interesting in a Web page does not always agree with the most descriptive features of a document according to a tf-idf type of analysis. This is, the most distinctive words of a document are not always the most descriptive features of its vector space representation.
For modeling Web documents, we believe that it is better to represent documents using queries instead of their actual text contents, i.e.; using queries as surrogate text. We extend and modify previous work based on the intuition that queries from which visitors clicked on Web documents, will make better features for the purposes of automatically grouping, labeling, and classifying documents. By associating only queries to the documents that were clicked from them, we bring implicit user feedback into the document representation model. By using clicked pages we are trusting the relevance judgements of the real users and not the search engines judgements (which may be different for different engines), and hence we are filtering non relevant pages, in particular spam pages that may bring noise to our technique.
There are two main data sources for obtaining clicked queries for documents, and depending on the source we might have partial queries or complete queries:
- partial queries: This is the case when the usage data is obtained from a search engine's query log. This situation is most likely to occur when organizing general Web documents or search results. Query clicks to documents discovered from this log are only the ones that were submitted to the particular search engine that generated the log. Therefore, the more widely used the search engine is, the better it will represent the real usage of documents.
- complete queries: This is the case when the usage data is obtained from a website's access logs. This situation is most likely when organizing documents belonging to a particular website. Standard combined access logs allow (very easily) to discover all of the queries from Web search engines that directed traffic to the site (i.e., queries from which documents in the site were clicked). This log may also contain information about queries to the internal search engine of the website (if one is available).
We present two document models based on queries and their clicked URLs, the query document model, which uses query terms as features, and an enhanced query-set document model, which uses query-sets as features.
1 Query Document Model
As a first approach to using queries to represent documents, we present the query document model. This model is a formalization and extension of the query view idea [9]. We extend [9] by not limiting queries only to those from internal searches, but including all possible queries available (complete or partial queries). The query document model consists of representing documents using as features only query terms. The queries used to model a document are only those for which users clicked on that document.
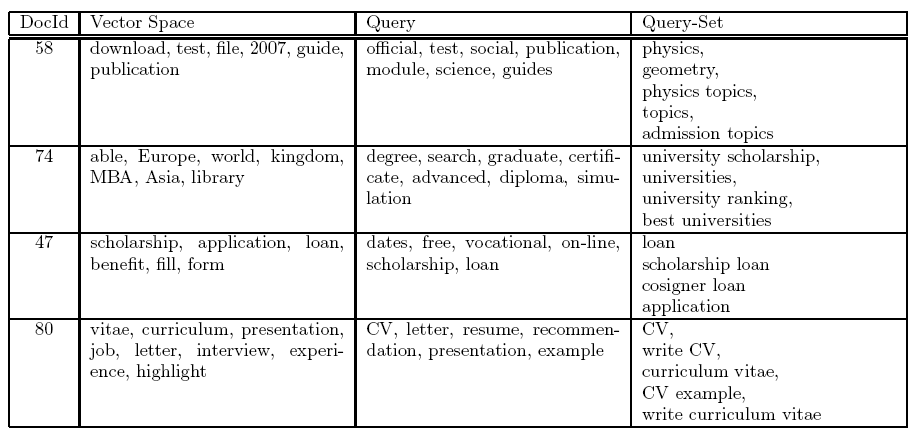
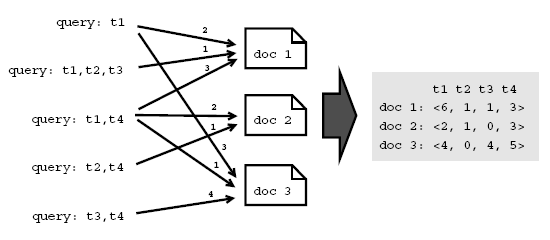
The query document model reduces the feature space dimensions considerably, because the number of terms in the query vocabulary is smaller than that of the entire website collection. This model is very similar to the vector model, with the only difference that instead of using a weighted set of keywords as vector features, we will use a weighted set of query terms. The weight of each term corresponds to the frequency with which each query that contains the term appears in the usage log as a referrer for the document. In other words: how many times users reach a document by submitting a query that contains a particular term. These query representations of Web documents are then normalized according to the well-known tf-idf scaling scheme. Figure 1 shows a simple example (without normalization) of a query document representation. This example shows a set of queries, the terms included in each query, the documents that were reached by users from the queries, and the number of times that this happened. This information is processed to create the query document representations.
More formally we define the query document model as:
Let
![]() be a collection of
documents, and let
be a collection of
documents, and let ![]() represent the vocabulary of all queries
found in the access log
represent the vocabulary of all queries
found in the access log ![]() . Moreover, let
. Moreover, let
![]() be the list of terms in
vocabulary
be the list of terms in
vocabulary ![]() . Let
. Let ![]() be the set of all the queries found
in
be the set of all the queries found
in ![]() from which users clicked at least one time on a document
from which users clicked at least one time on a document ![]() , and let
the frequency of
, and let
the frequency of ![]() in
in
![]() be the total number of times that
queries that contained
be the total number of times that
queries that contained ![]() were used to
visit
were used to
visit ![]() . The query representation of
. The query representation of ![]() is defined
as:
is defined
as:
where
and
![]() is the
is the ![]() weight
assigned to
weight
assigned to ![]() for
for ![]() .
.
Besides reducing the feature space, another result of this
representation is that documents are now described using terms
that summarize their relevant contents according to the users
point of view. In subsection 3.3 we discuss the case when
![]() .
.
Although we use queries for modeling documents, this approach differs from [24] in the following way: the queries considered for document features are only those from which users clicked on the document as a result of the query in the search engine. This way, implicit user feedback is used to relate queries to documents, and the frequency of clicks is considered for feature weight, and not the rank.
It is important to note that not all visits to a Web page in response to a query are relevant, i.e., some users could click on a result to find out that the page that they are visiting is not what they thought it would be. The only guide that users have to click on a Web page are the snippets displayed on the search engine results. To counteract this effect, the frequencies of clicks from a query to a document are considered in the vectors as a heuristic to attempt to give more importance to highly used queries and reduce noise due to errors.
2 Query-Set Document Model
The main drawback for the query model, is that it considers terms independent from each other even if they occur many times together in a same query. This can cause the loss of important information since many times more than one term is needed to express a concept. Also a term occurring inside a set can have different meanings if we change other elements in that set. For example, the two term queries class schedule and class diagram have different meanings for the word class. The first refers academic classes, and the second more likely to UML classes. To address this problem, which happens frequently in Web queries, we have created an enhanced version of the query model, called query-set document model.
The query-set model uses frequent query-sets as features, and aims at preserving the information provided by the co-occurrence of terms inside queries. This is achieved by mining frequent itemsets or frequent query patterns. Every keyword in a query is considered as an item. Patterns are discovered through analyzing all of the queries from which a document was clicked, to discover recurring terms that are used together. The difference with this model and the previous is that instead of using queries directly as features in a vector, we use all the frequent itemsets that have a certain support. The novelty of this approach relies on the combination of user feedback for each document, and mining frequent query sets to produce an appropriate document model. Previous work such as [7,23] use itemsets for feature selection over the full text of documents, our model on the other hand, applies this only to queries. We believe that frequent sets mined from queries are more powerful and expressive than the sets extracted from the full text of the documents. Frequent sets mined from the full text of documents have a similar problem to that of the vector space model, i.e.: not selecting sets from the terms that user's consider relevant. Queries on the other hand, already have the selected keywords that summarize the document from the user's perspective.
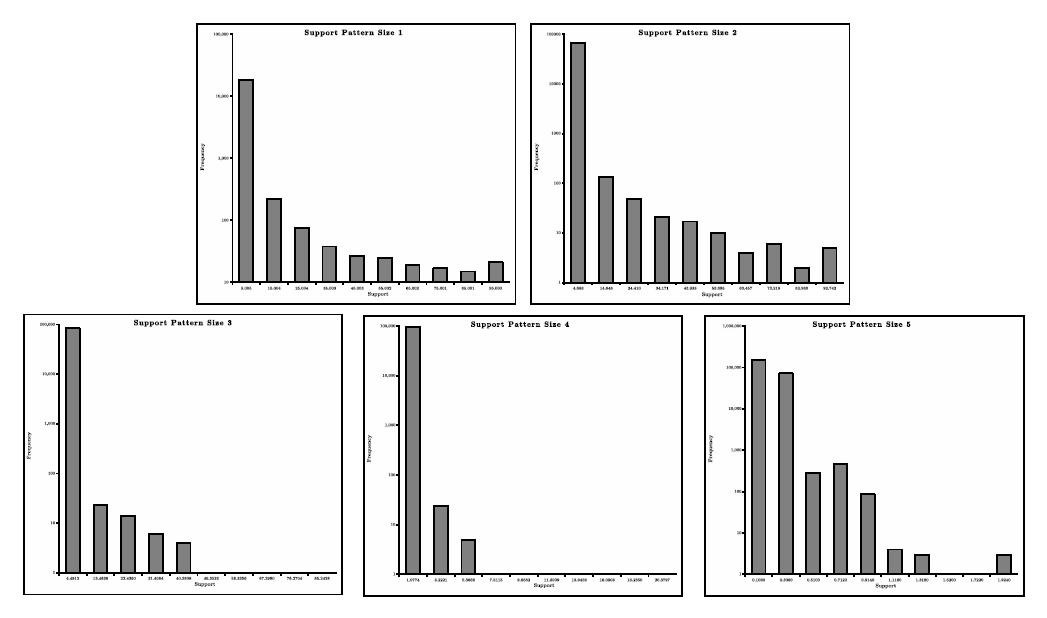
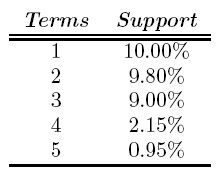
The support for frequent itemsets is decided for each collection experimentally, based on the frequency distribution of queries in a usage log. In general, the support decreases as the number of terms in a set increase. Figure 2 shows an example of all term sets found for a sample of queries. From this it is possible to determine the minimal support allowed for queries with 1, 2 and 3 terms, to obtain only the most relevant sets.

After the relevant sets of terms for each document are extracted, a weighed vector is created for the query-set document representation. Each dimension of the feature space is given by all the unique relevant term sets found in the usage logs. Each term set is a unit, and it cannot be split. The weight of each feature in the vector is the number of times that the pattern appears in a query that clicked on the document.
More formally we define the query-set document model as follows:
Let
![]() be a collection of
documents, and let
be a collection of
documents, and let ![]() represent the vocabulary of all relevant
terms sets found in the access log
represent the vocabulary of all relevant
terms sets found in the access log ![]() . Moreover, let
. Moreover, let
![]() be the list of term
sets in vocabulary
be the list of term
sets in vocabulary ![]() . Let
. Let ![]() be set of
queries found in
be set of
queries found in ![]() from which users clicked at least one time on a
document
from which users clicked at least one time on a
document ![]() , and let the frequency of
, and let the frequency of ![]() in
in
![]() be the total number of times that
queries that contained
be the total number of times that
queries that contained ![]() reached
reached
![]() . The query-set
representation of
. The query-set
representation of ![]() is defined as:
is defined as:
where
and
![]() is the
is the ![]() weight
assigned to
weight
assigned to ![]() for
for ![]() .
.
3
Modeling Documents that
do not have Queries
Since all the query-based approaches represent documents
only by using queries it is necessary to consider documents
that do not register visits from queries. This is needed if we
want to model a complete collection of documents. There are
several alternatives for modeling and clustering these
remaining documents. A straightforward approach is to model all
documents with queries using the query-set model and for the
remaining documents use a partial set-based model (see
[23]), but only using
the feature space of the query-sets (![]() ). If the
query model was being used (instead of the query-set model)
then the remaining documents would have to be modeled using the
traditional vector space approach, but using only the query
vocabulary (
). If the
query model was being used (instead of the query-set model)
then the remaining documents would have to be modeled using the
traditional vector space approach, but using only the query
vocabulary (![]() ).
).
The main focus of our work, is on documents that were reached by queries. Evaluation and further discussion of the best approach for documents that do not have queries will be pursued in the future, but as we show in the next section, our approach covers most of the relevant pages in a website. In addition, there are many techniques available to cluster and label text documents.
4 Evaluation and Discussion
As a first evaluation for our query-based models we chose to use a website with its access logs. This decision was based on the fact that by using a website's logs we can have access to complete queries and this gives us a full view of the query range from which users visited the site. The second motivation for evaluating using a website is that the collection of documents already have a strong similarity, so the clusters will be specialized and not trivial.
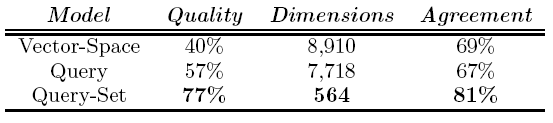
For the evaluation we used as a case study a large portal directed to university students and future applicants. This website gathers a great amount of visits and contents from a broad spectrum of educational institutions. Table 1 shows some general statistics of the one month log used for this evaluation. Table 2 describes how the different documents in the website were found by users (i.e., clicked on for the first time in a session). Documents in Table 2 are divided into: URLs that were not visited by users, URLs that only had visits as a result of a query click, visits from users who browsed to the URL (navigation), and visits from both (this implies that some users visited a page by browsing while others visited the same page by clicking on a query result). We can observe that the documents clicked at some point from queries represent more than 81% of the documents and more than 87% of the traffic to the Web site. Therefore, our technique applies to a large fraction of the pages and the most important ones in the site.


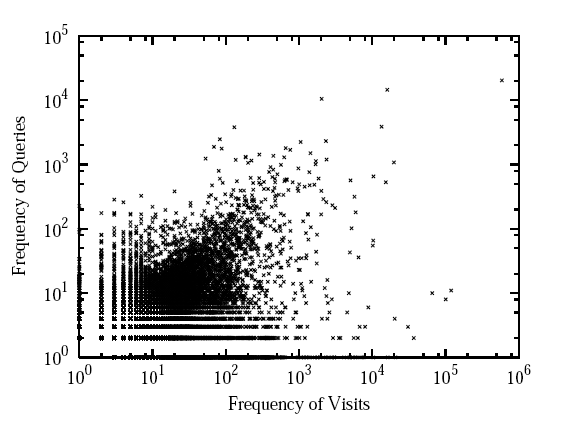
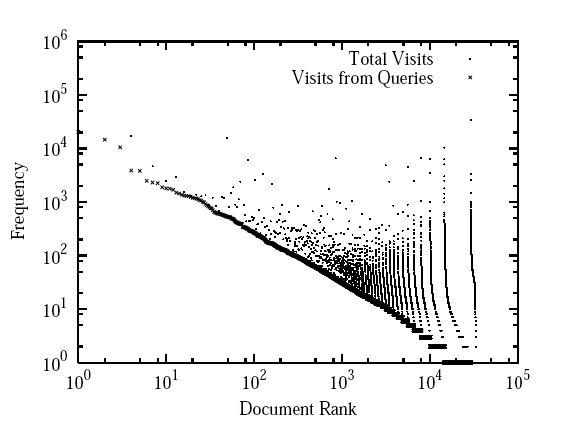
In Figure 3 we show the documents in the site sorted by query click frequency and by visit frequency. We can observe that the query click frequency distribution over documents is a power law with exponent -0.94. This is a very low absolute value, in comparison the usual power law found in Web search engine data. We believe this can be explained by the fact that the power law distribution of words in queries is correlated with the power law distribution of words in documents [1]. Therefore, since the query-based models only study queries with clicked results, the query-document distribution decays at a slower pace than the usual word-document distribution. On the other hand, in Figure 4 we can see the correlation between the frequency of queries and the frequency of navigational visits (without considering clicks from queries) for the URLs is low, as shown in Figure 4. This implies something that we expected: queries are being used to find documents that are not found usually by navigation. Consequently, the organization of documents into topics using queries can provide additional information to the current structure of the site.
 |