1
I.2.6Artificial IntelligenceLearning[Knowledge acquisition]
Algorithms, Experimentation
Web Entities, Attribute Labels, Entity Instances, Global Attribute Schema
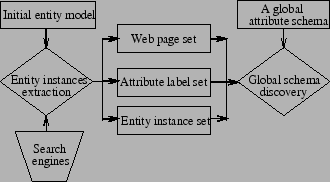
For example, both instances in Figure 1 contain several attributes regarding the same person. For the attribute type ``Birthday'', the first instance uses Born as its label, which is different from Birthday as used in the second. Therefore, we should make sure they are of the same attribute type if we want to integrate these two instances. In fact, it's common for entities of one entity type to have many types of attributes with each of them described by different labels. Consequently, to integrate the web entity instances of the same entity type, we have to establish a map between labels and their types. To establish this map, a global attribute schema, which reflects the main attribute types and their descriptive labels, must be constructed in advance.
We focus on automatically learning a global entity attribute schema for all the web entities of a specific entity type. For example, for person-type entities, a basic description that a person entity should contain attributes of name, gender, birthday, birthplace and weight is provided by the users. Then, based on this description, we can locate related web pages to extract person entity instances, mine other latent attributes, and then use the new attributes to locate more pages for more instances. This process runs iteratively until necessary attribute labels for the main attribute types have been discovered. Based on these attribute labels, entity instances and related pages, we discover the relations between different attribute labels, and, finally, construct the global entity attribute schema for person-type web entities.
The global attribute schema for web entities of a specific entity type is essential to integrate web entity instances. Moreover, from the global schema, the types of the important attributes owned by the web entities of the target entity type can be automatically identified, and then used as the input to web object extraction systems to extract web objects with these important attributes. And this makes the results of these systems more valuable and reasonable.
However, for this aim, there are obvious difficulties. On the one hand, enough frequent attribute labels must be extracted from the Web, and they should also be able to represent the main attribute types which constitute the global schema. On the other hand, the number of frequent labels in learning a global attribute schema is usually large and their qualities are not uniformly high, due to the variety and complexity of web entity instances.
In this paper, we propose the problem of learning a global attribute schema for all the web entities of a specific entity type for the first time, and present a novel framework to address this problem. Under this framework, first, we propose an iterative web entity instances extraction approach to extract enough web entity instances as well as frequent attribute labels to learn a global attribute schema. Next, we present a maximum entropy-based method to automatically learn a global attribute schema based on the frequent labels, entity instances and related pages. Finally, we demonstrate our technique on person-type and movie-type entities on the Chinese Web, and experimental results show that our technique is general, efficient and effective.
This article is further structured as follows. Section 2 discusses related works. Section 3 formulates the problem of learning a global attribute schema. Section 4 presents the iterative method of entity instances extraction. Section 5 proposes the maximum entropy-based approach of schema discovery. Section 6 illustrates the experiments and analyzes the experimental results. Section 7 summarizes this paper.
The previous study in [8] seeks to discover hidden schema model for query interfaces on deep Web. This study focuses on finding a hidden schema model to match schemas of query interfaces in the same domain. Its goal is the same as ours in finding a global schema. However, its method is effective and efficient only when the number of attribute labels in query interfaces is relatively small, because it creates the global schema based on all possible label partitions, and its time complexity is exponential to the number of labels. Moreover, it assumes that attribute labels in each query interface's schema are of different types, which is natural in deep Web. However, in our research, the attribute labels and the possible label partitions are both far more numerous than the aforementioned study. Further, the attribute labels in one entity instance are not always different types.
Besides, the other related researches can be summarized in the following aspects:
Similar to these studies, our research aims at learning a schema for web entities. However, our study is different from them in three aspects. First, we target learning a schema from large numbers of entity instances and related web pages, instead of from a single page, a single site or a set of logically related sites. Second, our study mines the attribute labels, entity instances and related pages, instead of analyzing the structure of HTML documents. And lastly, our study seeks to learn a global schema for all the web entities of a specific entity type, while previous related studies aimed to extract the schema of web data appearing in some sites or pages.
In our research, we first look for frequent attribute labels in entity instances from different pages, and then combine labels which belong to the same attribute type. Naturally, the attribute labels correspond to elements in schemas. However, our research is unlike schema matching. First, schema matching integrates different but related schemas, which are derived from different data resources. Meanwhile, our research combines attribute labels extracted from web entity instances to learn a global attribute schema. Second, the schemas used in schema matching are extracted from regular data sources, such as deep web databases, whose quality is high and their vocabularies are relatively small, while our attribute labels are collected from surface web pages, whose quality is not uniformly high and their quantity is relatively large.
Formally, assume we are given a basic description for entities of a specific entity type in ![]() , which is provided by users under the framework of a predefined entity model
, which is provided by users under the framework of a predefined entity model ![]() .
. ![]() presents users' knowledge about the entities of the target entity type. Then, our goal is to get a global attribute schema for all the web entities of the target entity type, which is denoted as
presents users' knowledge about the entities of the target entity type. Then, our goal is to get a global attribute schema for all the web entities of the target entity type, which is denoted as ![]() and is learned based on
and is learned based on ![]() and related web pages.
and related web pages.
To describe the problem clearly, we first define a concept ``entity'' as follows:
Definition 1 An entity is something that has a distinct, separate existence, and owns an entity type and all the attributes which are owned by all the entites with the same entity type. A web entity is an entity whose instances are presented in web pages. Formally, an entity can be represented as
![]() ,
, ![]() , where
, where ![]() is the entity type,
is the entity type, ![]() and
and ![]() is the type and value of
is the type and value of ![]() th attribute of
th attribute of ![]() , respectively.
, respectively.
Definition 2 An entity instance is a partial container of a specific entity. An entity instance contains some attribute labels and their values of the entity. Formally, an entity instance can be represented as
![]() ,
, ![]() , where
, where ![]() and
and ![]() is the label and value of
is the label and value of ![]() th attribute of
th attribute of ![]() . For example, the two person instances in Figure 1 are both entity instances of the same entity.
. For example, the two person instances in Figure 1 are both entity instances of the same entity.
Definition 3 An entity model is a model which characterizes the features of all the entities of a specific entity type, which include their entity type, the types of their attributes, and the labels describing their attributes.
As a result, an initial entity model must contain the entity type and some sets of attribute labels. An initial entity model can be formally represented as
![]()
![]() , where for
, where for
![]() ,
, ![]() ,
,
![]() , and for
, and for
![]() ,
,
![]() ,
,
![]() .
.
To learn a global attribute schema, an attribute schema for all the entities of a target entity type is defined as follows:
Definition 5 An attribute schema for all the entities of a target entity type is a schema about attribute types owned by these entities. It reflects the types of attributes owned by these entities and the labels describing each attribute type. Similarly, a global attribute schema for all the entities of a specific entity type is the schema which defines all the main attribute types and labels describing each attribute type. An attribute schema can be represented as
![]() ,
,
![]() , where
, where ![]() is the
is the ![]() th attribute type and can be initialized by one attribute label in
th attribute type and can be initialized by one attribute label in ![]() , and
, and ![]() is the label set of the
is the label set of the ![]() th attribute.
th attribute.
![\begin{algorithm}
% latex2html id marker 85
[h]
\renewedcommand{algorithmicrequi...
...nto $M_{init}$, and go to 2 to continue;
\ENDIF
\end{algorithmic}\end{algorithm}](at333w-yao-img37.png)
Based on the above definitions, our problem can be formulated as follows:
Given an initial entity model ![]() provided by users under an entity model framework
provided by users under an entity model framework ![]() , automatically extract enough entity instances
, automatically extract enough entity instances
![]() from the Web, mine attributes labels from
from the Web, mine attributes labels from
![]() and learn an global attribute schema
and learn an global attribute schema ![]() using attributes labels through the mining of
using attributes labels through the mining of
![]() and related web pages.
and related web pages.
We propose an iterative algorithm as in Algorithm 1 to automatically locate related structured pages and extract enough entity instances inside. There are three important issues in this algorithm as follows:
1. Query construction
Each query consists of several attribute labels in ![]() , and the query set created in each iteration does not include the queries created in previous iterations. Moreover, in order to locate structured pages containing entity instances of the target entity type, each query should contain enough labels in
, and the query set created in each iteration does not include the queries created in previous iterations. Moreover, in order to locate structured pages containing entity instances of the target entity type, each query should contain enough labels in ![]() . If the labels in a query is not enough, unrelated pages will be retrieved. For example, the query {`Name' AND `Age' AND `Weight'} will locate many target structured pages which contain person instances, while the query {`Name' AND `Weight'} will locate many other unrelated pages. Furthermore, to retrieve enough pages to extract enough instances, the labels in one query should not be excessive because the query with excessive labels will match only a few related pages. For instance, the query {`Name' AND `Gender' AND `Age' AND `Birthday' AND `Birthplace' AND `Height' AND `Weight' AND `Race'} will match fewer pages than the query {`Name' AND `Gender' AND `Age' AND `Birthday'}. Our experimental result indicates that the proper number of labels in one query is
. If the labels in a query is not enough, unrelated pages will be retrieved. For example, the query {`Name' AND `Age' AND `Weight'} will locate many target structured pages which contain person instances, while the query {`Name' AND `Weight'} will locate many other unrelated pages. Furthermore, to retrieve enough pages to extract enough instances, the labels in one query should not be excessive because the query with excessive labels will match only a few related pages. For instance, the query {`Name' AND `Gender' AND `Age' AND `Birthday' AND `Birthplace' AND `Height' AND `Weight' AND `Race'} will match fewer pages than the query {`Name' AND `Gender' AND `Age' AND `Birthday'}. Our experimental result indicates that the proper number of labels in one query is ![]() .
.
2. Entity instances extraction
After retrieving related pages, we attempt to extract their containing entity instances. For each page, we first identify its data regions with the help of related mining techniques such as [15]. If one or more regions are discovered, which implies that this page might be a structured page with entity instances-then we scan each region to count the label number corresponding to the query in that region. If the ratio between this number and the number of labels in the query reaches a certain threshold (![]() in our experiments), this region is regarded as a candidate data region containing one entity instance. We then extract this region, mine the pattern of the labels in the query appearing in this region, and utilize the pattern to locate each label with its value.
in our experiments), this region is regarded as a candidate data region containing one entity instance. We then extract this region, mine the pattern of the labels in the query appearing in this region, and utilize the pattern to locate each label with its value.
3. Iteration termination criteria
To get enough frequent labels, the termination criteria of the iterative extraction process is a key point. We assume that the frequency of a frequent label is above a certain threshold, and such labels are sufficient if no new frequent label is discovered after a predefined number (![]() ) of new instances have been extracted, or a predefined number (
) of new instances have been extracted, or a predefined number (![]() ) of continuous iterations have been performed.
) of continuous iterations have been performed.
Then, after each iteration, if at least ![]() (
(![]() in our experiments) new instances are extracted without new labels, we can conclude that the labels are sufficient and iterations can be terminated. And if
in our experiments) new instances are extracted without new labels, we can conclude that the labels are sufficient and iterations can be terminated. And if ![]() (
(![]() in our experiments) continuous iterations have been performed while the number of new instances are below
in our experiments) continuous iterations have been performed while the number of new instances are below ![]() , we consider that the labels are sufficient and iterations should also be terminated. Experimental results in section 6 affirm the effectiveness of our iteration termination criteria.
, we consider that the labels are sufficient and iterations should also be terminated. Experimental results in section 6 affirm the effectiveness of our iteration termination criteria.
Assume the set of frequent labels is
![]() , the set of web entity instances is
, the set of web entity instances is
![]() , and the set of related pages is
, and the set of related pages is
![]() , our goal is to mine the content of
, our goal is to mine the content of ![]() ,
, ![]() and
and ![]() to combine labels of the same attribute type together, and, finally, to create the attribute schema
to combine labels of the same attribute type together, and, finally, to create the attribute schema ![]() .
.
To achieve this goal, we first preprocess ![]() using the constraints embedded in
using the constraints embedded in ![]() to generate candidate attribute types, and get two sets of label sets
to generate candidate attribute types, and get two sets of label sets ![]() and
and ![]() . Each element of
. Each element of ![]() represents a unique candidate attribute type and consists of attribute labels belonging to this attribute type. Each element of
represents a unique candidate attribute type and consists of attribute labels belonging to this attribute type. Each element of ![]() also consists of attribute labels belonging to the same attribute type, but it does not represent a unique attribute type. In other words, the attribute type represented by each
also consists of attribute labels belonging to the same attribute type, but it does not represent a unique attribute type. In other words, the attribute type represented by each ![]() 's element is independent of the attribute types represented by another elements. Then, based on
's element is independent of the attribute types represented by another elements. Then, based on ![]() and
and ![]() , we propose a maximum entropy-based method to discover the attribute types hidden in
, we propose a maximum entropy-based method to discover the attribute types hidden in ![]() , and learn the global attribute schema.
, and learn the global attribute schema.
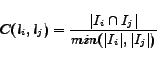 |
(1) |
Same entity-value factor: This factor measures the probability of two labels being of the same attribute type. The rationale behind this factor is that, when two labels often appear with the same value in different instances of the same entity, it is possible for them to be of the same attribute type. This inference is derived from the observation that different web pages often describe the same attribute type in the same entity's instances by using different labels. Then, if two instances are found to belong to the same entity (which will be discussed later), each pair of their labels appearing in them with the same value could be considered to be of the same attribute type. However, this inference may not stand for all situations, because some labels from different instances of the same entity may often contain some meaningless values such as ``unknown'', ``none'', and ``secret'', when these labels are actually not of the same attribute type. Consequently, we define the same entity-value factor as follows to measure the probability of two labels ![]() and
and ![]() being of the same attribute type:
being of the same attribute type:
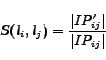 |
(2) |
![]() means
means ![]() and
and ![]() are actually of the same entity, which is determined by the names and the overlap of attribute values of two instances. The overlap of attribute values can be calculated as
are actually of the same entity, which is determined by the names and the overlap of attribute values of two instances. The overlap of attribute values can be calculated as
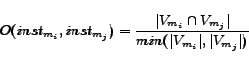

Based on the two factors defined above, we can generate candidate attribute types from the label set ![]() using Algorithm 2. In this algorithm, two issues need to be explained:
using Algorithm 2. In this algorithm, two issues need to be explained:

The frequency of a label in the above algorithm is the percentage of the extracted entity instances owning the label in instance set ![]() in all the extracted instances. Moreover, the key point of this algorithm is to use the maximum entropy-based method to determine whether a set of labels represents a new attribute type, which will be explained in detail.
in all the extracted instances. Moreover, the key point of this algorithm is to use the maximum entropy-based method to determine whether a set of labels represents a new attribute type, which will be explained in detail.
As in our problem, given an attribute schema ![]() , and a label set
, and a label set ![]() whose elements are of the same attribute type, our goal is to determine whether labels in
whose elements are of the same attribute type, our goal is to determine whether labels in ![]() are of a new attribute type, or of an existing attribute type in
are of a new attribute type, or of an existing attribute type in ![]() . And this determination is related to various dependent features, and is proper to be solved using maximum entropy model.
. And this determination is related to various dependent features, and is proper to be solved using maximum entropy model.
Suppose
![]() , for each label
, for each label ![]() , there are some entity instances which contain
, there are some entity instances which contain ![]() in the instances set
in the instances set ![]() . For each instance
. For each instance ![]() which appears in web page
which appears in web page ![]() and contains
and contains ![]() , we can calculate a probability of
, we can calculate a probability of ![]() being of an attribute type
being of an attribute type ![]() in
in ![]() as
as ![]() , where
, where ![]() is a context of
is a context of ![]() and is composed of some features created based on
and is composed of some features created based on ![]() ,
, ![]() and
and ![]() . Then, for
. Then, for ![]() , we can calculate its average probability being of the attribute type
, we can calculate its average probability being of the attribute type ![]() as
as
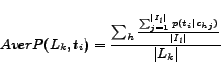 |
(3) |
If
![]() , where
, where ![]() is a certain threshold, and
is a certain threshold, and ![]() can not be determined by labels concurrence factor to be of different attribute type from
can not be determined by labels concurrence factor to be of different attribute type from ![]() , then labels in
, then labels in ![]() are of the attribute type of
are of the attribute type of ![]() ; Else, labels in
; Else, labels in ![]() are not of the type
are not of the type ![]() . Moreover, if labels in
. Moreover, if labels in ![]() are determined to be not of all the types in
are determined to be not of all the types in ![]() , they should be of a new attribute type.
, they should be of a new attribute type.
Given the instance ![]() and the web page
and the web page ![]() , the probability of
, the probability of ![]() being of the attribute type
being of the attribute type ![]() is
is
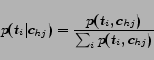 |
(4) |
The distribution ![]() in above constaints is given by
in above constaints is given by
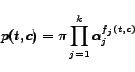
In our problem, the context of an attribute label is based on the set of labels, values, types, and words surrounding the label in the web page, which can be seen as the ``scene'' of the label. The ``scene'' of label ![]() in an instance
in an instance ![]() which appears in a web page
which appears in a web page ![]() is
is
Based on the ``scene'' of ![]() , the features can be created by scanning each pair
, the features can be created by scanning each pair ![]() in the training data with the feature ``templates'' given in Table 1, where
in the training data with the feature ``templates'' given in Table 1, where ![]() is the attribute type of the label with the ``scene''
is the attribute type of the label with the ``scene'' ![]() , and the training data is created using the attribute types in the current schema
, and the training data is created using the attribute types in the current schema ![]() . Given
. Given ![]() as the current ``scene'', a feature always asks some yes/no question about
as the current ``scene'', a feature always asks some yes/no question about ![]() , and constrains
, and constrains ![]() to a certain attribute type. The instantiations for the variables
to a certain attribute type. The instantiations for the variables ![]() and
and ![]() in Table 1 are obtained by automatically scanning training data.
in Table 1 are obtained by automatically scanning training data.
For example, for a label ``Birth time'' named ![]() , one feature with scene
, one feature with scene ![]() might be
might be
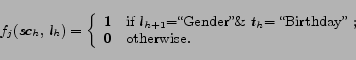
For this feature, each entity instance in training set is automatically scanned to initialize it. If ![]() is found in one instance with attribute type ``Birthday'', and ``Gender'' is the label behind it,
is found in one instance with attribute type ``Birthday'', and ``Gender'' is the label behind it, ![]() (
(![]() ,
, ![]() ) is to
) is to ![]() in this instance; else, it's set to 0.
in this instance; else, it's set to 0.
We select person-type and movie-type entities to evaluate the performance of our technique. For entities of each entity type, we specify two different initial models and guarantee each model is able to characterize them. We list these four initial models in Table 2, where ![]() and
and ![]() are models for person-type entities, and the others are for movie-type entities.
are models for person-type entities, and the others are for movie-type entities.
To the best of our knowledge, our research is the first study aimed at learning a global attribute schema for all the web entities of a specific entity type. The only relevant study is [8], which also aims at mining a global schema from an attribute label set. While, this study requires high-quality schemas as input and is sensitive to errors in schemas, and its efficiency decreases sharply with the increase of the unique labels' number in schemas. We select the algorithm ![]() in [8] as the baseline, and implement it to compare the result's quality and the algorithm's efficiency with our method.
in [8] as the baseline, and implement it to compare the result's quality and the algorithm's efficiency with our method.
| Model | Details of model |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| Model | # iterations | # time (hour) | # instances | # pages | # frequent labels | # unfrequent labels |
|
|
6 | 90 | 111879 | 556211 | 839 | 9012 |
|
|
8 | 110 | 129954 | 666742 | 863 | 9264 |
|
|
10 | 86 | 107798 | 257665 | 406 | 1849 |
|
|
9 | 79 | 93853 | 232348 | 383 | 1713 |
Actually, the learning of an attribute schema can be seen as the clustering of labels with the aim of grouping labels of the same attribute type into the same cluster. Assume the gold schema is
![]() ,
,
![]() , and the learned schema is
, and the learned schema is
![]()
![]() . Then, the labels clustering result corresponding to
. Then, the labels clustering result corresponding to ![]() is
is
![]() , and labels clustering result corresponding to
, and labels clustering result corresponding to ![]() is
is
![]()
![]() . We utilize weighted average Fscore (waFscore), which is often used in clustering evaluation[13,23], as the evaluation metric to measure the quality of the learned schema
. We utilize weighted average Fscore (waFscore), which is often used in clustering evaluation[13,23], as the evaluation metric to measure the quality of the learned schema ![]() , using the waFscore of
, using the waFscore of ![]() compared with
compared with ![]() .
.
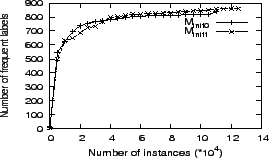
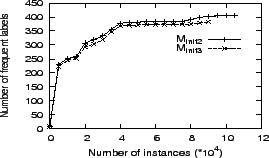
For movie-type instances, the two models are also capable of extracting enough instances, and the change of the frequent labels' number with the increase of the extracted movie instances' number is illustrated in Figure 4. The same conclusion can be drawn from this figure. Furthermore, it is observed that ![]() frequent labels created by
frequent labels created by ![]() also appear in the
also appear in the ![]() labels created by
labels created by ![]() , and we select
, and we select ![]() 's result as the working basis for movie-type entities.
's result as the working basis for movie-type entities.
To evaluate the quality of the extracted instances, we randomly select ![]() instances from the results of
instances from the results of ![]() and
and ![]() , respectively, and do the evaluation by manually checking them. The result is illustrated in Table 4. As we can see our algorithm could extract instances of specified entity type precisely, at the same time some errors exist for the errors in the mining of data regions.
, respectively, and do the evaluation by manually checking them. The result is illustrated in Table 4. As we can see our algorithm could extract instances of specified entity type precisely, at the same time some errors exist for the errors in the mining of data regions.
Moreover, in order to find out why the attribute-label error ratio of movie-type entities (![]() ) is higher than that of person-type entities (
) is higher than that of person-type entities (![]() ), we manually check the pages including these instances, and find that movie entity instances often appear in some arbitrary created pages with other movie instances, and the borders between them are not clearly identified by HTML tags, which makes the data region mining technique invalid when processing these pages. While person entity instances often appear in well-structured pages which include the resumes of persons, and data regions can be accurately mined from these pages.
), we manually check the pages including these instances, and find that movie entity instances often appear in some arbitrary created pages with other movie instances, and the borders between them are not clearly identified by HTML tags, which makes the data region mining technique invalid when processing these pages. While person entity instances often appear in well-structured pages which include the resumes of persons, and data regions can be accurately mined from these pages.
| Entity type | Precision | Entity-type | Attribute-label |
| error ratio | error ratio | ||
| person-type | |
|
|
| movie-type | |
|
|
Labels concurrence factor: For person-type entities, we randomly select ![]() frequent attribute labels, compute labels concurrence factor for each pair of them, and get
frequent attribute labels, compute labels concurrence factor for each pair of them, and get ![]() pairs with nonzero labels concurrence factors. Then, we manually evaluate whether labels in these pairs are actually of different types and find
pairs with nonzero labels concurrence factors. Then, we manually evaluate whether labels in these pairs are actually of different types and find ![]() pairs of labels which are of different types. Finally, we utilize our algorithm to automatically judge whether two labels are of different types, by determining whether their labels concurrence factors is above a certain threshold. Similarly, we randomly select
pairs of labels which are of different types. Finally, we utilize our algorithm to automatically judge whether two labels are of different types, by determining whether their labels concurrence factors is above a certain threshold. Similarly, we randomly select ![]() frequent labels for movie-type entities, and do the same experiment. We get
frequent labels for movie-type entities, and do the same experiment. We get ![]() pairs with nonzero labels concurrence factors and find
pairs with nonzero labels concurrence factors and find ![]() pairs of labels which are of different types.
pairs of labels which are of different types.
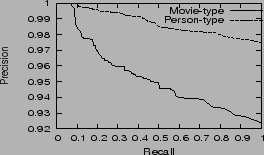
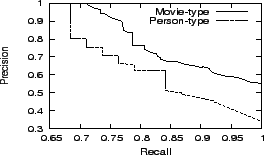
Figure 5 shows the relation between the precision and recall of the judgment when using different thresholds. We can see that the precision of judgment for person-type entities is always higher than that of movie-type entities. It is because the attribute-label error ratios of person-type entities are lower than those of movie-type entities as illustrated in section 6.3.1, and more pairs of movie-type entities' labels which are not of different types appear together in some instances due to higher attribute-label error ratios.
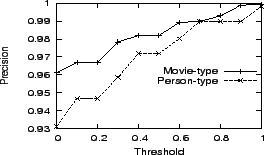
To get precise judgment, we select ![]() as the best threshold for person-type entities, and
as the best threshold for person-type entities, and ![]() as the best threshold for movie-type entities.
as the best threshold for movie-type entities.
Same entity-value factor: The basis of this factor is the judgment of whether two instances are of the same entity. For person-type instances, we randomly select ![]() person names from extracted instances and make sure each person name has at least 3 different instances, and totally get
person names from extracted instances and make sure each person name has at least 3 different instances, and totally get ![]() instances. Then, we calculate overlaps of attribute values for all pairs of instances which own the same name. After that, for each pair of instances which own the same name, we manually make the judgment on whether they are of the same entity. We also select
instances. Then, we calculate overlaps of attribute values for all pairs of instances which own the same name. After that, for each pair of instances which own the same name, we manually make the judgment on whether they are of the same entity. We also select ![]() movies from
movies from ![]() movie instances and run the same experiment. Figure 6 shows the precisions of the proposed method in section 5.1.1 for different thresholds. As we can see that this simple method is effective to make right judgments, and we select
movie instances and run the same experiment. Figure 6 shows the precisions of the proposed method in section 5.1.1 for different thresholds. As we can see that this simple method is effective to make right judgments, and we select ![]() as the best threshold to be used in experiments.
as the best threshold to be used in experiments.
Based on the judgment about two instances being of the same entity, we can calculate same entity-value factor for each label pair. If the factor is above a certain threshold, our algorithm can judge that they are of the same type. Figure 7 shows the relation between the precision and recall of the judgment with different thresholds for ![]() frequent labels of person instances and
frequent labels of person instances and ![]() frequent labels of movie instances. As we can see that the precision of judgment for movie-type entities is always higher than that of person-type entities. It is because movie-type entity instances include less meaningless attribute values than person-type entity instances.
frequent labels of movie instances. As we can see that the precision of judgment for movie-type entities is always higher than that of person-type entities. It is because movie-type entity instances include less meaningless attribute values than person-type entity instances.
In order to get precise result, we select ![]() as the best threshold for person-type entities, and
as the best threshold for person-type entities, and ![]() as the best threshold for movie-type entities.
as the best threshold for movie-type entities.
Candidate attribute types: For person-type entities, we select the top ![]() frequent attribute labels to generate candidate attribute types, because these labels account for
frequent attribute labels to generate candidate attribute types, because these labels account for ![]() percent of all the labels' occurrences in the extracted instances. We get
percent of all the labels' occurrences in the extracted instances. We get ![]() pairs of labels which are of different attribute types and
pairs of labels which are of different attribute types and ![]() pairs of labels which are of the same attribute types, and generate
pairs of labels which are of the same attribute types, and generate ![]() candidate attribute types. For movie-type entities, we select the top
candidate attribute types. For movie-type entities, we select the top ![]() frequent labels since they account for
frequent labels since they account for ![]() percent of all the labels' occurrences, and get
percent of all the labels' occurrences, and get ![]() pairs of labels which are of different types and
pairs of labels which are of different types and ![]() pairs of labels which are of the same types, and generate
pairs of labels which are of the same types, and generate ![]() candidate attribute types.
candidate attribute types.
| Label set | Occurrence ratio | # Created different schemas |
| Top10 | 0.5679 | 809 |
| Top20 | 0.6824 | 3388 |
| Top30 | 0.7235 | 4594 |
| Top40 | 0.7527 | 5202 |
| Label set | Method | WaFscore | Running time(s) |
| Our method | 1.0 | 60.67 | |
| Top10 | Baseline | 1.0 | 0.068 |
| Our method | 1.0 | 96.65 | |
| Top20 | Baseline | 0.7917 | 0.248 |
| Our method | 1.0 | 395.03 | |
| Top30 | Baseline | 0.7527 | 3.875 |
| Our method | 0.9837 | 631.52 | |
| Top40 | Baseline | -- | about 1553586 |
Comparison with the baseline
As mentioned in section 6.1, we select ![]() in [8] as the baseline, in which the input is a set of schemas consisting of attribute labels. Moreover, due to the time complexity of the baseline, for
in [8] as the baseline, in which the input is a set of schemas consisting of attribute labels. Moreover, due to the time complexity of the baseline, for ![]() and
and ![]() , we only select the top 10, 20, 30 and 40 labels from them, and get four label sets. Then, for each created label set
, we only select the top 10, 20, 30 and 40 labels from them, and get four label sets. Then, for each created label set ![]() , we create schemas by automatically scanning each extracted instance
, we create schemas by automatically scanning each extracted instance ![]() to create one set of labels which are both in
to create one set of labels which are both in ![]() and
and ![]() , and regarding this label set as the schema. Finally, we run
, and regarding this label set as the schema. Finally, we run ![]() using these schemas to create the desired attribute schemas, and compare the result's quality and the algorithm's efficiency with our method.
using these schemas to create the desired attribute schemas, and compare the result's quality and the algorithm's efficiency with our method.
For the baseline, since the hypothesis space is too big (360600 for person-type entities, and 2826021 for movie-type entities) when the number of labels is 40, we only estimate its running time. From the analysis of the baseline's running log, we find that running time is mainly spent on ![]() estimation. From the theoretical analysis of the algorithm, we discover that the time spent on
estimation. From the theoretical analysis of the algorithm, we discover that the time spent on ![]() estimation of each hypothesis is the same. As a result, by recording the running time spent on
estimation of each hypothesis is the same. As a result, by recording the running time spent on ![]() estimation for a small number of hypothesizes, we estimate the running time of all the hypothesizes for the baseline.
estimation for a small number of hypothesizes, we estimate the running time of all the hypothesizes for the baseline.
For person-type entities, the details of the four label sets created on ![]() are illustrated in Table 5, in which the second column, occurrence ratio, is the ratio of the occurrences of labels of the corresponding label set to the occurrences of all the labels in extracted instances, and the third column is the number of different schemas created by this label set. Table 6 shows the comparison of result quality and efficiency between our method and the baseline. As we can see the result's quality of our method is better than the baseline, which is because the baseline is too sensitive to the errors of schemas, while our method utilizes probabilistic method to eliminate errors. Furthermore, when the label set is small, the efficiency of the baseline is higher than our method, while with the increase of the label set's size, the efficiency begins to decline sharply for its exponential time complexity. However, the decline of our method's efficiency is far more smoother than the baseline.
are illustrated in Table 5, in which the second column, occurrence ratio, is the ratio of the occurrences of labels of the corresponding label set to the occurrences of all the labels in extracted instances, and the third column is the number of different schemas created by this label set. Table 6 shows the comparison of result quality and efficiency between our method and the baseline. As we can see the result's quality of our method is better than the baseline, which is because the baseline is too sensitive to the errors of schemas, while our method utilizes probabilistic method to eliminate errors. Furthermore, when the label set is small, the efficiency of the baseline is higher than our method, while with the increase of the label set's size, the efficiency begins to decline sharply for its exponential time complexity. However, the decline of our method's efficiency is far more smoother than the baseline.
Moreover, the baseline is only effective when the number of labels is less than 40, and become impractical even when processing the Top40 label set, which only accounts for ![]() of the labels' occurrences and is inadequate to create the global attribute schema. Therefore, the baseline can not create the global attribute schema effectively and efficiently. On the contrary, as the evaluation result illustrated, our method can learn the global attribute schema effectively and efficiently.
of the labels' occurrences and is inadequate to create the global attribute schema. Therefore, the baseline can not create the global attribute schema effectively and efficiently. On the contrary, as the evaluation result illustrated, our method can learn the global attribute schema effectively and efficiently.
We run the same experiment on movie-type entities, and the details of the label sets created on ![]() are illustrated in Table 7. The comparison result is illustrated in Table 8, and we can see that our method also outperforms the baseline.
are illustrated in Table 7. The comparison result is illustrated in Table 8, and we can see that our method also outperforms the baseline.
| Label set | Occurrence ratio | # Created different schemas |
| Top10 | 0.7361 | 356 |
| Top20 | 0.8213 | 1631 |
| Top30 | 0.8598 | 2286 |
| Top40 | 0.8821 | 2887 |
| Label set | Method | WaFscore | Running time(s) |
| Our method | 1.0 | 46.24 | |
| Top10 | Baseline | 1.0 | 0.038 |
| Our method | 1.0 | 74.06 | |
| Top20 | Baseline | 0.8333 | 0.413 |
| Our method | 0.9877 | 286.65 | |
| Top30 | Baseline | 0.7444 | 0.609 |
| Our method | 0.9694 | 547.36 | |
| Top40 | Baseline | -- | about 51372504 |
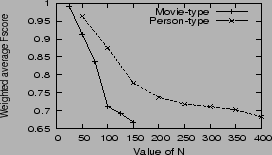
The comparison is illustrated in Figure 8. As we can see that our method perform well when the size of label set is relatively small and the performance declines with the growth of the label set. This is because that the labels with lower frequency own less features to characterize their attribute types, while the labels with higher frequency possess more features. However, even for the Top300 label set of person-type entities, which accounts for ![]() of the labels' occurrences, the wavFscore of the created global attribute schema is still acceptable (
of the labels' occurrences, the wavFscore of the created global attribute schema is still acceptable (![]() ), and the time spent on schema creation is
), and the time spent on schema creation is ![]() seconds (about
seconds (about ![]() minutes); for the Top100 label set for movie-type entities, which account for
minutes); for the Top100 label set for movie-type entities, which account for ![]() of the labels' occurrences, the waFscore of the created global attribute schema is also acceptable (
of the labels' occurrences, the waFscore of the created global attribute schema is also acceptable (![]() ), and the time used to create the schema is
), and the time used to create the schema is ![]() seconds (about
seconds (about ![]() minutes).
minutes).
This paper explores the problem of learning a global attribute schema for web entities of a given entity type. This problem is essential to facilitate the integration of entity instances and perform valuable and reasonable web object extraction, and is difficult due to the complexity and variety of web entity instances. We propose a general framework to automatically learn a global attribute schema, and further specialize it to develop an iterative instances extraction algorithm to extract sufficient instances and attribute labels, as well as a maximum entropy-based approach to construct the global attribute schema. We demonstrate our technique on person-type and movie-type entities on the Chinese Web, and create two global attribute schemas for the entities of these two types, and the weighted average Fscores for the two created schemas are 0.7122 and 0.7123, respectively. These results validate the efficiency and effectiveness of our technique in learning the global attribute schema for web entities of the specific type.