Learning Personal Preferences on Online Newspaper Articles from User Behaviors
Hidekazu Sakagami, Tomonari Kamba
C&C Research Laboratories, NEC Corporation
4-1-1 Miyazaki, Miyamae-ku, Kawasaki, Kanagawa 216, Japan
sakagami@mmp.cl.nec.co.jp, kamba@mmp.cl.nec.co.jp
Abstract
This paper discusses methods by which user preferences for WWW-based
newspaper articles can be learned from user behaviors.
Two modes of inference were compared in an experiment:
one using explicit feedback and the other using implicit feedback.
In the explicit feedback mode, the users score all articles
according to their relevance.
In the implicit feedback mode, the user reads articles
by performing scrolling and enlarging operations,
and the system infers from the operations how much the user was
interested in each article.
Our newspaper on the WWW, called ANATAGONOMY,
has a learning engine and a scoring engine on the server.
The system users read daily news articles by using a WWW browser
in which there is an interaction agent that monitors the user behaviors.
The learning engine on the server infers user preferences from
the interaction agent,
and the scoring engine scores new articles and creates personalized
newspaper pages based on the extracted user profiles.
In an experiment, the system was able to personalize the
newspaper to some extent when using only implicit feedback when some
parameters were properly set,
but the personalization was not as precise as it was when
explicit feedback was used.
By mixing explicit feedback with implicit feedback, the system
could personalize newspapers quickly and precisely without
requiring too much effort on the part of the users.
User preferences can also be used to construct information retrieval
agents or even to create cyberspace communities of the users
that have similar interests.
We think that the proposed technique for learning user
preferences greatly enhances the value of the WWW.
Keywords:Personalization, On-line newspaper, World Wide Web, User preference
1. Introduction
With the advent of the network age, individuals have become able to
easily access a huge amount of heterogeneous information,
such as that available on the World Wide Web (WWW),
but it is difficult to pick up really useful content from this
sea of information.
There are two possible approaches to solving this problem:
- Search service:
- the user inputs keywords and then gets search
results, as with on Yahoo [I] and Lycos [II].
- Personalization service:
- relevant information customized for each user is delivered
constantly, as with the Personal Wall Street Journal [III] and
Pointcast Network [IV].
Both services are popular these days, but their aims are different.
In search services, users with fairly clear objectives gather
information actively whereas the systems in personalization services
provide information pro-actively to users who are rather passive (Figure 1).
In everyday life, people usually read newspapers and watch TV programs
rather passively when they are not looking for any special information.
Once they find something interesting, they search actively in order
to get additional related information.
As this example shows, actively gathering information and passively
receiving information are complementary activities.

Figure 1. Search service and personalization service.
Information retrieval has been the subject of various studies
some of which can be applied to personalization services,
but these services also require techniques other than
those used for active information retrieval.
It is necessary, for example, that the system learn about user
preferences.
Users of personalization services do not want to specify what
information they need, and even so, the system needs to find the
information the users will be interested in and it has to show them
to the users.
Therefore, the system has to be able to learn user preferences
precisely without requiring too much effort of the users.
This paper describes methods for extracting user preferences on
daily newspaper articles.
It focuses on a technique to determine user preferences,
as automatically as possible,
by evaluating user operations when online newspaper articles
are accessed.
Regarding techniques to learn user preferences, the following
kinds of studies have been done targeting Netnews and other articles.
- Direct extraction of user preferences:
- The system asks users to register their interests in the form
of keywords, topics, and so on.
This technique is used in a news filtering services such as SIFT [1],
developed at Stanford University, and Pointcast Network [IV].
One of the advantages of this method is the transparency of system
behavior.
When articles have been delivered to a user,
the user can usually easily guess why each article was delivered.
One problem with this method, though, is that it requires
much effort on the part of the user.
Human interests change as time passes.
For example, people are very interested in earthquake information
just after a big earthquake, but this interest gradually
decreases over time.
It is cumbersome for users to have to modify keywords often.
Another problem is that people cannot necessarily specify what
they are interested in because their interests are sometimes
unconscious.
- Somewhat indirect extraction of user preferences:
- In the NewsWeeder [2] developed by Lang et al., the system learns
user preferences by asking users to specify their interest in each
article's page.
When the user moves from one document page to another,
he or she specifies how interesting the old page is by choosing a
position on a long bar.
The users thus have a greater mental load than they do when
just reading documents, because they are also required to
score them.
- Indirect extraction of user preferences:
- Morita et al. tried an experiment to anticipate user preferences
on the basis of the time spent reading each article in Netnews,
and they achieved good results [3].
This approach also intuitively reasonable because we tend to spend
more time reading interesting articles than uninteresting ones.
In their experiment, however, they asked the subjects
"to do nothing but read articles", that is, "not do other things
such as leaving the terminal a while to get a cup of coffee or
reading newly arrived e-mail messages".
These conditions show the limitations of their method.
In actual situations, we often receive e-mail and telephone calls
and are subjected to other interruptions.
Therefore, their method is not sufficiently practical.
We will describe a method to extract user preferences by monitoring
ordinary user operations such as scrolling articles.
We have applied the method to our personalized newspaper on the WWW,
and found that it is more practical because users do not need to
stick to reading articles and can read articles as they like.
Compared with the NewsWeeder,
The users' mental load is greatly reduced below that what it is
with the NewsWeeder because users not need to specify their interest
in all articles explicitly.
The user preferences derived in our system are currently used only
to provide personalized layouts of the online newspaper,
but can also be applied in many other systems (such as information
retrieval agents) or even to creating communities of the users
that have similar interests in cyberspace.
2. Anatagonomy: a personalized on-line newspaper
ANATAGONOMY, our personalized newspaper on the WWW,
has an architecture similar to the Krakatoa Chronicle
developed by Kamba et al. [4].
It differs from conventional WWW-based newspapers in that
the server does not manage the page layout.
Instead, the server has a scoring engine and a learning engine.
The scoring engine helps to create a newspaper page, and the
learning engine learns user profiles.
The scoring engine computes the importance of each article by comparing the
article's document vector (words and their frequencies of occurrence) and
the user profile.
Roughly speaking, an article gets a high score for a user
when it has a document vector similar to the user's profile
(Figure 2(a)).
This importance has a value that is called an article score.
The user profile is a set of words and their weights.
For example, if a user is interested in articles featuring the word
"Clinton," the word is given a high weighting in the user's profile.
Conversely, if a user shows little interest in articles related to
baseball, the word "baseball" will be given a low or negative weight.
The learning engine builds a user profile when the user scores a set of
articles showing how interesting each article is (Figure 2(b)).
Roughly speaking, a word in a user profile is given a high weighting
when the word appears frequently in high-scored articles.
Both the scoring engine and the learning engine were developed by
Nakamura et al. [5].

Figure 2.Scoring engine and learning engine.

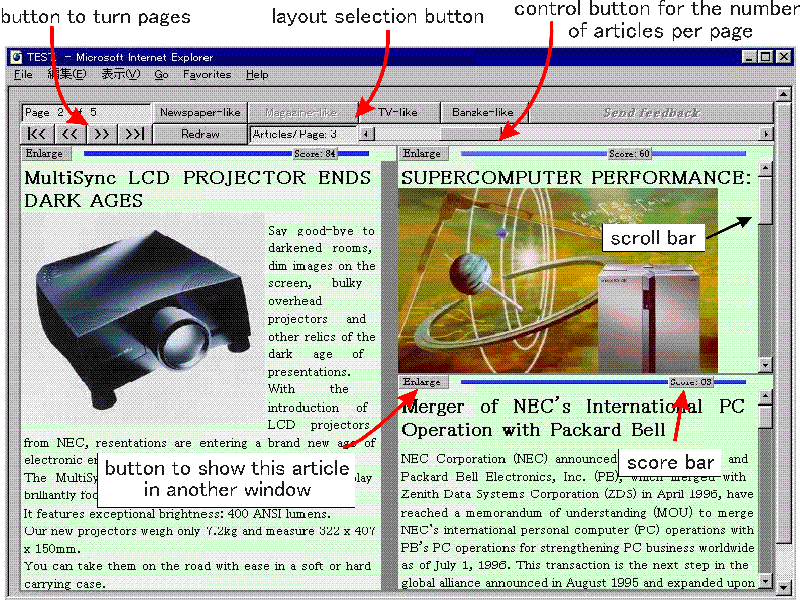
Figure 3. Example of the newspaper layout.

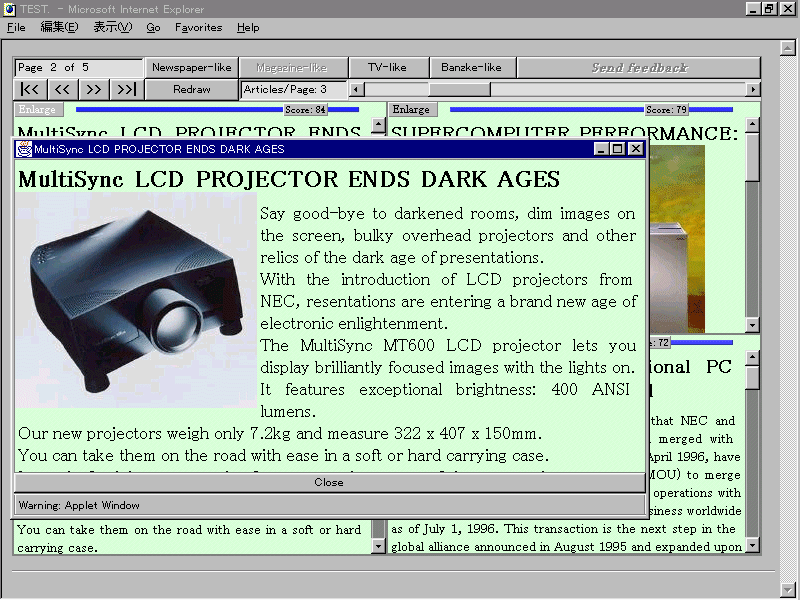
Figure 4. Example of an enlarged article.
After the scoring engine scores the day's articles for a user,
an interaction agent on the client (which is a Java applet downloaded from
the server) creates a newspaper page layout based on the article scores.
Articles that have high scores are allotted prominent locations and large
screen spaces.
This client-server architecture provides the following features to
our system.
- The user can switch the page layout algorithm.
Currently, the system provides several layouts(newspaper-like,
magazine-like, etc.) and is able to show all the articles
sequentially without requiring any input from the user.
Figure 3 shows an example of the layout.
- Each article has a score bar to show the score anticipated by the
scoring engine (see Figure 3).
The user can change the score value if it does not show his or her
interest in the article correctly.
The server is notified of the new score, and the learning engine
on the server modifies the user profile according to the new score.
- Interactions on our newspaper pages are not limited to ones on
pages written in Hypertext Markup Language (HTML).
For example, the user can choose an article and see it on another
window.
This operation is called "Enlarge."
Figure 4 shows a screen on which an article has been enlarged.
The user can read the article more easily by enlarging it.
- The above-mentioned operations on page layout and on articles are
monitored by the interaction agent and are notified to the server.
The system can infer user preferences from these operation records.
3. Experiment
3.1 Preliminary Experiment
We asked thirteen users (who already understood operations needed
to read articles on our system) to read thirty of a day's articles
on ANATAGONOMY.
We asked them to then rank all the articles
between A (very relevant) and E (not relevant at all).
Regarding rank A as 90 points, B as 70 points, C as 50 points,
D as 30 points, and E as 10 points, we calculated the averages for
scores given by the users.
We then examined the relationship between the user operations on articles
and the scores given to the articles (Table 1).
According to Table 1,
For all users, the average scores for the scrolled articles were
higher than the average scores for all articles.
The average scores for the enlarged articles were also higher than the
average scores for all articles.
In addition, articles that were both scrolled and enlarged got
higher scores than articles that were either scrolled or enlarged.
Operation logs indicated that users tended to first scroll articles
and then enlarge them after finding that they were worth reading
in entirety.
Table 1. Relationship between operations and scores
(total number of articles was 30).
| Number of subjects |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
Number of
scrolled articles |
23 |
7 |
10 |
8 |
3 |
0 |
11 |
12 |
25 |
7 |
14 |
9 |
7 |
Number of
enlarged articles |
4 |
0 |
0 |
0 |
7 |
0 |
9 |
0 |
5 |
0 |
0 |
2 |
0 |
Number of both
scrolled & enlarged articles |
3 |
0 |
0 |
0 |
3 |
0 |
1 |
0 |
5 |
0 |
0 |
0 |
0 |
Average scores of
all articles |
49.3 |
44.7 |
22.0 |
38.7 |
33.4 |
28.7 |
37.3 |
37.3 |
51.0 |
15.0 |
45.7 |
45.3 |
36.0 |
Average scores of
scrolled articles |
52.6 |
70.0 |
32.0 |
50.0 |
90.0 |
- |
46.4 |
70.0 |
57.6 |
32.9 |
50.0 |
58.9 |
37.6 |
Average scores of
enlarged articles |
60.0 |
- |
- |
- |
78.6 |
- |
45.6 |
- |
66.0 |
- |
- |
70.0 |
- |
Average scores of both
scrolled & enlarged articles |
70.0 |
- |
- |
- |
90.0 |
- |
50.0 |
- |
66.0 |
- |
- |
- |
- |
We therefore decided to give bonus points for the "scroll" and "enlarge"
operations.
When the user does these operations on an article, bonus points are
added to the article's score and the new score is sent to the server.
That is, these operations have the same effect that raising an
article's score by using a score bar does (Figure 5).
Conversely, when the user neither scrolls nor enlarges an article,
the same effect is then as when the user decreases the article's score.
When the user changes an article's score by using a score bar,
we call this explicit feedback. And when the system automatically
changes an article's score according to the user's ordinary operations
(such as "scroll" or "enlarge"), or even according to "no operations,"
we call this implicit feedback.

Figure 5. Two types of feedback.
3.2 Comparison of explicit feedback and implicit feedback
We compared the personalization effect of the explicit feedback mode
with that of the implicit feedback mode.
Fifteen users who already understood how to read articles on ANATAGONOMY
were divided into the following three groups, each of which included
five subjects.
- Group A:
- The subjects of this group gave no implicit feedback.
Instead, all subjects were asked to score all articles by using a
score bar each day.
- Group B:
- The subjects of this group gave bonus points.
When a subject scrolled or enlarged an article, the system added
10 points to the article's score.
When both operations occurred, 20 points were added.
Even when the user performed the same operation more than once,
only 10 points were added.
The score for an article that was neither scrolled nor enlarged
was decreased by 10 points.
The subjects were not allowed to give explicit feedback.
- Group C:
- The subjects of this group also gave only implicit feedback,
but the bonus was 30 points.
We downloaded about thirty articles every day from external news sites
and asked the subjects to read them for six days.
We also asked the users by e-mail to give all articles rankings between A
(very relevant) and E (not relevant at all).
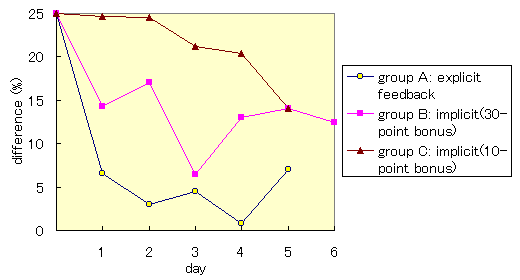
Figure 6(a) shows the chronological change in the averaged difference
between the score orders anticipated by the system and the rank orders
given by the subjects.
The difference is normalized with the total number of articles.
To get the score orders anticipated by the system, the user profiles
accumulated by the previous days were used.
To get the rank orders given by the subjects, the ranks the user
specified between A and E were used as the first sorting criterion.
Within the same rank, the scores anticipated by the system were used
as the second sorting criterion.
(a) Difference between the orders anticipated by the system
and the ranks given by the subjects (chronological change).
(b) System anticipation and user rating of Group B on the 6th day.
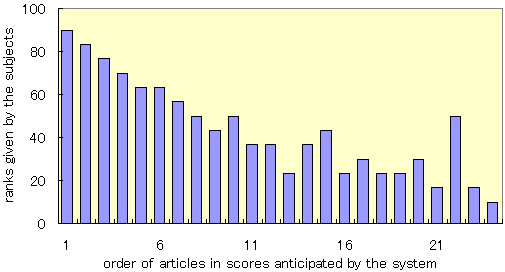
(c) System anticipation and user rating of Group A on the 4th day.
Figure 6. Comparison of explicit feedback and implicit feedback.
As Figure 6(a) shows, in Group A (explicit feedback mode),
the differences between the score orders anticipated by the system
and the rank orders given by the users decreased day by day
and almost stabilized within three days from the beginning of the
experiment.
In Group B (10-point bonus), the difference between the score orders
anticipated by the system and the rank orders given by the subjects
decreased a great deal on the first day, but the difference did not
decrease very much after that.
In Group C (30-point bonus), the difference between the two orders was
quite large and did not stabilize.
The system regarded the subjects in Group C to be interested in too many
topics, since some articles were given extremely high implicit scores,
and the anticipated scores were too high compared with the subjects'
actual interests.
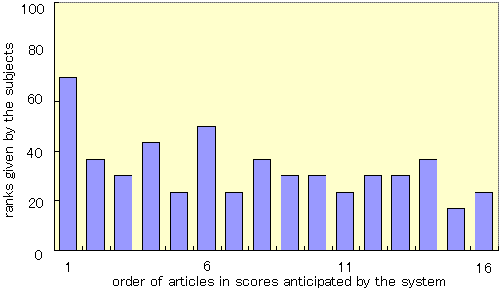
Illustrating that personalization worked well in Group B, Figure 6(b) shows
the relationship between the order of the article scores anticipated by the
system and the user's ratings.
In short, this graph shows that articles given high scores by the system's
anticipation were also given high scores by the users.
We can observe the following things from these graphs.
- Personalization works well in the explicit mode.
That is, the learning engine and the scoring engine work well.
- The success of personalization by implicit feedback depends on the
setting of operation bonus points.
In our experiment, personalization worked with 10 bonus points
but it did not work at all with 30 bonus points.
- When bonus points are set properly, personalization works
from the first day.
This surprised us because we expected that several
days would be needed for personalization.
- Even when bonus points were set properly, however, the newspaper
created by using implicit feedback could not be personalized
as well as the one created using explicit feedback mode
(compare Figure 6(b) and 6(c)).
4. Discussion and follow-up experiment
Although the experiment in the previous section shows that we can infer
user preference to some extent when using only implicit feedback
when the bonus points are properly set,
implicit feedback is inferior to explicit feedback.
During the experiment a subject provided us with the following clues to
solving this problem.
- He said:
- Implicit feedback is effective but the user might sometimes
want to specify his or her interest in an article explicitly.
For example, sometimes the user may find a very interesting
article and may want to increase the article's score to the
highest point.
And sometimes the user will want to decrease an article's score
after reading through the complete article because after reading
it he or she finds it irrelevant.
We therefore expected that the use of both explicit
feedback and implicit feedback would be very effective.
The user's mental load should be lower than
in the explicit feedback mode because users do not need to specify
interest in all articles explicitly.
They will give explicit feedback only when they wish to show
explicit interest.
We thus tried a follow-up experiment over six days
for the following group described below.
- Group D:
- The subjects in this group, like those in Group B, were given
a 10-point bonus.
The subject could also give explicit feedback by
using score bars.
The results were as follows:
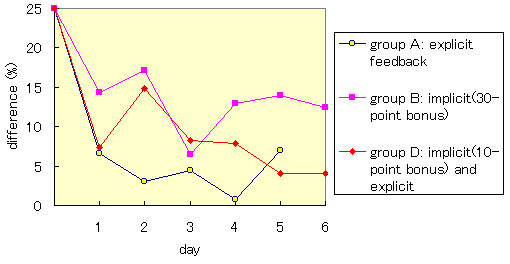
(a) Difference between the orders anticipated by the system and
the ranks given by the subjects (chronological change).
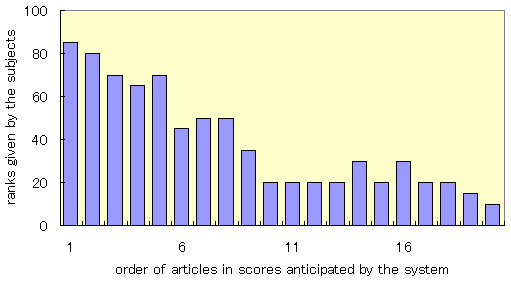
(b) System anticipation and user rating of Group D on the 5th day
Figure 7: Mixing explicit feedback and implicit feedback.
- The difference between the score orders anticipated by the system
and the rank orders given by the subjects decreased as accurately
and as quickly as in the case of the users giving explicit
feedback on all the articles (Figure 7(a) and 7(b)).
- The average number of articles for which users changed scores
explicitly was six.
These results show that the newspaper could be personalized accurately,
quickly although users explicitly specified scores for only
one third of all the articles.
5. Conclusion and Future Work
We described a method for personalizing an on-line newspaper by
learning users' preferences from their operations on articles.
It was shown that the newspaper could be successfully personalized by
mixing explicit feedback and implicit feedback.
Explicit feedback means that the user gives scores to articles,
and implicit feedback means that the system automatically infers
the user's preferences from the user's operations.
Providing implicit feedback greatly decreases the users' efforts, whereas
providing explicit feedback helps the system to infer user preferences
accurately.
In our current system, the extracted preferences are used only to
provide personalized layouts of the newspaper,
but there are various other occasions in which the preferences can be used
effectively.
For example, the personal preferences will also make it possible for
an online newspaper to provide personalized advertisements
that match each user's interest.
In search services such as the directory service,
the user will be able to get information that matches his or her taste
without typing keywords.
Another example that uses these preferences effectively would be
a "matching agent,"
which is an agent that finds the users who have similar interests by
comparing the user preferences.
This agent will be useful for constructing "communities" in cyberspace.
Another advantage of the preferences extracted from the user's
natural operations is that they sometimes include a user's
unconscious or subconscious preferences.
In the proposed method, the keywords are not defined by the users
but are collected from the articles that the users get interested in, and
their importance values are modified automatically.
When we ourselves used this system continuously, some articles were
given high scores by the system although they do not seem to fit is
our interests at first sight.
Even in such cases, however, we often found that they included topics
related to our interests when we read them carefully.
This implies that a user's unconscious or subconscious
preferences can suggest important topics that would likely be
missed if these preferences were ignored.
Therefore, they will be especially useful for constructing the
communities of the users that have similar interests.
These are only some cases in which the preferences
can be used efficiently, and we think that the proposed method for
learning user preferences greatly enhances the value of the WWW.
Note
ANATAGONOMY is named after a Japanese word "ANATA-GONOMI," which
means "as you like."
This is because our system is intended to create a newspaper that is
customized to the user's preferences.
References
- Yan, T.W, and Garcia-Molina, H. (1995): "SIFT - A Tool for
Wide-Area Information Dissemination", USENIX Technical Conference,
pp. 177-186.
- Ken Lang: "NewsWeeder: Learning to Filter NetNews",
Proceedings of the 12th International Conference on Machine Learning
(ICML'95), pp. 331-339 (1995).
- Morita, M., and Shinoda, Y. (1994):
"Information Filtering Based on User Behavior Analysis
and Best Match Text Retrieval",
Proceedings of the 17th Annual International ACM-SIGIR Conference on
Research and Development in Information Retrieval, pp. 272-281.
- Kamba, T., Bharat, K., Albers, M.C. (1995):
"The Krakatoa Chronicle -
An Interactive, Personalized Newspaper on the Web -",
Fourth International World Wide Web Conference Proceedings,
pp. 159-170.
- Nakamura, A., Mamizuka, H., Toba, H., Abe, N. (1995):
"Learning personal preference functions using boolean-variable
real-valued multivariate polynominals", 52nd National Convention of the
Information Processing Society of Japan (in Japanese).
- Kamba,T., Sakagami, H. and Koseki, Y. (1997):
"ANATAGONOMY: A Personalized Newspaper on the WWW,"
International Journal of Human-Computer Studies,
Special Issue on Innovative Applications of the World Wide Web
(to be appeared in March 1997).
URLs
- Yahoo : http://www.yahoo.com/
- Lycos: http://www.lycos.com/
- The Personal Wall Street Journal:
(http://www.ptech.wsj.com/)
- Pointcast Network: http://www.poincast.com/
Return to Top of Page
Return to Technical Papers Index