

Journal reference: Computer Networks and ISDN Systems, Volume 28, issues 7–11, p. 1321.
The explosive growth in the Web leads to the need for personalized client-based local URL repositories often called bookmarks. We present a novel approach to bookmark organization that provides automatic classification together with user adaption.
The explosive growth in information that becomes available on the Web, and the dynamic nature of the location and contents of such information, has led to the development of various search services (e.g., Yahoo, Lycos, InfoSeek, Excite, Alta Vista) which use "crawler" programs to collect new or updated documents, and information retrieval techniques for indexing and storing information to enable fast and accurate retrieval of these documents. Termed search engines, these are essentially huge URL (Universal Resource Locator) databases that hold characteristic information on each URL to determine its relevance to a given query.
In addition to the server-based global repositories maintained by search engines, there is a need for personalized client-based local URL repositories. Unlike their global counterparts, local repositories store only address and minimal state information per document and are used mainly to remember interesting sites or documents to revisit in the future. But despite the different purposes, they are nontheless URL repositories. These repositories are termed HotLists in Mosaic, Quicklists in WebExplorer, and Bookmarks in Netscape Navigator (we will refer to them as bookmarks from now on) and were initially represented as a simple flat list of URLs. As the use of the Web becomes more prevalent and the size of personal repositories grows, however, adequately organizing and managing bookmarks becomes crucial, somewhat analogous to the need to organize files in a private disk. As a result, a browser such as Netscape Navigator 2.0 has recently added support for tree-like directory (or folder) structure for organizing bookmarks. Such hierarchical organization enables users to browse easily through their repository to find the necessary information, (assuming that the documents were adequately classified and that the user remembers his/her classification scheme). However, manual URL classification and organization can be difficult and tedious when there are more than a few bookmarks to classify or when the user lost track of his classification scheme. Moreover, unlike file systems, the contents of the URLs may not be in the local cache so fetching the document only in order to refresh the user's memory about its contents might be time consuming.
In this paper we present a novel approach to bookmark organization as well as a tool that embodies this approach. The gist of our approach is in combining manual and automatic organization facilities that enable a user to flexibly determine when to apply automatic organization, and on what subsets to apply it. Section 2 describes how bookmarks are typically collected and explains why it is difficult to organize them entirely manually. Section 3 presents our high-level approach to bookmark organization. Section 4 presents the design of the organizer tool, covering analysis, clustering and search techniques used. Section 5 describes a sample scenario, and Section 6 gives some implementation notes. Section 7 concludes the paper. Related work is discussed as relevant throughout the paper.
The typical paradigm of ``net-surfing'' is characterized by visiting a series of URLs, occasionally spotting an interesting URL and adding it to the local repository on-the-fly. Manual classification of bookmarks is likely to be difficult for the following reasons:
Often, a user needs to classify a large set of URLs at once, as opposed to adding a single URL. Reasons for such multi-URL classification include:
The user has often very little knowledge or remembrance of what the bookmark is about, and how URLs are related to each other. Even if s/he knows roughly what the bookmark is about, s/he can at best perform a high-level classification i.e., store the bookmark in a top category), but cannot make a fine distinction among related bookmarks. Besides the obvious advantage of organizing documents by their relevance to each other, fine-level classification also helps to detect duplicates or highly similar documents and determine whether to keep or delete them (a typical example is when a Web search returns the same RFC under mutiple URLs and in various formats).
Regardless of the origin of the bookmark set, manual classification into an existing hierarchy is a tedious task that one might want to automate. One alternative to automatic classification could be to organize bookmarks per "journey" while surfing, by simply recording the history of traversed URLs and storing them in the same folder. Indeed, some browsers support this organization in addition to a flat bookmark list. For example, the IBM OS/2 WebExplorer uses WebMap to store history alongside the flat Quicklist.
While potentially useful in some cases, classifying bookmarks per journey is not adequate because typically the set of traversed URLs is not homogeneous.
Typical bookmark repositories contain bookmarks which are collected by a single person with a limited and well-defined set of interests (compared to multi-user repositories). This implies that a repository is likely to have an inherent partitioning into groups with high intra-group similarity and low inter-group similarity. Such organization just needs to be discovered. Hence, providing automatic assistance in organizing bookmark repositories by their conceptual categories would be extremely beneficial. This is the goal of the Bookmark Organizer (BO) that we present here.
Facing the strong need for automated organization, coupled with the need to retain full control with the user, we advocate a non-intrusive policy and suggest a hybrid approach in which manual and automatic organization are ``equal partners''. A user can employ only manual organization, fully automatic organization, or as in the typical case, interleave manual and automatic phases. Most importantly, to enable fine granularity with respect to the scope of application, a user can apply either mode of organization on a defined subset of the repository, recursively.
Automatic and manual organizations correspond to two modes that can be used alternatively and in a coordinated way. A user can define ``core'' categories manually, or import existing high-level taxonomies such as SmartMarks, and then apply automatic organization only within these categories. Alternatively, a user can automatically generate categories and manually arrange each category. Still, the user is free to (re)define categories and the partitions that are under "automatic clustering" control, but he/she does not have to apply either mode globally, on the entire repository.
In addition to fine granularity, this approach also promotes modularity, in that applying automatic organization can be done on part of the repository without affecting other loosely related parts of the repository.
One of the key features of BO is to allow users to mark internal nodes as frozen. By freezing nodes that have been manually defined or customized from automatically identified nodes, the user communicates with the automatic tool and ensures that the tool will not interfere with the manually-defined structure. More specifically, by freezing a node N, the user signifies that the subtree SN rooted at N represents a coherent group of documents. In particular, it prevents from automatic clustering to break this boundary by, say, re-clustering it with documents from other subtrees and generating new directory structure; however, it still allows to refine N's internal organization by automatically clustering any unfrozen subtree of SN.
Hence, a BO directory structure can be viewed in general as a tree with some "fat" frozen leaves treated as black-box subtrees. There are no restrictions on where in the hierarchy a frozen node can be placed; frozen nodes may even be nested, i.e., a frozen node can have a subtree which is also marked as frozen. However, in general we expect that frozen nodes will be mostly effective when defined relatively close to the root in the hierarchy, to represent high-level categories that are not likely to evolve as often as lower-level nodes.
The user does not know in which category to place the new bookmark (or does not care to find it), and requests automatic assistance. In this case, BO applies a very precise search technique (described later in Section 4), and determines the most relevant frozen cluster. It then inserts the document into the proper cluster by applying automatic clustering on it. This in turn generates a new organization in this cluster but does not affect any other part of the hierarchy.
The user specifies the node into which to insert the new document. He/she can now request (automatic) re-organization of bookmarks. Consequently, the algorithm climbs up the tree to find the closest frozen ancestor and applies the clustering algorithm on the sub-cluster. Note that this technique is applied at its best when the new bookmark is added to a frozen cluster.
It may seem that deletion of documents should not impose further actions from BO. However, since clustering is based on inter-document relationships, the absence of several documents might invalidate the raison d'etre of a given cluster. In other terms, since a cluster represents a set of documents that share some commonality, it might happen that after deletion not enough documents remain present to represent any shared abstraction. One could argue that the node could remain even if half empty. This would be the case only if it is frozen by the user. If not, reclustering should be performed to reflect other abstractions since the context has changed. Suppose, for example that document A was initially clustered with document B as the most similar document; document C, which was slightly less related to A but on another topic, was left aside because the clustering technique does not support overlapping. If B is deleted, it means that the user lost interest in it, and its the key topic. But since A was not deleted, it should probably now be clustered with C. Thus to enforce consistency, whenever a document is deleted, reclustering is applied on the containing sub-cluster.
Finally, movement of documents across sub-clusters is handled as an addition in the target sub-cluster and as a deletion in the origin sub-cluster.
Each time BO executes on a repository it stores in each internal node a computed checksum that characterizes its children (note that simply keeping the number of children is not sufficient because of possible addition followed by deletion). In addition, each leaf is annotated as "old". Addition of new documents or folders is easily detected since they don't have "old" or checksum notations. To identify movements/deletions, the checksum at each node is recomputed and compared with the previous value to determine whether the contents of its subtree have changed. If they did (whether added or deleted) and the parent node is frozen or a descendant of a frozen node, re-clustering takes place. Note that "addition" may actually be a movement of a pre-existing document from another folder, which explains why a binary flag would not suffice either.
The automatic organization of bookmarks per contents is done by applying sophisticated document clustering techniques. Clustering of documents has been primarily used in information retrieval (IR) for improving the effectiveness and efficiency of the retrieval process [Rasmussen 92] or more recently, for providing a new access paradigm [Cutting et al. 92]. We are more concerned here with the primary use of cluster analysis which is the visualization of underlying structures for explanation purposes.
Since the bookmark hierarchy is going to be shown to the user not only used internally by, say, a retrieval engine, it has to be more meaningful and more precise than what is usually required by document clustering techniques in IR.
We have described in [Maarek et al. 94] how one could take advantage of sophisticated indexing techniques based on multiple word indexing (namely lexical affinities as defined in [Maarek et al. 91]), not only to generate precise cluster hierarchies but also to associate a great deal of conceptual information with each cluster so as to facilitate the understanding and naming of clusters. We briefly explain below what cluster analysis consists of and the general principle of the algorithms we use. The reader is referred to [Maarek et al. 94] for more details.
The HAC method can be described as follows. Given a set of objects (or documents in IR applications):
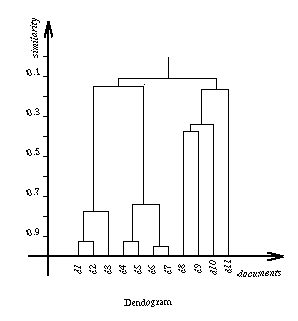
An example of the cluster hierarchy or dendogram to use the correct terminology thus generated is shown in Figure 1.
One major drawback with clustering documents is that wrong clusters might be induced by noisy or ambiguous indices. To reduce the influence of such indices, we use here a highly precise indexing scheme in which indexing units are not single words but pairs of words that are linked by a lexical affinity (LA). An LA between two units of language stands for a correlation of their common appearance [Saussure 49]. It has been described elsewhere how LAs can be extracted from text at a low cost via a sliding window technique and how an LA-based scheme allows to significantly increase precision in domain specific collections such as software documentation collections [Maarek et al. 91], [Maarek 91].
The LAs are represented as pairs of lexically ordered words. Note that a morphological analyzer is used rather than a stemmer to obtain more precise and meaningful indices. The weight associated to each index is a simple cosine normalized frequency. We have demonstrated that using LA-based rather than single word profiles significantly improve the precision of the generated clustering hierarchy. The example below compare a LA-based profile and a single-word based profile for the same document (entitled: " IBM Online library: Softcopy Collection") to show how LAs are less ambiguous and more informative:
normalized frequency /single word profile
LA-based profile
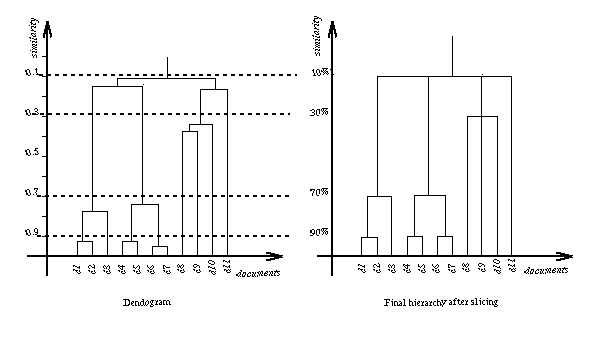
Hierarchies generated by the classical HAC are often inconvenient to visualize as they are binary. In many applications of cluster analysis such as classification of animal species, chemical structures etc., experts have to manually select the most adequate level clusterings in the dendogram to ease their discovery task. This is a rather tedious job, we therefore propose to automate it by slicing the hierarchy at meaningful levels. In the previously cited paper [Maarek et al. 94] that introduced this LA-based document clustering, we proposed a slicing method based on the ideal branching factor of nodes so as to control the clusters size. After usability studies, we discovered that in the context of bookmarks organization, users were not comfortable with the notion of controlling clusters size (this was rather a library administrator's concern) as it has no semantic meaning. They rather were interested in getting clusters that have a comparable degree of conceptual similarity. Therefore we introduce here a slicing technique - which we find more adapted to bookmarks organization - that automatically identifies the level clusterings within the tree which have a comparable degree of intra-cluster similarity. This slicing technique is described below.
One can associate with every level in the dendogram a measure of similarity between 0 and 1 that corresponds to the value for which the last cluster merging was performed. For instance, in Figure 1, documents d1 and d2 are merged at level 0.97, and clusters {d1,d2} and {d3} at level 0.81. Thus for every level, we know what the minimum degree of intra-cluster similarity is and it can be expressed as a percentage (0%= not similar whatsoever, 100%= identical). Thus, from the dendogram shown in Figure 1, one can infer that documents d1 and d2 are 97% similar and documents d4 and d5 are 98% similar. It is clear that the user does not need to distinguish between levels of similarity that are so close. S/he would rather know what clusters correspond to a degree of similarity of approximately 90%, or 80%, etc.
One very simple way to select representative levels is therefore to slice the tree at regular intervals of 10% of similarity and collapse into one single level all levels between two slices. The slicing method is illustrated in Figure 2 below.
A bookmark collection is thus structured automatically in five steps.
One major problem of cluster hierarchies is that they are difficult to interpret for non-experts. The problem is twofold. Users have difficulties identifying clusters in the classical dendogram layout (e.g., they have to understand that an horizontal line corresponds to a cluster) as shown in Figure 1. Once this difficulty is overcome, they have trouble understanding what the cluster is about. Indeed, with numerical clustering algorithms, clusters are defined in extension, i.e., by enumeration of their members, rather than in intention i.e., by membership rules. There is for instance no direct way to name a cluster. This is crucial when dealing with bookmark hierarchies since every node correspond with a folder that must receive a name to enable further easy browsing.
The problem of displaying clusters of documents to the user has already been addressed in the past. It has been often proposed to represent the cluster information defined by the dendogram in a different manner. Typical examples are two-dimensional displays, where clusters are represented as "bubbles" [TEWAT], [Botafogo 93]. We believe however that the tree representation should not be dropped. First, it is the historical mean of displaying cluster information since the beginning of taxonomy techniques in the 18th century, but mostly most computer literates are familiar and comfortable with hierarchical structures. To cite just a simple example: most users know how to browse hierarchical directory structures. Yet cluster hierarchies can be made easier to visualize making them dynamic graphical objects which layout can be interactively manipulated. Note that this view seems to be shared by some as the current bookmark windows in Netscape Navigator 2.0 precisely used this hierarchical folder, or directory like, structure (See Figure 4). In addition, such a hierarchy can be made easier to interpret by enriching them with conceptual information (in quantitative or qualitative form) as explained below.
To help users understand what a cluster (or bookmark folder) is about, we dynamically generate a list of characterizing key concepts for each cluster by computing the centroid of all the vector profiles associated to the documents within the cluster. Using the center of gravity instead of performing a simple intersection operation allows us to keep all the relevant concept information. The cluster indices are then sorted according to their weights, and those with the higher scores are selected as key concepts. We have explained before that using lexical affinities instead of single words to represent concepts is much less ambiguous. However, it might happen that understanding the underlying concept in lexical affinities requires some prior tutoring. Typical examples are triple-word concept. For instance "NCSA Mosaic documentation" would be represented by 2 or 3 binary lexical affinities .e.g., (Mosaic,NCSA) (documentation,Mosaic) (documentation,NCSA) (note that component words are listed in lexicographic order). Thus, if the user sees the 3 following lexical affinities with similar score: (application,development), (development, kit), (application kit), s/he must able to infer that they actually stand for the single concept "application development kit".
We thus compute for every bookmark cluster (including the singular case of a singleton cluster formed by a unique document) a list of key concepts represented by LAs and that form a inherent part of the description of the bookmark folder. In addition, we select the best LAs from this list of key concepts, and use them as a pseudo-title for the folder that the user can leave as such or replace by a more stylistic phrase. It a future stage, we intend to use this information to reanalyze the document taking the extracted LAs into account so as to generate a syntactically correct title (via longer collocations for instance).
Another way to enrich the cluster hierarchy is to keep the measure of similarity for which each cluster was formed. We have explained above that the intra-cluster similarity notion is intuitive to users. That is the reason for which we use it as a criterion to select representative levels from a binary dendogram. Thus, a cluster with an intra-cluster similarity of 99% is at the same level in the tree as another cluster whose similarity is 95% or yet another one whose similarity is 92%. By collapsing all these former levels into a single one some information is lost that might be useful in some cases. For instance a 99% degree of similarity between documents reveals that the documents are probably perfect duplicates, whereas a degree of similarity of 92% shows that they differ by few sentences.
Thus, we keep this intra-cluster similarity rate, which indicate the quality of the bookmark folder and associate it as one of its properties that the user can consult upon demand.
As explained above, we can compute for every cluster/folder a profile (represented as a vector of LAs) by analyzing its members. Whenever, a node is frozen we do not need to index the cluster - as it has already been done - but only to store them in an inverted index format, as done in standard information retrieval methods [Salton et al. 83]. Then, searching for the most relevant node consists of feeding to the retrieval engine the entire contents of the bookmark as a free-text query and getting as result a ranked list of frozen nodes. At this stage, the rest of the mechanism can be again fully or semi automated.
In this example, a user who surfed mainly for sites related to his hobbies (Tennis and Cars) and having a very short bookmarks list, decided suddenly to learn everything about Java and using Lycos issued the query "Java ". He scanned the results and from time to time added a bookmark, without deeply reading any of the documents. By doing so, he realizes that his flat bookmark list becomes suddenly pretty long and needs to be organized.
Therefore he decides to use the Bookmark Window Management in Netscape Navigator 2.0 for the first time. He first looks at the window and sees only a flat list. See Figure 3 below.
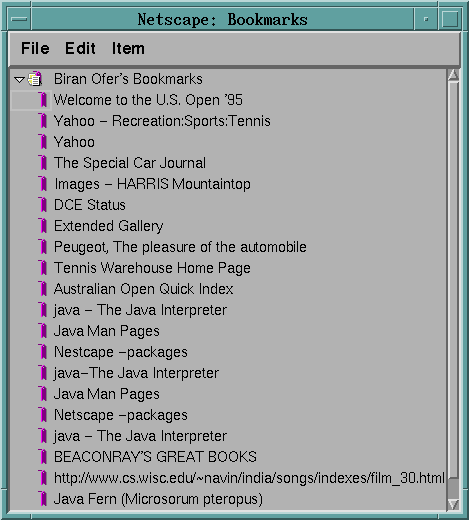
Figure 3: A Flat Bookmark List
So he decided to at least distinguish between his previous and new interests and created three high level folders that he called: My Hobbies, Java and he simply dragged and dropped (or cut and paste) all his bookmarks into the relevant categories (See Figure4)
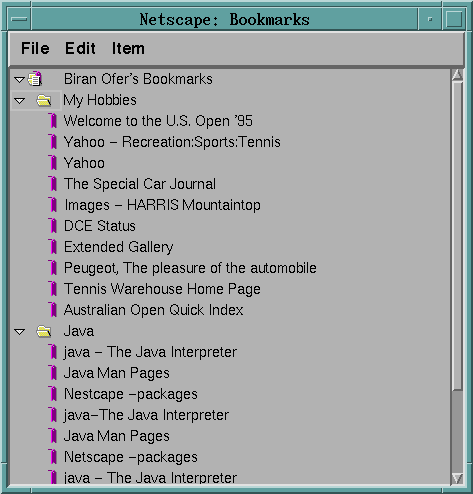
Being exhausted at having done that, he stopped and decided to use BO on his bookmark file. So, he went into the properties of his two folders and entered the keyword FROZEN in the description field, to notify BO not to touch this high level classification, but only to organize what is below it. Then, as an external application, he run BO giving it as input his private bookmarks.html file and generate a new file that he called new_bookmarks.html. Turning again towards his Navigator Bookmarks Window, he imported the file new_bookmarks.html (and thus generated a high-level top folder) to check BO's results as shown in Figure 5 below.
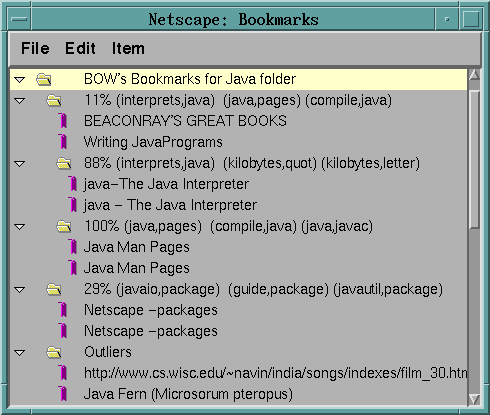
BO has identified 3 first level categories and attributed automatically a pseudo_title for each of them:
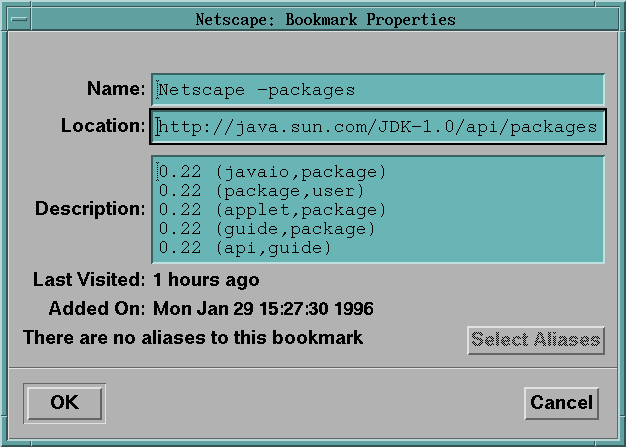
In addition, the user can have more conceptual information about a cluster or document, via a list of key concepts represented as LAs. This information is stored as a property of the URL under the description field as shown in Figure 6
From this point, the user can decide to freeze some sub categories that seem really important and get rid of his previous unorganized falt-list, still using the same interface.
Note that for the sake of the simplicity and in order not to generate too large figures, we reduced the number of bookmarks handled in this example. In practice however, BO can easily handle several hundreds of bookmarks.
We used a standard "XOR and bit rotating" checksum function that computes the checksum value over a stream consisting of the concatenation of the state information on all children. Recall that this function is used only to indicate whether or not changes were made in a node's subtree, and not to characterize the changes (if any). Once a change is detected, reclustering is applied as explained above.
Evaluation of the quality of the clusters generated have already been presented in [Maarek et al. 94]. For this bookmark application, we intend to conduct further usability studies in the future.
Our novel approach, embodied in the BO tool, is to provide automatic classification mechanism that uses clustering analysis to organize documents based on their conceptual similarity, but enable the user the freedom to select when and on what part of the hierarchy (which itself has been previously classified either manually or automatically) to apply it, thereby allowing full co-existence and compatibility of manual and automatic classification.
Thanks to Ofer Biran for volunteering his bookmarks files for our typical scenario, and to Amir Herzberg for complaining about strangers reordering his desk.
Israel Ben-Shaul is an assistant professor in the Electrical Engineering department at the Technion. He received his BSc in Mathematics and Computer Science from Tel Aviv University in 1988, and his MS and PhD in Computer Science from Columbia University in 1991 and 1995, respectively. As a research staff at Columbia (1990–1991) he also served as the project manager in the Programming Systems Lab. Prior to joining the Technion he was a research fellow at the IBM research laboratory in Haifa. His research interests include distributed and heterogeneous systems, software engineering, workflow management systems, groupware, information retrieval, and federated databases.