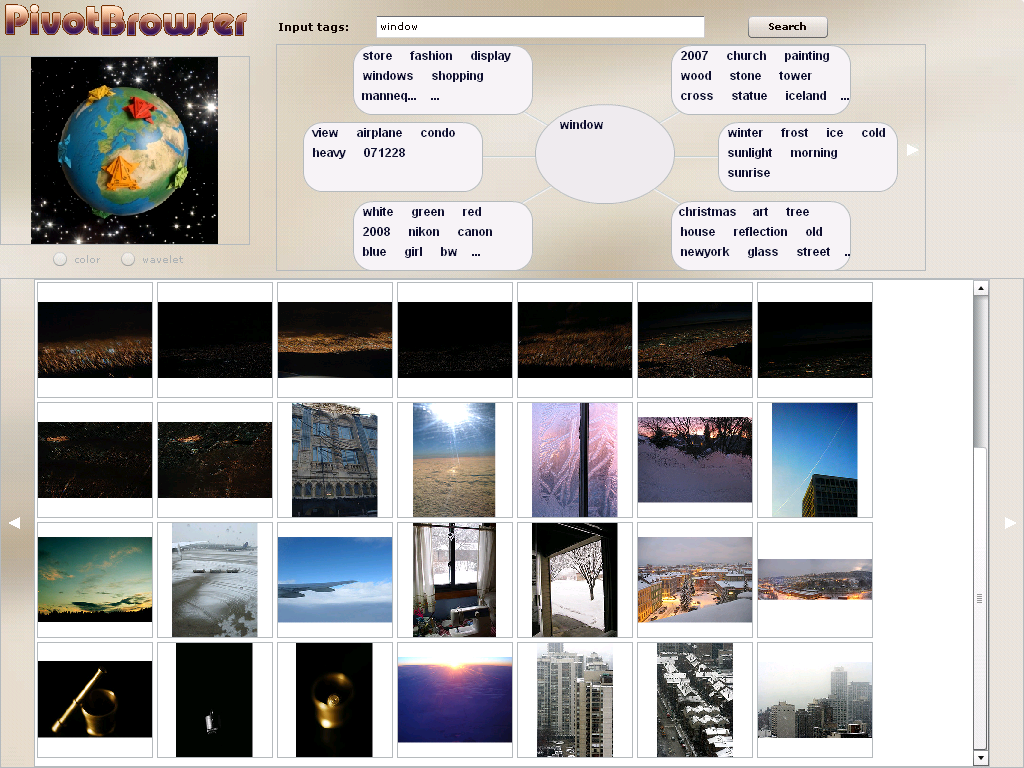
Tagging based search systems are known to be prone to semantic errors or limitations [2]. To name a few: Different users may use different tags (maybe synonyms) to describe the same object, causing inconsistency in tagging; The existence of polysemy (single term having multiple meanings) in a query causes ambiguity, and the query is often hard to refine; The distribution of the tags being used is usually skewed and has the long-tail characteristic. Therefore, on one hand, images with rare tags cannot be easily found. On the other hand, queries with rare tags may need to be expanded to larger scopes. We propose PivotBrowser, an iterative searching and refining prototype for tagged images. PivotBrowser employs a novel tag-based structure called pivot to address the above problems. Our approach is different from a previous work on social tag clustering [1] as we can handle both synonymy and ambiguity.
To introduce the concept of pivot, we first give the
definition of tag atom based on the
availability of a tag thesaurus. The
tag thesaurus contains lexical relevance information for all
tags, such as the synonyms (``flower, bloom, blossom''), the
spelling variations (plural, abbreviation, etc.), and the other
highly relevant terms (``film'' vs. ``movie''). A good example of
tag thesaurus is the one used in the WordNet[3]. A tag
atom ![]() is a set of tags that satisfy the
following requirements: (1) If a tag atom
is a set of tags that satisfy the
following requirements: (1) If a tag atom ![]() contains a tag
contains a tag
![]() , it must
also contain all lexically relevant tags of
, it must
also contain all lexically relevant tags of ![]() as defined in the
thesaurus; (2) For any two tags in
as defined in the
thesaurus; (2) For any two tags in ![]() ,
, ![]() and
and ![]() , they must be lexically relevant to each other.
It is important to note that one tag may possibly appear in
multiple tag atoms as it can have more than one lexical meaning
in the thesaurus. Therefore, given a universe of tags
, they must be lexically relevant to each other.
It is important to note that one tag may possibly appear in
multiple tag atoms as it can have more than one lexical meaning
in the thesaurus. Therefore, given a universe of tags
![]() , we
can precompute an inverted list for all possible tag atoms based
on the tag thesaurus. Each entry in the inverted list is like
following
, we
can precompute an inverted list for all possible tag atoms based
on the tag thesaurus. Each entry in the inverted list is like
following
A pivot atom of tag ![]() , denoted as
, denoted as ![]() , is defined as the
union of all tag atoms which contain
, is defined as the
union of all tag atoms which contain ![]() (or those in the same
entry of
(or those in the same
entry of ![]() in TAIL). A pivot of
in TAIL). A pivot of ![]() tags,
tags,
![]() , is defined as the set
containing all pivot atoms of its tags,
, is defined as the set
containing all pivot atoms of its tags,

The interactive pivot browsing is an iterative process consisting of the following three phases:
(1) First, when a user issues a query ![]() containing tags
containing tags
![]() , the system looks up the TAIL to
find the tag atoms for each query tag
, the system looks up the TAIL to
find the tag atoms for each query tag ![]() . By merging the tag
atoms for each query tag, we obtain a pivot
. By merging the tag
atoms for each query tag, we obtain a pivot
![]() . For each tag set
. For each tag set
![]() supported
by
supported
by ![]() , we look
up the inverted index of the image database to find images where
all tags in
, we look
up the inverted index of the image database to find images where
all tags in ![]() co-occur. These images are saved as a candidate image set
co-occur. These images are saved as a candidate image set
![]() , and
all tags associated with them are saved (except for the query
tags in
, and
all tags associated with them are saved (except for the query
tags in ![]() )
as a candidate tag set
)
as a candidate tag set ![]() for further consideration in the subsequent
phases.
for further consideration in the subsequent
phases.
(2) Second, all candidate tags in ![]() will undergo a
selection pass, and the top-
will undergo a
selection pass, and the top-![]() candidates relevant to
candidates relevant to ![]() will be obtained.
Meanwhile, the relevance value of each tag is saved as its
weight. The tag selection method will be discussed in section
2.3.
will be obtained.
Meanwhile, the relevance value of each tag is saved as its
weight. The tag selection method will be discussed in section
2.3.
(3) Third, the ![]() tags in the output of the previous phase will be
clustered on the fly using a graph-partitioning algorithm as
proposed in [4]. The
affinity metric for clustering is based on the precomputed
tag-to-tag affinity values. These
tags in the output of the previous phase will be
clustered on the fly using a graph-partitioning algorithm as
proposed in [4]. The
affinity metric for clustering is based on the precomputed
tag-to-tag affinity values. These ![]() tags, grouped in their clusters, will then be
presented to the user for a new round of tag
selection/refinement. Meanwhile, one of the tag clusters (by
default the most compact one) will be used to select the images
in
tags, grouped in their clusters, will then be
presented to the user for a new round of tag
selection/refinement. Meanwhile, one of the tag clusters (by
default the most compact one) will be used to select the images
in ![]() -
only candidates with tags which appear in the cluster are
selected. Ranking of the output images is based on the relevance
between the tag vector of each image and the weighted vector of
the cluster. The latter can be obtained from the results of phase
2. A user can certainly choose another tag cluster for image
selection and browsing. If a user subsequently adds a new tag to
or removes an old one from the query, the pivot browsing process
enters the next iteration (goto phase 1).
-
only candidates with tags which appear in the cluster are
selected. Ranking of the output images is based on the relevance
between the tag vector of each image and the weighted vector of
the cluster. The latter can be obtained from the results of phase
2. A user can certainly choose another tag cluster for image
selection and browsing. If a user subsequently adds a new tag to
or removes an old one from the query, the pivot browsing process
enters the next iteration (goto phase 1).
We perform 200 unique queries on the prototype. Each query is
executed for 100 times. Table 1
presents the average CPU time for selecting the candidate image
set on the inverted index of the image database (SelectI),
generating the top-![]() relevant tags (SelectT), clustering the
relevant tags (SelectT), clustering the
![]() tags
(ClusterT), and ranking the results (Rank). The time for creating
a pivot is negligible. The results in the table reveal that the
query cost is dominated by the selection on the inverted index of
the image database.
tags
(ClusterT), and ranking the results (Rank). The time for creating
a pivot is negligible. The results in the table reveal that the
query cost is dominated by the selection on the inverted index of
the image database.
Table 1: Run-time CPU Cost in Each Phase
| SelectI | SelectT | ClusterT | Rank | |
|---|---|---|---|---|
| CPU Time (ms) | 535.3 | 15.5 | 97.5 | 78.1 |
In conclusion, the pivot browsing scheme realizes effective query expansion and image searching in the tag-space at a low expense of computation and storage. Therefore, it can help users to find the intended results more effectively compared to conventional methods. We believe that pivot browsing can potentially become a general tag-space search paradigm not only limited to images.
For future work, we would conduct a usability study on PivotBrowser. We would also consider a comprehensive study on incorporating visual feature comparison, and other tag selection and clustering strategies into it.
[1] G. Begelman, P. Keller, and F. Smadja. Automated Tag Clustering: Improving search and exploration in the tag space. In WWW Collaborative Web Tagging Workshop, 2006.
[2] S. A. Golder and B. A. Huberman. Usage patterns of collaborative tagging systems. J. Inf. Sci., pages 198-208, 2006.
[3] G. A. Miller, R. Beckwith, C. Fellbaum, D. Gross, and K. Miller. Introduction to WordNet: an on-line lexical database. International Journal of Lexicography, 3(4):235-244, 1990.
[4] S. White and P. Smyth. A spectral clustering approach to finding communities in graphs. In SDM, 2005.