Ying Yan1
, Chen Wang2
, Aoying Zhou1,3
, Weining Qian3
, Li Ma2
, Yue Pan2
1
Department of Computer Science and Engineering, Fudan University
{yingyan,
ayzhou}@fudan.edu.cn
2
IBM China Research Laboratory
{chwang, malli,
panyue}@cn.ibm.com
3
Institute of Massive Computing, East China Normal University
{ayzhou,
wnqian}@sei.ecnu.edu.cn
Efficiently querying RDF [1] data is being an important factor in applying Semantic Web technologies to real-world applications. In this context, many efforts have been made to store and query RDF data in relational database using particular schemas. In this paper, we propose a new scheme to store, index, and query RDF data in triple stores. Graph feature of RDF data is taken into considerations which might help reduce the join costs on the vertical database structure. We would partition RDF triples into overlapped groups, store them in a triple table with one more column of group identity, and build up a signature tree to index them. Based on this infrastructure, a complex RDF query is decomposed into multiple pieces of sub-queries which could be easily filtered into some RDF groups using signature tree index, and finally is evaluated with a composed and optimized SQL with specific constraints. We compare the performance of our method with prior art on typical queries over a large scaled LUBM and UOBM benchmark data (more than 10 million triples)in [3]. For some extreme cases, they can promote 3 to 4 orders of magnitude.
H.2.4[Systems]Query processing, C.4[Performance of Systems]Design studies
Experimentation, Performance
RDF, Signature, Graph Partitioning, Indexing
The Semantic Web is an effort by the World Wide Web Consortium (W3C) to enable data integration and sharing across different applications. It is designed to evolve the general web which mostly consists of markup or other formats perceived by people into the machine-readable data web. The Semantic Web data model of Resource Description Framework [1] (RDF), recommended by W3C, represents data as a labelled graph connecting resources and their property values with labelled edges representing properties. The graph can be structurally parsed into a set of triples or statements in the form of < subject, predicate, object >. RDF data model is very general and is easy to express any type of data. Though RDF data representation is flexible, it potentially results in serious performance issues since RDF queries involve intensive self-joins over the triple table. When the number of triples is so large that they can not be cached in memory for each filter, the joins will be very expensive because disk scan and index lookup are required. As a general data model, RDF triple table stores any type of data in a column. For example, values of age, weight, or even given name of all persons co-exist in the object column. Accordingly, the statistics collected in these columns complicates selectivity estimation, which will further disable relational database query optimizer to deliver a nice query plan.
At present, creating indices, splitting data into property tables (2-column schema), and materializing join views (e.g., subject-subject and subject-object) are common methods for improving RDF query performance on the vertical database structure. However, it is still urgently needed to figure out new storage and indexing schemes that make relational database much efficient to support RDF query. In this paper, we propose a novel idea to optimize executable SQL for general-purposed triple stores by considering graph feature of RDF data. An intuitive example is given as follows to illustrate the idea and our motivation.
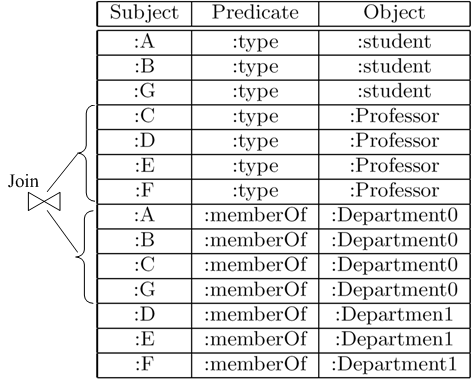
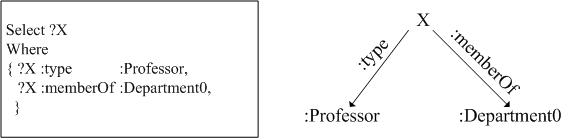
Given a SPARQL [2] query on the left of Figure 1 which logically equals to the query graph on the right, we issue it over the RDF data in Figure 2. Suppose that the triples stored in the table are not well sorted intentionally in advance and no index is created as well. After the SPARQL query is translated and submitted to relational database, query engine might determine a nested-loop self-join on the column of subject accordingly. Roughly estimated, the join will cost 4 X 4 = 16 times of string comparison and 4 + 4 = 8 I/O times. Once the query and data are much more complex, the cost will increase dramatically.
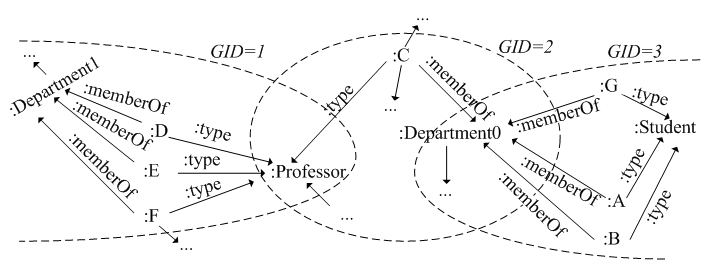
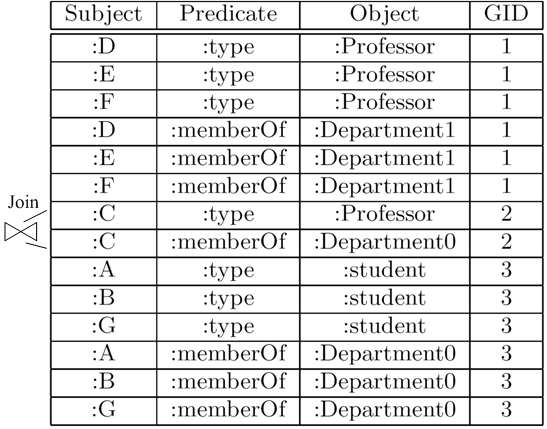
Observing the same example from perspective of graph model shown in Figure 3, even though the triples (or edges bridging two vertices) like <:D :Type :Professor> are totally disconnected with those including <:A :MemberOf :Department0>, <:B :MemberOf :Department0> and <:G