WWW 2008, April 21-25, 2008, Beijing, China.
2008
978-1-60558-085-2/08/04
3
Feature Weighting in Content Based Recommendation System Using Social Network Analysis
Abstract:
We propose a hybridization of collaborative filtering and content based recommendation system. Attributes used for content based recommendations are assigned weights depending on their importance to users. The weight values are estimated from a set of linear regression equations obtained from a social network graph which captures human judgment about similarity of items.
H.3.3Information Storage and RetrievalInformation Search and Retrieval[information filtering]
Algorithms, Design, Experimentation
Recommender System, Social Network, Feature Similarity
Recommendation systems produce a ranked list of items on which a user might be interested, in the context of her current choice of an item. Recommendation systems are built for movies, books, communities, news, articles etc. There are two main approaches to build a recommendation system - collaborative filtering and content based [3]. Collaborative filtering computes similarity between two users based on their rating profile, and recommends items which are highly rated by similar users. However, quality of collaborative filtering suffers in case of sparse preference databases. Content based system on the other hand does not use any preference data and provides recommendation directly based on similarity of items. Similarity is computed based on item attributes using appropriate distance measures. We attempt to hybridize collaborative filtering and content based recommendation for circumventing the difficulties of these individual approaches. Item similarity measure used in content based recommendation is learned from a collaborative social network of users.
Some previous attempts at integrating collaborative filtering and
content based approach include content boosted collaborative
filtering [3], weighted, mixed, switching and feature combination of
different types of recommender system [2]. But none of these talks
about producing recommendation to a user without getting her
preferences. We demonstrate the effectiveness of the proposed system
for recommending movies in Internet Movie Database (IMDB) [1]. From
the results it is seen that our recommendation is quite in agreement
with IMDB recommendation.
In content based recommendation every item is represented by a feature vector or an attribute profile. The features hold numeric or nominal values representing certain aspects of the item like color, price etc. A variety of distance measures between the feature vectors may be used to compute the similarity of two items. The similarity values are then used to obtain a ranked list of recommended items. If one considers Euclidian or cosine similarity; implicitly equal importance is asserted on all features. However, human judgment of similarity between two items often gives different weights to different attributes. For example, while choosing a camera, price of a camera may be more important than the body color attribute. It may be stated that users base their judgments on some latent criteria which is a weighted linear combination of the differences in individual attribute. Accordingly, we define similarity 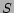 between objects
between objects 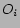 and
and 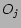 as
as
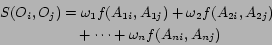 |
(1) |
where 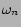 is the weight given to the difference in value of
attribute
is the weight given to the difference in value of
attribute 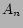 between objects and , the difference
given by
between objects and , the difference
given by
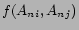 . The definition of
. The definition of 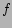 depends on
the type of attribute (numeric, nominal, boolean). We normalize
's to have value in [0, 1]. In general the weights
depends on
the type of attribute (numeric, nominal, boolean). We normalize
's to have value in [0, 1]. In general the weights
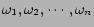 are unknown. In the next section we describe a
method of determining these weights from a social collaborative
network.
are unknown. In the next section we describe a
method of determining these weights from a social collaborative
network.
We have used the above methodology for recommending movie in IMDB database. A set of 13 features are considered. The features along with their type, domain and distance measures are shown in Table 1. All these feature values can be obtained from the IMDB database.
Table 1:
Features Used in Movie Recommendation
| Feature |
Type |
Domain |
Distance |
| |
|
|
Measure |
| Release |
Year |
YYYY |
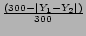 |
| Type |
String |
Movie,TV etc. |
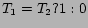 |
| Rating |
Integer |
(0-10) |
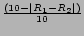 |
| Vote |
Integer |
(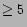 ) ) |
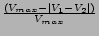 |
| Director |
String |
 Name Name |
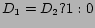 |
| Writer |
String |
Name |
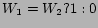 |
| Genre |
(String)* |
Drama etc. |
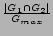 |
| Keyword |
(String)* |
College etc. |
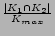 |
| Cast |
(String)* |
(Name)* |
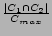 |
| Country |
(String)* |
France etc. |
|
| Language |
(String)* |
English etc. |
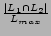 |
| Color |
String |
Color, B/W |
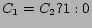 |
| Company |
String |
Name |
|
We estimate the feature weights from a social network graph of items. The underlying principle is to use existing recommendation by users to construct a social network graph with items as nodes. The graph represents human judgment of similarity between items aggregated over a large population of users. Optimal feature weights are considered to be those which induce a similarity measure between items best conforming to this social network graph.
We describe below a linear regression framework for determining the optimal feature weights. Let the items under consideration be denoted by
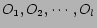 , they corresponds to the vertices of our social network. The edge weight between vertices and ,
, they corresponds to the vertices of our social network. The edge weight between vertices and ,
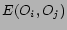 = # of users who are interested in both , .
= # of users who are interested in both , .
, suitably normalized, may be considered as human
judgment of similarity between , . Recall that feature
vector (content based) similarity between , has been
defined as 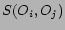 in Eq. (1). Equating with
leads to the following set of regression equations.
in Eq. (1). Equating with
leads to the following set of regression equations.
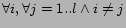 ,
,
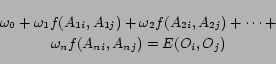 |
(2) |
The values of
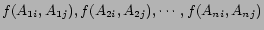 are known from the data as are the values of
. Solving the above regression equations provide
estimates for the values of
. If
there are
are known from the data as are the values of
. Solving the above regression equations provide
estimates for the values of
. If
there are 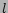 objects under consideration, it is possible to have
objects under consideration, it is possible to have
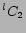 regression equations of the above form. In the case of movie
recommendation we have considered movies as nodes in the social
network. The edge weight between two movies is the number of IMDB
reviewers who have reviewed both the movies.
regression equations of the above form. In the case of movie
recommendation we have considered movies as nodes in the social
network. The edge weight between two movies is the number of IMDB
reviewers who have reviewed both the movies.
The movie database used in our recommendation system consists of 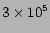 random movies downloaded from the IMDB. The movies voted by less than 5 people or the movies that have not been reviewed by a single person are filtered out. The data is then divided into three equal sets. Each movie is described by 13 features (Table 1).
random movies downloaded from the IMDB. The movies voted by less than 5 people or the movies that have not been reviewed by a single person are filtered out. The data is then divided into three equal sets. Each movie is described by 13 features (Table 1).
Our recommendation system is based on the presumption that feature weights are almost universal
for different sets of users and movies. To test this presumption we consider different sets of regression equations and solve for the weights. We consider the following varieties of regression equations.
I. Equations using only edge weights 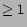 (i.e. movie pairs having at least one co-reviewer)
(i.e. movie pairs having at least one co-reviewer)
II. Equations using only edge weights 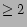 . (Note that this gives a graph which is a sub-graph of the previous graph.)
. (Note that this gives a graph which is a sub-graph of the previous graph.)
For the above graphs we construct a set of equations for each of the
three (partitioned) datasets having 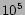 movies. Thus we get six
sets of regression equations which we solve using SPSS package. It
is observed from the weight values obtained from each of the above
six sets of regression equations that some of the features have
stable weight values, while some features like Director, Rating,
Vote, Year, Color have unstable or negative weight. We remove the
features with unstable or negative weights from our regression
equations and obtain the following set (Table 2) of stable weights
for eight features. Also note, out of the 8, 3 features namely type,
writer and company are particularly important. These features along
with their weights are used to obtain the recommendations.
movies. Thus we get six
sets of regression equations which we solve using SPSS package. It
is observed from the weight values obtained from each of the above
six sets of regression equations that some of the features have
stable weight values, while some features like Director, Rating,
Vote, Year, Color have unstable or negative weight. We remove the
features with unstable or negative weights from our regression
equations and obtain the following set (Table 2) of stable weights
for eight features. Also note, out of the 8, 3 features namely type,
writer and company are particularly important. These features along
with their weights are used to obtain the recommendations.
Table 2:
Feature Weight Values
| Feature |
Mean |
Variance |
| Type |
0.18 |
0.0023 |
| Writer |
0.36 |
0.0048 |
| Genre |
0.04 |
0.0001 |
| Keyword |
0.03 |
0.0011 |
| Cast |
0.01 |
0.0003 |
| Country |
0.07 |
0.0013 |
| Language |
0.09 |
0.0004 |
| Company |
0.21 |
0.0110 |
The proposed algorithm is compared with pure content based method (considering equal weights for all features) and IMDB recommendations. Performance is measured using the classical Recall measure, considering IMDB recommendation as benchmark. The experiment has been done on 10 different movies. The proposed method achieves an average recall of 0.29. Where as, the pure content based method achieves a recall of 0.24 with IMDB. Thus the proposed method agrees well with IMDB recommendation and in this regard it outperforms pure content based method. This demonstrates the effectiveness of feature weighting.
A hybridization of content based and collaborative filtering based recommendation is proposed. The weights of different attributes of an item are computed from the collaborative social network using regression analysis. Further studies on other weight estimation techniques like sparse regression and isometric projection are being considered. Also more rigorous performance evaluation based on human judgment will be undertaken.
- 1
-
Internet Movie Database.
http://www.imdb.com.
- 2
-
Bruke, R.
Hybrid recommender systems: survey and experiments,
User Modeling and User Adapted Interaction 12 (2002) 331-370.
- 3
-
P. Melville, R.J. Mooney, R. Nagarajan
Content-Boosted Collaborative Filtering for Improved Recommendations,
Proceedings of the 18th National Conference on Aritificial Intelligence (AAAI-2002), July 2002, Edmonton, Canada.