 |
 |
 |
Email spam has been around for more than a decade, with many covert companies offering mass emailing services for product advertisements. It has become usual for people to receive more spam email than relevant email. The design of the SMTP protocol is one main reason for email spam: it is possible to send millions of fake email messages via computer software without any authentication. Lately, authentication policies have been adopted by various web servers, where webmasters can maintain a list of blocked web domains. However, spammers keep registering millions of domain names at a pace far greater than what system administrators can cope up with.
The biggest step in the fight against spam has been the successful design of spam filtering software. Such software typically trains classifiers to identify spam and ham. For the past decade, much progress has been made in designing accurate classifiers for text emails. These classifiers are trained to use two kinds of rules: (a), rules based on connection and relay properties of the email, and (b), rules exploiting the features extracted from the content of emails. The former category of rules utilize publicly shared blacklists of servers which have been known to transmit spam emails. This information is frequently updated, requiring spammers to change domain names and servers frequently. The second type of rules use features extracted from spam text (e.g. keywords, frequent words etc) which are compared with corresponding features from ham text (normal emails) and classifiers are learnt [6]. Such classifiers have proven to be very useful and highly accurate, even though spammers continue to devise novel ways of fooling them.
|
|
|
Image based spam is a breakthrough from the spammers' view point; it is a simple and effective way of deceiving spam filters since they can process only text. An image spam email is formatted in HTML, which usually has only non-suspicious text with an embedded image (sent either as an attachment or via the use of self referencing HTML with image data in its payload). The embedded image carries the target message and most email clients display the message in their entirety. Since many ham emails also have similar properties (using HTML, carrying embedded images, with normal text) as image-based emails, existing spam filters can no longer distinguish between image-based spam and image ham. A whitepaper released in November 2006 [12] shows the rise of image spam from 10% in April to 27% of all email spam in October 2006 totaling 48 billion emails everyday. It is thus imperative to devise new approaches for identifying image-based spam in email traffic which are both fast and accurate. Clearly, identification of image-based email spam (referred as I-spam here onwards) requires content analysis of the attached image. Since images are a large and heterogeneous data format, it is essential to understand characteristic properties of I-spam in order to identify them successfully. I-spam has been studied very recently by some researchers and it is possible to identify some common traits of currently visible spam images; exploiting these properties forms the basis of our solution to detection of I-spam.
Available figures for 2006 suggest more than 30% of all spam emails are image based, and most of these emails reach email inboxes undetected. Humans are easily able to distinguish spam images from normal spam; moreover, they can abstract from various versions of the same base image, even though these images may have very different properties like background, fonts, or different arrangement of sub-images. Current feature based approaches have had some success in identifying image spam [5]; extracted features include file type and size, average color, color saturation, edge detection, and random pixel test. However these features do not seem to provide good generalization, since spammers can easily modify these features; thus further feature engineering is required. In particular, we observe that computer-generated images do not have the same texture as natural images; natural images like photographs would likely be classified as ham. We therefore postulate that low-level features which capture how an image is perceived are likely to be better discriminants between spam and ham. This is the first part of our detection strategy: to find features which capture how humans perceive spam images vs. ham images.
While some extracted features may provide good generalization, a spammer can clearly realize this and mutate spam images by using more natural/photographic content in spam images. However, creating completely different image spam each time is a costly activity; thus any spam image is likely to have thousands of similar (though not same) images, each generated from the same template image, but modified using the usual spam tricks. Even though image spam may evolve to defeat obvious give-away features (like text), there are likely to be many near duplicates. This forms the second part of our spam detection strategy: to detect near-duplicates of spam images which have been labeled as spam.
As noted earlier, recent work has used feature-based classification to detect I-spam. Dredze et al. [5] have investigated the use of high-level features in classifying I-spam. Table 1 lists the features used by the authors in this work; the core idea is that high level features of the image, for example file format, can be extracted much quicker than lower level features like edges; thus there is an intrinsic ordering of features we want to consider in order to build fast classifiers. The approach is general and our work can easily be extended to this framework.
Other researchers (cf. [16]) have
discussed yet another important aspect which we capture in our methodology:
they have investigated common obfuscation methods like rotation, scaling,
partial translation, font change etc. They correctly identify the procedure
used by spammers to generate image spam; they postulate that the two steps
involved are template generation and the randomization of
template. This procedure makes images sent to different users different in
nature, hence defeating simple techniques for checking exact duplicates (e.g.
hashing). However, their method is limited in the features used, achieving an
accuracy below 85%. In this work, we explore visual image features, while
using a simple and novel mechanism of dealing with various obfuscation
techniques. Table 2 lists obfuscation techniques that the survey in
[16] has identified.
|
Early methods for I-spam exploited the heavy use of text in I-spam, a feature that is still present. However, spammers hit back by exploiting the deficiencies of Optical Character Recognition and modifying I-spam accordingly. Shortcomings of OCR have been aptly demonstrated in the design of CAPTCHAs1 which remain an effective mechanism of telling humans and computer agents apart. To demonstrate the ineffectiveness of OCR for (current) I-spam filtering, we have compared our algorithm with OCR.
While technology may not be advanced enough for recognizing spam from random images without any explicit instructions or rules, recent research in machine learning has lead to efficient and accurate pattern recognition algorithms. Our near duplicate detection algorithm is based on the intuition that we can recognize a lot of images similar to an identified spam image; since I-spam is usually generated from a template (see Sec. 2), near duplicates should be easy to detect. Given enough training data, we should be able to detect large volumes of I-spam, while being open to further training. We should additionally provide better generalization performance than pure similarity search and abstract from observer positive and negative samples.
Near-duplicate detection for images is an extreme form of similarity search [7] which is a well studied topic. Recent work in probabilistic image clustering has focused on similar issues but from a different perspective, where a query image is used to search for similar images in a large database. Probabilistic image modeling is particularly suited to the task at hand since we want to classify a family of images as spam, while having observed only a few samples from the family. We have chosen Gaussian Mixture Models (GMM) as the starting point for our approach.
Gaussian Mixture Models model an image as coherent regions in feature space.
First, features are extracted for each pixel, projecting the image to a
high-dimensional feature space. For each pixel, we extract a seven tuple
feature vector: two parameters for pixel coordinates ![]() (to
include spatial information), three for color
attributes in the color space and two for texture attributes
(anisotropy and contrast [3]). We chose the
(to
include spatial information), three for color
attributes in the color space and two for texture attributes
(anisotropy and contrast [3]). We chose the
![]() color space (henceforth called as Lab) since it models most closely
how humans perceive colors. The Lab color space is perceptually linear,
meaning that a change of the same amount in a color value produces a change of
about the same visual importance. For texture, anisotropy and contrast are
extracted from the second moment matrix defined as follows:
color space (henceforth called as Lab) since it models most closely
how humans perceive colors. The Lab color space is perceptually linear,
meaning that a change of the same amount in a color value produces a change of
about the same visual importance. For texture, anisotropy and contrast are
extracted from the second moment matrix defined as follows:
| (1) |
Given this transformation, we now represent an image as a set of ![]() -tuples:
-tuples:
| (2) |
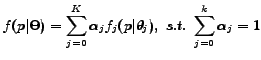 |
(3) |
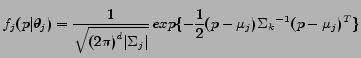 |
Additional constraints on the parameters of the above model include
![]() , and diagonal covariance
, and diagonal covariance ![]() ; this simplifies the model and avoids inversions of the covariance matrix. We are now
interested in finding the maximum likelihood estimate (MLE) of the model
parameters
; this simplifies the model and avoids inversions of the covariance matrix. We are now
interested in finding the maximum likelihood estimate (MLE) of the model
parameters ![]() , such that:
, such that:
| (4) |
E-step:
| (5) |
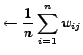 |
(6) | |
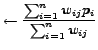 |
(7) | |
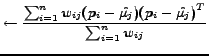 |
(8) |
The GMM framework allows us to learn probabilistic models of images, but a hidden assumption is that the images are similar in size. While this is not true for our data, it offers an opportunity as well: at lower resolutions, many obfuscation techniques are ineffective. Using this key assumption, we scale every image to a resolution of
![]() . The computational advantage of this method is obvious. This scale has
been selected empirically and strikes a balance between loss of information
and gain in performance. We explore the effect of scale when extracting visual
image features in Section 4.1.
. The computational advantage of this method is obvious. This scale has
been selected empirically and strikes a balance between loss of information
and gain in performance. We explore the effect of scale when extracting visual
image features in Section 4.1.
In order to ensure faster GMM fitting, we optimized model fitting procedure; the EM model was parameterized using ![]() -means clustering. For all
experiments, the number of mixtures was fixed at
-means clustering. For all
experiments, the number of mixtures was fixed at ![]() . A smaller value of
. A smaller value of
![]() would have resulted in omission of important components of an image, while
a larger value would have taken into consideration also the insignificant
portions of an image. After sufficient experimentation, the value of
would have resulted in omission of important components of an image, while
a larger value would have taken into consideration also the insignificant
portions of an image. After sufficient experimentation, the value of ![]() was
fixed at
was
fixed at ![]() to ensure that noise was filtered out of the model.
to ensure that noise was filtered out of the model.
After all the GMMs have been learnt (one for every image), we need to cluster similar images together. Clustering requires a similarity measure, and our task requires modeling distance between two probability distributions. A commonly used distance measure is Kullback-Leiber (KL) Divergence defined as follows:
| (9) |
In [8], the authors have described an agglomerative clustering
algorithm, where clusters are learnt from observed data in an unsupervised
fashion, i.e. the number of clusters is initially unknown. To aid in
clustering, the Information Bottleneck principle is used. The information bottleneck (IB) principle states that the loss of mutual information between the objects and the features extracted should be minimized by the desired clustering among all
possible clusterings. Using the IB principle, clustering of the
object space ![]() is done by preserving the relevant information about another
space
is done by preserving the relevant information about another
space ![]() . We assume, as part of the IB approach, that
. We assume, as part of the IB approach, that
![]() is a Markov chain, i.e. given
is a Markov chain, i.e. given ![]() the clustering
the clustering ![]() is
independent of the feature space
is
independent of the feature space ![]() . Consider the following distortion
function:
. Consider the following distortion
function:
| (11) |
Note that
![]() is a function of
is a function of
![]() . Hence,
. Hence,
![]() is not predetermined, but depends on the
clustering. Therefore, as we search for the best clustering, we also search for
the most suitable distance measure.
is not predetermined, but depends on the
clustering. Therefore, as we search for the best clustering, we also search for
the most suitable distance measure.
Since the number of clusters may not be known apriori, we use the agglomerative clustering. The Agglomerative Information Bottleneck (AIB) algorithm for clustering is a greedy algorithm based on a bottom-up merging procedure [13] which exploits the IB principle. The algorithm starts with the trivial clustering where each cluster consists of a single point. Since we want to minimize the overall information loss caused by the clustering, in every greedy step we merge the two classes such that the loss in the mutual information caused by merging them is minimized.
Note however, that we are still operating in the classification domain, i.e. the data available to us has a label (ham/spam). The original AIB approach does not consider data labels as input; therefore, we extend it here for handling label data. We can use label information to restrict the clustering to a similar data, thus speeding up the cluster formation by distance comparison with data of the same label. Since the base AIB algorithm is quadratic, this information can result in a speedup of up to 4 times (assuming labels are equally likely to be positive and negative). Further optimizations are possible to make the unsupervised clustering faster (e.g. merging more than two clusters in an iteration or merging below a threshold); this is a placeholder for replacement with better Labeled AIB algorithms. Our presented algorithm consists of the two phases GMM training and Labeled AIB clustering which are summarized in Algorithms 1 and 2.
New images, whose label have to be predicted, are fitted to a GMM, and compared to the labeled signatures already known from the trained cluster model. The closest cluster to a new image, is found using the JS divergence distance, and the label of the new image is the label of the cluster. As a result, images similar to the signatures corresponding to spam label will be marked as spam and images similar to ham labeled signatures will be marked as ham. An optimization of this algorithm is to introduce a new label called unidentified. Images that are not similar to any of the existing signatures (i.e. the JS divergence with the closest cluster is larger than a particular threshold) can be labeled as unidentified and may require user intervention to be labeled appropriately into either of ham or spam data sets. This way more accurate results are obtained while also ensuring that the training phase continues even in the testing phase.
Near-Duplication is likely to perform well in abstracting base templates, when given enough examples of various spam templates in use. However, the generalization ability of this method will be limited, since we are not exploiting global features of images; there are many likely giveaway features as previous work has shown. We feel however that the explored feature set does not identify a key aspect: i-spam is artificially generated. In this section, we explore visual features like texture, shape and color and learn classifiers using these selected features. Notice that we extract global features, i.e. each feature represents a property of the entire spam image.
Color models are used to classify colors and to qualify them according to such attributes as hue, saturation, chroma, lightness, or brightness. The Red-Blue-Green (RGB) model is the most basic and well-known color model. It is also the basic color model for on-screen display. Using this color model, we chose the following features

|
Image texture, defined as a function of the spatial variation in pixel intensities (gray values), is useful in a variety of applications and has been a subject of intense study by many researchers (cf. [15]). The intuition behind choosing texture features for classification is that natural images have a different quality of texture as compared to textures in computer generated images. We extract the following features from the images in our data set:
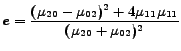 |
(13) |
Many approaches exist to train classifiers using extracted features; however, Support Vector Machines(SVM) [2] have been established as the best performing technique. In particular, the use of the kernel trick allows SVM to explore non-linear combinations of features by considering dot products in a high dimensional Hilbert space. The SVM classification is formalized as follows: We consider data points of the form:
where
![]() and denotes the class that
and denotes the class that
![]() belongs to (e.g. spam/ham).We can view this as training data, which
denotes the correct classification which we would like the SVM to
distinguish, by means of the dividing (or separating) hyperplane,
which takes the form
belongs to (e.g. spam/ham).We can view this as training data, which
denotes the correct classification which we would like the SVM to
distinguish, by means of the dividing (or separating) hyperplane,
which takes the form
Optical Character Recognition (OCR) was the first proposed solution to I-spam; there are various commercial and open source solutions (e.g. SpamAssasin's FuzzyOCR plug-in) using OCR libraries. We chose to use the well known Tesseract OCR suite developed by HP labs, recently open sourced by Google2. The OCR based algorithm we use is a simple one: we classify an image as spam if the OCR module can find more than 2 characters in the image. This has low accuracy of around 80%; increasing the threshold to 5 characters leads to accuracies below 65%.
![\includegraphics[width=3.1in,height=2.4in]{spam_accuracy_manish_50_100_2.eps}](fp707-mehta-img87.png) |
To evaluate our algorithms, we have chosen three recent public datasets; the first is due to [6] who collected over 13000 I-spam emails from the erstwhile SpamArchive3. The second was created by Dredze et al. [5] (who also used the SpamArchive dataset for evaluation) from their personal emails. This is called the Personal Spam dataset by the authors; they have also created a Personal Ham dataset from their personal emails, representing true ham emails. This is an important collection since most other researchers have used general images and photos from the web (examples of ham images are shown in Fig. 3.2.1). Both these datasets are now publicly distributed at http://www.seas.upenn.edu/~mdredze/datasets/image_spam/. The SpamArchive Collection consists of 13621 files, out of which only 10623 are in image format. The other files are unreadable by image processors; this is due to deliberate manipulation by spammers to use other alternatives of image for e-mail spam. The Personal spam collection consists of 3300 images. In addition, we have also used the Princeton Image Spam Benchmark4 which contains 1071 images with category information. The utility of this dataset is that each category contains permutations of the same base I-spam template (See Fig. 6).
![\includegraphics[width=3.0in,height=2.4in]{spam_accuracy_manish_new.eps}](fp707-mehta-img88.png) |
|
Baseline: For the sake of comparison, we use the same datasets used previously by other researchers. In particular, we use the approach for testing as used by Dredze et al. since their results are the best reported so far in comparison to other work. The above presented algorithms are compared in identical conditions as in the experiments in [5]. OCR results using Open Source Tesseract are also provided for comparison.
![\includegraphics[width=6.0in]{same_category_spam_images.eps}](fp707-mehta-img90.png)
![\includegraphics[width=6.0in]{gmm_images_2.eps}](fp707-mehta-img91.png)
|
We observe that visual features are highly indicative of spam images; our
method reports a prediction accuracy of over 95% in all cases. Even with
large sets of over ![]() emails with only 10% data used for training, the
prediction accuracy is higher than best numbers reported by
[5,6]. At a comparable fraction of training/test set as used
by Dredze et al., we achieved almost 98% accuracy, an improvement of over
6%. With the Personal spam dataset, we achieve comparable results as
[5].
emails with only 10% data used for training, the
prediction accuracy is higher than best numbers reported by
[5,6]. At a comparable fraction of training/test set as used
by Dredze et al., we achieved almost 98% accuracy, an improvement of over
6%. With the Personal spam dataset, we achieve comparable results as
[5].
We also investigated the impact of resolution on our approach; in particular
we are interested to know if lower resolutions can provide similar results at
a cheaper computationally cost. Fig. 3 shows the
results of this evaluation; we notice small losses at lower resolutions and
small gains at higher resolutions. At
![]() , the approach is near
perfect achieving more than 99.6%. Higher accuracies will be practically
impossible due to human errors in labeling data.
, the approach is near
perfect achieving more than 99.6%. Higher accuracies will be practically
impossible due to human errors in labeling data.
It is important to point out that our results are nearly completely comparable with the previous papers; all researchers have used their own ham datasets, including us. The choice of ham can have a big impact on the outcome of prediction. However, the important issue is labeling spam correctly over a large heterogeneous spam set. We are currently procuring more spam by creating honeypots with an aim of collecting over 100,000 spam emails. We are also working on the creation of a SpamAssassin5 Plug-in using our framework.
Results from GMM based AIB The Labeled AIB approach is unlikely to reach the same generalization performance; the approach is designed to identify permutations of a base template. Since positive images do not necessary follow this pattern and are potentially infinite, Labeled AIB is expected to be clueless about images previously unseen. Early experiments in settings as above lead to weak results. However, the idea is still powerful; collaborative approaches to spam filtering like Spamato [1] encourage users to share manually-classified email spam, which can be used to train the spam filters of other users in the community. Our approach fits very well into this framework, since AIB based on GMMs can identify the base template. This makes our approach also well suited to server deployment as an identified pattern can be protected against for a large user population before spam reaches individual inboxes. The goal is to detect a new pattern in a manner similar to viruses and make the pattern available to all subscribed email servers. Further investigation of this idea is in progress.
To explore how effective the GMM approach is in identifying patterns pre-classified as spam, we find the Princeton dataset very helpful. This dataset has various categories of I-spam images clustered according to the base template; descriptions of different strategies used by spammers are also provided. Fig. 6 demonstrates that two spam images produced by the same template are indeed modeled very similarly to each other. Notice how well our chosen features can model the low resolution thumbnails with a simple parametric model. This provides the perfect opportunity to raise the question: Can AIB Clustering based on GMM identify the clusters correctly and demonstrate that it recognizes the base templates? We performed a run with our algorithm to test this hypothesis.
The Princeton dataset contains images in 178 categories, however this categorization is very strict. Many of these clusters can be merged and manual clustering resulted in fewer than 150 clusters. Our approach found 140 clusters; clearly some misclassification was also found. However, the performance is better than indicated by the numbers; clusters that were wrongly merged were classified as wrong, though they are similar when manually observed. When constrained to find exactly 178 clusters, the misclassification rate falls to below 16%. This indicates that the predictive performance for spam detection should still be high. Fig. 5 proves this empirically. GMM based Labeled AIB has high accuracy when predicting spam in comparable conditions. OCR does much worse, while the trained SVM has a marginally better performance.
In this paper, we have presented two novel approaches to fight the menace of image-based email spam by exploiting visual features and the template-based nature of I-spam. Experimental results heavily support our hypothesis that low-level feature analysis can provide a more accurate detection mechanism than previously known. Our work complements earlier work, and it should be very easy to incorporate visual features extracted by us into the framework of [5]. The gain is likely to be better accuracy, with a much improved running time by using the JIT feature extraction suggested by them. Since research in I-spam is recent, with less than one year since the emergence of the problem, more work is likely to happen in the future. In particular, spammers will notice the anti-spam measures taken and innovate to produce new attacks. The emergence of PDF based spam is one such innovation from spammers; clearly, spammers try to exploit all popular document formats to get their messages through. Till more principled shifts in email (e.g. postage for email c.a. [11]) or improvements in the underlying protocols happen, anti-spam research will remain a firefighting operation.
![\begin{algorithm}
% latex2html id marker 248
[h]
\caption{TrainGMM $(I_i, {i=\{...
...E $\Theta=(\mu_j$, $\alpha_j$, $\Sigma_j)$\
\end{algorithmic}
\end{algorithm}](fp707-mehta-img61.png)
![\begin{algorithm}
% latex2html id marker 261
[h]
\caption{LabeledAIB $(\theta_i...
..._l$, $l \leftarrow \text{No. Of Clusters}$\
\end{algorithmic}
\end{algorithm}](fp707-mehta-img62.png)
![\begin{algorithm}
% latex2html id marker 372
[h]
\caption{SVM-classify $(I_i, L...
...e*{0.1cm}
\ENSURE Classifier $\mathrm{C}$\
\end{algorithmic}
\end{algorithm}](fp707-mehta-img86.png)
![\includegraphics[width=3.0in,height=2.4in]{spam_accuracy_princeton.eps}](fp707-mehta-img89.png)