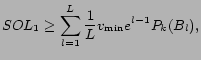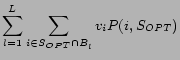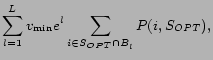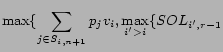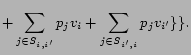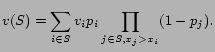The problem of mechanism design with externalities can be motivated in multiple settings in the context of online advertising, for instance, in the setting of sponsored search (e.g., Google's Adwords or Yahoo!'s Search Marketing) or ad placement on content pages (e.g., Google's Adsense or Yahoo!'s Content Match). In this paper we focus on a setting commonly known as online lead generation, or the pay-per-lead model [11]. The objective of online lead generation is to sell credible leads (in the form of personal information of a potential customer) to companies, or advertisers, interested in such leads. The advertisers then contact the potential customer directly to offer quotes and information about their service. This model of advertising is currently most popular among financial firms that offer mortgages, insurance companies, auto dealers interested in potential buyers of new cars, and the distance education industry1. According to the PricewaterhouseCoopers' IAB Revenue Report for year 2006 [12], lead generation revenues accounted for 8 percent of the 2006 full year revenues or $1.3 billion, up from the 6 percent or $753 million reported in 2005. In addition to having been the initial motivation of the present work, focusing on the lead generation model has the advantage that it simplifies the discussion of externalities by abstracting away aspects of the problem relating to the specific placement of the ads on a page. We will briefly discuss such issues and their interplay with the externality problem at the end of this paper.
The main problem faced by a lead generation company that has acquired a lead is the following tradeoff: if the lead is sent to fewer advertisers, the value to each advertiser will be higher since they are competing with fewer other advertisers for the potential customer. Further, the value to an advertiser might also depend specifically on which other advertisers obtain the lead, not just how many others: a competing advertiser who provides a similar service and is very likely to offer a better deal to the user decreases the value of the lead much more than a less competitive advertiser, or an advertiser who is offering a different service (e.g., a Toyota dealer might decrease the value to a Honda dealer more than a Ford dealer does). In any case, the utility to an advertiser who buys a lead depends on other buyers of the same lead. In addition, typically a lead can only be sold to a limited number of advertisers, as specified in the privacy policy of the website [11].
In the most general and abstract form, the problem we are
interested in is the following: there are ![]() bidders, each with a utility function
bidders, each with a utility function
![]() , where
, where
![]() is the utility that bidder
is the utility that bidder
![]() derives when the set of winners
is
derives when the set of winners
is
![]() . It is
reasonable to assume that
. It is
reasonable to assume that ![]() is
zero if
is
zero if
![]() . The problem is to
design an incentive compatible mechanism to maximize welfare.
Such a mechanism would select the subset of bidders that
maximizes
. The problem is to
design an incentive compatible mechanism to maximize welfare.
Such a mechanism would select the subset of bidders that
maximizes
Since specifying a utility function of the form above takes exponential space in the number of bidders, we are interested in investigating models for utility functions that are both realistic in the context of online advertising, and also allow compact representation. We build such a model by looking at the choice problem from the advertising audience's perspective. Our model assumes that customers have (possibly interdependent) valuations for different advertisers (these valuations might be a function of the quote the customer receives from the advertisers in a lead generation business, or the perception of the quality of the product offered by the advertiser) and also for an outside option. When presented with a number of choices, they pick the advertiser whom they have the highest valuation for, or no advertiser if their valuation of the outside option is greater than the valuations of all advertisers presented in the set. This model is defined in more detail in the next section. We will study the computational complexity of the winner determination problem in this model, and prove that in the most general case, if the distributions of the values are given explicitly, the winner determination problem is hard to approximate within a constant factor. On the other hand, we will give an approximation algorithm that solves this problem within a factor that is logarithmic in the ratio of the maximum to the minimum bid. Furthermore, in several special cases, most notably in the case that distributions are single-peaked, the winner determination problem can be solved exactly in polynomial time. We will prove that these algorithms, combined with a VCG-style payment scheme, give rise to dominant-strategy incentive compatible mechanisms.
Finally, we discuss alternative models for externalities, and directions for future work.
Related work. Auctions with externalities have been
studied in the economics literature, the earliest related work
being that of Jehiel, Moldovanu and Stacchetti [7], where a loser's value depends on the
identity of the winner. The problem of mechanism design with
allocative externalities is also studied by Jehiel and Moldovanu
[5], and Jehiel, Moldovanu and
Stacchetti [8]; [6] studies mechanism design with both
allocative and informational externalities. However, none of
these papers address computational issues arising from the
mechanism design problem.
To the best of our knowledge, this is the first theoretical work that specifically addresses the problem of externalities in online advertising. Limited experimental evidence for the hypothesis that the click-through rate of ads depend on surrounding ads is provided in the work of Joachims et al. [9].
More formally, suppose there are ![]() advertisers numbered
advertisers numbered
![]() , each with a private
value
, each with a private
value ![]() (which is the value
advertiser
(which is the value
advertiser ![]() derives when he is chosen
by a user). The quality of advertiser
derives when he is chosen
by a user). The quality of advertiser ![]() (from the perspective of the user) is denoted by
(from the perspective of the user) is denoted by ![]() . Furthermore, let
. Furthermore, let ![]() denote the quality of the best outside
option. These quality parameters
denote the quality of the best outside
option. These quality parameters ![]() are random variables, drawn from a joint probability
distribution
are random variables, drawn from a joint probability
distribution ![]() . Intuitively,
considering
. Intuitively,
considering ![]() 's as random variables
(as opposed to deterministic values) captures the fact that users
do not all make the same choices among the advertisers. Also, in
general the
's as random variables
(as opposed to deterministic values) captures the fact that users
do not all make the same choices among the advertisers. Also, in
general the ![]() 's need not be
independent, since the choices of users are often dictated by the
same general principles. For example, knowing that a user
perceives Ford autos as superior to Toyotas increases the
likelihood that she also prefers Chevy to Honda.
's need not be
independent, since the choices of users are often dictated by the
same general principles. For example, knowing that a user
perceives Ford autos as superior to Toyotas increases the
likelihood that she also prefers Chevy to Honda.
When a set ![]() of advertisers is
chosen, the user picks the advertiser with the largest quality
of advertisers is
chosen, the user picks the advertiser with the largest quality
![]() in
in ![]() , if the quality of this advertiser is greater than that
of the outside option. This advertiser then derives a value of
, if the quality of this advertiser is greater than that
of the outside option. This advertiser then derives a value of
![]() ; all other advertisers
derive a value of 0. So the expected value when a set
; all other advertisers
derive a value of 0. So the expected value when a set ![]() of advertisers is chosen is
of advertisers is chosen is
The winner determination problem in this model is to choose a
set ![]() of at most a given number
of at most a given number
![]() of advertisers to maximize
of advertisers to maximize
![]() . Note that
. Note that ![]() is not monotone in
is not monotone in ![]() : adding an advertiser with low value but high
quality can actually cause a net decrease in the value of the
set. The winner determination problem can be written as the
following mathematical program:
: adding an advertiser with low value but high
quality can actually cause a net decrease in the value of the
set. The winner determination problem can be written as the
following mathematical program:
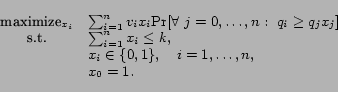 |
(1) |
Before we can start talking about the computational complexity
of the winner determination problem, we need to specify how the
input is represented. In particular, there are many ways the
distribution ![]() can be
represented. In this paper, we mainly consider an explicit
representation of
can be
represented. In this paper, we mainly consider an explicit
representation of ![]() , i.e.,
when the distribution has a finite support and all elements of
the support of this distribution are listed as part of the input
(as explained below). This is perhaps the simplest way to
represent the distribution, and our hardness result in the next
section (showing that the winner determination problem is hard to
approximate for this representation) clearly carries over to
stronger representations, such as models where
, i.e.,
when the distribution has a finite support and all elements of
the support of this distribution are listed as part of the input
(as explained below). This is perhaps the simplest way to
represent the distribution, and our hardness result in the next
section (showing that the winner determination problem is hard to
approximate for this representation) clearly carries over to
stronger representations, such as models where ![]() is given by an oracle.
is given by an oracle.
Observe that in our model, the actual values of the quality
parameters ![]() do not matter; all that
matters is the relative ordering of the qualities. Specifically,
the only real information we use from the distribution is the
probability of each ranking of the bidders' qualities and the
quality of the outside option. In other words, we can assume that
there are a finite number of different user types, and each user
type
do not matter; all that
matters is the relative ordering of the qualities. Specifically,
the only real information we use from the distribution is the
probability of each ranking of the bidders' qualities and the
quality of the outside option. In other words, we can assume that
there are a finite number of different user types, and each user
type ![]() is given by a real number
which indicates the probability that a random user is of type
is given by a real number
which indicates the probability that a random user is of type
![]() , and a permutation of the
, and a permutation of the
![]() options
options
![]() (with 0
representing the outside option and
(with 0
representing the outside option and
![]() representing the
advertisers). Note that the ordering of advertisers that occur
after the outside option in a permutation is irrelevant, and
therefore can be omitted. To summarize, the externality problem
with an explicitly given distribution can be formulated as
follows.
representing the
advertisers). Note that the ordering of advertisers that occur
after the outside option in a permutation is irrelevant, and
therefore can be omitted. To summarize, the externality problem
with an explicitly given distribution can be formulated as
follows.
|
WINNER DETERMINATION
PROBLEM WITH
EXTERNALITIES: INPUT:
|

In the next section, we will show a strong hardness result for
the above problem. In Section 4 we will
give an approximation algorithm, and in Section 5 we prove that the problem is solvable
in polynomial time if preferences ![]() are single-peaked, and also in another special case
of the problem with implicitly given distributions.
are single-peaked, and also in another special case
of the problem with implicitly given distributions.
The permutation ![]() corresponding to user type
corresponding to user type ![]() is
constructed as follows. Let
is
constructed as follows. Let
![]() and
and
![]() denote the set of
neighbors of
denote the set of
neighbors of ![]() in
in ![]() that have an index less than
that have an index less than ![]() . The permutation
. The permutation ![]() ranks the elements of
ranks the elements of ![]() in an arbitrary order at the top, followed by
in an arbitrary order at the top, followed by
![]() , followed by the outside
option 0 (recall that the ordering of elements after the
outside option is not important). This completes the definition
of the instance of the winner determination problem.
, followed by the outside
option 0 (recall that the ordering of elements after the
outside option is not important). This completes the definition
of the instance of the winner determination problem.
Now, we show that if the size of the maximum independent set
in the graph ![]() is
is ![]() , then the value of the solution of the above
instance of the winner determination problem is between
, then the value of the solution of the above
instance of the winner determination problem is between
![]() and
and
![]() .
.
Let ![]() denote the maximum
independent set of
denote the maximum
independent set of ![]() (
(![]() ). First, we
prove that the value of the solution to the winner
determination problem is at least
). First, we
prove that the value of the solution to the winner
determination problem is at least ![]() . To show this, it is enough to take
. To show this, it is enough to take ![]() . Since
. Since ![]() is
an independent set, for every
is
an independent set, for every ![]() , the first element of
, the first element of ![]() that is in
that is in ![]() is
is
![]() . Therefore, for every such
. Therefore, for every such
![]() , users of type
, users of type ![]() contribute a total value of
contribute a total value of
![]() to the
objective function. Hence, the value of the set
to the
objective function. Hence, the value of the set ![]() is precisely
is precisely ![]() .
.
Next, we prove that no set ![]() in the instance of the winner determination problem
has value more than
in the instance of the winner determination problem
has value more than
![]() . To show this,
take the optimal set
. To show this,
take the optimal set ![]() in the winner
determination problem, and define an independent set
in the winner
determination problem, and define an independent set
![]() in the graph as follows:
start with
in the graph as follows:
start with
![]() , and process
vertices of
, and process
vertices of ![]() in increasing order
of their index. For every vertex
in increasing order
of their index. For every vertex ![]() , if no neighbor of
, if no neighbor of ![]() is added to
is added to ![]() so far, add
so far, add
![]() to
to ![]() . Clearly, at the end of this procedure, we obtain an
independent set
. Clearly, at the end of this procedure, we obtain an
independent set ![]() of
of
![]() . We show that the value of
the set
. We show that the value of
the set ![]() is at most
is at most
![]() . To
see this, note that for every element
. To
see this, note that for every element ![]() that is in
that is in ![]() but not in
but not in
![]() , the vertex
, the vertex ![]() must have a neighbor
must have a neighbor ![]() with
with ![]() .
Consider such a
.
Consider such a ![]() with the
smallest index. By definition,
with the
smallest index. By definition, ![]() appears before
appears before ![]() in
in
![]() . Therefore, the
contribution of each such user type
. Therefore, the
contribution of each such user type ![]() to
to ![]() is at most
is at most
![]() . For every
. For every
![]() , the contribution of
, the contribution of
![]() to
to ![]() is at most
is at most ![]() . Summing up these contributions, we obtain
. Summing up these contributions, we obtain
![]() . Since
. Since ![]() is an independent set, we
get
is an independent set, we
get
![]() .
.
Therefore, if we take ![]() , the value of the solution of the winner
determination problem divided by
, the value of the solution of the winner
determination problem divided by ![]() is within
is within
![]() of the size the
maximum independent set of
of the size the
maximum independent set of ![]() .
Thus, by the hardness of the independent set problem [14], the winner determination
problem cannot be approximated within a factor of
.
Thus, by the hardness of the independent set problem [14], the winner determination
problem cannot be approximated within a factor of
![]() for any
for any
![]() , unless
, unless
![]() .
.
![]()
The above theorem rules out the possibility of finding an
algorithm for the winner determination problem with any
approximation factor that is a reasonable function of ![]() . However, note that the
instances constructed in the above hardness result contain
advertisers whose values differ by a large factor (
. However, note that the
instances constructed in the above hardness result contain
advertisers whose values differ by a large factor (![]() ). This raises the
question of whether one can approximate the winner determination
problem within a factor that depends on the spread between the
largest and the smallest values. The answer to this question is
indeed positive, as we will see in the next section.
). This raises the
question of whether one can approximate the winner determination
problem within a factor that depends on the spread between the
largest and the smallest values. The answer to this question is
indeed positive, as we will see in the next section.
We begin with the following lemma, which shows that the problem can be solved approximately when all values are close to each other.
The greedy approximation algorithm for the maximum
![]() -coverage problem can be
easily generalized to solve the weighted version: the algorithm
proceeds in iterations, in each iteration picking an advertiser
that covers a set of previously uncovered user types of maximum
total weight. It is not hard to see that this algorithm
achieves an approximation factor of
-coverage problem can be
easily generalized to solve the weighted version: the algorithm
proceeds in iterations, in each iteration picking an advertiser
that covers a set of previously uncovered user types of maximum
total weight. It is not hard to see that this algorithm
achieves an approximation factor of ![]() for the weighted maximum
for the weighted maximum ![]() -coverage problem [15]. The winner determination
problem can be approximated to within the same factor when all
values are equal. If advertisers have unequal values, we can
obtain a factor
-coverage problem [15]. The winner determination
problem can be approximated to within the same factor when all
values are equal. If advertisers have unequal values, we can
obtain a factor
![]() by simply
ignoring the values and solving the weighted max-coverage
problem.
by simply
ignoring the values and solving the weighted max-coverage
problem. ![]()
We will now build on this observation to obtain a randomized
algorithm with a ratio that is logarithmic in ![]() . Then we will show how this algorithm can be turned
into a monotone algorithm (a property that is needed in order to
achieve incentive compatibility), and how it can be
derandomized.
. Then we will show how this algorithm can be turned
into a monotone algorithm (a property that is needed in order to
achieve incentive compatibility), and how it can be
derandomized.
For a given subset
![]() ,
denote by
,
denote by ![]() the value of the
optimal solution to the weighted max-
the value of the
optimal solution to the weighted max-![]() -coverage problem restricted to the subset of
advertisers
-coverage problem restricted to the subset of
advertisers ![]() ,
, ![]() the value of the solution returned by the greedy
algorithm to the weighted max
the value of the solution returned by the greedy
algorithm to the weighted max ![]() -coverage problem, and denote by
-coverage problem, and denote by ![]() the subset of advertisers from
the subset of advertisers from ![]() chosen by the greedy algorithm.
chosen by the greedy algorithm.
Assume ![]() is a known lower
bound, and
is a known lower
bound, and ![]() is a known upper
bound on the value of an advertiser. We will show later that our
derandomized algorithm works even if we do not know the values of
is a known upper
bound on the value of an advertiser. We will show later that our
derandomized algorithm works even if we do not know the values of
![]() and
and ![]() . Divide advertisers into buckets
. Divide advertisers into buckets ![]() through
through ![]() , where
, where
![]() and bucket
and bucket
![]() consists of advertisers with
values
consists of advertisers with
values
![]() .
.
Algorithm ![]() :
:
The welfare from the optimal set of advertisers for the winner
determination problem ![]() is
is
Since ![]() is the solution
returned by the greedy algorithm for the maximum
is the solution
returned by the greedy algorithm for the maximum ![]() -coverage problem restricted to advertisers in
-coverage problem restricted to advertisers in
![]() , and
, and
![]() is a solution
for this problem of value at least
is a solution
for this problem of value at least
![]() , we have
, we have
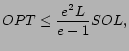
It is a well-known theorem (see, for example, Archer and
Tardos [1]) that in a setting with
one-dimensional types, in order to design an incentive compatible
mechanism, one needs an allocation algorithm that is
monotone: the probability of winning should not decrease
if an advertiser's value increases. The above algorithm does not
have this property: for example, if advertiser ![]() is the only advertiser in an interval
is the only advertiser in an interval ![]() , she wins with probability
, she wins with probability
![]() independent of her position
in the permutations, whereas she may not be chosen as a winner in
her new bucket if her value increases.
independent of her position
in the permutations, whereas she may not be chosen as a winner in
her new bucket if her value increases.
The following modification ensures that the allocation algorithm is monotone.
Define the (overlapping) buckets
Algorithm ![]() :
:
Finally, we show that our algorithm can be derandomized while
maintaining the monotonicity property. The idea of
derandomization is easy: instead of picking a random bucket,
check all buckets and pick one that gives the highest value.
However, one needs to be careful as this transformation can
sometimes turn a monotone algorithm into a non-monotone one. In
our case, we can use properties of the greedy maximum ![]() -coverage algorithm to prove
that the algorithm remains monotone.
-coverage algorithm to prove
that the algorithm remains monotone.
In addition to decreasing uncertainty, one advantage of the
derandomized algorithm is that it can be implemented without
knowledge of the values of ![]() or even
or even ![]() .2 In order to do this,
for every integer
.2 In order to do this,
for every integer ![]() , we define the
bucket
, we define the
bucket
![]() as the set of
advertisers of value at least
as the set of
advertisers of value at least ![]() (
(
![]() ). By the definition of
). By the definition of
![]() , there are at most
, there are at most
![]() non-empty
distinct buckets. We can now define the deterministic algorithm
as follows:
non-empty
distinct buckets. We can now define the deterministic algorithm
as follows:
Algorithm ![]() :
:
Note that
![]() is
unchanged for all
is
unchanged for all ![]() ,
since
,
since
![]() is unchanged
for these sets, and the values of bidders in
is unchanged
for these sets, and the values of bidders in
![]() do not
affect the value of
do not
affect the value of
![]() , or the
set of bidders corresponding to
, or the
set of bidders corresponding to
![]() . For the
sets
. For the
sets
![]() with
with
![]() , the only
addition is the bidder
, the only
addition is the bidder ![]() .
Since the algorithm used to compute
.
Since the algorithm used to compute
![]() is the
deterministic greedy algorithm for weighted max-
is the
deterministic greedy algorithm for weighted max-![]() coverage [15],
coverage [15],
![]() changes
only if the algorithm chooses
changes
only if the algorithm chooses ![]() in the winning set. Thus if
in the winning set. Thus if
![]() ,
,
![]() is chosen as a winner in
is chosen as a winner in
![]() . Therefore,
the allocation algorithm is monotone.
. Therefore,
the allocation algorithm is monotone. ![]()
The above theorem, together with the theorem of Archer and
Tardos [1] implies that there is a
dominant-strategy incentive-compatible mechanism for ad auctions
with externalities that can approximate the social welfare to
within a factor of
![]() of the
optimum.
of the
optimum.
We start by defining the notion of single-peaked preferences
in the context of the externality problem. Recall that the
preference of each user type ![]() is
given as a permutation
is
given as a permutation ![]() of
of
![]() , where 0 is
the outside option and
, where 0 is
the outside option and
![]() represent
advertisers. We say that the user preferences are single-peaked
(with respect to the ordering
represent
advertisers. We say that the user preferences are single-peaked
(with respect to the ordering
![]() of the advertisers),
if for every user type
of the advertisers),
if for every user type ![]() , there is a
value
, there is a
value
![]() , such that
for every
, such that
for every
![]() , advertiser
, advertiser
![]() is preferred to advertiser
is preferred to advertiser
![]() according to
according to ![]() , and for every
, and for every
![]() , advertiser
, advertiser
![]() is preferred to advertiser
is preferred to advertiser
![]() according to
according to ![]() . In other words, each user type
. In other words, each user type ![]() has an ideal advertiser
has an ideal advertiser ![]() , and advertisers before
, and advertisers before ![]() are ranked according to their distance to
are ranked according to their distance to ![]() , and similarly for
advertisers after
, and similarly for
advertisers after ![]() . No
restriction is placed on how
. No
restriction is placed on how ![]() ranks
two advertisers, one before
ranks
two advertisers, one before ![]() and
the other after
and
the other after ![]() , or how she
ranks any advertiser in comparison to the outside option.
, or how she
ranks any advertiser in comparison to the outside option.
The following theorem gives an algorithm for the winner
determination problem with externalities, when preferences are
single-peaked, with respect to a known ordering
![]() .
.
Consider an instance of the winner determination problem with externalities where the set of user types is restricted to(note that we do not change the probabilities
's, so in this restriction the probabilities can add up to less than 1. However, the problem is still well-defined in this case). Let
be the maximum value
of a set
satisfying the following:
,
, and
.
We show how ![]() can be
computed recursively. The idea is to focus on the first
advertiser after
can be
computed recursively. The idea is to focus on the first
advertiser after ![]() that will be
included in the set
that will be
included in the set ![]() . If
. If ![]() is the index of this
advertiser, the value derived from user types
is the index of this
advertiser, the value derived from user types ![]() with
with ![]() can be
written as
can be
written as
![]() , since by the
single-peaked property of the preferences, none of these users
prefers any advertiser before
, since by the
single-peaked property of the preferences, none of these users
prefers any advertiser before ![]() to
to
![]() . Users
. Users ![]() with
with
![]() will choose one
of the advertisers
will choose one
of the advertisers ![]() and
and ![]() or the outside option
(again, by the single-peaked property). Therefore, the total
value of the solution in this case can be written as
or the outside option
(again, by the single-peaked property). Therefore, the total
value of the solution in this case can be written as
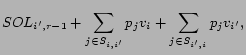
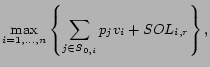
An interpretation of this model is that there is an underlying
true quality rating amongst all advertisers (as given by the
ordering of the ![]() 's), and a
user who is informed about two advertisers
's), and a
user who is informed about two advertisers ![]() and
and ![]() ranks them in this
order. However, with probability
ranks them in this
order. However, with probability ![]() , the user has not heard of advertiser
, the user has not heard of advertiser ![]() , in which case she will not choose this advertiser.
In other words, users rank the advertisers according to
independent perturbations of the same ranking, under a particular
model of perturbation. As we will point out in Remark 2, the idea can be generalized to more general
``local'' perturbation models.
, in which case she will not choose this advertiser.
In other words, users rank the advertisers according to
independent perturbations of the same ranking, under a particular
model of perturbation. As we will point out in Remark 2, the idea can be generalized to more general
``local'' perturbation models.
The value of a set of advertisers ![]() in this model can be written as
in this model can be written as
Number advertisers in decreasing order of ![]() , so that
, so that
![]() . We consider the
following subproblem: Let
. We consider the
following subproblem: Let ![]() denote the optimal value when no more than
denote the optimal value when no more than
![]() advertisers can be selected
from the subset
advertisers can be selected
from the subset
![]() of advertisers. In
other words,
of advertisers. In
other words,
![]() .
.
Note that
![]() for
for
![]() is
is
![]() . Using
this, it is easy to prove the following recursion.
. Using
this, it is easy to prove the following recursion.
Pairwise multiplicative model. As before, there are
![]() advertisers with private values
advertisers with private values
![]() . The model is
defined in terms of parameters
. The model is
defined in terms of parameters
![]() for
for
![]() . The value of
. The value of
![]() represents the factor by
which advertiser
represents the factor by
which advertiser ![]() decreases the
value to advertiser
decreases the
value to advertiser ![]() , if both are
chosen together in the winning set. The value of a set
, if both are
chosen together in the winning set. The value of a set
![]() is
is
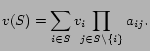
Uniform discount model. This model assumes that different
advertisers experience the same degree of discount, which depends
only on total weight of the set of winners. More precisely, we
assume each advertiser ![]() has a private
value
has a private
value ![]() and a weight
and a weight ![]() (the weight could correspond to the conversion
rate or another measure of the importance of the advertiser), and
we are given a non-increasing function
(the weight could correspond to the conversion
rate or another measure of the importance of the advertiser), and
we are given a non-increasing function
![]() , which
specifies the discount as a function of the total weight of the
advertisers in the set. The value of a set
, which
specifies the discount as a function of the total weight of the
advertisers in the set. The value of a set ![]() is given by
is given by
We believe that the externality problem is a major issue in the study of online advertising, and so far has not received enough attention from the research community. In the following, we list a few directions for future research.
Location-dependent externalities. The models studied in
this paper, motivated by the lead generation business, was
developed for a setting where the only decision made by the
winner determination algorithm is the set of advertisers who get
an advertising opportunity (by receiving a lead), without any
particular order. However, in the cases where the auction decides
which advertisements should be displayed on a page (which is the
more common case), the winner determination algorithm should not
only specify which ads are displayed, but also in which slot each
ad is displayed. Furthermore, in this setting the externalities
can be location dependent: for example, a sponsored search ad
displayed in the 10th slot might impose no externality on the ad
displayed on the top slot. Therefore, in order to be applicable
to this setting, our model for externalities has to be modified
to take the locations into account.
A simple way to incorporate the location component into our
model is as follows: assume the slots are numbered
![]() , from top to
bottom. We assume a random user only looks at the ads in the top
, from top to
bottom. We assume a random user only looks at the ads in the top
![]() slots, where
slots, where ![]() is a random variable with a given distribution. The
user then decides which of the ads she has looked at to click on,
according to one of our models.
is a random variable with a given distribution. The
user then decides which of the ads she has looked at to click on,
according to one of our models.
Clearly, our hardness result for the winner determination problem works for this more general model as well. It would be interesting to find interesting special cases of this problem that can be solved in polynomial time.
The long-term externality effect. In this paper, our focus
was on the immediate externality that advertisers impose on each
other, in terms of lowering the conversion rate or the
click-through rate of other advertisers in the same session.
There is also a long-term externality effect: if a user finds the
ads displayed on a website (e.g., sponsored search ads on Google)
helpful, he or she is more likely to click on ads in the future,
and conversely, if the ads are found to be not relevant, the user
will pay less attention to ads in the future. This externality
effect is well understood in the context of traditional
advertising, and is sometimes referred to as the rotten-apple
theory of advertising [4]. The implication of this effect
in the context of traditional advertising media is in the domain
of public policy: it is used to justify adopting regulations
against false advertising.
In the context of online advertising, however, there is much more a publisher can do to measure this type of externality and reward or punish advertisers based on whether they create positive or negative externality. Publishers such as Google or Yahoo often can track when a user revisits their website and clicks on an ad, and also whether an ad leads to a conversion or some action on the advertiser's site. Designing mechanisms to extract the relevant information from this wealth of data and use it to overcome the externality problem and maximize the efficiency of the system in the long run is an interesting research direction.
Learning externalities. Throughout this paper, we studied
the winner determination problem with externalities, assuming
that the parameters of the model - user preferences in our main
model - are known to the algorithm. Learning these parameters
given the history of choices made by the users, or designing
experiments in order to learn these parameters remains open.
Diversity problem. It is known that having diversity among
the set of web search results or among the set of products
displayed on an electronic store front is valuable. There has
been some effort on designing algorithms in these applications
that give some weight to the diversity of the solution set (see,
for example, [16]).
However, it is not clear what is the right way to incorporate the
diversity component in the objective. Note that in our model,
optimizing for the value of solution in presence of externalities
can automatically result in a diverse solution set. This is
because advertisers that are similar to each other impose greater
negative externality on each other (e.g., presumably an
advertiser who sells Apple computers imposes little externality
on one that sells the fruit). This suggests that our framework
might be a good starting point for defining a diversity
optimization problem that is based on economic principles.
Dating problem. As mentioned earlier, online dating
services can also be considered in the framework of lead
generation. Similar externalities exist in the online dating
industry: sending a woman ![]() on a
date with a man
on a
date with a man ![]() imposes a
negative externality on all other men, since it decreases their
chances with
imposes a
negative externality on all other men, since it decreases their
chances with ![]() . Currently, online
dating services take one of the two extremes of either allowing
unrestricted search (i.e., a subscriber has access to the
profiles of anyone who meets his or her criteria, and can contact
them, which is the model adapted by Yahoo! Personals or
match.com), or matching people one pair at a time (this is the
model adapted by
. Currently, online
dating services take one of the two extremes of either allowing
unrestricted search (i.e., a subscriber has access to the
profiles of anyone who meets his or her criteria, and can contact
them, which is the model adapted by Yahoo! Personals or
match.com), or matching people one pair at a time (this is the
model adapted by ![]() Harmony). Chen
et al. [2] initiated the study
of the
Harmony). Chen
et al. [2] initiated the study
of the ![]() Harmony model from a
stochastic optimization point of view. An interesting direction
for future research is to study this problem in a model with
externalities in order to strike the right balance between these
two extremes.
Harmony model from a
stochastic optimization point of view. An interesting direction
for future research is to study this problem in a model with
externalities in order to strike the right balance between these
two extremes.
http://www.iab.net/standards/lead_generation.asp.http://www.iab.net/resources/adrevenue/pdf/
IAB_PwC_2006_Final.pdf, May 2007.