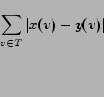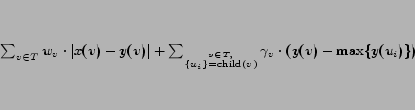 |
H.4.mInformation SystemsInformation Storage and Retrieval Algorithms, Experimentation Hierarchical Classification, Taxonomy, Regualrized Isotonic Regression, Dynamic Programming
Hierarchical taxonomies play a crucial role in the organization of knowledge in many domains. Taxonomies structured as hierarchies make it easier to navigate and access data as well as to maintain and enrich it. This is especially true in the context of a vast dynamic environment like the World Wide Web where the amount of available information is overwhelming; this has lead to a proliferation of human constructed topic directories [5,18] Because of their ubiquitousness there has been considerable interest in automated methods for classification into hierarchical taxonomies, and numerous techniques have been proposed [6,14,3,10]. In this paper, we will introduce ideas as well as algorithms that serve to further improve the accuracy of hierarchical classification systems.
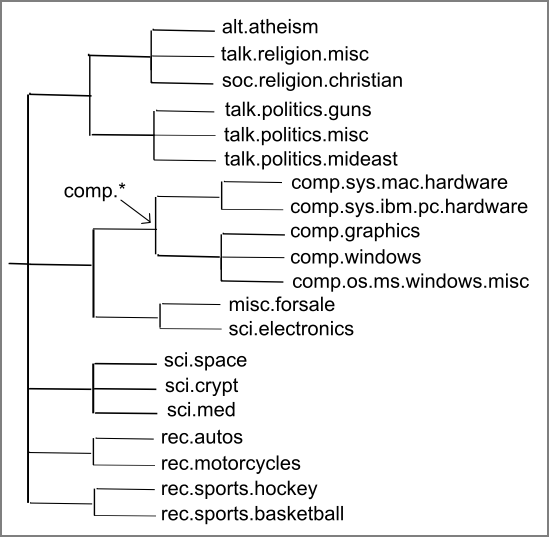
While studying systems that classify instances into a taxonomy of classes we have to consider many different aspects of the problem. Some of these result from variations in characteristics of taxonomies themselves, such as whether or not instances are allowed to belong to classes at the internal nodes, while others are because of variations in the way classifiers are trained. We illustrate some of these issues by considering a few real-world scenarios. We will refer to these scenarios throughout the paper to place the applicability of our approaches in context. A taxonomy constructed on the 20-newsgroups dataset (Figure 1) will be used as a running example below.
In addition to these two scenarios several other variations in the structure of the taxonomy and construction of classification problems can be imagined. A common aspect, however, is the mechanism for classifying new data instances into the taxonomy. For this purpose each learned classifier is applied to the new data instance to obtain membership scores. The membership scores outputted may be binary, or they can be thresholded to determine the classes that are labeled positive.
However, from our discussion of different classification scenarios we know that in many cases these membership scores are related across nodes. For example, in case of the 20-newsgroups dataset under Scenario I, it cannot be that the class comp.graphics is labeled positive and class comp.* is labeled negative for the same document. In other words, due to characteristics of taxonomies and specifics of classifier training, relationships between classes in a taxonomy lead to relationships between outputs of their classifiers. Furthermore, these properties can also be devised from knowledge of the application domain or the behavior of classification algorithms.
OUR CONTRIBUTION.
The central idea in this paper is that once we have identified the exact property that the outputs of classifiers in a taxonomy must satisfy, we can post-process the classification scores to enforce these constraints. Whenever classifier scores violate these constraints we will replace them with consistent scores that are as close as possible to the original ones. Since only a few classifiers are likely to make mistakes on any one instance it is hoped that the outputs of the incorrect ones will be modified appropriately.
In this paper, we will formulate the problem of enforcing constraints
on classifier outputs under Scenarios I and II as regularized
tree isotonic median regression problems. These are generalizations
of the classic isotonic regression problem. We will also provide a
dynamic programming based algorithm that finds the optimal solutions
to these more general optimization problems in ![]() time;
this is equal to the best known algorithms for the classic problem.
This new problem formulation and algorithm might be of interest
independent of the hierarchical classification task. We will present
empirical analysis on a real-world text dataset to show that
post-processing of classifier scores results in improved
classification accuracy.
time;
this is equal to the best known algorithms for the classic problem.
This new problem formulation and algorithm might be of interest
independent of the hierarchical classification task. We will present
empirical analysis on a real-world text dataset to show that
post-processing of classifier scores results in improved
classification accuracy.
NOTATION.
Let ![]() be a set of
be a set of ![]() classes in a taxonomy that have a one
to one mapping with the nodes of a rooted tree
classes in a taxonomy that have a one
to one mapping with the nodes of a rooted tree ![]() .
Let
.
Let
![]() and
and
![]() represent the set of leaves and the root
of the tree
represent the set of leaves and the root
of the tree ![]() respectively. Let
respectively. Let ![]() be a node of
be a node of ![]() (written as
(written as ![]() ) and let
) and let ![]() denote the subtree rooted at
denote the subtree rooted at ![]() . We will refer
to a node in the tree
. We will refer
to a node in the tree ![]() sometimes as a class.
We use
sometimes as a class.
We use
![]() to denote the parent of
to denote the parent of ![]() in
in ![]() ,
,
![]() to
denote the set of all immediate children of
to
denote the set of all immediate children of ![]() in
in ![]() .
Let
.
Let ![]() denote the set of all data instances. These instances
belong to one of the classes in
denote the set of all data instances. These instances
belong to one of the classes in ![]() ; this mapping is denoted by
function
; this mapping is denoted by
function ![]() . Depending on the real-world scenario being modeled,
. Depending on the real-world scenario being modeled,
![]() may map instances to only a subset of classes in
may map instances to only a subset of classes in ![]() .
.
Each class ![]() has associated with it a function
has associated with it a function
![]() , where
, where ![]() is the degree of membership of
instance
is the degree of membership of
instance ![]() in class
in class ![]() . In our application setting this value can
be interpreted as a posterior probability; using an appropriate
threshold it can be rounded to a boolean value. An instance
. In our application setting this value can
be interpreted as a posterior probability; using an appropriate
threshold it can be rounded to a boolean value. An instance ![]() can
be represented by a function
can
be represented by a function ![]() where the
where the ![]() represents the
value
represents the
value ![]() . Since each class corresponds to a unique node in the
taxonomy
. Since each class corresponds to a unique node in the
taxonomy ![]() , we can think of
, we can think of ![]() as being values assigned to nodes
of
as being values assigned to nodes
of ![]() . Henceforth we will use
. Henceforth we will use ![]() ,
, ![]() , and
, and ![]() as
metaphors for the taxonomy, a class or a node, and the classifier
score or node value respectively. In our application settings we
distinguish between an instance belonging to a class (implying
that
as
metaphors for the taxonomy, a class or a node, and the classifier
score or node value respectively. In our application settings we
distinguish between an instance belonging to a class (implying
that ![]() ) and associating with a class (implying that
because of the way classifiers were trained we expect
) and associating with a class (implying that
because of the way classifiers were trained we expect
![]() ). However, when it is clear from context, we will use the
term belonging to refer to both situations.
). However, when it is clear from context, we will use the
term belonging to refer to both situations.
However, as each classifier ![]() processes the instances
independently of other classifiers, they miss this intuitive
relationship amongst classifier outputs;
processes the instances
independently of other classifiers, they miss this intuitive
relationship amongst classifier outputs; ![]() need not satisfy
Property 2.1. Hence, we need
to transform
need not satisfy
Property 2.1. Hence, we need
to transform ![]() into smoothed classifier scores
into smoothed classifier scores ![]() such that elements in
such that elements in ![]() satisfy the monotonicity property.
satisfy the monotonicity property.
We have defined the monotonicity property for boolean classification
values, so we first consider a natural generalization in order to
handle real-valued classifier scores. Suppose ![]() are the
smoothed classifier scores, then they satisfy generalized strict
classification monotonicity property if for every internal node
are the
smoothed classifier scores, then they satisfy generalized strict
classification monotonicity property if for every internal node ![]() ,
with children
,
with children
![]() ,
,
![]() , i.e., the smoothed score of an
internal node is the equal to the maximum of its children's smoothed
scores. Note that generalized monotonicity ensures that whenever an
instance is associated with a class
, i.e., the smoothed score of an
internal node is the equal to the maximum of its children's smoothed
scores. Note that generalized monotonicity ensures that whenever an
instance is associated with a class ![]() , first, it's also associated
with
, first, it's also associated
with
![]() , and second, it's also associated with at least one
child of
, and second, it's also associated with at least one
child of ![]() , if any.
, if any.
Moreover, we assume that the individual classifiers have reasonable
accuracy and so we want to obtain ![]() that is as close as
possible to the original scores
that is as close as
possible to the original scores ![]() while satisfying the
monotonicity property. This gives us the following problem:
while satisfying the
monotonicity property. This gives us the following problem:
 |
Now consider Scenario II mentioned above. In this situation there
exist some instances that belong only to internal nodes, and not to
any of the leaf nodes. Moreover, the positive set of instances used
for training classifier ![]() for node
for node ![]() is the union of
instances that belong to all nodes in the subtree
is the union of
instances that belong to all nodes in the subtree ![]() . This implies
that the true labels for an instance will be a node
. This implies
that the true labels for an instance will be a node ![]() and all
its parents on the path to
and all
its parents on the path to
![]() . However, unlike Scenario I, its
no longer necessary for at least one child of
. However, unlike Scenario I, its
no longer necessary for at least one child of ![]() to also be included
in the true labels.
to also be included
in the true labels.
As is evident, this relationship between classifiers scores is not covered by Property 2.1, which enforces that every instance must belong to at least one leaf node. In order to incorporate situations such as Scenario II we state the relaxed monotonicity property.
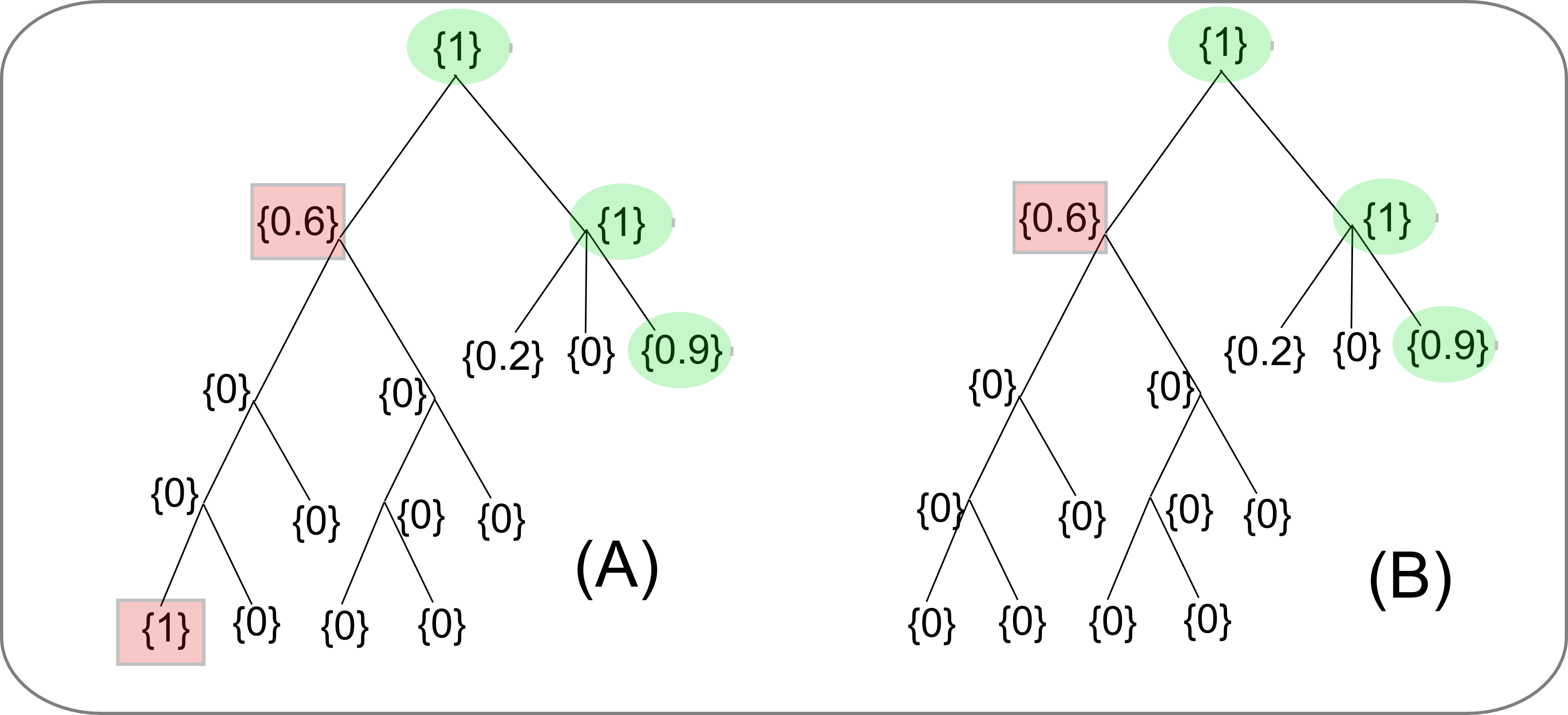
For instance, consider the classification scores on the tree A in Figure 2. The nodes that are shaded by a red square represent the errors in the classification. The leaf-node with score 1 clearly violates monotonicity constraints since its ancestors' scores are lower than its own. This error will be corrected since it is more expensive to increase all the ancestors' scores than it is to reduce the erroneous node's score.
However, the relaxed monotonicity property will allow certain other types of errors that might occur frequently. For example, consider the error node in tree B of Figure 2. This node doesn't violate the relaxed monotonicity property since its parent's score is higher than its own. However, this error node's score would have been corrected by the strict monotonicity property, which would have required at least one child of the error node to have the same score. It would have cost less (in terms of Equation (1)) to reduce 0.6 to 0, than to increase a whole series of values from 0 to 0.6.
In order to correct the latter type of errors we introduce an
additional regularization term in our objective function, which
penalizes violations of strict monotonicity. Hence, while we will
accept smoothed scores ![]() that satisfy the relaxed
monotonicity property as valid solutions, they will be charged for all
the violations of the strict monotonicity constraints. In the case of
the tree B in Figure 2, if the penalty is high enough, it
will cost lesser to reduce the error node's value to 0 than to leave
the scores as it is, thus correcting the false positive
error. Regularization can also be useful for reducing false negative
errors when it is cheaper to increase a child node value than to pay
the penalty.
that satisfy the relaxed
monotonicity property as valid solutions, they will be charged for all
the violations of the strict monotonicity constraints. In the case of
the tree B in Figure 2, if the penalty is high enough, it
will cost lesser to reduce the error node's value to 0 than to leave
the scores as it is, thus correcting the false positive
error. Regularization can also be useful for reducing false negative
errors when it is cheaper to increase a child node value than to pay
the penalty.
Taking into account this regularization we state a new problem:
Problem 2.4 is a regularized version of isotonic
regression problem on trees which has been widely
studied [1,13]. It reduces to
the standard isotonic regression when all the penalties are set to
0. Moreover, we can also enforce strict monotonicity
(Property 2.1) by setting
![]() .
.
 |
We first present an algorithm for the special case of penalty
![]() ; in fact, we'll solve
Problem 2.2. The dynamic programming based algorithm
presented in this section is similar in structure to the more general
algorithm presented in the next section, and serves as a good starting
point in introducing the ideas behind the approach.
; in fact, we'll solve
Problem 2.2. The dynamic programming based algorithm
presented in this section is similar in structure to the more general
algorithm presented in the next section, and serves as a good starting
point in introducing the ideas behind the approach.
Before we describe the algorithm we will discuss a crucial detail of
the structure of the problem. We show that the optimal smoothed
scores in ![]() can only come from the classifier scores
can only come from the classifier scores
![]() .
.
Consider the maximal connected subtree
This result shows that in the optimal solution the smoothed score for
each node will come from a finite set of values. Note that this result
also holds for the case of weighted ![]() distance. In this case each
weighted node in the tree can be considered as multiple nodes, which
number proportional to the weight, and which always have the same
score. In this case too, the minimizer remains the median of this
expanded graph. And hence the smoothed score values come from the
finite set of original values.
distance. In this case each
weighted node in the tree can be considered as multiple nodes, which
number proportional to the weight, and which always have the same
score. In this case too, the minimizer remains the median of this
expanded graph. And hence the smoothed score values come from the
finite set of original values.
To solve Problem 2.2 optimally we construct a dynamic
programming based method (pseudo-code in Figure 3).
The program consists of two main algorithms, (1) BUILDERRORSTRICT, which builds up the index function ![]() and error
function
and error
function ![]() , and (2) ISOTONESMOOTH, which uses the
, and (2) ISOTONESMOOTH, which uses the ![]() function to compute the optimal values for each node in the tree. Let
function to compute the optimal values for each node in the tree. Let
![]() be the set of unique values in
be the set of unique values in ![]() , and let
, and let ![]() be an
index into this set. Then index function
be an
index into this set. Then index function ![]() holds the index of
the value that node
holds the index of
the value that node ![]() should take in the optimal solution when its
parent takes the value
should take in the optimal solution when its
parent takes the value ![]() . In other words, when
. In other words, when
![]() then
then
![]() . In order to
compute the function
. In order to
compute the function ![]() , BUILDERRORSTRICT computes for each
node
, BUILDERRORSTRICT computes for each
node ![]() the function
the function
![]() , which holds the total cost of the
optimal smoothed scores in the subtree
, which holds the total cost of the
optimal smoothed scores in the subtree ![]() when
when
![]() .
.
Initially BUILDERRORSTRICT is invoked with
![]() as a
parameter. The function then recursively calls itself (step 6) on the
nodes of
as a
parameter. The function then recursively calls itself (step 6) on the
nodes of ![]() in a depth-first order. While processing a node
in a depth-first order. While processing a node ![]() , for
each possible value
, for
each possible value ![]() that
that ![]() can set itself to, BUILDERRORSTRICT finds the best values for its children that are less
than or equal to
can set itself to, BUILDERRORSTRICT finds the best values for its children that are less
than or equal to ![]() (step 10). All children of
(step 10). All children of ![]() are
assumed to be set to their best possible values (step 11) and their
costs (errors) are added up (step 12). Also, since in the final
solution one of the children's value has to be equal to value of
are
assumed to be set to their best possible values (step 11) and their
costs (errors) are added up (step 12). Also, since in the final
solution one of the children's value has to be equal to value of ![]() ,
BUILDERRORSTRICT maintains information about the child that
would cost the least (steps 13 & 14) to move to
,
BUILDERRORSTRICT maintains information about the child that
would cost the least (steps 13 & 14) to move to ![]() (step
16). At the end the cost of all children and the additional cost of
the ``minchild'' that is moved are added (step 17) to obtain the cost
for the current node.
(step
16). At the end the cost of all children and the additional cost of
the ``minchild'' that is moved are added (step 17) to obtain the cost
for the current node.
To demonstrate the correctness of this algorithm, we show that the restriction of the optimal solution to a subtree is also the optimal solution for the subtree under the monotonicity constraint imposed by its parent.
Consider the subtree rooted at any non-root node ![]() . Now
suppose the smoothed score
. Now
suppose the smoothed score
![]() is specified. Then, let
is specified. Then, let
![]() be the smoothed scores of the optimal solution to the
regularized tree isotonic regression problem for this subtree, under
the additional constraint that
be the smoothed scores of the optimal solution to the
regularized tree isotonic regression problem for this subtree, under
the additional constraint that
![]() . Note that
if
. Note that
if ![]() is chosen as ``minchild'' in algorithm BUILDERRORSTRICT
above, the constraint is
is chosen as ``minchild'' in algorithm BUILDERRORSTRICT
above, the constraint is
![]() .
.
Consider a smoothed solution
The algorithm computes up the optimal smoothed scores for each subtree, i.e., the
COMPLEXITY. Let ![]() , and so
, and so
![]() can
at most be
can
at most be ![]() . The dynamic programming table takes
. The dynamic programming table takes ![]() space per
node, and so the total space required is
space per
node, and so the total space required is ![]() . Next, we consider
the running time of the algorithm. In the algorithm BUILDERRORSTRICT-I, step 2 takes
. Next, we consider
the running time of the algorithm. In the algorithm BUILDERRORSTRICT-I, step 2 takes ![]() time, step 7 takes
time, step 7 takes ![]() time
amortized over all calls (this loop is called for each node only
once), and the loop in step 9 can be done in
time
amortized over all calls (this loop is called for each node only
once), and the loop in step 9 can be done in
![]() time by
storing
time by
storing
![]() values in a heap and then running over the values
values in a heap and then running over the values
![]() in descending order of
in descending order of
![]() . Hence, the total running time is
. Hence, the total running time is
![]() .
Note that this is same as the best time complexity of previously known
algorithms for the non-regularized forms of tree isotonic
regression [1].
.
Note that this is same as the best time complexity of previously known
algorithms for the non-regularized forms of tree isotonic
regression [1].
In the previous section we presented an algorithm to solve
Problem 2.2. In this section we give an algorithm
that solves the more general regularized isotonic regression problem
exactly.
The main difference between the two problems is that in the latter
case the hard constraint of a parent's value being equal to at least
one of its children's value
is enforced via soft penalties. These violations of the strict
monotonicity rule are charged for in the objective function, so that
if the cost of incurring the penalties is lower than the improvement
in ![]() error, the optimal solution will contain violations. This
makes the current problem much tougher to solve. When constraints were
strict each child only had two ways it could set its own value: equal
to the best possible value less than the parent's value or equal to
the parent's value. In the current problem because penalties are soft,
the child has more options of values it can set itself to. However, we
show that this set of possible values is still finite.
error, the optimal solution will contain violations. This
makes the current problem much tougher to solve. When constraints were
strict each child only had two ways it could set its own value: equal
to the best possible value less than the parent's value or equal to
the parent's value. In the current problem because penalties are soft,
the child has more options of values it can set itself to. However, we
show that this set of possible values is still finite.
Here we prove that the central result (Lemma 2.5) which facilitated the algorithm in Figure 3 also holds for the modified objective function Equation (2).
PRELIMINARY FACTS.
Consider the maximal connected subtree ![]() of nodes in
of nodes in ![]() such that
(1)
such that
(1) ![]() , and (2) for all
, and (2) for all ![]() ,
, ![]() . Let
. Let ![]() be the
median of the set of original scores
be the
median of the set of original scores
![]() . The cost incurred by
. The cost incurred by ![]() through the first term of
Equation (2) (
through the first term of
Equation (2) (![]() distance between
distance between ![]() and
and ![]() ) is
minimized when
) is
minimized when ![]() . As we raise or lower
. As we raise or lower ![]() the increase in
this cost is piecewise-linear, with the discontinuities at the values
in the set
the increase in
this cost is piecewise-linear, with the discontinuities at the values
in the set ![]() . In other words, in between any two adjacent
values in
. In other words, in between any two adjacent
values in ![]() the rate of change in the
the rate of change in the ![]() cost is constant
(we denote this rate by a function
cost is constant
(we denote this rate by a function ![]() ).
).
Now lets consider the cost due to penalties. Let ![]() be the
``maximal'' node in
be the
``maximal'' node in ![]() , such that
, such that
![]() . Note that, as
. Note that, as
![]() is connected and is a tree, there is a unique such node. Also,
let
is connected and is a tree, there is a unique such node. Also,
let ![]() be a set of nodes such that at least one child of
each
be a set of nodes such that at least one child of
each ![]() is not in
is not in ![]() . Some elements in the set
. Some elements in the set
![]() are involved in penalties for
having values different from
are involved in penalties for
having values different from ![]() . This cost from penalties also
changes in a piecewise-linear fashion with possible discontinuities at
the values in the set
. This cost from penalties also
changes in a piecewise-linear fashion with possible discontinuities at
the values in the set ![]() . Let us denote the rate of change of
penalty-based cost as
. Let us denote the rate of change of
penalty-based cost as ![]() .
.
Let the cost of the optimal solution
Consider the maximal connected subtree ![]() of nodes in
of nodes in ![]() such that
(1)
such that
(1) ![]() , (2) for all
, (2) for all ![]() ,
, ![]() , and
(3) there does not exist any
, and
(3) there does not exist any ![]() such that
such that
![]() . As mentioned above, since
. As mentioned above, since ![]() (median of
(median of
![]() ), we can decrease the cost due to
), we can decrease the cost due to
![]() error at the rate of
error at the rate of ![]() by moving
by moving ![]() towards
towards
![]() . Also, the cost due to penalties changes at the rate of
. Also, the cost due to penalties changes at the rate of
![]() when we move
when we move ![]() . If the values
. If the values
![]() then we can move
then we can move ![]() very slightly to decrease the
overall cost.
very slightly to decrease the
overall cost.
Hence, we consider the case where
![]() . Let
. Let
![]() be the closest value to
be the closest value to ![]() in between it and
in between it and ![]() .
Since the two rates of cost change counterbalance each other, small
changes in
.
Since the two rates of cost change counterbalance each other, small
changes in ![]() result in solutions with the exact same cost. In
fact, we can move
result in solutions with the exact same cost. In
fact, we can move ![]() to
to ![]() without any change in the overall
cost, hence producing an optimal solution with satisfies the lemma. To
see why this happens, consider that as we move
without any change in the overall
cost, hence producing an optimal solution with satisfies the lemma. To
see why this happens, consider that as we move ![]() to
to ![]() ,
,
![]() will not change as explained above. The quantity
will not change as explained above. The quantity
![]() will change if we encounter an element from the set
will change if we encounter an element from the set
![]() in between
in between ![]() and
and ![]() . But this means that we can
obtain a solution with cost
. But this means that we can
obtain a solution with cost ![]() that has fewer distinct values,
which violates our assumption. Another way in which
that has fewer distinct values,
which violates our assumption. Another way in which ![]() can
change is if the maximal node
can
change is if the maximal node ![]() stops/starts having the highest
value of all its siblings (stops/starts getting penalized) as we move
stops/starts having the highest
value of all its siblings (stops/starts getting penalized) as we move
![]() . However, it can be easily verified that this can only reduce
the cost of the new solution further.
. However, it can be easily verified that this can only reduce
the cost of the new solution further.
 |
Now we are ready to present the dynamic program to solve
Problem 2.4 (pseudo-code in
Figure 4). The input to the system is ![]() ,
the original classifier scores;
,
the original classifier scores; ![]() is the set of unique values
in
is the set of unique values
in ![]() . The algorithm BUILDERRORRELAX, invoked on the root
node, recurses over nodes of
. The algorithm BUILDERRORRELAX, invoked on the root
node, recurses over nodes of ![]() in a depth first order (step 6) and
fills up the index function
in a depth first order (step 6) and
fills up the index function ![]() and error function
and error function ![]() . The
index function
. The
index function
![]() holds the index of the value that node
holds the index of the value that node ![]() should take in the optimal solution when its parent takes the value
should take in the optimal solution when its parent takes the value
![]() , while the function
, while the function
![]() stores the total cost of
the optimal smoothed scores in the subtree rooted at
stores the total cost of
the optimal smoothed scores in the subtree rooted at ![]() when
when
![]() . In these respects, BUILDERRORRELAX is
identical to the algorithm for the strict monotonicity property
presented in Section 2.2. The
main difference is that now the cost of the solution doesn't just come
from the
. In these respects, BUILDERRORRELAX is
identical to the algorithm for the strict monotonicity property
presented in Section 2.2. The
main difference is that now the cost of the solution doesn't just come
from the ![]() error, but also from the penalties. Hence, while
picking a value for a child node we have to consider both the cost of
the optimal solution in the subtree of the child and the cost of the
child's value differing from the parent value. To add to the
complexity, we have to consider the latter cost only when the child
has the maximum value amongst its siblings.
error, but also from the penalties. Hence, while
picking a value for a child node we have to consider both the cost of
the optimal solution in the subtree of the child and the cost of the
child's value differing from the parent value. To add to the
complexity, we have to consider the latter cost only when the child
has the maximum value amongst its siblings.
While operating on a node ![]() , for each possible value
, for each possible value ![]() that
that ![]() can set itself to, BUILDERRORRELAX first obtains the
best value assignments for its children that are less than or equal to
can set itself to, BUILDERRORRELAX first obtains the
best value assignments for its children that are less than or equal to
![]() (step 10). At this stage, only the cost of the optimal
solutions in the subtree of a child is considered while determining
its best value (step 8); for now the cost, due to penalties, of a
child's value differing from
(step 10). At this stage, only the cost of the optimal
solutions in the subtree of a child is considered while determining
its best value (step 8); for now the cost, due to penalties, of a
child's value differing from ![]() is ignored.
The
is ignored.
The ![]() array entries of the children are set to these best values
(step 11) and the costs are added up (step 12).
While processing each child this way another table
array entries of the children are set to these best values
(step 11) and the costs are added up (step 12).
While processing each child this way another table
![]() is
populated with the additional cost of moving one of the children to be
the maximum child under
is
populated with the additional cost of moving one of the children to be
the maximum child under ![]() (step 13). Once all children values have
been set this way, in a second pass the
(step 13). Once all children values have
been set this way, in a second pass the
![]() table is used
to determine which child should be moved, and what value it should be
moved to, so that the sum of the cost from its subtree and penalty
w.r.t. the parent value is minimum (step 17). Once the child and its
new value are determined, step 18 and step 19 update the
table is used
to determine which child should be moved, and what value it should be
moved to, so that the sum of the cost from its subtree and penalty
w.r.t. the parent value is minimum (step 17). Once the child and its
new value are determined, step 18 and step 19 update the ![]() array
and the cost of the current node
array
and the cost of the current node ![]() respectively. Note that the
initial assignment of values to children might not change in this
second pass if the original child with the maximum value also costs
the least once we take into account penalties. Once BUILDERRORRELAX has filled the
respectively. Note that the
initial assignment of values to children might not change in this
second pass if the original child with the maximum value also costs
the least once we take into account penalties. Once BUILDERRORRELAX has filled the ![]() array, the function ISOTONESMOOTH uses it to compute the optimal values for each node in
the tree.
array, the function ISOTONESMOOTH uses it to compute the optimal values for each node in
the tree.
To demonstrate the correctness of this algorithm, we first show that
the restriction of the optimal solution to a subtree is also the
optimal solution for the subtree under the constraints imposed by its
parent. Consider the subtree rooted at any non-root node ![]() .
Now suppose the smoothed score
.
Now suppose the smoothed score
![]() is specified and also
whether
is specified and also
whether ![]() has the maximum value of its siblings in the optimal
solution. If
has the maximum value of its siblings in the optimal
solution. If ![]() does not have the maximum value then let
does not have the maximum value then let ![]() be the smoothed scores of the optimal solution to the regularized tree
isotonic regression problem for this subtree, under the additional
constraint that
be the smoothed scores of the optimal solution to the regularized tree
isotonic regression problem for this subtree, under the additional
constraint that
![]() . If
. If ![]() does have the
maximum value then let
does have the
maximum value then let ![]() represent the optimal smoothed
scores in
represent the optimal smoothed
scores in ![]() such that they minimize
such that they minimize
![]() subject to
subject to
![]() , where
, where
![]() is the cost of the subtree
is the cost of the subtree ![]() under
under ![]() .
.
This Lemma can be proved by similar reasoning as Lemma 2.6. Consider a smoothed solution
In order to proceed with showing correctness of our algorithm, we have to next show that the two separate loops in steps 9-15 and steps 16-19 do an optimal job of assigning values to children nodes. The first loop assigns children values only based on the costs within their subtrees. The second loop then changes the value of a single child node making it the maximum amongst all siblings. Hence, we need to prove that this one transformation results in the optimal assignments of values to children.
Consider a node ![]() with children
with children
![]() . Let
. Let
![]() be the optimal solution to
Problem 2.4 for the subtree
be the optimal solution to
Problem 2.4 for the subtree ![]() when
when ![]() is
constrained to be some value
is
constrained to be some value ![]() . Also, let
. Also, let ![]() be a
valid solution with
be a
valid solution with
![]() obtained after execution of
steps 5-15 in algorithm BUILDERRORRELAX in
Figure 4.
obtained after execution of
steps 5-15 in algorithm BUILDERRORRELAX in
Figure 4.
By Lemma 2.8, in the optimal solution, a node can take only take values from a finite sized set, and by Lemma 2.6, combining the optimal smoothed scores for subtrees yields the optimal smoothed scores for the entire tree. Hence, all that remains to be shown is that BUILDERRORRELAX finds optimal assignments for the children
COMPLEXITY. The space complexity of the algorithm is ![]() as there are
as there are ![]() entries in the dynamic programming table for each
node. In the algorithm BUILDERRORRELAX, step 2 takes
entries in the dynamic programming table for each
node. In the algorithm BUILDERRORRELAX, step 2 takes ![]() time, step 7 takes
time, step 7 takes ![]() time amortized over all calls (this loop
is called for each node only once), and the loops in step 9 and step
16 can be done in
time amortized over all calls (this loop
is called for each node only once), and the loops in step 9 and step
16 can be done in
![]() time by storing
time by storing
![]() and
and
![]() values in heaps and then running over the values
values in heaps and then running over the values
![]() in descending order of
in descending order of ![]() .
Hence, the total running time is
.
Hence, the total running time is
![]() . Note that this is
same as the complexity of the algorithm for the strict case (in
Figure 4) and also the best time complexity of
previously known algorithms for the non-regularized forms of tree
isotonic regression [1].
. Note that this is
same as the complexity of the algorithm for the strict case (in
Figure 4) and also the best time complexity of
previously known algorithms for the non-regularized forms of tree
isotonic regression [1].
In this section we evaluate our approach and algorithm on the text classification domain.
DATASET.
We perform our empirical analysis on the 20-newsgroups dataset2. This dataset has been extensively used for evaluating text categorization techniques [15]. It contains a total of 18, 828 documents that correspond to English-language posts to 20 different newsgroups, with a little fewer than a 1000 documents in each. The dataset presents a fairly challenging classification task as some of the categories (newsgroups) are very similar to each other with many documents cross-posted among them (e.g., alt.atheism and talk.religion.misc). In order to evaluate our classifier smoothing schemes we use the hierarchical arrangement of the 20 newsgroups/classes constructed during experiments in [14]. The hierarchy is shown in Figure 1 and we refer to it as TAXONOMYI.
Since all documents in the 20-newsgroups taxonomy belong to leaf level nodes, it serves to evaluate our approach on Scenario I. In order to simulate the conditions encountered under Scenario II, we constructed ``hybrid'' documents that represent the content of internal nodes in the hierarchy. For each internal node class, hybrid document were constructed by combining documents from a random number of its children classes. Care was taken to ensure that the number of distinct words in a hybrid document as well as its length were similar to the documents being combined. For each internal node around 1000 new documents were created this way. We refer to this modified taxonomy as TAXONOMYII.
OBTAINING CLASSIFIER SCORES.
We trained one classifier for each node, internal as well as leaf-level, of both the 20-newsgroups taxonomies. Each classifier was trained to predict whether a test document belongs to one of the classes in the subtree of the node associated with the classifier. Hence, while training the classifiers on TAXONOMYI, the positive set of documents comes from leaf level classes in the subtree of the node. All the documents from outside the node form the negative class. In the case of TAXONOMYII, the positive (negative) set of documents also included those from internal nodes within (outside) the subtree. As classification algorithms, we used the Support Vector Machine [9] and Naive Bayes [12] classifiers, both of which have been shown to be very effective in the text classification domain [14]. Another reason for choosing these particular classification functions is that they can both output posteriors probabilities of documents belonging to classes [8]. This ensures that the outputs of distinct classifiers/nodes that being smoothed are comparable to each other.
EVALUATION MEASURES.
We report on a few different evaluation measures to highlight various aspects of our smoothing approach's performance. A standard question that can be asked about performance is ``How many documents were placed in the correct class?''. To answer this question, we report the classification accuracy averaged over the all the classes in the dataset. The classification accuracy is fraction of documents for which the true labels and the predicted labels match; accuracy is micro-averaged over all the classes. In TAXONOMYI classification accuracy was computed over 20 leaf-level classes, while in TAXONOMYII it was computed over all 31 nodes in the tree.
We can also ask performance questions from the perspective of
documents. Since each document has multiple true labels (a class and
all parents on the path to the root), we can ask ``How many of a
document's true labels were correctly identified?''. We answer this
question via the precision and recall of true labels for each
document. Precision is the fraction of class labels predicted
as positive by our approach that are actually true labels, while
recall is the fraction of true class labels that are also
predicted by our approach as positive. These precision-recall numbers
can be summarized by their harmonic mean, which is also known as the
F-measure. We also use a related measure called area
under the ROC curve [7], which summarizes
precision-recall trade-off curves. An advantage of AUC is that it is
independent of class priors; a labeling that randomly predicts labels
for documents has an expected AUC score of ![]() , while a perfect
labeling scores an AUC of
, while a perfect
labeling scores an AUC of ![]() .
.
PARAMETER SETTINGS.
All results reported in this section were obtained after a 5-fold cross validation. Hence, in each fold 80% of the data was used for training. Out of that 10% was held out to be used as a validation set for adjusting parameters. Each performance number reported in this section is averaged over the 5 folds. The variation in performance across folds was typically on the order of the third decimal place and so all improvements reported in Table 1 and 2 are statistically significant.
The SVM classifier was trained with a linear kernel and the ``C'' parameter was learned using the validations set by searching over {0.1,1,10} as possible values. These set of values have been seen to be effective in past work [14]. Both classifiers were trained without any feature selection as both are fairly robust to overfitting (our classification system's performance is very close to what has been previously recorded [14]). While performing smoothing on TAXONOMYI the penalties for all nodes are set equal, while penalties are set in a node-specific manner while performing smoothing on TAXONOMYII. The details of penalties are mentioned later in this section.
| |||||||||||||||||||
| |||||||||||||||||||
 |
 |
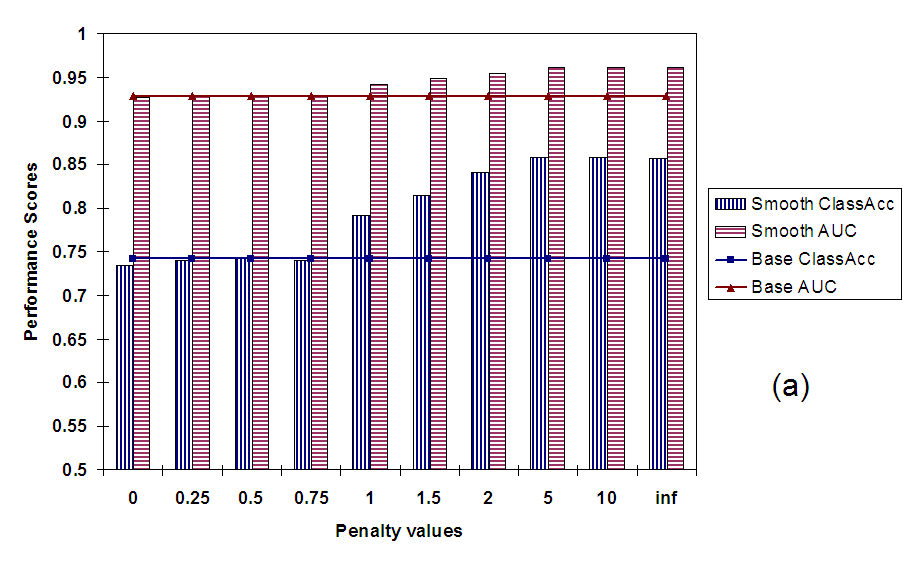
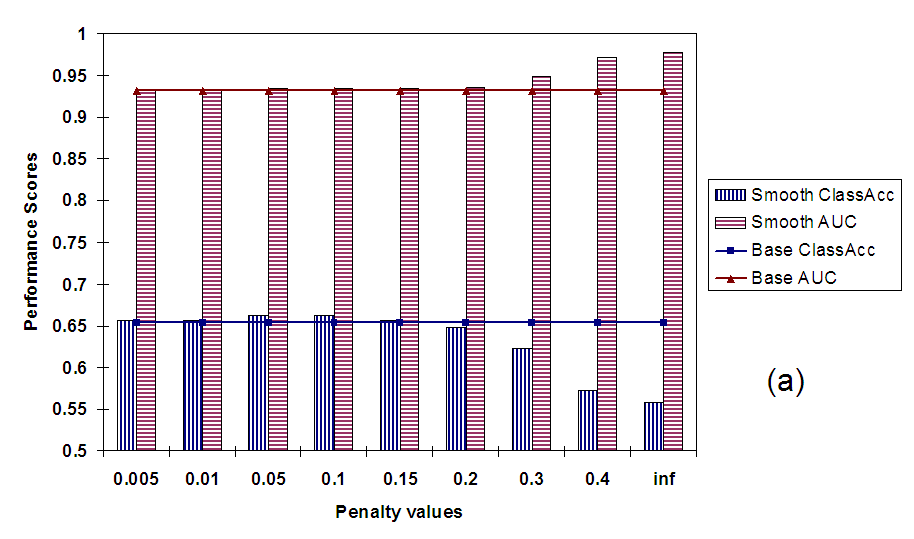
First we discuss the performance of isotonic smoothing in terms of
average classification accuracy per class and average AUC per
document. In Figure 5(a) we plot both these
measures against varying values of penalty. As we vary the penalty
from 0 to ![]() , the problem changes from simple isotonic
regression to enforcing the strict monotonicity constraints. We can
see from the plots that this progression of problems also translates
into improved performance; both classification accuracy and AUC
increase significantly with higher penalties. This shows that our
method for smoothing classifier scores improves performance from the
perspectives of both the classes as well as the documents.
, the problem changes from simple isotonic
regression to enforcing the strict monotonicity constraints. We can
see from the plots that this progression of problems also translates
into improved performance; both classification accuracy and AUC
increase significantly with higher penalties. This shows that our
method for smoothing classifier scores improves performance from the
perspectives of both the classes as well as the documents.
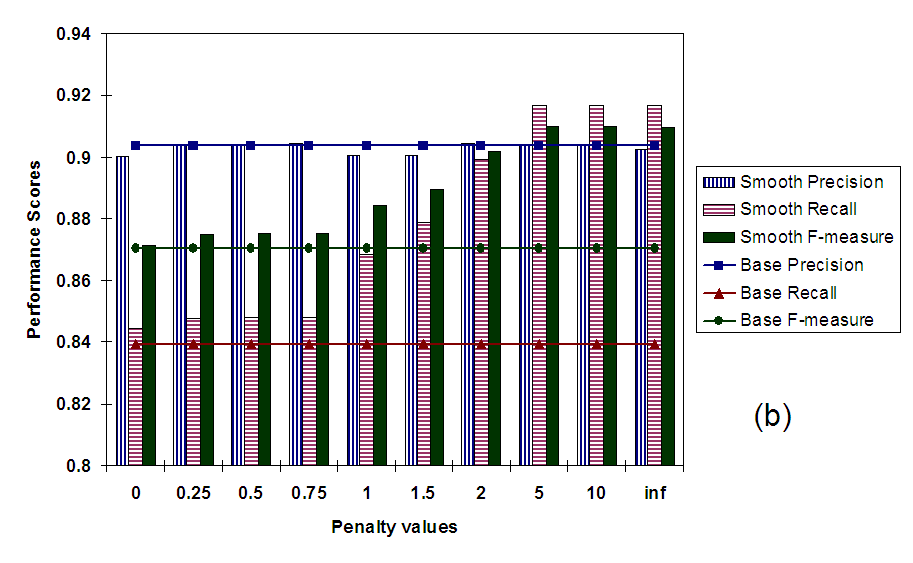
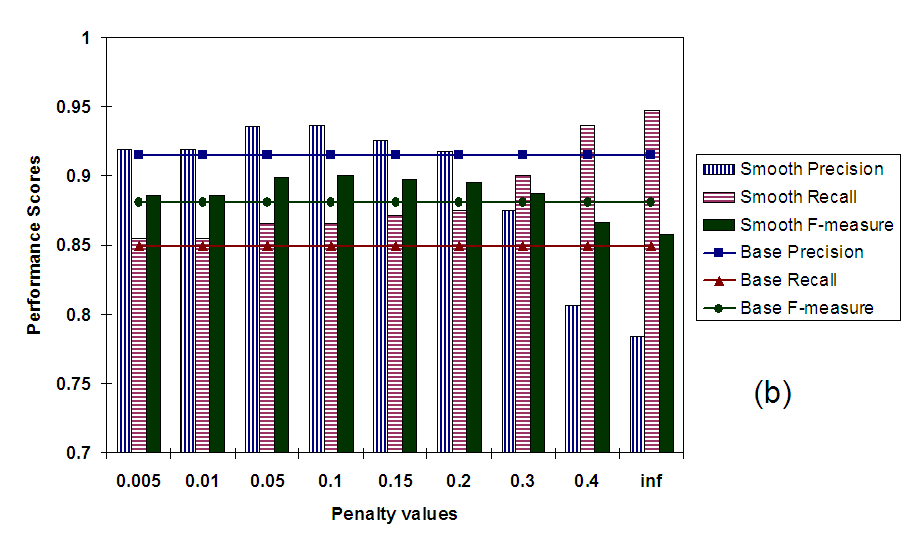
Figure 5(b) plots the values for precision, recall, and F-measure averaged across all documents. Once again, these values are plotted against increasing penalty values. As we can see F-measure rises as penalties are increased and we move towards enforcing strict monotonicity constraints. These strict constraints ensure that the value of the parent is equal to the value of at least one of its children. This type of smoothing takes care of situations where leaf-level classes are mislabeled while their parent nodes are correctly labeled. In these cases, high penalty values make children conform to the parent's score correcting the error, resulting in increased precision and recall. However, strict constraints can also sometime lead to some false positives - especially in shallow hierarchies like the 20-newsgroups - causing a decrease in precision. These trends are exactly what we observe in Figure 5(b). However, the increase in recall compensates for the slight decrease in precision by far, resulting in a higher overall F-measure score.
Since we are evaluating on a dataset that falls under Scenario I, and
the strict monotonicity property was framed for just such a scenario,
it makes sense that of all penalty values,
![]() results
in best performance. However, it is also interesting to observe the
behavior of our dynamic programming based method for low and high
range of penalties. As we can see from
Figure 5(a) and
Figure 5(b) for penalty values between 0 and 1
there is hardly any change in performance from simple isotonic
regression (
results
in best performance. However, it is also interesting to observe the
behavior of our dynamic programming based method for low and high
range of penalties. As we can see from
Figure 5(a) and
Figure 5(b) for penalty values between 0 and 1
there is hardly any change in performance from simple isotonic
regression (![]() ). This is because, in this range of penalty
the cost to a node for deviating from its parent's smoothed value is
less than the cost from
). This is because, in this range of penalty
the cost to a node for deviating from its parent's smoothed value is
less than the cost from ![]() error for deviating from its own
original value. Hence, the regularization term gets no chance to
correct certain types of common errors, especially in shallow
hierarchies like TAXONOMYI. Also, as penalty increases well
above 1 (
error for deviating from its own
original value. Hence, the regularization term gets no chance to
correct certain types of common errors, especially in shallow
hierarchies like TAXONOMYI. Also, as penalty increases well
above 1 (
![]() ) the increase in performance
saturates. This is because once penalty becomes sufficiently large it
becomes impossible to violate any strict monotonicity constraints (a
node's value always equals the maximum of its children's value) and
the smoothing behaves as if penalty was set to
) the increase in performance
saturates. This is because once penalty becomes sufficiently large it
becomes impossible to violate any strict monotonicity constraints (a
node's value always equals the maximum of its children's value) and
the smoothing behaves as if penalty was set to ![]() .
.
We summarize the performance of our smoothing approach in Table 1 and Table 2. As we can see, over and above just classification smoothing provides considerable gains in terms of classification accuracy over classes and precision-recall of labels for a document. According to our results simple isotonic regression without penalties results in almost no improvement highlighting that the gains are due to the regularization aspect our approach.
THE EFFECT OF MISSING CLASSIFIER SCORES.
In certain applications, especially those involving dynamic, fast changing, and vast corpora like the Web, we may not have the time or the data to train classifiers for each node (internal or leaf-level) in a hierarchical classification system. In such situations we can classify test instances for nodes with trained classifiers, while resorting to guessing at values for nodes without classifiers. In this section we evaluate whether smoothing the outputs of classifiers that have been trained can help us predict scores for classifiers that haven't been learned.
In order to simulate situations like these we randomly select a set
fraction of nodes in our 20-newsgroups taxonomy that we don't train
classifiers for. Then we apply our smoothing approach to the tree of
nodes (some with missing values) and see if the smoothed scores of the
nodes with missing values match the true labels. In our dynamic
programming based method the nodes with missing values are given a
weight of zero so that they don't contribute to the ![]() error. The
smoothing approach, hence, replaces the values of the missing nodes
with whatever value that helps reduce the cost of isotonic
smoothing. However, as the number of missing nodes increases the
amount of information provided to the smoothing algorithm decreases
and, therefore, we expect the performance of the whole system to also
degrade.
error. The
smoothing approach, hence, replaces the values of the missing nodes
with whatever value that helps reduce the cost of isotonic
smoothing. However, as the number of missing nodes increases the
amount of information provided to the smoothing algorithm decreases
and, therefore, we expect the performance of the whole system to also
degrade.
In order to provide baseline performance we replace the missing classifier scores randomly with a true or a false - we bias the random predictions by the observed priors for the missing class. This class prior information is gathered from the training data for the class. In situations where classifier values are missing because of lack of training data, we can use other priors for these replacements (maybe average size of other classes in the data). Note that we didn't use the class prior information in the smoothing approach to predicting missing values.
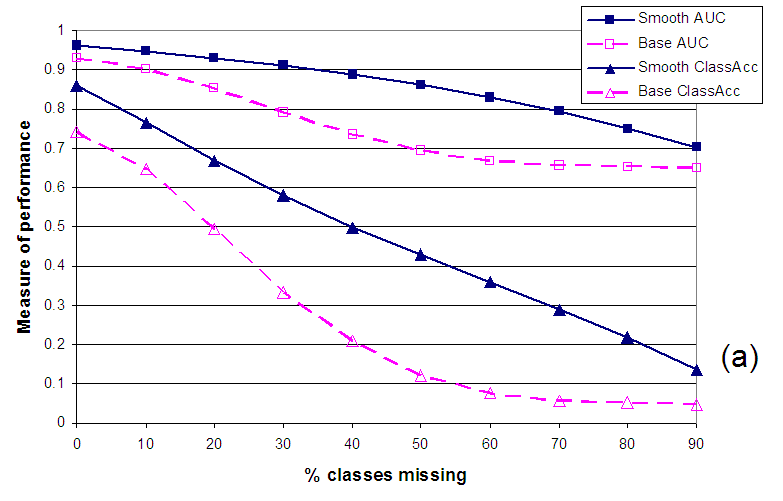
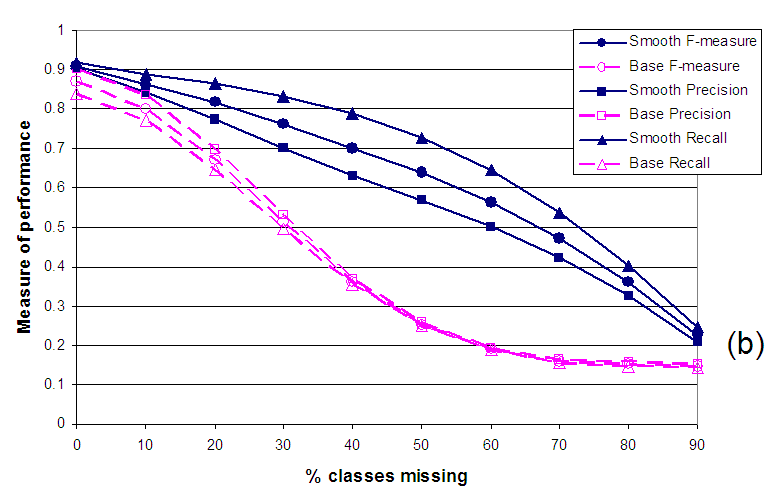
In Figure 6 we examine the performance of our system as the fraction of missing classes is increased (on the X-axis). The performance is measured in terms of the metrics mentioned earlier in this paper. As we can see from the plots, as the fraction of missing values increases the performance decreases. However, the decrease in the quality of smoothed outputs is far lower than the baseline predictions. Even though the smoothed and baseline predictions start with similar accuracy values, the difference between their performances grows dramatically with increasing number of missing values. For instance, in Figure 6(a) the classification accuracy after smoothing is 16% higher than baseline with no missing values and this difference grows to 254% at 50% missing values. Similarly, the corresponding numbers for AUC are 3% and 24%. Figure 6(b) graphs performance in terms of precision, recall, and F-measure against varying amounts of missing values. Once again as the number of missing values increases, the difference in performance of smoothed outputs over baseline balloons: at 50% missing values, smoothing outperforms baseline by 155% in terms of F-measure.
The decrease in performance of baseline predictions is very dramatic at the beginning but after sufficient number of values are missing the effect of predicting with priors kicks in and the accuracy stabilizes. Since our smoothing approach does not use the knowledge of class priors, its performance never stops decreasing and at around 90% missing values the accuracy of smoothed scores and baseline scores is similar again. Hence, devising a well founded way to incorporate such prior information into the smoothing will improve the performance of our approach even more, especially in adverse conditions with many missing values.
 |
In fact, we observe exactly this behavior in the plots in
Figure 7(a) and
Figure 7(a). As we increase the penalty
from 0 to ![]() , the performance measures first increase and then
decrease. The only exceptions to this trend of rise and fall are the
Recall and AUC measures. Recall increases because as we increase the
penalty (and start enforcing strict monotonicity), more children
classes are forcefully and erroneously labeled positive. This increase
in Recall and AUC is offset by a decrease in Precision and, hence, the
F-measure.
, the performance measures first increase and then
decrease. The only exceptions to this trend of rise and fall are the
Recall and AUC measures. Recall increases because as we increase the
penalty (and start enforcing strict monotonicity), more children
classes are forcefully and erroneously labeled positive. This increase
in Recall and AUC is offset by a decrease in Precision and, hence, the
F-measure.
These above results showcase a scenario where penalties need to set in a node-specific manner. When we used a standard penalty value for all nodes we didn't see any improvement in performance upon smoothing. This was because the same penalty that lead to correction of an error at a leaf-level class, introduced errors in other cases where a document belonged to an internal node (and not to any of its children). Hence, gains in classification accuracy in one part of the tree were offset by losses in others. Figure 7(a) and Figure 7(a) correspond to experiments in which penalties for nodes were set in proportion to the chance that a document belonging to the node also belongs to one of its children (the value on the X-axis is the proportionality constant). At a given node, the more the chance the higher its penalty value was set, as this ensured that the node's value was close to the maximum of its children's values.
Even with the node-specific penalties, the performance gains at the best values of penalty are very modest: at penalty=0.1, F-measure and Classification Accuracy increase above the baseline by 2% and 1.3% respectively. This is because the hypothesis that we are trying to enforce here is very weak, and many erroneous classifications of a document pass the hypothesis. A stronger property that relates classification scores of adjacent nodes (like in Scenario I) will lead to higher performance gains.
While we are not aware of any work that explicitly post-processes classifier outputs in a taxonomy in order to correct errors and improve accuracy, in this section we present some existing work on related topics.
HIERARCHICAL TEXT CLASSIFICATION.
Hierarchical classifiers have been used to segment classification problems into more manageable units at the nodes of the hierarchy [3]. Using well defined hierarchies ensures that a smaller set of features suffices for each classifier [6,10]. Dumais et al. [6] work with SVM classifiers on a two-level hierarchy and show that hierarchical classification performs better than classification over a flat set of classes. Similar results are shown by Punera et al. in [14], where the effect of quality of hierarchy on classification accuracy is examined.
EXPLOITING CLASS RELATIONSHIPS IN CLASSIFIER.
The inter-class relationships in hierarchies can be exploited to improve the accuracy of classification. One of the early works in this area employed a statistical technique called shrinkage to improve parameter estimates of nodes in scarce data situations via the estimates of parent nodes [11]. Chakrabarti et al. [4] present Hyperclass, a classifier for webpages that, while classifying a page, consults the labels of its neighboring (hyperlinked) webpages. Finally, there is some recent work on generalizing support vector learning to take into account relationships among classes mirrored in the class-hierarchy [17].
Our work differs from these approaches by exploiting inter class relationships as a post-processing step leaving classifiers to treat each class individually. There are a couple of distinct advantages of this paradigm. First, by separating monotonicity enforcement from classification, we drastically simplify the latter step and can use any off-the-shelf classifier. This way we can take advantage of all the different classifier that have been developed, many of them for specialized domains. Second, while the above classifiers can be trained to follow monotonicity rules there is no guarantee that on a test instance they will produce monotonic outputs, a requirement that might be critical in some domains.
ISOTONIC REGRESSION.
Isotonic regression has been used in many domains such as
epidemiology, microarray data analysis [1],
webpage cleaning [2], and calibration of
classifiers [19]. Similarly, many works have
proposed efficient algorithms for finding optimal solutions. For
complete orders the optimal solutions can be computed in ![]() for
for ![]() , and
, and ![]() time for
time for ![]() distance
metrics [16]. For isotonic regression on rooted trees
the best known algorithms work in
distance
metrics [16]. For isotonic regression on rooted trees
the best known algorithms work in ![]() time for
time for ![]() [13] and
[13] and ![]() time for
time for ![]() metrics [1]. A regularized version of the
isotonic regression problem is solved
in [2], once again in
metrics [1]. A regularized version of the
isotonic regression problem is solved
in [2], once again in ![]() time
for the
time
for the ![]() metric.
metric.
In this paper we have introduced a different isotonic regression
problem in which the regularization term only depends on the parent
value and the maximum of its children's values. This distinct
constraint is motivated by the classifier output smoothing problem. We
presented a dynamic programming based method to solve this new problem
optimally in ![]() time for the
time for the ![]() metric.
metric.
In this paper we formulated the problem of smoothing classifier outputs as a novel optimization problem that we call regularized isotonic regression. To solve this problem, we presented an efficient algorithm that gives an optimal solution. Moreover, using a real-world text dataset we showed that performing smoothing as a post-processing step after classification can drastically improve accuracy.
Interesting future work includes applying isotonic smoothing of hierarchical classifiers to other domains (with novel cost functions and constraints), and devising well founded ways to incorporate prior knowledge (like class priors) into the smoothing formulation.
ACKNOWLEDGMENTS. The authors thank Deepayan Chakrabarti and
Ravi Kumar for valuable discussions.