Unfortunately, using mirror sites for Web 2.0 applications for scalability may not be effective. In the Web 2.0 environment, each user is an author and publisher. The sheer amount of user interaction, and the fact that shared data are edited simultaneously at mirror sites physically far apart, create a lot of difficulty in consistency control. In fact, performances of some popular Web 2.0 sites (e.g. Wikipedia, Open Directory Project, YouTube, etc.) can be very different across different places at different times.
Traditional distributed database systems maintain consistency by enforcing the following semantics: the result of a concurrent execution must be equivalent to a serial one [16]. A common way to achieve serialized transactions is to use Two Phase Locking (2PL) [7]: transactions on different objects are executed simultaneously while transactions on a same object are serialized by using locks.
In the Web environment, the main weaknesses of the above approaches are the following: (1) Due to internet latency between mirror sites, it is very costly to obtain locks and commit transactions. To ensure data integrity during the process, the system must block all other operations (including read-only operations), which reduces performance, and is unacceptable in the Web 2.0 environment. This undoes the purpose of creating mirror sites, which is to increase scalability. (2) The locking mechanism requires all mirror sites to wait for the slowest site to commit the transaction and free the lock. Thus, vulnerability of one mirror site may affect the efficiency of the entire system.
Web 2.0 users need a more flexible concurrency control mechanism. Many current studies on user collaboration [6,14,11] show that in order to facilitate free and natural information flow among collaborating users, it is important to allow users to concurrently edit any part of the shared document at any time. Traditional methods are unfit as concurrent operations (in transaction mode) always block one another. Thus, it is clear that lock-based mechanisms are unsuitable for mainitaining consistency of mirror sites that run Web 2.0 applications. This motivates us to explore novel approaches for consistency control in the Web 2.0 environment.
In this paper, we introduce a light-weight, lock-free approach to maintain consistency of mirrored sites. We briefly summarize our approach below.
This paper is organized as follows. In Section 2, we describe the replicated architecture of mirrored sites. Section 3 introduces the causality concept. Lock-free consistency control for transactional and non-transactional operations are discussed in Section 4 and 5. Section 6 discusses experiments. We discuss related work in Section 7 and conclude in Section 8.
In this section, we describe the consistency control problem in the web environment.
Data shared in mirrored sites can be in varied forms. In this paper, we assume the shared data on mirrored sites are XML documents. Consequently, operations on the data are expressed by XML queries and updates.
There are two W3C standards for XML queries: XPath [17] and XQuery [18]. To process an XPath query, we start from the root node, match all paths satisfying the XPath pattern, and return the leaf nodes on this path. An XQuery is represented as a FLWR (For-Let-Where-Return) pattern, and processed in two phases: a twig pattern matching phase defined by FLW and a result construction phase defined by R. XQuery is an extension to XPath and is more powerful than XPath.
Update operations allow users to modify XML documents. Currently, there is no standard for Update operations. We use FLWU, an XQuery extension introduced by Tatarinov et. al. [15], to express updates. An FLWU is processed in two phases: in the FLW phase, multiple subtrees that match the pattern specified by FLW are generated, that is similar with the first part of XQuery [18], then in the U (update) phase, certain nodes of the sub-trees are modified. The actions of second phase (U) are based on the result of the first phase (FLW), thus we call the results of the first phase the execution set of the operation. In mirrored sites, so long as the FLW process gets the same execution set, the final results should be the same across all sites.
<Root>
<book @title="Introduction to Algorithm">
<category>CS</category>
<tag>Hot</tag>
</book>
<book @title="Advanced Statistical Learning">
<category>UnKnow</category>
</book>
<book @title="Linear Algebra">
<category>Math</category>
</book>
</Root>
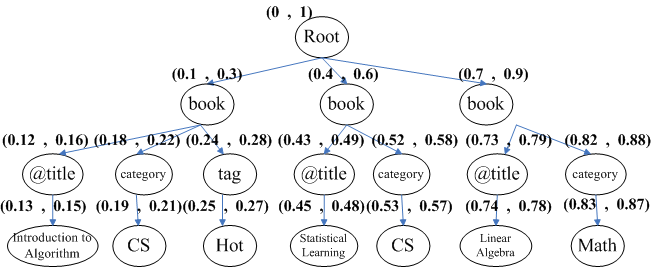
In our paper, we use the above XML document consisting 3
books, and the four Update operations, ![]() ,
, ![]() ,
, ![]() and
and ![]() on the XML
document as a running example for explaining consistency control
in mirrored sites.
on the XML
document as a running example for explaining consistency control
in mirrored sites.
|
Operation Change the title ``Advanced Statistical Learning'' to ``Statistical Learning''.
FOR $title in
/root//title
WHERE $title =
"Advanced
Statistical Learning"
UPDATE $title {
REPLACE $title WITH
"Statistical Learning"
}
|
Operation Set the category of the ``Linear Algebra'' book to ``Math''.
FOR $book in /root/book,
$title = $book/title,
$category = $book/category
WHERE $title =
"Statistical Learning"
UPDATE $book {
REPLACE $category WITH
<category>Math</category>
}
|
|
Operation Add a discount tag to books in ``Math'' category.
FOR $book in /root/book,
$category =
$book/category
WHERE $category = "Math"
UPDATE $book {
INSERT
<tag>Discount</tag>
}
|
Operation Set the category of the ``Linear Algebra'' book to ``CS''.
FOR $book in /root/book,
$title = $book/title,
$category = $book/category
WHERE $title =
"Linear Algebra"
UPDATE $book {
REPLACE $category WITH
<category>CS</category>
}
|
We assume that shared data on each mirrored site is represented as a huge XML document. Our goal is to achieve good query/update response and support unconstrained collaboration. This leads us to adopt a replicated architecture for storing shared documents: the shared document is replicated at the local storage of each mirrored site. A user can operate on the shared data at any replica site, but usually at the site closest to the user. Non-transactional user operations are executed immediately at that site, and then dispatched to other sites. Transactional operations require more complicated scheduling. We discuss both cases in this paper.
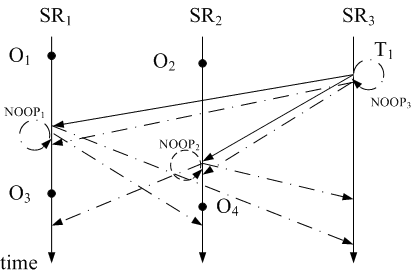
As an example, Figure 2
shows three replicas in a groupware environment: ![]() ,
, ![]() and
and
![]() . Replica
. Replica ![]() receives and executes two operations
receives and executes two operations ![]() and
and ![]() . We assume
. We assume
![]() and
and ![]() are causal operations, since
are causal operations, since ![]() operates on the results of
operates on the results of ![]() , and they are initiated from the same site, possibly
by the same user. Operations
, and they are initiated from the same site, possibly
by the same user. Operations ![]() ,
,
![]() and
and ![]() arrive at roughly the same time on
arrive at roughly the same time on ![]() ,
, ![]() , and
, and ![]() respectively. Here, we assume
respectively. Here, we assume ![]() is a transaction.
is a transaction. ![]() ,
,
![]() and
and ![]() are concurrent operations.
are concurrent operations.
To be clear, given a user operation, we call the replica receiving the operation the local replica and other replicas remote replicas. And for the local replica, we also call this operation its local operation, and operations dispatched from other replicas remote operation. In Section 3, we define a causal (partial) ordering relationships on operations based on their generation and execution sequences.
We use three examples to illustrate the need for consistency control based on the above settings.
The three cases require different handling in consistency control. In the rest of the paper, Section 3 discusses consistency control issues for causal relationships, Section 4 for transactions, and Section 5 for non-transactional concurrent operations. Overall, we generalize the above cases and show our method ensures consistency in a replicated Web architecture.
In this section, we present the concept of causality, as well
as a known solution for causality preservation (ensuring causal
operations such as ![]() and
and ![]() are executed in the same order across all
replicated sites) without using locking mechanisms. The
techniques we discuss here will be used as building blocks for
ensuring consistency of transaction and non-transactional
concurrent operations.
are executed in the same order across all
replicated sites) without using locking mechanisms. The
techniques we discuss here will be used as building blocks for
ensuring consistency of transaction and non-transactional
concurrent operations.
Consider operations ![]() ,
, ![]() in Figure 1, and
replica
in Figure 1, and
replica ![]() in Figure 2. Operation
in Figure 2. Operation ![]() changes a book title from ``Advanced Statistical
Learning'' to ``Statistical Learning'', and then
changes a book title from ``Advanced Statistical
Learning'' to ``Statistical Learning'', and then ![]() sets the category of book ``Statistical Learning''
to ``Math''. Obviously,
sets the category of book ``Statistical Learning''
to ``Math''. Obviously, ![]() is
causally after
is
causally after ![]() since the user
intends to execute
since the user
intends to execute ![]() based on
based on
![]() 's result. However, because of
internet latency, replica sites such as
's result. However, because of
internet latency, replica sites such as ![]() may receive
may receive ![]() before
before
![]() . To address this problem, we
apply the causality preservation strategy.
. To address this problem, we
apply the causality preservation strategy.
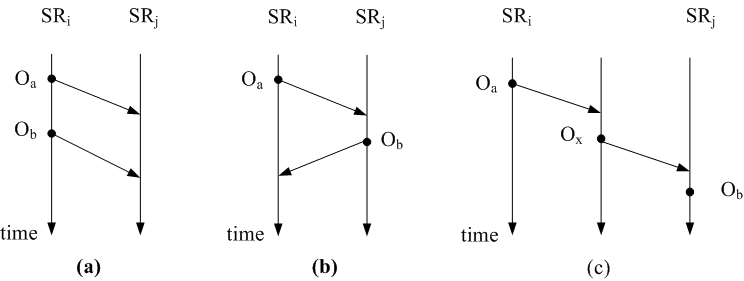
Figure 3 illustrates the 3 cases of causality given by Definition 2.
Intuitvely, in order for every site to execute causal
operations such as ![]() and
and ![]() in the same order, all they need to know is that
in the same order, all they need to know is that
![]() precedes
precedes ![]() on the site they are generated, so if
on the site they are generated, so if ![]() arrives first, they will wait until
arrives first, they will wait until ![]() arrives. But in a distributed environment, it is
difficult to implement a global, precise clock that informs each
site the precedence of operations. The challenge is thus to
define the "happened before" relation without using physical
clocks.
arrives. But in a distributed environment, it is
difficult to implement a global, precise clock that informs each
site the precedence of operations. The challenge is thus to
define the "happened before" relation without using physical
clocks.
To do this, we use a timestamping scheme based on State Vector
(![]() ) [6,14]. Let
) [6,14]. Let ![]() be
the number of replica sites (we assume
be
the number of replica sites (we assume ![]() is a constant). Assume replica sites are identified by
their unique replica IDs:
is a constant). Assume replica sites are identified by
their unique replica IDs:
![]() . Each site
. Each site ![]() maintains a vector
maintains a vector ![]() with
with ![]() components. Initially,
components. Initially,
![]() .
After it executes a remote operation dispatched from site
.
After it executes a remote operation dispatched from site
![]() , it sets
, it sets
![]() .
.
In our approach, all (non-transactional) operations are
executed immediately after their generation (operations'
localized execution ensures good response and supports
unconstrained collaboration). Then the operation is dispatched to
remote sites with a timestamp (state vector) equal to the local
state vector. Specifically, operation ![]() generated from site
generated from site ![]() is dispatched to
other replicas with a state vector timestamp
is dispatched to
other replicas with a state vector timestamp ![]() .
.
Intuitively, the first condition ensures that ![]() is the next operation from site
is the next operation from site ![]() , that is, no operations originated from site
, that is, no operations originated from site
![]() before
before ![]() have been missed by site
have been missed by site ![]() . The
second condition ensures that all operations originated from
other sites and executed at site
. The
second condition ensures that all operations originated from
other sites and executed at site ![]() before the generation of
before the generation of ![]() have been
executed at site
have been
executed at site ![]() already. The two
conditions ensure that
already. The two
conditions ensure that ![]() can executed at
site
can executed at
site ![]() without violating causality.
[14]
without violating causality.
[14]
Take Figure 2 as an
example. Assume the state vector of each site is
![]() initially.
When
initially.
When ![]() is dispatched to
is dispatched to ![]() , it carries a state vector with
, it carries a state vector with
![]() , because
, because
![]() has executed 2 local
operations
has executed 2 local
operations ![]() and
and ![]() . However,
. However, ![]() because
site
because
site ![]() has not executed any operation
from
has not executed any operation
from ![]() . Thus the first execution
condition,
. Thus the first execution
condition,
![]() , is not
satisfied, which means
, is not
satisfied, which means ![]() cannot be
executed on
cannot be
executed on ![]() yet. Now
yet. Now ![]() arrives at
arrives at ![]() with
state vector
with
state vector
![]() . It is executed
immediately and
. It is executed
immediately and ![]() is increased
by 1. Then,
is increased
by 1. Then, ![]() is ready for execution
because
is ready for execution
because
![]() . Thus,
. Thus,
![]() and
and ![]() will be executed on
will be executed on ![]() and
and ![]() in the same order as they are executed on
in the same order as they are executed on
![]() . We have thus solved the first
problem in Section 2.3.
. We have thus solved the first
problem in Section 2.3.
We omit the proof of Theorem 1 in the paper. Details related to this result can be found in [6,10]. Specifically, Lamport [10] first introduced timestamp to describe the causal relationship. C. A. Ellis [6] first proposed an execution condition to preserve the causality among operations.
Some critical operations need to be executed in the transaction mode to guarantee integrity across multi-replicas. For example, when doing a money transfer, if the money is debited from the withdrawal account, it is important that it is credited to the deposit account. Also, transactions should not interfere with each other. For more information about desirable transaction properties, please refer to [16,7]. In this section, we discuss a light-weight approach to achieve this in a replicated environment.
The transaction model is introduced to achieve concurrent transparency [16,7]. In the transaction semantics, although the system is running many transactions concurrently, the user can still assume that his/her transaction is the only operation in the system. To achieve the same goal in a distributed environment, we must guarantee a transaction is serializable with other operations (both transactional and non-transactional operations).
According to our definition of concurrent operations (Definition 3), it is easy to see that a serialized transaction does not have concurrent operations. This ensures that transaction integrity is guaranteed across multiple replicas. But in a fully replicated architecture, it is very hard to achieve global serialization. In the following, we describe in detail how we achieve global serialization in such a replicated environment.
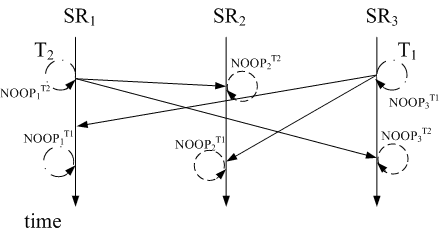
Of course, existing causal relationships are not enough to enforce serialization of operations across all sites. To solve this problem, we create dummy operations (NOOPs) to introduce a rich set of virtual causal relationships. With these virtual relationships, we implement transaction semantics.
Assume ![]() is submitted to replica
is submitted to replica
![]() . Because
. Because ![]() is a transaction, it is not executed immediately at
its local replica, as we must enforce transaction semantics
across all sites. Each site
is a transaction, it is not executed immediately at
its local replica, as we must enforce transaction semantics
across all sites. Each site ![]() ,
including
,
including ![]() itself, creates a dummy
NOOP
itself, creates a dummy
NOOP![]() upon receiving
upon receiving ![]() , and dispatches NOOP
, and dispatches NOOP![]() to other
sites. This is shown in Figure 4, where a solid line represents
the dispatching of a transaction from a local site to a remote
site, a dashed line represents the dispatching of a NOOP, and a
circle represents the dispatching of a NOOP to the local site
itself.
to other
sites. This is shown in Figure 4, where a solid line represents
the dispatching of a transaction from a local site to a remote
site, a dashed line represents the dispatching of a NOOP, and a
circle represents the dispatching of a NOOP to the local site
itself.
The NOOPs introduce a rich set of causal relationships. Assume
![]() is initiated at
is initiated at ![]() between its local operations
between its local operations ![]() and
and ![]() , and
, and ![]() is initiated at
is initiated at ![]() between its local operations
between its local operations ![]() and
and
![]() . The NOOPs create the following
causal relationships:
. The NOOPs create the following
causal relationships:
Under the execution condition, ![]() and
and ![]() will be
executed after
will be
executed after ![]() and
and ![]() , while
, while ![]() and
and
![]() will be executed after
will be executed after
![]() and
and ![]() . At any site, we execute
. At any site, we execute ![]() immediately after all NOOPs corresponding to
immediately after all NOOPs corresponding to
![]() are executed. It is easy to
see that at each site,
are executed. It is easy to
see that at each site,
The above procedure works not only in this case. It actually
enforces serializability in all cases. Intuitively, when
NOOP![]() is generated on
is generated on ![]() , it divides concurrent operations local to
, it divides concurrent operations local to
![]() into two sets:
into two sets: ![]() and
and ![]() , which are
concurrent operations that arrive before and after
NOOP
, which are
concurrent operations that arrive before and after
NOOP![]() at
at ![]() ,
respectively. The causality introduced by NOOP
,
respectively. The causality introduced by NOOP![]() at site
at site ![]() can be expressed
as
can be expressed
as
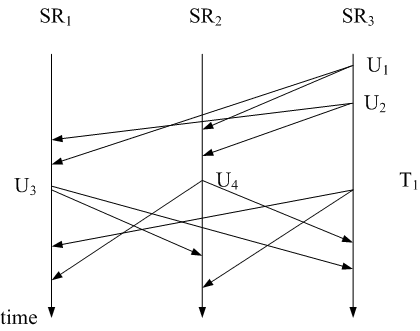
There is one pitfall in the above reasoning: it is possible
that on a site, the set of NOOPs will never be causally
ready to execute. This happens when there are more than one
concurrent transactions. Figure 5 shows an example. Two
concurrent transactions arrive at replica sites in different
order. Let NOOP![]() denote the NOOP
operation generated for transaction
denote the NOOP
operation generated for transaction ![]() at
replica
at
replica ![]() . At site
. At site ![]() , we have NOOP
, we have NOOP
![]() NOOP
NOOP
![]() , and at site
, and at site
![]() , we have NOOP
, we have NOOP
![]() NOOP
NOOP
![]() . Thus, neither the
entire set of { NOOP
. Thus, neither the
entire set of { NOOP![]() }, nor the
entire set of { NOOP
}, nor the
entire set of { NOOP![]() }, will
ever be causally ready for execution: the two transactions block
each other.
}, will
ever be causally ready for execution: the two transactions block
each other.
Our goal is to achieve global serialization. Suppose finally
we have
![]() . Clearly,
causality in the form of
. Clearly,
causality in the form of
![]() are
inconsistent with this order. The solution is to simply remove
such causalities. However, this requires all sites to agree on
the final order
are
inconsistent with this order. The solution is to simply remove
such causalities. However, this requires all sites to agree on
the final order
![]() .
.
The State Vector timestamping mechanism we introduced in Section 3 creates a virtual global clock, so that each relica site agrees on the ``happened-before'' relationship for causal operations. This gives us a way to order non-transactional operations. Transactions, however, do not have State Vector timestamps (they are not executed immediately on local replicas). In our case, transactions trigger non-transactional NOOP operations, which enable us to extend the order among non-transactional operations to transactions.
A non-transactional operation is assigned a state vector
timestamp at the site it is generated, and dispatched to all
other replicas with the same state vector timestamp. We define a
![]() function [14] based on such timestamps.
function [14] based on such timestamps.
![]()
It is easy to see that, because each non-transactional operation has the same state vector timestamp at each replica, the total order among non-transactional operations defined above is agreed by all replicas.
We then extend TOrder to create a total order among transactions.
With a total order among transactions, we can solve the problem above. Algorithm 1 handles local operations, and Algorithm 2 handles operations dispatched from other sites. Finally, Theorem 2 shows that they achieve serializability.
In this section, we discuss how to perform consistency control for concurrent, non-transactional operations.
 |
To ensure consistency without using locks, we propose an XML
storage model that allows us to recover XML documents to states
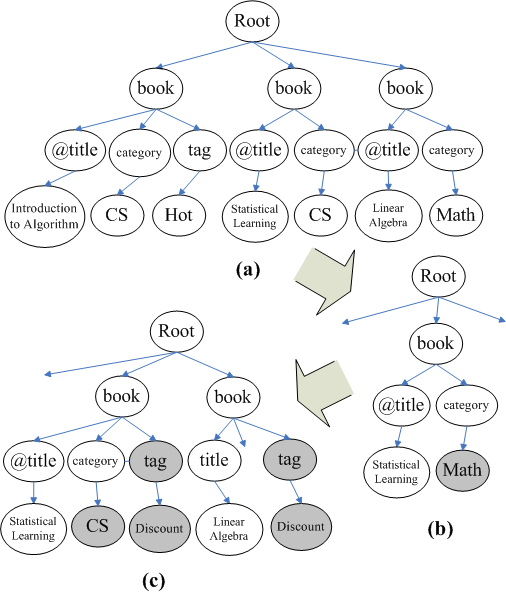
before a previous concurrent operation was executed. Figure
6 gives an example. Figure
6(a) shows the XML document
on site ![]() after the execution of
operation
after the execution of
operation ![]() , which changes the category
of ``Statistical Learning'' from ``CS'' to ``Math''. Later,
, which changes the category
of ``Statistical Learning'' from ``CS'' to ``Math''. Later,
![]() receives operation
receives operation ![]() , and it decides that
, and it decides that ![]() has an earlier timestamp than
has an earlier timestamp than ![]() (as
indicated by TOrder). Then, it retraces the state of XML document
to the state shown in Figure 6(b), which is the state before
(as
indicated by TOrder). Then, it retraces the state of XML document
to the state shown in Figure 6(b), which is the state before
![]() is executed. Finally,
is executed. Finally,
![]() is executed on the retraced XML
document, which adds a ``Discount'' tag to both
``Statistical Learning'' and ``Linear Algebra'' since both of
them are in category ``Math'', then
is executed on the retraced XML
document, which adds a ``Discount'' tag to both
``Statistical Learning'' and ``Linear Algebra'' since both of
them are in category ``Math'', then ![]() is
executed to change the category of ``Statistical Learning'' to
``CS''. The result XML document, which is shown in Figure
6(c), will be the same as
that on site
is
executed to change the category of ``Statistical Learning'' to
``CS''. The result XML document, which is shown in Figure
6(c), will be the same as
that on site ![]() , where
, where ![]() is generated and executed first.
is generated and executed first.
The high level procedures for the local site and remote site are shown in Algorithm 3 and 4 respectively. Both of the algorithms are concerned with the non-transactional operations, as we have discussed transactions in Section 4. Algorithm 3 executes a local operation immediately once it is generated. Algorithm 4 retraces to earlier states when remote operates arrive with an earlier timestamp. Note that in neither of the two algorithms, the operations are forced to wait.
In the rest of the section, we describe in detail the storage model and the retracing algorithm.
The core of XML query processing relies on one fundamental
operation: determine the ancestor-descendent relationship between
two nodes in an XML document. An efficient way of telling whether
one node is an ancestor (descendant) of another node is to use
interval-bases labels [4].
In the example shown in Figure 7 (which represents the XML document
on site ![]() after the execution of
after the execution of
![]() but before the execution of
but before the execution of
![]() ), each node
), each node ![]() is labeled by an interval
is labeled by an interval
![]() . Using the labels,
we can immediately tell the ancestor-descendent relationships:
node
. Using the labels,
we can immediately tell the ancestor-descendent relationships:
node ![]() is a descendant of node
is a descendant of node
![]() if
if
![]() . The
labels in Figure 7 are real
values in the range of [0, 1], which allows us to subdivide the
range when new nodes are inserted.
. The
labels in Figure 7 are real
values in the range of [0, 1], which allows us to subdivide the
range when new nodes are inserted.
To support efficient twig matching, we employ inverted lists
to organize labeled nodes. More specifically, for each
element/attribute/value in the XML document, we create a linked
list which includes the labels of nodes that have the same
element/attribute/value. For instance, in Figure 8, the linked list for the
book element has three members:
![]() , corresponding to the
3 books in Figure 7.
, corresponding to the
3 books in Figure 7.
The inverted lists enable us to efficiently find the nodes involved in a query and match the twig pattern by joining the nodes. The inverted lists, however, represent a certain state of the XML document only. In order to retrace its temporal history, i.e., states of the XML document before certain update operations are executed, we need some additional mechanisms.
In order to recover the document to a previous state, we
assign each node in the inverted lists a pair of timestamps
(create, delete), where create and
delete are the TOrder number of the operation that
creates and deletes the node. It is clear that create
![]() delete. In other
words, when an operation deletes a node, instead of removing it
from the inverted lists, we assign it a delete
timestamp, but keep it there. In Section 5.4, we show that we only need to
keep a limited number of states in the inverted lists - when an
operation has been executed on all sites, it will have no
concurrent operations, and its effect is made permanent on the
inverted lists. In the next section, we discuss how retracing and
query processing are performed on timestamped inverted lists.
delete. In other
words, when an operation deletes a node, instead of removing it
from the inverted lists, we assign it a delete
timestamp, but keep it there. In Section 5.4, we show that we only need to
keep a limited number of states in the inverted lists - when an
operation has been executed on all sites, it will have no
concurrent operations, and its effect is made permanent on the
inverted lists. In the next section, we discuss how retracing and
query processing are performed on timestamped inverted lists.
In this section, we discuss how to augment traditional XML query processing engines to support retracing, querying, and updating on timestamped inverted lists.
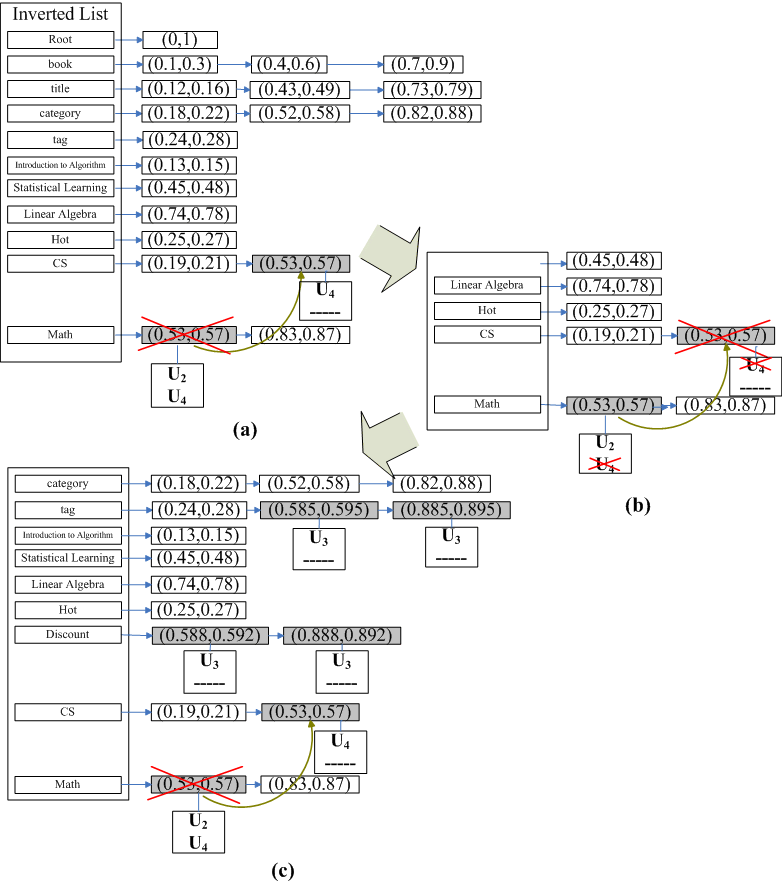
The (create, delete) timestamps enable us to retrace
the temporal history of an XML document. Let us first examine an
example. The inverted lists shown in Figure 9 correspond to the XML documents in
Figure 6. Figure 9(a) shows the inverted list on site
![]() after the execution of
after the execution of
![]() ,
, ![]() ,
and
,
and ![]() . The Math node
. The Math node
![]() is created by
operation
is created by
operation ![]() and deleted by operation
and deleted by operation
![]() . Thus, it has timestamp
. Thus, it has timestamp
![]() 2. Since
2. Since
![]() changes the Math node to
a CS node, a new node with timestamp
changes the Math node to
a CS node, a new node with timestamp ![]() is created in the inverted list of CS.
When
is created in the inverted list of CS.
When ![]() arrives, we find that, according
to the total order,
arrives, we find that, according
to the total order,
![]() . We thus retrace the
steps to before
. We thus retrace the
steps to before ![]() is executed, as
we show in Figure 6(b).
Since the Math node
is executed, as
we show in Figure 6(b).
Since the Math node
![]() is timestamped
is timestamped
![]() , which means it is
deleted by
, which means it is
deleted by ![]() , its timestamp is rolled
back to
, its timestamp is rolled
back to ![]() , making the node
current again. On the other hand, the CS node with
timestamp
, making the node
current again. On the other hand, the CS node with
timestamp ![]() will be removed as it
is created at time
will be removed as it
is created at time ![]() , which is a
future timestamp at time
, which is a
future timestamp at time ![]() .
.
In summary, the inverted lists keep mutltiple versions or
multiple states for the category of the book ``Statistical
Learning''. This is shown in Figure 10. First, ![]() changes its category from Unknown to Math, then
changes its category from Unknown to Math, then
![]() changes it again to CS.
Thus, the three states can be arranged into a sequence. It is
clear that there is no overlap in their timestamps, and at any
time only one of them is valid.
changes it again to CS.
Thus, the three states can be arranged into a sequence. It is
clear that there is no overlap in their timestamps, and at any
time only one of them is valid.
In general, only nodes whose timestamp
![]() satisfies
satisfies
![]() are
valid at
are
valid at ![]() . For the example above,
given
. For the example above,
given ![]() , whose timestamp precedes
that of
, whose timestamp precedes
that of ![]() , we know only the
Math state is valid, and the Unknown and CS
states are invalid.
, we know only the
Math state is valid, and the Unknown and CS
states are invalid.
We introduce an algorithm called State-Join (Algorithm
5) to process basic parent/child
relationships, ``![]() '', or ancestor
/descendant relationships, ``
'', or ancestor
/descendant relationships, ``![]() ''. The
algorithm takes into consideration the states of each XML node
defined by its timestamp. As finding the parent-child and
ancestor/descendant relationships is the most fundamental
operation in XML query processing, it can be used by other XML
query algorithms, such as the stack-based algorithm known as
Stack-Tree-Desc [2],
for twig-pattern matching in a transparent manner.
''. The
algorithm takes into consideration the states of each XML node
defined by its timestamp. As finding the parent-child and
ancestor/descendant relationships is the most fundamental
operation in XML query processing, it can be used by other XML
query algorithms, such as the stack-based algorithm known as
Stack-Tree-Desc [2],
for twig-pattern matching in a transparent manner.
As the example shown in Figure 8 (which represents the XML document
on site ![]() after the execution of
after the execution of
![]() but before the execution of
but before the execution of
![]() ), in order to process
), in order to process
![]() , we first fetch the inverted
list of ``book'', ``title'', ``category'' and ``Math''. Though
the category of book ``Linear Algebra'' has been changed into
``CS'', the original node (0.53, 0.57) still exists in the
inverted list of ``Math'' and is timestamped (
, we first fetch the inverted
list of ``book'', ``title'', ``category'' and ``Math''. Though
the category of book ``Linear Algebra'' has been changed into
``CS'', the original node (0.53, 0.57) still exists in the
inverted list of ``Math'' and is timestamped (![]() ,
, ![]() ). According to the total
order,
). According to the total
order,
![]() , which
means the node is valid as far as
, which
means the node is valid as far as ![]() is
concerned. Since timestamp checking has
is
concerned. Since timestamp checking has ![]() cost, the State-Join algorithm will not increase the
complexity of the original Stack-Tree-Desc algorithm.
cost, the State-Join algorithm will not increase the
complexity of the original Stack-Tree-Desc algorithm.
Instead of modifying a node, what an update operation really
does is to create a new state for the node in the state-based
inverted list, and leave the original node intact (except
changing its timestamp). For example, in order to execute
![]() at the state of Figure 8, it (i) creates two new nodes
(0.585, 0.595) and (0.885, 0.895), and insert them into the
inverted list for ``tag''; (ii) creates two new nodes (0.588,
0.592) and (0.888, 0.892), and insert them to the inverted list
for ``Discount''; and (iii) set the timestamps for all of them to
(
at the state of Figure 8, it (i) creates two new nodes
(0.585, 0.595) and (0.885, 0.895), and insert them into the
inverted list for ``tag''; (ii) creates two new nodes (0.588,
0.592) and (0.888, 0.892), and insert them to the inverted list
for ``Discount''; and (iii) set the timestamps for all of them to
(![]() , -).
, -).
XML documents are sensitive to the order of sibling nodes
under a parent node. If two operations insert two nodes under a
same parent node, we must enforce that their order is the same at
all sites. We again use the ![]() function to determine the sibling order of nodes inserted by
concurrent operations. A serious treatment of this problem may
use techniques as the scan function [8] to achieve global consistentancy for
insert operations in a linear structure. We omit the proof here.
Information for this result can be found in [8].
function to determine the sibling order of nodes inserted by
concurrent operations. A serious treatment of this problem may
use techniques as the scan function [8] to achieve global consistentancy for
insert operations in a linear structure. We omit the proof here.
Information for this result can be found in [8].
Our approach ensures faster response time. Notably, each non-transactional concurrent operation is executed immediately on its local replica. More generally, concurrent operations are executed in different order on different replicas. This means inconsistency exists across mirrored sites. However, we guarantee that at any moment, if all operations have been executed on all replicas, the mirrored data on each replica converges to a same state. In essence, the convergence property ensures the consistency of the final results at the end of a cooperative editing session [14].
In order to evaluate the efficiency of XML Updates, we build a prototype system and compare it to lock-based distributed system. The experiment is conducted with 100Mbps LAN, 2-4 sites, CPU P4 2.4G, main memory 1G, and Windows 2003. The prototype system and the lock-based distributed system are both implemented By Java (Version 1.6.0-b105). We adjust operations' frequency to simulate network latency.
Experiment data comes from DBLP website [1], and current size is 133MB. We create 70 queries and 70 updates and execute them repeatedly. An additional computer is used to submit the above operations to each site with given frequency, and record the average responding time. The process of experiments are described as follows.
There are three types of operations: Query,
Non-Transaction Update, and Transaction Update. We
label them as
![]() ,
, ![]() and
and ![]() respectively. For lock-based distributed system, all operations
are in transaction mode, and it has only two types of operations:
respectively. For lock-based distributed system, all operations
are in transaction mode, and it has only two types of operations:
![]() and
and
![]() .
.
First, we evaluate the effect of different operation
frequencies. The parameters are: 3 sites, the proportions of
![]() ,
, ![]() and
and ![]() are 90%,
8% and 2%, respectively, network latency between two sites is
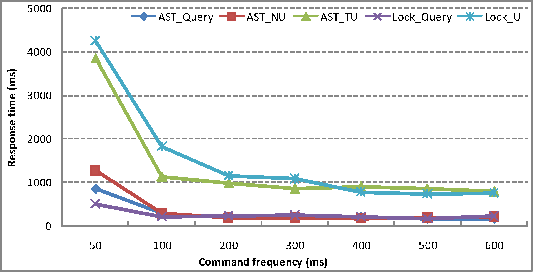
200ms. The result is shown in Figure 11:
are 90%,
8% and 2%, respectively, network latency between two sites is
200ms. The result is shown in Figure 11:
When the frequency is every 50ms or 100ms an operation, since
operations can not be executed immediately, they were blocked in
the waiting queue. ![]() and
and
![]() involves more
dependancies than
involves more
dependancies than ![]() ,
,
![]() and
and
![]() do, so the response
time of
do, so the response
time of ![]() and
and
![]() rose rapidly. On the
other hand, when the frequency drops to 200ms to 600ms an
operation, the response time of
rose rapidly. On the
other hand, when the frequency drops to 200ms to 600ms an
operation, the response time of ![]() is similar to query operation and also far below
is similar to query operation and also far below
![]() and
and
![]() . By using
. By using
![]() instead of
instead of ![]() and forcing more operations executed at
local site we can significantly improve the response time.
and forcing more operations executed at
local site we can significantly improve the response time.
Second, we evaluate the effect of different network latencies.
The parameters are: 3 sites, the proportions of
![]() ,
, ![]() and
and ![]() is 90%, 8%
and 2% and the sending command frequency is 200ms. The network
latency between sites are simulated by force a given delay. The
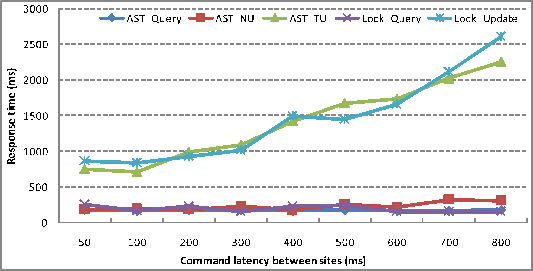
result is shown in Figure 12.
is 90%, 8%
and 2% and the sending command frequency is 200ms. The network
latency between sites are simulated by force a given delay. The
result is shown in Figure 12.
As latency increases, the only notable growth is for
![]() and
and
![]() , as they need all
sites participation. As noted before, one of the benefits to
deploy more sites is to enable the user to select the nearest
site to access and get higher speed and shorter respond time. So
by relying on
, as they need all
sites participation. As noted before, one of the benefits to
deploy more sites is to enable the user to select the nearest
site to access and get higher speed and shorter respond time. So
by relying on ![]() , which execute
locally, we have a good way to achieve this goal. But the
lock-based update operations need to request locks from all
replicated sites and will block all other conflict operations.
Even thought more sites are deployed, the respond time not only
depends on the latency between the user and his/her entry site
but also depends on the network latency among all replicated
sites. Further more, the network latency in internet is unstable
and inevitable.
, which execute
locally, we have a good way to achieve this goal. But the
lock-based update operations need to request locks from all
replicated sites and will block all other conflict operations.
Even thought more sites are deployed, the respond time not only
depends on the latency between the user and his/her entry site
but also depends on the network latency among all replicated
sites. Further more, the network latency in internet is unstable
and inevitable.
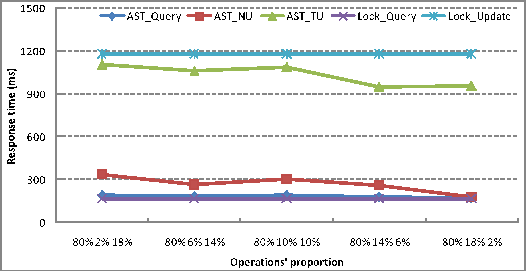
Third, we evaluate the effect of compositions of different types of operations. Similarly, the parameters are: 3 sites, network latency between sites is 200ms, and the frequency is 200ms per operation. The results are shown in Figure 13 and Figure 14.
The figures show, as the ratio of ![]() increases, the conflicts between
increases, the conflicts between ![]() decreases. It lowers the responding time of both
decreases. It lowers the responding time of both
![]() and
and ![]() . The figures also show that through increasign
the ratio of
. The figures also show that through increasign
the ratio of ![]() , we can
significantly reduce the average response time.
, we can
significantly reduce the average response time.
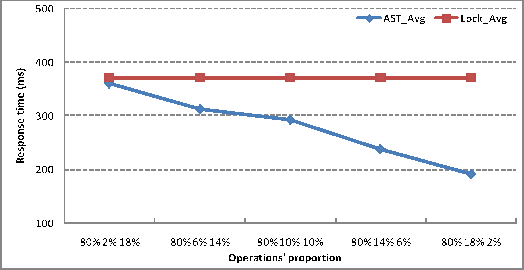
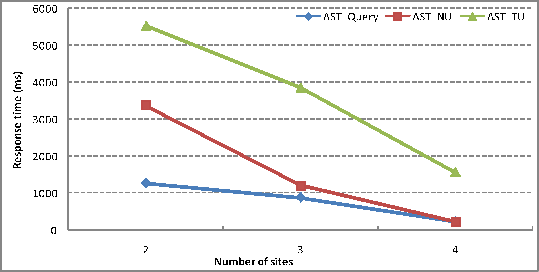
Finally, we evaluate the effect of number of sites. The
parameters are: network latency is 200ms, the average frequency
is 50ms per operation, and the proportions of
![]() ,
, ![]() and
and ![]() operation
are 90%, 8% and 2%. The result is shown in Figure 15:
operation
are 90%, 8% and 2%. The result is shown in Figure 15:
To evaluate the effect for different number of sites, we choose the frequency to 50ms. The result shows as the number of sites increases, the average response time decreases.
In summary, the four experiment results show that the
algorithm meet our expectations. By executing ![]() locally and avoiding the dependance of network
latency, we can make better load balance and achieve high-speed
access and shorter respond time.
locally and avoiding the dependance of network
latency, we can make better load balance and achieve high-speed
access and shorter respond time.
There are a few multi-replicas consistency maintenance solutions. Bayou [13] implements a multi-replicas mobile database, but for concurrent operations, its repeated undo and redo lead to huge system cost. TACT [13] tries to limit the differences between replicas, but when a replica exceeds the limit, operations will be blocked and response time will increase. TSAE [13] uses ack vectors and vector clocks to learn about the progress of other replicas. The execution of an Update operation is blocked until it arrives at all replicas. XStamps [20] proposes a timestamp based XML data multi-replica control solution, but some conflicting operations will be aborted. Though this is avoidable in a serial execution, the authors point out that generally, aborting is inevitable in XStamps.
Our work focuses on consistency control of structured data such XML, and is uses the stack-based algorithm for XML query processing. Recent work including Holistic Twig Joins [3] further improves XML query performance. These new approaches rely on the same inverted list as the stack-based algorithm. Thus, they are compatible to our retracing approach.
Assume there are ![]() transactions in
the system:
transactions in
the system:
![]() .
Without loss of generality, assume the
.
Without loss of generality, assume the
![]() , for all
, for all
![]() . There may exist
one or more
. There may exist
one or more
![]() and we have
and we have
![]() for all
for all
![]() . Since
. Since
![]() , we switch the
timestamps of involving NOOPs to reverse the causality.
Specifically,
, we switch the
timestamps of involving NOOPs to reverse the causality.
Specifically,
![]() will switch its
timestamp with all
will switch its
timestamp with all
![]() until
until
![]() causally
precedes all
causally
precedes all
![]() where
where
![]() .
.
Thus, ![]() must be executed first
among
must be executed first
among
![]() on all replica
sites. Then the remain operations are
on all replica
sites. Then the remain operations are
![]() .
According to the assumption, the execution order of
.
According to the assumption, the execution order of ![]() operations at every site is
consistent. Thus, the execution order are consistent after
operations at every site is
consistent. Thus, the execution order are consistent after
![]() operations in all replica site.
operations in all replica site.
![]()
We consider the situation after all timestamp switches have
taken place for transactional operations. Without loss of
generality, assume ![]() is generated
from replica site
is generated
from replica site ![]() . Since the
switch rule only applies to NOOP operations from the same
replica site, after the switch,
. Since the
switch rule only applies to NOOP operations from the same
replica site, after the switch, ![]() should still have one corresponding NOOP operation from each
replica site. Let
should still have one corresponding NOOP operation from each
replica site. Let
![]() denote the NOOP
operation from site
denote the NOOP
operation from site ![]() . Since both
. Since both
![]() and
and
![]() are local
operations of replica site
are local
operations of replica site ![]() , their
relationship can only be Causal Relationship (Definition
2). Their execution order
is determined by the Execution Condition for remote operation
(Definition 4).
Since transaction
, their
relationship can only be Causal Relationship (Definition
2). Their execution order
is determined by the Execution Condition for remote operation
(Definition 4).
Since transaction ![]() will be executed
together with
will be executed
together with
![]() at all sites. So
the execution order between
at all sites. So
the execution order between ![]() and
and
![]() is fixed.
is fixed.
In summary, no matter which type the operation is, the
execution order is certain. This satisfies the Definition
5. ![]()
Lemma 2 proved
consistency for two operations in a distributed environment.
Based on Lemma 2, we
simply apply the results in our previous work (Theorem 3 of
[8]) to extend the proof to
![]() operations.
operations.

![\begin{definitions} (Execution Condition). Assume site $i$\ executes an operati... ...k]$, for all $1 \leq k \leq N$\ and $k \neq i$. \end{enumerate}\end{definitions}](paper-img40.png)
![\begin{algorithm} % latex2html id marker 834 [ht] \floatname{algorithm}{Algorit... ...luding $SR_i$) \par\ENDIF \par\STATE Goto 1 \par\end{algorithmic}\end{algorithm}](paper-img89.png)
![\begin{algorithm} % latex2html id marker 845 [ht] \floatname{algorithm}{Algorit... ...]+1$, for all $SR_j$\ENDIF \ENDIF \STATE Goto 1 \end{algorithmic}\end{algorithm}](paper-img90.png)
![\begin{algorithm} % latex2html id marker 1261 [!t] \floatname{algorithm}{Algori... ...SV_{i}[i] \Leftarrow SV_{i}[i]+1$\par\ENDIF \par\end{algorithmic}\end{algorithm}](paper-img93.png)
![\begin{algorithm} % latex2html id marker 1272 [!t] \floatname{algorithm}{Algorit... ...SV_{i}[j] \Leftarrow SV_{i}[j]+1$\par\ENDIF \par\end{algorithmic}\end{algorithm}](paper-img94.png)


![\begin{algorithm} % latex2html id marker 1360 [ht] \floatname{algorithm}{Algori... ...rn Stack-Tree-Desc($AList$, $DList$) as $ES$\par\end{algorithmic}\end{algorithm}](paper-img121.png)
![\begin{algorithm} % latex2html id marker 1375 [ht] \floatname{algorithm}{Algori... ...rt of Section.\ref{sec:retrace} \par\ENDFOR \par\end{algorithmic}\end{algorithm}](paper-img122.png)