A dramatic development of Internet in China has been witnessed in the recent years. The number of Internet users in China now exceeds 160 millions and the Chinese Web pages are numbered in billions1. As the most commonly used language only second to English, Chinese is expected to enjoy such a rocketing increase in scale. Because the Web pages written in Chinese is becoming a major information source on the Internet, more research efforts are now devoted to organizing and mining the Chinese Web pages via Web mining techniques, such as Chinese blog mining [20] and query log analysis [19].
A potential problem in mining the Chinese Web pages is the lack of sufficient labeled data. As we know, classification requires a large amount of labeled training data. Generally speaking, the more labeled training data one can obtain, the better the classification accuracy and robustness are. Fortunately, due to many reasons, there exists a lot of labeled Web-page information in English, in particular in the machine learning community. Examples of these resources are Reuters-21578 [16], 20 Newsgroups [15], and Open Document Project [22]. It is thus useful and intriguing to fully utilize the labeled documents in English to help classify the Web pages in Chinese. This problem is called cross-language Web-page classification. In this paper, we address this important problem using a novel information theory based technique.
Although the training and test documents are in different languages, one can use a translation tool to help translate the test data sets in the English language, before a classifier trained on English pages can be applied. While such a method may be feasible, we observe that a simple-minded application of this method may result in serious problems because of the following reasons:
- First, due to the difference in language and culture, there exists a topic drift when we move from the English Web pages to the Chinese Web pages. This corresponds to the situation in machine learning where the training and test data have different distributions in terms of the class labels. This topic-imbalanced problem needs to be overcome in our research.
- Second, due to the errors introduced in the translation process, there may be different kinds of errors in the translated text. For example, some errors may result from Chinese phrase segmentation, others are due to ambiguities introduced by a dictionary. This translation noise problem must be addressed effectively.
- Finally, the feature spaces of the English and Chinese Web pages may be different, resulting in a situation where the training and test data may have different feature sets. We therefore must be innovative in our solution to this problem by carefully extracting the common-semantic parts of the two data sets, and use these parts as a bridge to propagate the class labels.
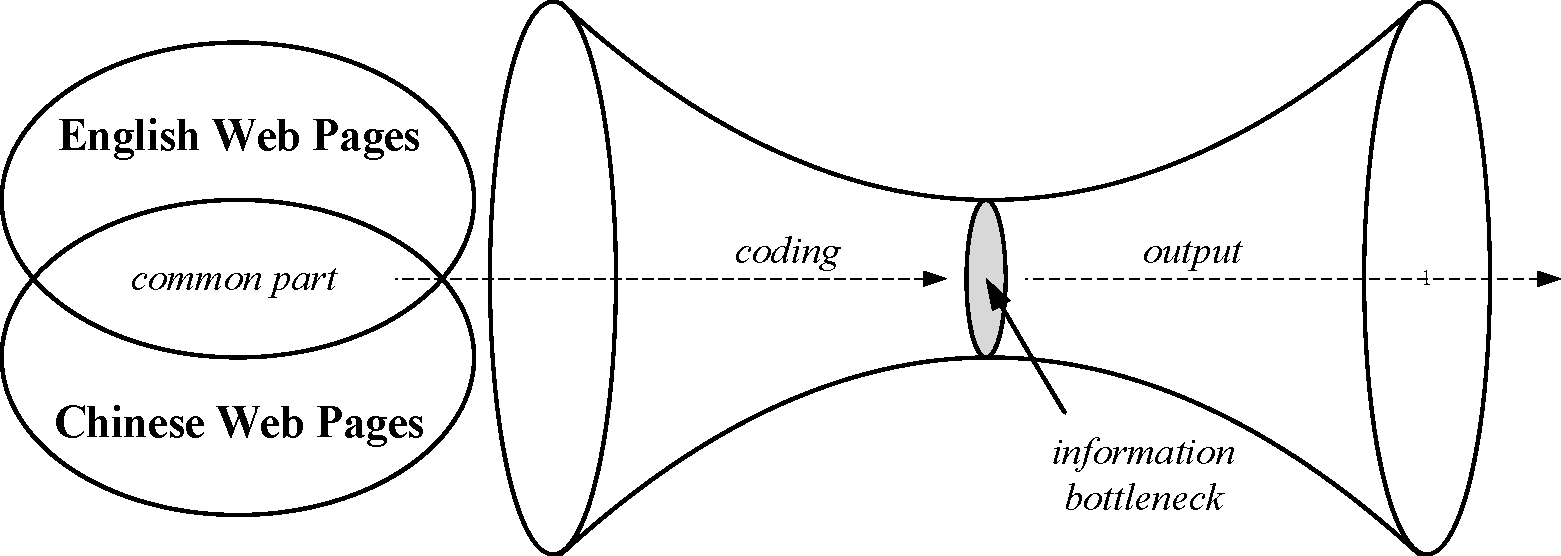
Figure 1: The model of our information bottleneck cross-language classifier.
To solve the above problems, we develop a novel approach for classifying the Web pages in Chinese using the training documents in English. Our key observation is that despite the above listed problems, linguistically, the pages in Chinese and English may share the same semantic information, although they are in different representation forms, i.e., Chinese characters and English words, respectively. This is reasonable, because people with good command of both English and Chinese can convey the same information in both languages. Also, it is noted that the same meaning might be expressed in different ways due to the cultural and linguistic differences.
Based on the observations, we propose to tackle the cross-language classification problem using information bottleneck theory [29]. Figure 1 illustrates our idea intuitively. The training and translated target texts are encoded together, allowing all the information to be put through a ``bottleneck'' and represented by a limited number of codewords (i.e. labels in the classification problem). Information bottleneck based approach can maintain most of the common information and disregard the irrelevant information. Thus we can approximate the ideal situation where similar training and translated test pages, which is the common part, are encoded into the same codewords.
In the experimentation, we collect the Web pages in English and Chinese from Open Directory Project for the data sets. Five binary and three multi-class tasks have been set up. Our method gives significant improvement against several existing classifiers, and converges very well.
In summary, in this paper we make the following contributions:
- In addressing the cross-language Web page classification problem, we observe that there is a common part of Chinese and English documents and develop a novel method for addressing the problem of topic drifts in Chinese and English documents, thus improving the classification performance.
- We propose to handle noisy features and different features problem in cross-language Web-page classification by the information bottleneck technique. This method allows the common part in the two languages to be extracted and used for classification, despite their differences. We show experiments on real English and Chinese Web documents. Our method is shown to improve other classification algorithms.
The rest of our paper is organized as follows: In Section 2 we briefly discuss the related work. Following the basic concepts reviewed in Section 3, we introduce the information bottleneck theory in Section 4. Section 5 describes our proposed method in details. The experiments and results are presented in Section 6. In the end, we conclude this paper with future work discussion in Section 7. The detailed proofs to the lemmas and theorems in this paper will be given in Appendix.
2 Related Work
In this section, we review several prior researches mostly related to our work, including traditional classification, cross-language classification and information theoretic learning.
The traditional classification formulation is built on the foundation of statistical learning theory. Two schemes are generally considered, where one is supervised classification and the other is semi-supervised classification. Supervised classification focuses on the case where the labeled data are sufficient, and where the learning objective is to estimate a function that maps examples to class labels using the labeled training instances. Examples of supervised classification algorithms include decision trees [25],  nearest neighbor methods [6], naive Bayes classifiers [17], support vector machines [5], and so on.
nearest neighbor methods [6], naive Bayes classifiers [17], support vector machines [5], and so on.
Semi-supervised classification [32] addresses the problem that the labeled data are too few to build a good classifier. It makes use of a large amount of unlabeled data, together with a small amount of the labeled data to enhance the classifiers. Many semi-supervised learning techniques have been proposed, e.g., co-training [4], EM-based methods [21], transductive learning [13] etc.
As we claimed, there are two main difficulties in the cross-language classification, namely errors by translation and bias by topic drifts, which traditional classifiers cannot handle well. Our proposed method tries to tackle these difficulties via the information bottleneck technique.
There are several research works addressing the cross-language classification problem. Bel et al. [3] studied English-Spanish cross-language classification problem. Two scenarios are considered in their work. One scenario assumes to have training documents in both languages. The other scenario is to learn a model from the text in one language and classify the data in another language by translation. In our work, we focus on the second scenario. [26] gave good empirical results on English-Italian cross-language text categorization using an EM-based learning method. Note that to avoid trivial partitions, it applies feature selection before each iteration. [23] employed a general probabilistic English-Czech dictionary to translate Czech text into English and then classified Czech documents using the classifier built on English training data. Other cross-language text classification research include [11] (English-Spanish), [18] (English-Japanese) etc, to be mentioned. In addition to text categorization, there are some other specific cross-language applications: Named Entity Recognition [30], Question Answering [8], etc.
However, most existing algorithms are based on traditional supervised or semi-supervised classification techniques. As we stated, there are two difficulties in the cross-language classification, the translation error and topic drift, which lead to difference in distributions between the Web pages in two languages. Since traditional supervised classification techniques assume identical distribution for training and test data and in the cross-language setting this assumption is hardly met, most existing algorithms will not cope with the cross-language text classification well. In this work, our method tries to handle the Chinese-English cross-language categorization problem by information bottleneck. We will show that our algorithm can better alleviate the impact of translation error and topic drift, and improve the (English to Chinese) cross-language classification performance against existing methods.
Another related research is information theory based learning. Information theory is widely used in machine learning, e.g. decision tree [25], feature selection [31], etc.
The information bottleneck theory (IB) was first proposed by Tishby et al. [29]. They constructed a model that uses information theory to solve the clustering problem. In their work, a rate distortion function is introduced as a loss function. They also presented a converging iterative algorithm for this self-consistent determination problem. After that, a lot of interesting works have been conducted, c.f. [27]. As known, IB is an information theoretic formulation for clustering problem while maximum likelihood of mixture models is a standard statistical method to clustering. Interestingly, Slonim and Weiss [28] have proved that under a certain mapping, these two approaches are strongly related. Moreover, when input data is large enough, they are statistically equivalent.
Several extensions to information bottleneck method have been investigated recently. [9] proposed a word clustering method which minimizes the loss in mutual information between words and class-labels, before and after clustering. Using similar strategy, mutual information based [10] and Bregman divergence based [2] co-clustering were proposed.
In contrast to these works, we focus on solving the cross-language classification problem via an information theoretic approach. More specifically, the IB technique is used to mine the common part of the pages in different languages for classification.
3 Preliminary
In this section, some preliminary knowledge in the information theory is briefly introduced, including information entropy, mutual information and Kullback-Leibler divergence [14]. For more details, please refer to [7].
The term entropy is used to measure the uncertainty associated with a random variable 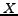 . Formally,
. Formally,
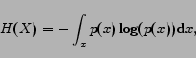 |
(1) |
where 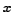 enumerates each value may take. In the communication system, the entropy quantifies the information contained in a piece of data, i.e. its minimum average message length in bits. This means the best possible lossless data compression is limited to this measure.
enumerates each value may take. In the communication system, the entropy quantifies the information contained in a piece of data, i.e. its minimum average message length in bits. This means the best possible lossless data compression is limited to this measure.
Let and 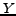 be random variable sets with a joint distribution
be random variable sets with a joint distribution 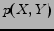 and marginal distributions
and marginal distributions 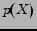 and
and 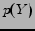 . The mutual information
. The mutual information 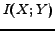 is defined as
is defined as
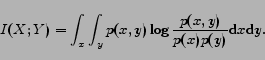 |
(2) |
The mutual information is a measure of the dependency between random variables. It is always non-negative, and it is zero if and only if the variables are statistically independent. Higher mutual information values indicate more certainty that one random variable depends on another.
The mutual information is related to the Kullback-Leibler (KL) divergence or relative entropy measures, defined for two probability mass functions 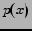 and
and 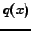 ,
,
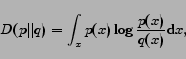 |
(3) |
where is a reference distribution. The KL-divergence can be considered as a kind of a distance between the two probability distributions, although it is not a real distance measure because it is not symmetric. In addition, KL-divergence is always non-negative due to the Gibbs' inequality [7].
4 Information Bottleneck
In this section, we present the basic concepts for information bottleneck, and show how it can be applied to cross-language classification.
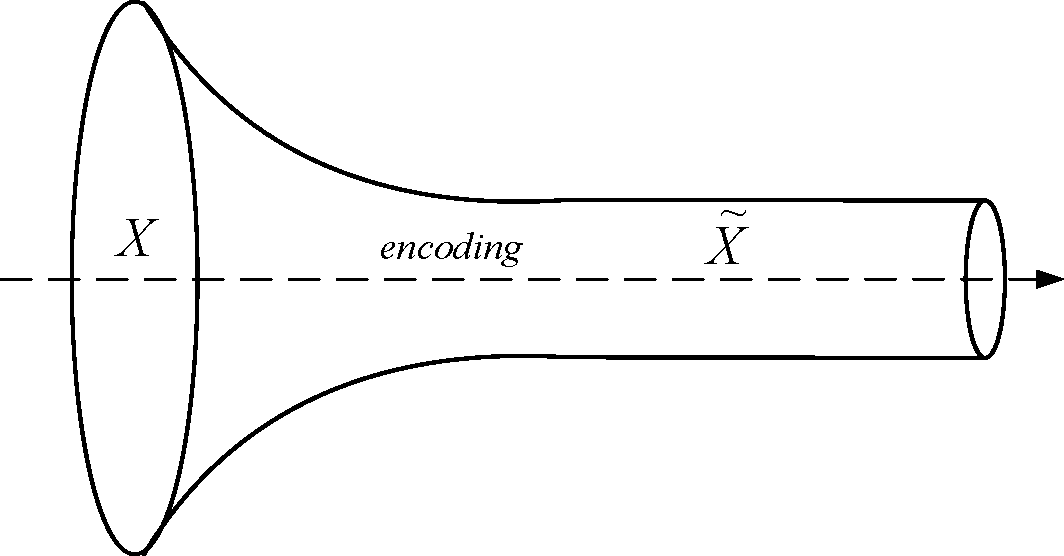
The information bottleneck (IB) method is a distributional learning algorithm proposed by Tishby et al. [29]. In this theory, the clustering and classification problems can be treated as a coding process. Let be the signals to be encoded, and  be the set of codewords. In classification, the codewords is defined as class labels, and then classifying can be seen as using to encode . Usually is not able to contain as much information as . Therefore, when the signals is encoded to codewords , part of the information contained by will be lost. This can be imaged as the information in passing through a bottleneck , as shown in Figure 2, and thus is called information bottleneck.
be the set of codewords. In classification, the codewords is defined as class labels, and then classifying can be seen as using to encode . Usually is not able to contain as much information as . Therefore, when the signals is encoded to codewords , part of the information contained by will be lost. This can be imaged as the information in passing through a bottleneck , as shown in Figure 2, and thus is called information bottleneck.
A good clustering should guarantee the encoding effectiveness (the lower rate the better) as well as meaningful information, which can be formulated as a trade-off objective
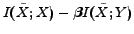 [29], where is the feature set with respect to . Note that the coding rate
[29], where is the feature set with respect to . Note that the coding rate
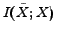 in classification is no so important as in clustering problems, since classification focuses on prediction accuracy. Therefore, in this task, we need to mainly concentrate on improving the classification accuracy. So that,
in classification is no so important as in clustering problems, since classification focuses on prediction accuracy. Therefore, in this task, we need to mainly concentrate on improving the classification accuracy. So that,
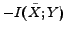 is optimized instead of
, as the coding rate
is ignored. Moreover, in order to make the optimization easier, in this work, we optimize
is optimized instead of
, as the coding rate
is ignored. Moreover, in order to make the optimization easier, in this work, we optimize
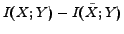 instead of
. We will show the optimization details in the next section. Note that, is a constant, when and are fixed, and thus optimizing
is equivalent to optimizing
.
instead of
. We will show the optimization details in the next section. Note that, is a constant, when and are fixed, and thus optimizing
is equivalent to optimizing
.
The meaning of objective function
can be also understood in another way. In classification, the instances are described by the features, and thus there should be mutual information between data instances and their features, i.e.
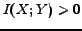 . In addition, the category information is also described by the features, and thus
. In addition, the category information is also described by the features, and thus
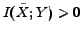 . Therefore, the information in and is contained in forms of and
. Therefore, the information in and is contained in forms of and
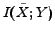 . Note that is always greater than or equal to
, which will be derived in Lemma 1 in Section 5.2.
. Note that is always greater than or equal to
, which will be derived in Lemma 1 in Section 5.2.
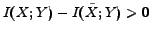 means there is some loss in mutual information after categorization. To sum up, a good categorization should keep the mutual information between data and features, and minimize the information loss. In other words,
should be close to . Therefore, in the information bottleneck classification setting, the quality of the categorization should be judged by the loss in mutual information between the original instances and categorized instances. The following remark lays our the objective function formally.
means there is some loss in mutual information after categorization. To sum up, a good categorization should keep the mutual information between data and features, and minimize the information loss. In other words,
should be close to . Therefore, in the information bottleneck classification setting, the quality of the categorization should be judged by the loss in mutual information between the original instances and categorized instances. The following remark lays our the objective function formally.
In the information bottleneck (IB) classification setting, a qualified hypothesis
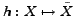 approximately satisfies:
approximately satisfies:
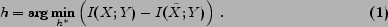
2 Applying to Cross-Language Classifier
Before the formal problem formulation, we would like to present a brief idea to address the cross-language classification problem by information bottleneck. Suppose we have the union set of English and Chinese Web pages, is the set of words contained in , and stands for the class labels.
It is observed that there is a common part of English and Chinese web pages, which share the similar semantic information. This observation inspired our work. If the texts are put through the ``bottleneck'', the labeled data (English Web pages) will, to some extent, guide the classification on Chinese pages by encoding the common part into the same codewords. It is because that during the information theoretic compression, IB tends to encode the similar pages into the same code (label) in that it can reduce the code length without loss of much information. If one Chinese page is in the common part, i.e. similar to a labeled English page, this page will be classified into the same category as that of the English one.
To summarize, it is noted that cross-language Web pages are carrying a common part of semantic information. According to the information bottleneck theory, this part of information is expected to help encode similar Web pages in different languages since it is highly relevant information to class labels and also is contained in the Web pages in both languages. Therefore, it is clear that the information bottleneck technique is suitable to address the cross-language classification problem.
5 Cross-Language Classifier via
Information Bottleneck
In this section, the problem is carefully formulated and an objective function is proposed to build a classification model. The classification algorithm (IB) is then presented. Also, the convergence and time complexity are theoretically analyzed.
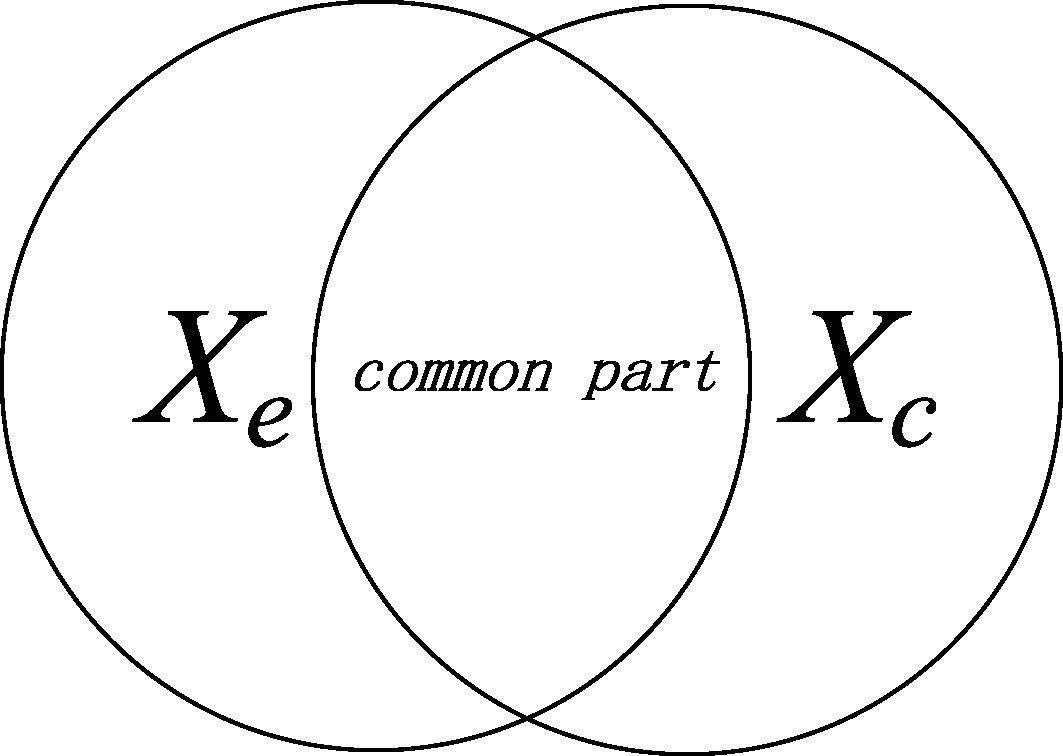
Figure 3: The cross-language classification problem. Here,  is the set of the Web pages in English and
is the set of the Web pages in English and 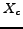 is the set of the Web pages in Chinese. It is assumed that there is some common part between English and Chinese Web pages.
is the set of the Web pages in Chinese. It is assumed that there is some common part between English and Chinese Web pages.
Let be the set of the Web pages in English with class labels and be the set of the Web pages in Chinese without labels. Usually, it is assumed that the English Web pages and Chinese Web pages share some common information with each other, as shown in Figure 3. The feature space for is the English words 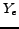 and for is the Chinese words
and for is the Chinese words 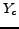 . The objective is, we are trying to classify the pages in into
. The objective is, we are trying to classify the pages in into 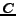 , the predefined class label set, which is the same for the pages in . To sum up, labeled training documents are available only in one language, and we want to estimate a hypothesis
, the predefined class label set, which is the same for the pages in . To sum up, labeled training documents are available only in one language, and we want to estimate a hypothesis
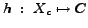 which classifies documents written in another language. This is called cross-language text classification.
which classifies documents written in another language. This is called cross-language text classification.
In contrast to traditional text categorization, where the training and test pages are in the same language, cross-language text classification requires that the training and test data should be unified into one single feature space. Otherwise, it is not possible for existing machine learning techniques to get the results. The most common way is to translate the pages in one language into the other one. However, it is noticed that this common approach will bring the error and bias for further classification. Linguistically speaking, machine translation technique is far from satisfactory. What is worse, the simple translation preprocessing does not give the accurate information. The topics of original data may drift under translation. Empirically, these claims were justified. The experimental details are presented in Section 6.1.2.
2 Objective Function
As stated in Section 4.2, we propose to address the problems via the information bottleneck technique. The test Web page set is translated to English, denoted as 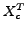 . Let
. Let
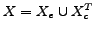 , as the original signal for the bottleneck. The class label set is the output of the bottleneck . is referred to the features of all the documents. To fully utilize the common part for classification, we defined the objective function as
, as the original signal for the bottleneck. The class label set is the output of the bottleneck . is referred to the features of all the documents. To fully utilize the common part for classification, we defined the objective function as
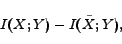 |
(4) |
which is exactly the objective function in Remark 1. Note that
is always non-negative, which will be derived by Lemma 1. Based on Remark 1, the objective function value should be minimized, since we aim to draw
close to .
Before proposing the optimization approach for minimizing the objective function, we first define some notations used in subsequent analysis.
Definition 1 We use
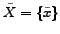 to denote a categorization of
to denote a categorization of 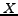 for the hypothesis
for the hypothesis  , where
, where
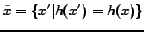 . Clearly,
. Clearly, 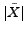 is equal to
is equal to 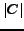 , since maps the instances in to the class-labels in
, since maps the instances in to the class-labels in 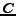 .
.
Definition 2 The joint probability distribution of and 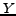 under the categorization is denoted by
under the categorization is denoted by
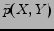 , where
, where
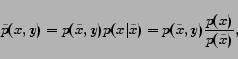 |
(5) |
where
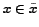 , and
, and
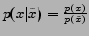 since totally depends on
since totally depends on 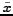 .
.
In the following, we will transform the objective function in Equation (5) into another representation by KL-divergence [14].
Lemma 1 For a fixed categorization , we can write the objective function in Equation (5) as
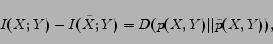 |
(6) |
where
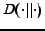 is the KL-divergence defined as Equation (3).
is the KL-divergence defined as Equation (3).
Note that, based on the non-negativity of KL-divergence, the objective function
should always be non-negative.
From Equation (7), it is found that the loss in mutual information in the objective function equals to the KL-divergence between and
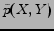 . To minimize the objective function in Equation (5), we need only to find a categorization which minimizes the KL-divergence value
. To minimize the objective function in Equation (5), we need only to find a categorization which minimizes the KL-divergence value

However, the objective function in Equation (7) is in the joint probability form that is difficult to be optimized. Now, we are to rewrite it into a conditional probability form, which will facilitate our algorithm to reduce the objective function value.
Lemma 2 The objective function in Equation (7) can be expressed by a conditional probability form as
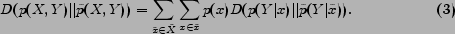
Lemma 2 gives a straightforward explanation for cross-language text classification via the information bottleneck technique. If one Chinese page is more similar to the English pages of one class , i.e. the distance
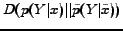 is the smallest, assigning this page to will lead to a lower value of the objective function. Then it is desirable during the optimization process, which means the common part between English and Chinese Web pages work as stated in Section 4.2.
is the smallest, assigning this page to will lead to a lower value of the objective function. Then it is desirable during the optimization process, which means the common part between English and Chinese Web pages work as stated in Section 4.2.
Also, Lemma 2 provides an alternative way to reduce the objective function value. From Equation (9), we know that minimizing
for a single instance could reduce the global objective function
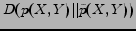 . As a result, if we iteratively optimize the corresponding
for each instance , the objective function will decrease monotonically. Thus, based on Lemma 2, the information bottleneck cross-language text classification (IB) is derived as in Algorithm 1.
. As a result, if we iteratively optimize the corresponding
for each instance , the objective function will decrease monotonically. Thus, based on Lemma 2, the information bottleneck cross-language text classification (IB) is derived as in Algorithm 1.
![\begin{algorithm} % latex2html id marker 381 [h] \caption{The Cross-Language Tex... ... $h^{(N)}$ as the final hypothesis $h_f$. \end{algorithmic}\par \end{algorithm}](www2008camera-img61.png)
In Algorithm 1, in each iteration, the algorithm keeps the prediction labels for the English Web pages unchanged since their true labels are already known, while choosing the best category for each data instance in to minimize the function
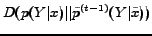 . As we have discussed above, this process is able to decrease the objective function in Equation (7). The whole algorithm is illustrated in Figure 4.
. As we have discussed above, this process is able to decrease the objective function in Equation (7). The whole algorithm is illustrated in Figure 4.
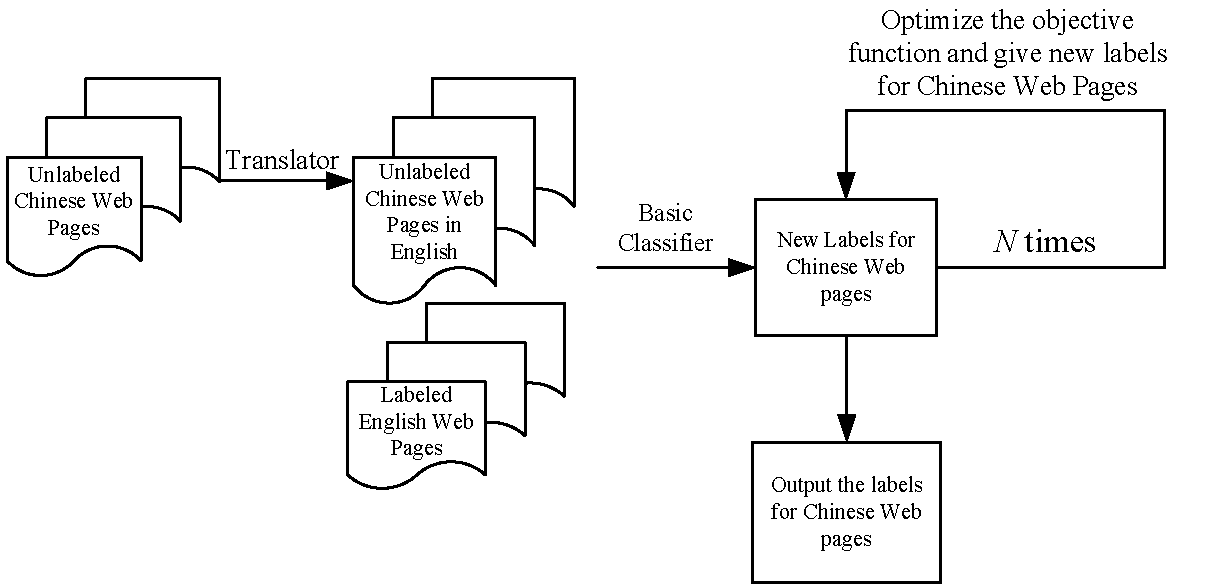
Figure 4: The scheme of the IB-based cross-language classification algorithm.
Since our algorithm IB is iterative, it is necessary to discuss its property of convergence. The following theorem shows that the objective function in our algorithm monotonically decreases, which establishes that the algorithm converges eventually.
Theorem 1 The objective function in Equation (7) monotonically decreases in each iteration of Algorithm IB.
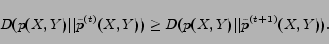 |
(7) |
Note that, although the algorithm is able to minimize the objective function value in Equation (5), it is only able to find a locally minimal one. Finding the global optimal solution is NP-hard. From Theorem 1, we can straightforwardly derived that the algorithm IB converges in a finite number of iterations, since the hypothesis space is finite.
Regarding the computational cost for IB, suppose the non-zeros in is 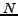 . In each iteration, IB needs to calculate
. In each iteration, IB needs to calculate 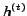 in
in
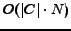 and update
and update
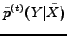 in
in
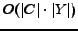 . Therefore, the time complexity of IB is
. Therefore, the time complexity of IB is
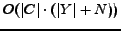 as a result. Usually, is not large and could be considered as a constant, while
as a result. Usually, is not large and could be considered as a constant, while 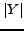 is usually not larger than . Thus, the time complexity of IB is
is usually not larger than . Thus, the time complexity of IB is 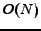 in general. Thus, our algorithm IB has good scalability, and is capable for large data sets.
in general. Thus, our algorithm IB has good scalability, and is capable for large data sets.
6 Experiments
In this section, we evaluate our cross-language classification algorithm based on information bottleneck, and compare our algorithm with several state-of-art supervised and semi-supervised classifiers.
We conduct our evaluation on the Web pages crawled from the Open Directory Project (ODP) [22] during August 2006. Each Web page in ODP was classified by human experts into 17 top level categories (Arts, Business, Computers, Games, Health, Home, Kids and Teens, News, Recreation, Reference, Science, Shopping, Society, Sports, Regional, Adult and World). We removed the Regional category because the Web pages in the Regional category are also in other categories. The Web pages in the Adult have not been crawled by our crawler, because most of them are banned by our internet service provider, and thus the Adult category is not included in our data collection. Moreover, the Web pages in the World category are in the languages other than English. We selected all the Chinese pages from the World category as Chinese test data. For Chinese Web pages, there are also 14 top categories each of which can be mapped to a top category in the English ODP. Therefore, we have 14 categories for both Chinese and English Web pages in this experiments. Figure 1 represents the detailed description for our data collection. From the table, it can be seen that, the number of English labeled Web pages is much larger than that of Chinese ones in ODP, which indicates English labeled Web pages (1,271,106) is much more abundant than Chinese ones (18,243).
Table 1: The descriptions for all the categories in ODP, including Chinese and English ones. Note that, all the Chinese Web pages as well as their category labels were translated into English using Google Translator.
| Category |
Chinese Web Pages |
English Web Pages |
| Arts |
1,942 |
186,307 |
| Business |
6,503 |
203,569 |
| Computers |
1,907 |
102,571 |
| Games |
296 |
39,269 |
| Health |
518 |
47,607 |
| Home |
203 |
23,117 |
| Kids and Teens |
292 |
27,323 |
| News |
359 |
96,510 |
| Recreation |
681 |
77,901 |
| Reference |
2,338 |
48,231 |
| Science |
914 |
75,434 |
| Shopping |
488 |
86,736 |
| Society |
1,481 |
185,466 |
| Sports |
321 |
71,065 |
| Total |
18,243 |
1,271,106 |
Data preprocessing has been applied to the raw data. First, all the Chinese Web pages were translated by Google Translator [1]. Then, we converted all the letters to lower cases, and stemmed the words using the Porter's stemmer [24]. After that, stop words were removed. In order to reduce the size of the feature space, we used a simple feature selection method, document frequency (DF) thresholding [31], to cut down the number of features, and speed up the classification. Based on [31], DF thresholding, which has comparable performance with information gain (IG) or CHI, is suggested since it is simplest with lowest cost in computation. In our experiments, we set the DF threshold to 3. After feature selection, the vocabulary size becomes 512,896.
In order to evaluate our cross-language classifier, we set up eight cross-language classification tasks. Five of them are binary classification tasks, and others are for multiple-class classification. Table 2 presents the detailed composition for each classification task.
Table 2: The composition for each data sets.
| Data Sets |
Categories |
| Games vs News |
Games, News |
| Arts vs Computers |
Arts, Computers |
| Recreation vs Science |
Recreation, Science |
| Computers vs Sports |
Computers, Sports |
| Reference vs Shopping |
Reference, Shopping |
| 3 Categories |
Arts, Computer, Society |
| 4 Categories |
Business, Health, News, Sports |
| 5 Categories |
Games, Home, News, Shopping, Sports |
2 Cross-Language Topic Drift
We extracted the most frequent features in the Chinese and English Web pages for each of the 14 ODP categories, and found the frequent features in the Chinese and English Web pages are quite different, although they share some part. Table 3 presents the top 5 frequent features in the Chinese and English Web pages for each of the 14 ODP categories. We believe there is topic drift between Chinese and English Web pages. For example, there are several Chinese words which are frequently appears in the Chinese Web pages, such as ``qiyuan'', ``mufurong'', ``pingqiu'' and so on. In the Games, ``qiyuan'', one of the famous online game in China, is the most frequent keyword, while it hardly appears in the English Web pages. This is due to the difference in culture between the Chinese and western societies. ``pingqiu'', which means ``draw'' in English, hardly appears in English Web pages, because the translator fails to provide a mapping between ``draw'' and it. The observations demonstrate the claim we made previously that there are two main obstacles for the cross-language classification: one is the difference in topic focus between the two languages; the other is the translation error.
Table 3: The most frequent (stemmed) features in the Chinese and English Web pages for each ODP category. All the Chinese Web pages have already been translated into English using Google Translator.
| Category |
Chinese Web Pages |
English Web Pages |
| Arts |
giotto, tugen, penchant, ashima, banzai |
paean, base, dvdlaser, crew, taglin |
| Business |
congeni, nanci, decre, wallk, darshan |
natstat, kazaa, bcm, aanspreken, wct |
| Computers |
volp, uptim, screenshot, malcolm, datastorag |
volp, easyb, letterhack, grundriss, wsmcafe |
| Games |
qiyuan, vierni, vernier, firstyeargirl, kangderong |
accident, enix, impress, rifl, freeenergynew |
| Health |
neurosyphili, maximowicziana, carboyhdr, podophyllin, interpol |
finespun, stadium, linear, shyamalan, ryder |
| Home |
banlan, xero, bcsahin, mufurong, prestonwood |
machist, evita, beradino, bakk, fudoh |
| Kids and Teens |
head, yangpu, ashaar, geetanjali, urdupoetri |
pact, isch, argo, quem, melanesia |
| News |
uppercut, muham, readjust, pulverul, dovic |
narr, hume, mujer, dude, gif |
| Recreation |
frauenhof, fatehpur, xingyuncao, nakedpoetri, orchha |
behoof, heepster, bonafid, tiltrecord, kapil |
| Reference |
filmcent, pessim, cold, seed, farm |
platitudin, waggon, blankli, dfee, quotearch |
| Science |
applaud, zhouyulin, flask, middlepillar, modarr |
frobozzica, exploratori, forbrydelsen, kashyyk, pallot |
| Shopping |
lcjzl, lashel, aubrac, roozi, ebullit |
scherick, tricia, strewn, caryn, glenda |
| Society |
cass, indispens, buddhist, tahm, trod |
wallpap, hornadai, lafort, obstat, duranczyk |
| Sports |
parama, cow, pingqiu, nesi, shiduotangbei |
shinobi, jumbl, shirt, invert, sould |
Figure 5 shows the instance-feature co-occurrence distribution on the Games vs News data set. In this figure, documents 1 to 484 are from , while documents 485 to 853 are from . Within a data set, or , the documents are ordered by their categories (Games or News). The words are sorted by
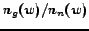 , where
, where 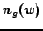 and
and 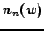 represent the number of word positions
represent the number of word positions 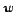 appears in Games and News documents, respectively. From Figure 5, it can be found that the distributions of English and Chinese Web pages are somewhat different, however the figure also shows large commonness exists between the two data sets. The density divergence between two data sets in the figure makes the cross-language classification difficult, because most classification techniques rely on the basic assumption that the training data should be drawn from the same distribution as the test data. However, the common part between the two data sets can help increase the feasibility of the classification.
appears in Games and News documents, respectively. From Figure 5, it can be found that the distributions of English and Chinese Web pages are somewhat different, however the figure also shows large commonness exists between the two data sets. The density divergence between two data sets in the figure makes the cross-language classification difficult, because most classification techniques rely on the basic assumption that the training data should be drawn from the same distribution as the test data. However, the common part between the two data sets can help increase the feasibility of the classification.
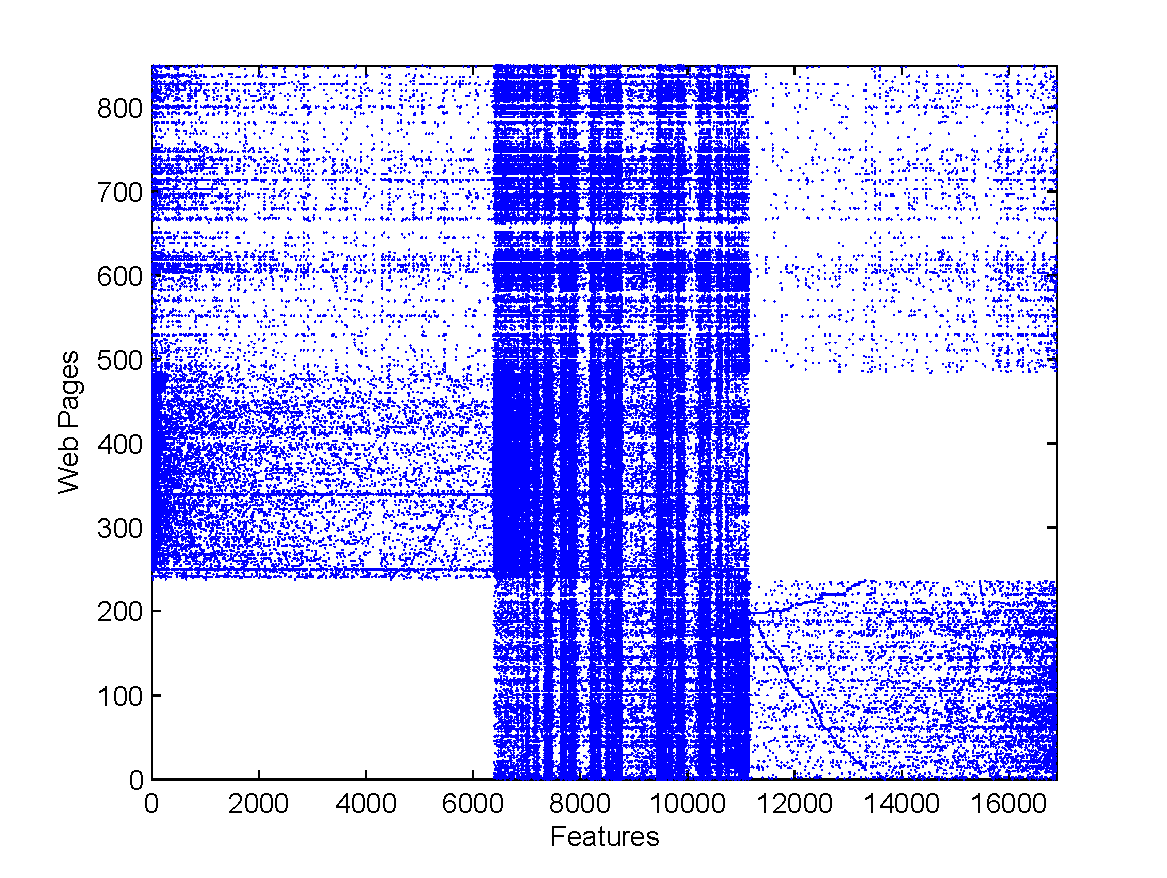
Figure 5: The instance-feature co-occurrence density for the Games vs News data set.
In this experiments, we compare our information bottleneck cross-language classifier (IB) with several state-of-art classification algorithms to show the advantages of our algorithm.
We take the supervised classification algorithms to be the baseline methods. Naive Bayes classifiers (NBC) [17] and support vector machines (SVM) [5] are evaluated in the experiments. They are trained on and tested on . Transductive support vector machines (TSVM) [13] is also introduced as comparison semi-supervised learning methods, which take both labeled and unlabeled for training and for testing.
For implementation details, TF-IDF is used for feature weighting when training support vector machines (SVM) [5] and transductive support vector machines (TSVM) [13]. TF is used for feature weighting when training naive Bayes classifier (NBC) [17] and our information bottleneck based cross-language classification algorithm (IB).
SVM and TSVM are implemented by
 [12] with default parameters (linear kernel). For more details about SVM and TSVM, please refer to [5] and [13]. NBC and IB are implemented by ourselves. The initial categorizations for IB are given by NBC.
[12] with default parameters (linear kernel). For more details about SVM and TSVM, please refer to [5] and [13]. NBC and IB are implemented by ourselves. The initial categorizations for IB are given by NBC.
We now present the classification performance for each comparison methods, and show advantages of our information bottleneck cross-language classifier IB.
The metrics used in this experiments are macro-average precision, recall and 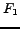 -measure. Let
-measure. Let 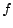 be the function which maps from document
be the function which maps from document 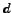 to its true class label
to its true class label 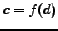 , and be the function which maps from document to its prediction label
, and be the function which maps from document to its prediction label 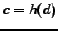 given by the classifiers. The macro-average precision
given by the classifiers. The macro-average precision 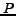 and recall
and recall 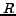 are defined as
are defined as
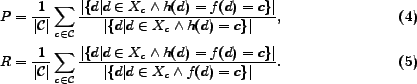
-measure is a harmonic mean of precision and recall defined as follows
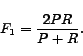 |
(8) |
Table 4 presents the performance on each binary classification data set given by NBC, SVM, TSVM and our algorithm IB. The implementation details of the algorithms have already been presented in the last subsection. The evaluation metrics are macro-average precision, recall and -measure, of which we have just given the definitions. From the table, we can see that IB significantly improves the other three methods. Although SVM and TSVM is slightly better than IB on the Arts vs Computers data set, IB is still comparable. But, on some of the other data sets, e.g. Computers vs Sports and Reference vs Shopping, both SVM and TSVM fail, while IB is much better than the two discriminative methods. In addition, NBC is always worse than IB, but never fails a lot. In average, IB gives the best performance in all the three evaluation metrics.
Table 5 presents the performance on each multiple-class classification data set given by NBC and our algorithm IB. SVM and TSVM are not included here because they are designed for binary classification, and cannot cope well with the multiple-class classification problem. In this table, IB still gives significant improvements against the baseline method NBC. Therefore, we believe our algorithm IB is not only effective for English-Chinese cross-language classification, but also extensible for multiple-class classification.
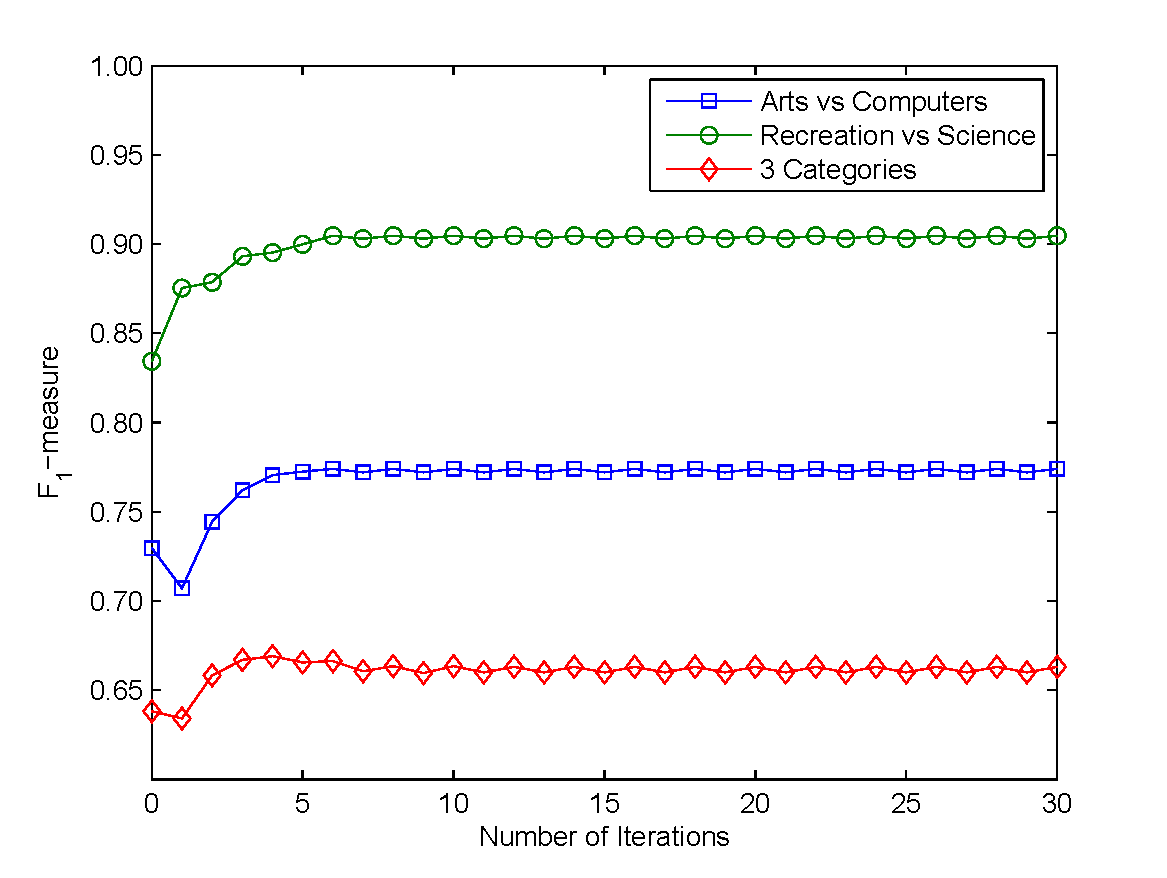
Figure 6: The -measure curves after each iterations on three data sets Arts vs Computers, Recreation vs Science and 3 Categories respectively.
Since our algorithm IB is an iterative algorithm, an important issue for IB is the convergence property. Theorem 1 has already proven the convergence of IB theoretically. Now, let us empirically show the convergence property of IB. Figure 6 shows the test error rate curves as functions for each iteration on three data sets, Arts vs Computers, Recreation vs Science and 3 Categories. From the figure, it can be seen that IB always achieves almost convergence points within 10 iterations. This indicates that IB converges very fast. We believe that 10 iterations is empirically enough for IB.
7 Conclusions and Future Work
The tremendous growth of the World Wide Web in China has raised the need for classifying and organizing Chinese Web space via classification techniques. In this paper we put forward a technique for the Chinese Web mining task to exploit the abundant labelled information in English. In particular, we have developed a novel method known as the information bottleneck technique to address the topic drift and different feature-space problems across two languages. Our method brings out a common part between the Chinese and English Web pages, which can be used to encode similar pages in different languages into the same codewords (class labels). An iterative algorithm is presented to optimize the objective function and therefore solve this problem. The experimental results show that our method can effectively improve existing methods in general, including five binary and three multi-class problems.
To extend our work, we wish to modify our method to achieve a global optimal value. It is also interesting to conduct more experiments in other language pair (e.g. French vs English, which does not suffer the word segmentation problem). Moreover, our method has the potential to be effective for the cross-language information retrieval problem.
Qiang Yang would like to thank the support of Hong Kong RGC Grant 621307. We also thank the anonymous reviewers for their great helpful comments.
REFERENCES
[1] Google translator. http://www.google.com/language_tools.
[2] A. Banerjee, I. Dhillon, J. Ghosh, S. Merugu, and D. S. Modha. A generalized maximum entropy approach to bregman co-clustering and matrix approximation. In Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining , pages 509-514, 2004.
[3] N. Bel, C. Koster, and M. Villegas. Cross-Lingual Text Categorization. Proceedings ECDL , 200:126-139, 2003.
[4] A. Blum and T. Mitchell. Combining labeled and unlabeled data with co-training. In Proceedings of the Eleventh Annual Conference on Computational Learning Theory , pages 92-100, 1998.
[5] B. E. Boser, I. Guyon, and V. Vapnik. A training algorithm for optimal margin classifiers. In Proceedings of the Fifth Annual Workshop on Computational Learning Theory , pages 144-152, 1992.
[6] T. M. Cover and P. E. Hart. Nearest neighbor pattern classification. IEEE Transactions on Information Theory , 13:21-27, 1967.
[7] T. M. Cover and J. A. Thomas. Elements of information theory . Wiley-Interscience, New York, NY, USA, 1991.
[8] M. Day, C. Ong, and W. Hsu. Question Classification in English-Chinese Cross-Language Question Answering: An Integrated Genetic Algorithm and Machine Learning Approach. In Proceedings of the 2007 IEEE International Conference on Information Reuse and Integration , pages 203-208, 2007.
[9] I. S. Dhillon, S. Mallela, and R. Kumar. Enhanced word clustering for hierarchical text classification. In Proceedings of the Eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining , pages 191-200, 2002.
[10] I. S. Dhillon, S. Mallela, and D. S. Modha. Information-theoretic co-clustering. In Proceedings of the Ninth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining , 2003.
[11] A. Gliozzo and C. Strapparava. Cross language Text Categorization by acquiring Multilingual Domain Models from Comparable Corpora. Proc. of the ACL Workshop on Building and Using Parallel Texts (in conjunction of ACL-05) , 2005.
[12] T. Joachims. SVM light. Software available at http://svmlight.joachims.org .
[13] T. Joachims. Transductive inference for text classification using support vector machines. In Proceedings of the Sixteenth International Conference on Machine Learning , pages 200-209, 1999.
[14] S. Kullback and R. A. Leibler. On information and sufficiency. Annals of Mathematical Statistics , 22(1):79-86, 1951.
[15] K. Lang. Newsweeder: Learning to filter netnews. In Proceedings of the Twelfth International Conference on Machine Learning , pages 331-339, 1995.
[16] D. D. Lewis. Reuters-21578 test collection. http://www.daviddlewis.com/.
[17] D. D. Lewis. Representation and learning in information retrieval . PhD thesis, Amherst, MA, USA, 1992.
[18] Y. Li and J. Shawe-Taylor. Advanced learning algorithms for cross-language patent retrieval and classification. Information Processing and Management , 43(5):1183-1199, 2007.
[19] Y. Liu, Y. Fu, M. Zhang, S. Ma, and L. Ru. Automatic search engine performance evaluation with click-through data analysis. Proceedings of the 16th international conference on World Wide Web , pages 1133-1134, 2007.
[20] X. Ni, G. Xue, X. Ling, Y. Yu, and Q. Yang. Exploring in the weblog space by detecting informative and affective articles. Proceedings of the 16th international conference on World Wide Web , pages 281-290, 2007.
[21] K. Nigam, A. K. McCallum, S. Thrun, and T. Mitchell. Text classification from labeled and unlabeled documents using em. Machine Learning , 39(2-3):103-134, 2000.
[22] ODP. Open directory project. http://www.dmoz.com/.
[23] J. Olsson, D. Oard, and J. Hajic. Cross-language text classification. Proceedings of the 28th annual international ACM SIGIR conference on Research and development in information retrieval , pages 645-646, 2005.
[24] M. F. Porter. An algorithm for suffix stripping. Program , 14(3):130-137, 1980.
[25] J. R. Quinlan. C4.5: Programs for Machine Learning . Morgan Kaufmann, 1993.
[26] L. Rigutini, M. Maggini, and B. Liu. An em based training algorithm for cross-language text categorization. In Proceedings of the 2005 IEEE/WIC/ACM International Conference on Web Intelligence , pages 529-535, 2005.
[27] N. Slonim. The Information Bottleneck: Theory and Applications. Unpublished doctoral dissertation, Hebrew University, Jerusalem, Israel , 2002.
[28] N. Slonim and Y. Weiss. Maximum likelihood and the information bottleneck. Advances in Neural Information Processing Systems , 15, 2002.
[29] N. Tishby, F. C. Pereira, and W. Bialek. The information bottleneck method. In Proceedings of the Thirty-seventh Annual Allerton Conference on Communication, Control and Computing , pages 368-377, 1999.
[30] Y.-C. Wu, K.-C. Tsai, and J.-C. Yang. Two-pass named entity classification for cross language question answering. In Proceedings of NTCIR-6 Workshop Meeting , pages 168-174, 2007.
[31] Y. Yang and J. O. Pedersen. A comparative study on feature selection in text categorization. In Proceedings of Fourteenth International Conference on Machine Learning , pages 144-152, 1997.
[32] X. Zhu. Semi-supervised learning literature survey. Technical Report 1530, University of Wisconsin-Madison, 2006.
In this appendix, we provide the detailed proof to Lemmas 1 and 2, and Theorem 1.

Footnotes
- 1
- According to the report by CNNIC in January 2007: http://www.cnnic.net.cn/uploadfiles/pdf/2007/2/13/95522.pdf
 Gui-Rong Xue
Gui-Rong Xue Yong Yu
Yong Yu