2
H.3.6INFORMATION SYSTEMSLibrary Automation[Large text archives] H.3.4INFORMATION SYSTEMSSystems and Software[Distributed systems] C.5.5COMPUTER SYSTEM IMPLEMENTATIONServers
Design, Management, Performance
System architecture, Data model, Scalability
The introduction of a modular CiteSeer architecture offers a great opportunity to exploit newly emerged web technologies to improve the system's performance and configurability. Accordingly, the system will become more powerful and robust: more simultaneous transactions can be supported; and tasks like system monitoring and logging will be faciliated. The next generation CiteSeer is far more than a debugged version of CiteSeer. It is also a system with new elements: new services, new resources, and new data models, all working in a new framework. Our design goal is to setup a new architecture which can be scalable, flexible, self-adaptive and user-oriented.
CiteSeer![]() is built
upon a new data model which has the following new features:
is built
upon a new data model which has the following new features:
Extended Data Models: Expanding the old
document-centric approach, CiteSeer![]() introduces author and venue records into the
system. These records are no longer considered as metadata
belonging to a document, but as peer digital objects that
are linked to documents as well as to each other.
introduces author and venue records into the
system. These records are no longer considered as metadata
belonging to a document, but as peer digital objects that
are linked to documents as well as to each other.
Virtual Documents: Metadata of an existing paper can be inferred from various information sources, such as its citations and researcher publication lists. It is not rare to find the corresponding document has not been retrieved by the system. To address such cases, we propose the notion of virtual documents, which are built upon incomplete metadata and act as a placeholder of the document.
Digital Objects: To make CiteSeer![]() more flexible
and extensible in terms of storage types and service types, the
notion of digital objects[2] is introduced into the
system, separating physical storage from service access. As such,
a level of abstraction can be defined on top of the physical
storage. Actual physical storage can be distributed across
multiple machines and sites.
more flexible
and extensible in terms of storage types and service types, the
notion of digital objects[2] is introduced into the
system, separating physical storage from service access. As such,
a level of abstraction can be defined on top of the physical
storage. Actual physical storage can be distributed across
multiple machines and sites.
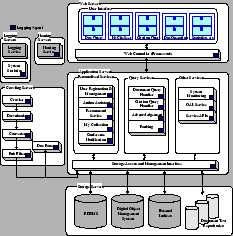
Based on the new data model, CiteSeer![]() will have a new modular system architecture
to overcome the limitations previously described. Figure 1 gives an overview of the new architecture.
Basically, the system comprises three layers:
will have a new modular system architecture
to overcome the limitations previously described. Figure 1 gives an overview of the new architecture.
Basically, the system comprises three layers:
Storage Layer: The storage layer handles the management
of and access to locally stored data objects of
CiteSeer![]() . These
objects are maintained by a digital object management system.
Each digital object is accompanied by a description file that
contains the metadata of the object.
. These
objects are maintained by a digital object management system.
Each digital object is accompanied by a description file that
contains the metadata of the object.
Application Layer: The application layer is the
collection of the function modules and services in
CiteSeer![]() , which
includes naming service, logging service, crawling service, query
handling service, indexing service, personalized service,
etc.
, which
includes naming service, logging service, crawling service, query
handling service, indexing service, personalized service,
etc.
User Interface Layer: This layer provides an
abstraction for the web interface of CiteSeer![]() by acting as a
gateway between the user interface and application modules and
gives flexibility to update the application logic without
worrying about the user interface as well as providing
personalized services to users.
by acting as a
gateway between the user interface and application modules and
gives flexibility to update the application logic without
worrying about the user interface as well as providing
personalized services to users.
Under the proposed architecture, CiteSeer![]() continues to
support its existing services with more user-friendly interfaces
and application-accessible APIs. New services and features are
added into the system as well.
continues to
support its existing services with more user-friendly interfaces
and application-accessible APIs. New services and features are
added into the system as well.
CiteSeer-Specific Services: These services are specific to CiteSeer and would provide value added if made available on the semantic web. These services enable the processing of citations and the navigation through those citations. This set of services includes the metadata extraction service, citation graph service, indexing service, metadata service, electronic repository service, electronic conversion service, duplicate identification service, etc. They are described in more detail in previous work[4].
Acknowledgement Extraction: We have developed an algorithm for automatic acknowledgement extraction in order to extend the native extraction capabilities of CiteSeer [1]. This initial algorithm identifies acknowledging text passages and extracts the names of acknowledged entities. This data is stored in an auxiliary index alongside CiteSeer's traditional indices with special bridges created to integrate the new acknowledgement data into the existing CiteSeer system. This integration represents a structural shift in entity relationship handling in CiteSeer, requiring an extension of the traditional author-document and document-document relationships to reified relations between entities and documents, flexibly modeling the roles of entities within the data.
Distributed Usage Logging Service: An XML based
description language for information retrieval system usage logs
is introduced in CiteSeer![]() by modeling a user-system interaction
ontology. The language encompasses rich semantic descriptions of
the events being logged such as dependency between successive
actions. The logging service architecture of CiteSeer
by modeling a user-system interaction
ontology. The language encompasses rich semantic descriptions of
the events being logged such as dependency between successive
actions. The logging service architecture of CiteSeer![]() reflects the
idea of detaching the logging service from the target system such
that is is no longer the duty of each module in the system to
write document usages. Instead, an independently running logging
service collects and manages logs from every module.
reflects the
idea of detaching the logging service from the target system such
that is is no longer the duty of each module in the system to
write document usages. Instead, an independently running logging
service collects and manages logs from every module.
MyCiteSeer: For an ACI system like CiteSeer, it becomes
increasingly difficult for users to find information that
accurately matches their needs with the growth of the number of
stored documents. In such scenarios, a user's query context, as
well as his personal interests, can be taken into consideration
in answering a user's query and effectively filter the results.
To support personalized services, CiteSeer![]() provides registration mechanism to profile
users. The new logging framework and log schema are user-aware
and session-aware, by which data mining algorithms and
recommendation techniques can be applied.
provides registration mechanism to profile
users. The new logging framework and log schema are user-aware
and session-aware, by which data mining algorithms and
recommendation techniques can be applied.