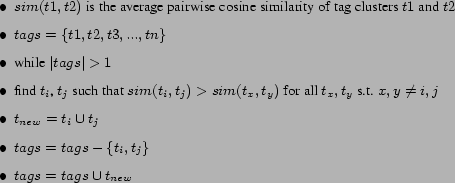Christopher H. Brooks
Computer Science Department
University of San Francisco
2130 Fulton St.
San Francisco, CA 94117-1080
Nancy Montanez
Computer Science Department
University of San Francisco
2130 Fulton St.
San Francisco, CA 94117-1080
Tags have recently become popular as a means of annotating and organizing Web pages and blog entries. Advocates of tagging argue that the use of tags produces a 'folksonomy', a system in which the meaning of a tag is determined by its use among the community as a whole. We analyze the effectiveness of tags for classifying blog entries by gathering the top 350 tags from Technorati and measuring the similarity of all articles that share a tag. We find that tags are useful for grouping articles into broad categories, but less effective in indicating the particular content of an article. We then show that automatically extracting words deemed to be highly relevant can produce a more focused categorization of articles. We also show that clustering algorithms can be used to reconstruct a topical hierarchy among tags, and suggest that these approaches may be used to address some of the weaknesses in current tagging systems.
H.3.1Information SystemsContent Analysis and Indexing
H.3.3Information SystemsSearch and Retrieval
Experimentation, Algorithms
In the past few years, weblogs (or, more colloquially, blogs) have emerged as a means of decentralized publishing; they have successfully combined the accessibility of the Web with an ease-of-use that has made it possible for large numbers of people to quickly and easily disseminate their opinions to a wide audience. Blogs have quickly developed a large and wide-reaching impact, from leaking the details of upcoming products, games, and TV shows to helping shape policy to influencing U.S. Presidential elections.
As with any new source of information, as more people begin blogging, tools are needed to help users organize and make sense of all of the blogs, bloggers and blog entries in the blogosphere (the most commonly-used term for the space of blogs as a whole). One recently popular phenomenon in the blogosphere (and in the Web more generally) that addresses this issue has been the introduction of tagging. Tags are collections of keywords that are attached to blog entries, ostensibly to help describe the entry. While tagging has become very popular, and tags can be found on many popular blogs, there has not been (to our knowledge) much analysis devoted to the question of whether tags are an effective organizational tool for blogs, what functions tags are well suited for, or the broader question of how tags can benefit authors and readers of blogs.
In this paper, we discuss some initial experiments that aim to determine what tasks are suitable for tags, how blog authors are using tags, and whether tags are effective as an information retrieval mechanism. We examine blog entries indexed by Technorati and compare the similarity of articles that share tags to determine whether articles that have the same tags actually contain similar content. We compare the similarity of articles that share tags to clusters of randomly-selected articles and also to clusters of articles that share most-relevant keywords, as determined using TFIDF. We find that tagging seems to be most effective at placing articles into broad categories, but is less effective as a tool for indicating an article's specific content. We speculate that this is in part due to tags' relatively weak representational power. We then show how clustering algorithms can be used with existing tags to construct a hierarchy of tags that looks very much like those created by a human, and suggest that this may be a solution to the argument between advocates of handbuilt taxonomies and supporters of folksonomies and their emergent meaning. We then conclude with a discussion of future work, focusing on increasing the expressivity of tags without losing their ease of use.
Tags are keywords that can be assigned to a document or object as a simple form of metadata. Typically, users do not have the ability to specify relations between tags. Instead, they serve as a set of atomic symbols that are associated with a document. Unlike the sorts of schemes traditionally used in libraries, in which users select keywords from a predefined list, a user can choose any string to use as a tag.
The idea of tagging is not new; photo-organizing tools have had this for years, and HTML has had the ability to allow META keywords to describe a document since HTML 2.0 [3] in 1996. However, the idea of using tags to annotate entries has recently become quite popular within the blogging community, with sites like Technorati1 indexing blogs according to tags, and sites like Furl2 and Delicious 3 providing users with the ability to assign tags to web pages and, most importantly, to share these tags with each other. Tags have also proved to be very popular in the photo-sharing community, with Flickr4 being the most notable example.
This idea of sharing tags leads to a concept known as ``folksonomy'' [11,9], which is intended to capture the notion that the proper usage or accepted meaning of a tag is determined by the practicing community, as opposed to being decreed by a committee. Advocates of folksonomy argue that allowing the meaning of a tag to emerge through collective usage produces a more accurate meaning than if it was defined by a single person or body. Advocates of folksonomies as an organizational tool, such as Quintarelli [9], argue that, since the creation of content is decentralized, the description of that content should also be decentralized. They also argue that centrally-defined, hierarchical classification schemes are too inflexible and rigid for application to classifying Web data (in particular blogs), and that a better approach is to allow the ``meaning'' of a tag to be defined through its usage by the tagging community. This, it is argued, provides a degree of flexibility and fluidity that is not possible with an agreed-upon hierarchical structure, such as that provided by the Library of Congress' system for cataloging books.
To some extent, the idea of folksonomy (which is an argument for subjectivity in meaning that has existed in the linguistics community for years) is distinct from the particular choice of tags as a representational structure, although in practice the concepts are often conflated. There's no a priori reason why a folksonomy must consist entirely of a flat space of atomic symbols, but this point is typically contested by tagging advocates. Quintarelli [9] and Mathes [7] both argue that a hierarchical representation of topics does not reflect the associative nature of information, and that a hand-built taxonomy will likely be too brittle to accurately represent users' interests. As to the first point, we would argue that there is no conflict between indicating subclass/superclass relationships and allowing for associative relations, as can be seen in representation schemes such as Description Logic [1]. We would also point out that the representational power of schemes such as Description Logic goes well beyond tree-structured parent-child relationships, and is capable of expressing complex relationships between data. With respect to the brittleness and lack of usability of human-constructed ontologies, one contribution of this paper is a demonstration that a hierarchical structure which seems to match that created by humans can in fact be inferred from existing tags and articles. This may imply that folksonomies and traditional structured representations are not so opposed after all; rather, tags are a first step in helping an author or reader to annotate her information. Automated techniques can then be applied to better categorize specific articles and relate them more effectively to other articles.
This discussion of tags and folksonomy highlights an interesting challenge to the traditional research community when studying subjects such as blogs: much of the discussion over the advantages and disadvantages of tags and folksonomy has taken place within the blogosphere, as opposed to within peer-reviewed conferences or journals. For example, the Quintarelli, Mathes, and Shirky articles cited above all exist only as blog entries or web pages, and yet are widely cited in discussions of folksonomy. The blogosphere has the great advantage of allowing this discussion to happen quickly and provide a voice to all interested participants, but it also presents a difficult challenge to researchers in terms of properly evaluating and acknowledging contributions that have not been externally vetted. For example, a traditional function of the peer review process is to ensure that authors are aware of related work that is relevant to their results. As of yet, no such function exists in the blogosphere. There is also a risk that the discussion can become balkanized; authors within the blogosphere may be more likely to reference other blogs or online works, whereas authors of journal or conference papers will be more inclined to cite papers with ``traditional'' academic credentials. One goal of this paper is begin to create a bridge between these communities and move some of the discussion regarding tagging and folksonomies into the traditional academic publishing venues.
Tags, in the sense that they are used in Technorati and Delicious, are propositional entities; that is, they are symbols with no meaning in the context of the system apart from their relation to the documents they annotate. It is not possible in these systems to describe relationships between tags (such as `opposite', `similar', or `superset') or to specify semantics for a tag, apart from the fact that it has been assigned to a group of articles. While this would seem like a very weak language for describing documents, tagging advocates point to its ease of use as a factor in the adoption of tagging. Tagging advocates argue that a less-powerful but widely used system such as tagging provides this collaborative determination of meaning, and is superior to more powerful but less-widely-used systems (the RDF vision of the Semantic Web is typically offered as an alternative, often in a straw-man sort of way). Tagging advocates also argue that any externally-imposed set of hierarchical definitions will be too limiting for some users, and that the lack of structure provides users with the ability to use tags to fit their needs. This presents a question: what needs are tags well-suited to address?
In this paper, we focus on the issue of tags as a means of annotating and categorizing blog entries. Blog entries are a very different domain from photos or even webpages. Blog entries are more like ``traditional'' documents than webpages; they typically have a narrative structure, few hyperlinks, and a more ``flat'' organization, as opposed to web pages, which often contain navigational elements, external links, and other markup that can help to automatically extract information about a document's content or relevance. As a result, tags are potentially of great value to writers and readers of blogs.
Technorati5 is a search engine and aggregation site that focuses on indexing and collecting all of the information in the blogosphere. Users can search for blog entries containing specific keywords, entries that reference particular URLs, or (most relevant to our work) entries that have been assigned specific tags.
Technorati also provides a RESTful [6] API that allows programmatic
access to their data, including the ability to find the top
![]() tags, find all articles that
have been assigned a particular tag, or all blogs that link to a
particular URL. It is precisely this ability to access all blog
entries that use a given tag that makes the analysis in this
paper possible.
tags, find all articles that
have been assigned a particular tag, or all blogs that link to a
particular URL. It is precisely this ability to access all blog
entries that use a given tag that makes the analysis in this
paper possible.
We are particularly interested in determining what uses tags have. This question can take two forms: first, for what tasks are tags well-suited, and second, what tasks do users want to do with tags? In this paper we will focus on the first question.
It is worth a brief digression to present our anecdotal observations about how tags are used empirically. There seem to be three basic strategies for tagging: annotating information for personal use, placing information into broadly defined categories, and annotating particular articles so as to describe their content.
Figure 1 contains a list of the top 250 tags used by blog writers to annotate their own entries, collected from Technorati on October 6, 2005. Examining this list immediately points out several challenges to users of tags and designers of tagging systems. First, there are a number of cases where synonyms, pluralization, or even misspelling has introduced the ``same'' tag twice. For example, ``meme'' and ``memes'', ``Pasatiempos'' and ``Passatempos'', or (more difficult to detect automatically) ``Games'' and ``Juegos''. It could be argued that a next-generation tagging system should help users avoid this sort of usage.
In addition, many of the tags are not in English. This was an issue that we had not anticipated, but which is very significant to the experiments discussed below. Since we analyze document similarity using statistical estimates of word frequency, including non-English documents could potentially skew our results.
Finally, it seems clear that many users seem to use tags simply as a means to organize their own reading and browsing habits. This can be seen by the usage of tags such as ``stuff'', ``Whatever'', and ``others.'' Looking at tags in Delicious produces similar results; along with tags indicating a web page's topic are tags such as ``toRead'', ``interesting'', and ``todo''. While this may be a fine use of tags from a user's point of view, it would seem to conflict with the idea of using tags to build a folksonomy; there's no shared meaning that can emerge out of a tag like ``todo.''
Figure 1 provides some evidence that many users seem to use tags as a way of broadly categorizing articles. This can be seen from the popularity of Technorati tags such as ``Baseball'', ``Blogs'', ``Fashion'', ``Funny'', and so on. While there is clearly great utility in being able to group blog entries into general categories, this presents a question: do tags provide users with the necessary descriptive power to successfully group articles into sets?
Finally, one of the greatest potential uses of tags is as a means for annotating particular articles and indicating their content. This is the particular usage of tags that we are interested in: providing a mechanism for the author of a blog entry to indicate what a particular article is about. Another way to think about this is to ask if a tag is able to provide a description that is sufficient to retrieve that article from a larger collection at a later date. Looking at the list of most popular tags, it would appear that there are not many tags that focus specifically on the topic of a particular article. However, it may be the case that less popular tags are better at describing the subject of specific articles; we examine this hypothesis below.
The first question we were interested in addressing in this paper was how well tags serve as a tool for clustering similar articles. In order to test this, we collected articles from Technorati and compared them at a syntactic level.
As mentioned above, one unanticipated wrinkle was that many of the blog entries are not in English. Since we analyzed document similarity based on weighted word frequency, it was important that non-English documents be removed, since we used an English-language corpus to estimate the general frequency of word occurrence. Our first naive approach was to use WordNet [8] to determine whether a tag was a valid English word, and to discard tags with non-English tags. Unfortunately, that approach was ineffective, since many technical or blogging-related terms, such as ``iPod'', ``blogging'', ``metroblogging'', and ``linux'', are not in WordNet. Our current approach has been to construct an auxiliary ``whitelist'' of approximately 200 tags that are not in WordNet, but are in common usage in conjunction with English-language articles on Technorati.
We realize that this is only a stopgap measure - there are undoubtedly tags that are not in WordNet that are not on our whitelist, and it is certainly possible for someone to use an English tag to annotate an article written in Spanish. We are currently experimenting with an N-gram-based approach [4] to classifiying documents based on language. /pagebreak
Our fundamental approach was to group documents that share tags into clusters and then compare the similarity of all documents within a cluster. Our hypothesis was that a cluster of documents that shared a tag should be more similar than a randomly selected set of documents. As a benchmark, we also compared clusters of documents labeled as similar by an external source. Finally, we constructed tags automatically by extracting relevant keywords, and used these tags to construct clusters. This was intended to tell us whether humans did a better job of categorizing articles than automated techniques.
We began by collecting the 350 most popular tags from Technorati. For each tag, we then collected the 250 most recent articles that had been assigned this tag. HTML tags and stop words were removed, and a TFIDF [10] score was computed for each remaining word for each article using the following formula:
Where
![]() indicates the
number of times that word occurs in the blog article being
processed. The second term in the formula provides an estimate of
how common a word is in general usage. To compute this, a corpus
of 8000 web pages were selected at random, and stop words and
HTML tags removed.
indicates the
number of times that word occurs in the blog article being
processed. The second term in the formula provides an estimate of
how common a word is in general usage. To compute this, a corpus
of 8000 web pages were selected at random, and stop words and
HTML tags removed. ![]() indicates how frequently a word appears in that corpus. This will
cause commonly-used words to have a very low TFIDF score, and
rare words to have a high TFIDF score.
indicates how frequently a word appears in that corpus. This will
cause commonly-used words to have a very low TFIDF score, and
rare words to have a high TFIDF score.
Once we have a TFIDF score for each word in each article, we can construct clusters, one per tag, where a cluster contains a vector for each article bearing that tag.
For each cluster corresponding to a tag, we then computed the
average pairwise cosine similarity [2] of all articles in each
cluster ![]() , using the following
equation:
, using the following
equation:
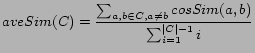 |
where
![$\displaystyle cosSim(A,B) = \frac{\sum_{w \in A \cup B}A[w] B[w]}{\sqrt{\sum_{v \in A}A[v]\sum_{v \in B} B[v]}}$](529-brooks-img8.png) |
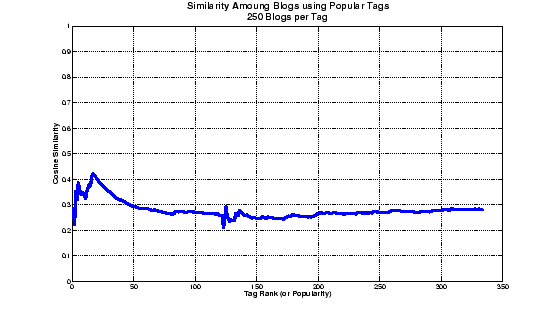
The results of this experiment can be seen in Figure 2.
Figure 2 shows the rank order of
tags on the ![]() axis, with the most
popular tag at the left, and cosine similarity on the
axis, with the most
popular tag at the left, and cosine similarity on the ![]() axis. As we can see, there
is a small spike among very popular tags (centered around the
tags ``Votes'', ``Games'', and ``Game''). Apart from this peak,
the similarity remains flat at 0.3. Interestingly, there is not
an increase in similarity for rarely-used tags. Counter to our
expectations, commonly-used tags and rarely-used tags seem to
cluster articles at similar levels of similarity.
axis. As we can see, there
is a small spike among very popular tags (centered around the
tags ``Votes'', ``Games'', and ``Game''). Apart from this peak,
the similarity remains flat at 0.3. Interestingly, there is not
an increase in similarity for rarely-used tags. Counter to our
expectations, commonly-used tags and rarely-used tags seem to
cluster articles at similar levels of similarity.
Taken in isolation, this is not very informative; does 0.3 indicate that a collection of articles are very similar, not at all similar, or very similar?
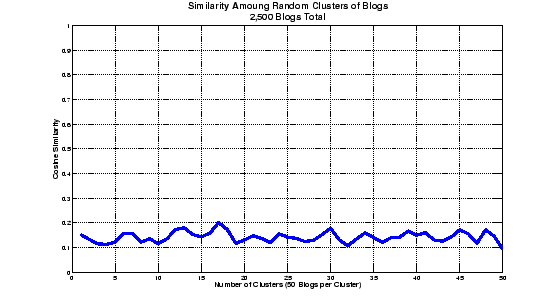
In order to provide a lower bound on the expected similarity measurements, we also conducted an experiment in which articles were placed into clusters at random, and the pairwise cosine similarity of these clusters was calculated. The results of this experiment can be seen in Figure 3.
As we can see from Figure 3, the pairwise similarity of randomly-selected blog entries is between 0.1 and 0.2. This would seem to indicate that tags do provide some sort of clustering information. However, it is not clear whether an average pairwise similarity of 0.3 is a good score or not. We know that, if all articles are completely identical, the average pairwise similarity will be 1.0, but not how this score will fall off for non-identical articles.
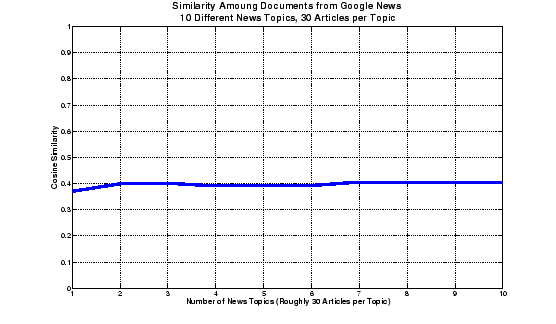
To address this question, we applied the same metric of average pairwise cosine similarity to articles grouped as ``related'' by Google News. The intent of this is to provide an upper bound by determining average pairwise cosine similarity for articles judged to be similar by an external mechanism. The results of this experiment can be seen in Figure 4.
As we can see from Figure 4, articles classified as ``related'' by Google News have an average pairwise cosine similarity of approximately 0.4. Examining these articles by hand shows some articles that would be considered ``very similar'' by a human, and some articles that are more generally about the same topic, but different specifically. For example, under related articles about the nomination of Harriet Miers to the U.S. Supreme Court are specific articles about Bush's popularity, about Miers' appeal to Evangelical Christians, about cronyism in the Bush White House, and about Senator Rick Santorum's opinion of Miers. While these articles are broadly related, they clearly describe different specific topics, and we would not expect them to have a pairwise cosine similarity of anywhere near 1.0.
We can conclude from this that tagging does manage to group articles into categories, but that there is room for improvement. It seems to perform less well than Google News' automated techniques. Furthermore, it would seem that the clusters produced through tagging contain articles that are only broadly related. Tags do not seem to be very useful in helping a user to determine the specific topic of an article.
As a first step towards providing tools that will assist users in effectively tagging articles, we tested the similarity of articles that contained similar keywords.
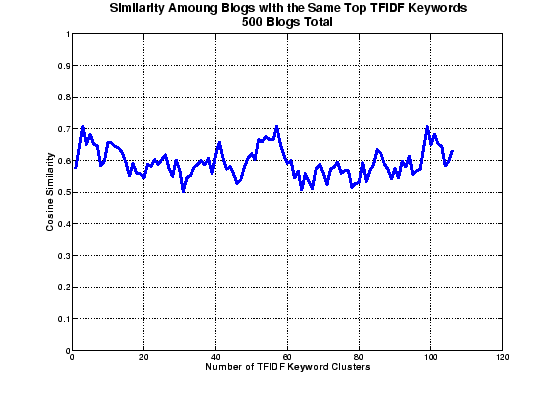
We selected 500 of the articles collected from Technorati and, for each of these articles, we extracted the three words with the top TFIDF score. These words were then treated as the article's ``autotags.'' We then clustered together all articles that shared an autotag, and measured the average pairwise cosine similarity of these clusters. The results of this experiment are shown in Figure 5.
Interestingly, simply extracting the top three TFIDF-scored words and using them as tags produces significantly better similarity scores than tagging does (or than our evaluation of Google News, for that matter). The clusters themselves are also typically smaller, indicating that automated tagging produces more focused, topical clusters, whereas human-assigned tags produce broad categories. This would indicate that automated techniques for extracting tags from article would potentially be of great benefit to those users who wanted to search for blog articles on a specific subject using the article's tags.
One conclusion that can be drawn from the tags shown in Figure 1 is that there is some overlap in tag usage. In other words, there appear to be cases in which users may be using different tags, such as ``feelings'' and ``moods'', to indicate similar ideas. It also appears that tags can be grouped into categories, such as computers, personal feelings, and news. This would imply that it may be possible to construct abstract tags that serve to encompass the topics annotated by one or more of the tags in Figure 1. We wanted to determine whether it was possible to automatically induce a hierarchical tag structure that corresponded to the way in which a human would perform this task.
To test this hypothesis, we decided to use agglomerative clustering [5] to construct a hierarchy of tags.
To begin, we randomly selected 250 of the top 1000 tags from Technorati. For each tag, we collected 20 blog articles6. As above, these articles form a tag cluster: a cluster of articles whose content is assumed to be similar.
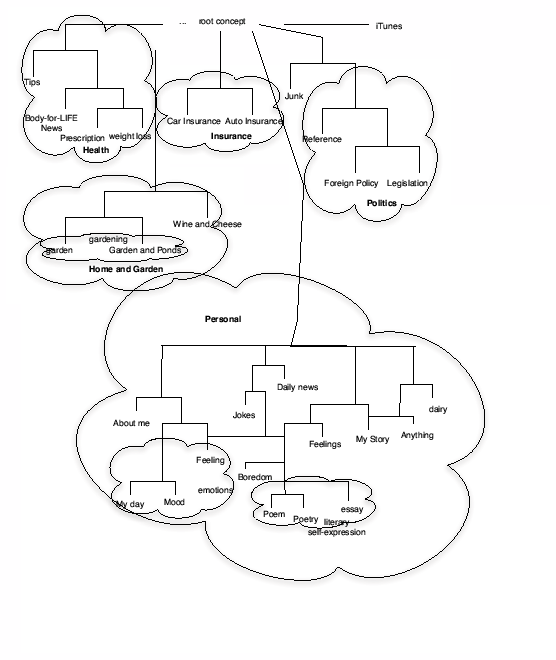
We use agglomerative clustering to build this hierarchy of tags. Figure 6 provides pseudocode for this procedure. We proceed as follows: we compare each tag cluster to every other tag cluster, using the pairwise cosine similarity metric described in Section 5.2. Each article in cluster 1 is compared to each article in cluster 2 and the average of all measurements is computed. We then remove the two closest-similarity clusters from our list of tag clusters and replace them with a new abstract tag cluster, which contains all of the articles in each original cluster. This cluster is annotated with an abstract tag, which is the conjuction of the tags for each cluster. We proceed in this fashion until we are left with a single global cluster that contains all of the articles. By recording the order in which clusters are grouped into progressively more abstract clusters, we can reconstruct a tree that shows the similarity of tags. We have reproduced a subset of this tree 7 in Figure 7.
What is particularly interesting about this tree is the degree to which the relationship between tags mirrors that seen in hand-built taxonomies such as those built by dmoz.org or Yahoo!. We can see that the clustering algorithm was able to separate articles into ``Personal'', ``Home and Garden'', ``Insurance'', ``Politics'' and ``Health'' categories. Furthermore, we can see subcategories being formed within those categories. For example, ``Poem'', ``Poetry'' and ``Essay'' form a ``literary self-expression'' subcluster, ``My Day'', ``Mood'', and ``Feeling'' form an ``emotions'' subcluster, and ``garden'' and ``Garden and Ponds'' form a ``gardening'' subcluster.
It is worth emphasizing the point that the tags were not used in constructing this hierarchy, but only in constructing the original clusters. All grouping was done based on the similarity of the articles. Yet we see the tags fitting into a topical hierarchy very similar to those constructed by humans who reason explicitly about the semantics of these tags.
This shows that there may be a middle ground in the debate between advocates of a flat folksonomy and advocates of a centrally-defined hierarchy. By applying information retrieval algorithms, we are able to reconstruct a hierarchical classification of articles, even though the users who annotated those articles only had access to the standard flat tag space. The authors retained the ease-of-use of flat tags, and yet this hierarchical information can be made available to users who wish to browse or search more effectively.
The experiments discussed above raise a number of interesting questions. The first is whether the metric we have used is in fact an accurate way to measure the similarity of blog entries. This is a completely syntactic measure, based primarily on frequencies of single words occurring. Sentences are not parsed or analyzed, synonyms are not detected, and larger phrases are not looked for. These are all potential future directions; however, what is really needed is a means to calibrate our similarity metric, by measuring its performance relative to larger sets of articles deemed to be similar by an external source.
Assuming that our similarity metric has some merit, these experiments shed some light on what it is that tags actually help users to do. These results imply that tags help users group their blog entries into broad categories. In retrospect, this is not a huge surprise; given that tags are propositional entities, we know that a tag's expressive power is limited to indicating whether or not an article is a member of a set. Additionally, since tags cannot be combined or related to each other, users must create a new tag for each concept they wish to assign to a blog entry. It is not hard to imagine that most users would not want to create a vast number of unrelated tags; rather, they would choose a smaller, more general set. These experiments lend credence to this theory.
Figure 1 also provides an interesting snapshot of how tags are used by groups of users. At least within this picture, it would seem that bloggers are not settling on common, decentralized meanings for tags; rather, they are often independently choosing distinct tags to refer to the same concepts. Whether or not the meanings of these distinct tags will eventually converge is an open question.
We feel that the ability to arrange tags into a hierarchy also has a great deal of potential benefit. Two applications that come to mind: First, a system that would suggest similar tags to authors. For example, when a user chooses the tag ``My Day'', the system might recognize that ``mood'' is a similar, but more widely-used tag and suggest this to the user. Second, this hierarchy could be used to provide users with a flexible way to make their tags more or less specific. We plan to build a Web Service that would allow a blog author to check her tags against those being used by other bloggers. The system would use the methods described herein to suggest synonomymous tags, as well as more specific and more general tags.
While it seems clear that tagging is a popular and useful way for bloggers to organize and discover information, it also seems clear that there is room for improvement.
For one, we maintain that a more expressive representation for tags is needed. Observing the way that tags are used in, for example, Delicious, it is apparent that newcomers want to use phrases, rather than single words, to describe documents. Eventually, users realize that phrases are not effective and construct multi-word tags, such as ``SanFranciscoCalifornia.'' Unfortunately, these multi-word tags are also inflexible; there is no way to relate ``SanFranciscoCalifornia'' to either ``San Francisco'' or ``California'' in current tag systems.
In particular, we argue that users should be able to cluster tags (i.e. `Baghdad', `Tikrit', and `Basra' tags might be contained within an `Iraq' cluster) to specify relations (not just similarity) between tags, to use tags to associate documents with objects such as people. This is not necessarily inconsistent with the idea of folksonomy; as we showed in section 6, there is no reason why hierarchical definitions can't emerge from common usage. In fact, the term ``hierarchy'' may be overly restrictive; what users really seem to need is a way to express relations between tags. ``Is-a'' is merely one of those possible relations. Furthermore, there may be cases in which authors are able to provide knowledge about how tags should be clustered that is much more accurate and specific that what can be inferred from article text.
One of tagging's biggest appeals is its simplicity and ease of use. Novices can understand the concept (although they may try to use phrases rather than isolated symbols). Tags are easy for authors to assign to an article. The importance of this cannot be overstated; any extensions to current tagging systems must retain this ease of use. Complex languages or cumbersome interfaces will mean that tags simply will not be used. We plan to incrementally develop tools that allow users to cluster their tags in a low-impact, easy-to-understand way, automating as much of the work as possible.
Another open question is the relationship between the tasks of article tagging and information retrieval. It is taken for granted that the tags that an author chooses to describe an article are the same as the tags that a reader would select when choosing articles to read. We would like to know whether this is actually the case.
We also feel that tools that can help users automatically tag articles will be of great use. In fact, one might argue that even the act of manually assigning tags to articles is too much burden for the user, as it forces her to interrupt her writing or browsing to select appropriate tags. We plan to develop extensions to the approach described above that automatically extract relevant keywords and suggest them as tags. Additionally, this tool should interface with social tagging systems such as Technorati and Delicious to determine how these suggested tags are being used in the folksonomy. It should detect if there are synonymous tags that might be more effective, and assist users in assigning tags in a consistent manner.
Finally, we are also interested in the evolution of tags as a social phenomenon. Tagging is an interesting real-world experiment in the evolution of a simple language. Anecdotally, we have seen that some tags, such as ``linux'' or ``iPod'' have relatively fixed meanings, whereas other tags, such as ``katrina'', have a usage that varies widely over time. We plan to study this evolution more systematically, repeatedly collecting the top tags from Technorati and Delicious and comparing the articles they are tagged with to look for drifts in meaning.