ABSTRACT
This paper presents the notion of Semantic Associations as complex relationships between resource entities. These relationships capture both a connectivity of entities as well as similarity of entities based on a specific notion of similarity called r-isomorphism. It formalizes these notions for the RDF data model, by introducing a notion of a Property Sequence as a type. In the context of a graph model such as that for RDF, Semantic Associations amount to specific certain graph signatures. Specifically, they refer to sequences (i.e. directed paths) here called Property Sequences, between entities, networks of Property Sequences (i.e. undirected paths), or subgraphs of r-isomorphic Property Sequences.
The ability to query about the existence of such relationships is fundamental to tasks in analytical domains such as national security and business intelligence, where tasks often focus on finding complex yet meaningful and obscured relationships between entities. However, support for such queries is lacking in contemporary query systems, including those for RDF.
This paper discusses how querying for Semantic Associations might be enabled on the Semantic Web, through the use of an operator r. It also discusses two approaches for processing r-queries on available persistent RDF stores and memory resident RDF data graphs, thereby building on current RDF query languages.
Categories and Subject Descriptors
H.2.3 [Information Systems]: Database Management–Query Languages
General Terms
Languages, Theory, Management
Keywords
Semantic Web Querying, Semantic Associations, RDF, Complex Data Relationships, graph traversals.
1. INTRODUCTION
The Semantic Web [13] proposes to explicate the meaning of Web resources by annotating them with metadata that have been described in an ontology. This will enable machines to “understand” the meaning of resources on the Web, thereby unleashing the potential for software agents to perform tasks on behalf of humans. Consequently, significant effort in the Semantic Web research community is devoted to the development of machine processible ontology representation formalisms. Some success has been realized in this area in the form of W3C standards such as the eXtensible Markup Language (XML) [16] which is a standard for data representation and exchange on the Web, and the Resource Description Framework (RDF) [41], along with its companion specification, RDF Schema (RDFS) [17], which together provide a uniform format for the description and exchange of the semantics of web content. Other noteworthy efforts include OWL [25], Topic Maps [52], DAML+OIL [30]. There are also related efforts in both the academic and commercial communities, which are making available tools for semi-automatic [29] and automatic [48][29] semantic (ontology-driven and/or domain-specific) metadata extraction and annotation.
With the progress towards realizing the Semantic Web, the development of semantic query capabilities has become a pertinent research problem. Semantic querying techniques will exploit the semantics of web content to provide superior results than present-day techniques which rely mostly on lexical (e.g. search engines) and structural properties (e.g. XQuery [24]) of a document. There are now a number of proposals for querying RDF data including RQL [39], SquishQL [44], TRIPLE [48], RDQL [47]. These languages offer most of the essential features for semantic querying such as the ability to query using ontological concepts, inferencing as part of query answering, and some allow the ability to specify incomplete queries through the use of path expressions. One key advantage of this last feature is that users do not need to have in-depth knowledge of schema and are not required to specify the exact paths that qualify the desired resource entities. However, even with such expressive capabilities, many of these languages do not adequately support a query paradigm that enables the discovery of complex relationships between resources. The pervasive querying paradigm offered by these languages is one in which queries are of the form: “Get all entities that are related to resourceA via a relationship R” where R is typically specified as possibly a join condition or path expression, etc. In this approach, a query is a specification of which entities (i.e. resources) should be returned in the result. Sometimes the specification describes a relationship that the qualifying entities should have with other entities, e.g. a join expression or a path expression indicating a structural relationship. However, the requirement that such a relationship be specified as part of the query is prohibitive in domains with analytical or investigative tasks such as national/homeland security [11] and business intelligence, where the focus is on trying to uncover obscured relationships or associations between entities and very limited information about the existence and nature of any such relationship is known to the user. In fact, in this scenario the relationship between entities is the subject of the user’s query and should being returned as the result of the query as opposed to be specified as part of the query. That is, queries would be of the form “How is Resource A related to Resource B?”. For example, a security agent may want to find any relationship between a terrorist act and a terrorist organization or a country known to support such activities.
One major challenge in dealing with queries of this nature is that it is often not clear exactly what notion of a relationship is required in the query. For example, in the context of assessing flight security, the fact that two passengers on the same flight are nationals of a country with known terrorist groups and that they have both recently acquired some flight training, may indicate an association due to a similarity. On the other hand, the fact that a passenger placed a phone call to someone in another country that is known to have links to terrorist organizations and activities may indicate another type of association characterized by connectivity. Therefore, various notions of “relatedness” should be supported.
This paper intends to make two main contributions. First, we formalize a set of complex relationships for the RDF data model, which we call Semantic Associations. Second, we outline two possible approaches for processing queries about Semantic Associations through the use of an operator r (r-Queries). One of the two approaches is based on processing r-queries on persistent RDF data systems such as RDFSuite [8], while the other is based on processing these queries on a main memory based representation of an RDF model such as JENA [55].
The rest of the paper is organized as follows: Section 2 discusses some background and motivates our work with the help of an example. Section 3 presents the formal framework for Semantic Associations, section 4 discusses implementation strategies for the r operator, section 5 reviews some related work, and section 6 concludes the paper.
2. BACKGROUND & MOTIVATION
Although there are various knowledge modeling languages that may be used on the Semantic Web such as Topic Maps [54], UML [46], DAML+OIL [30], OWL [25], etc., in this paper we have chosen to formalize Semantic Associations for the RDF data model. It should be clear that we are not suggesting that the notion of Semantic Associations only applies to RDF. On the contrary, the notion is very general and is applicable to any data model that can be represented as a graph. The choice of RDF for formalization does not confer serious problems however. In the first place, some of these other models e.g. DAML+OIL build upon RDF. Secondly, there is work on mappings from other formalisms to RDF [20][41].
Next, we will briefly summarize the RDF data model and then motivate our work with an example.
2.1 RDF
RDF [41] is a standard for describing and exchanging semantics of web resources. It provides a simple data model for describing relationships between resources in terms of named properties and their values. The rationale for the model is that by describing what relationships an entity has with other entities, we somehow capture the meaning of the entity. Relationships in RDF, or Properties as they are called, are binary relationships between two resources, or between a resource and a literal value. An RDF Statement, which is a triple of the form (Subject, Property, Object), asserts that a resource, the Subject, has a Property whose value is the Object (which can be either another resource or a literal). This model can be represented as a labeled directed graph, where nodes represent the resources (ovals) or literals (rectangles) and arcs representing properties whose source is the subject and target is the object, and are labeled with the name of the property. For example, in the bottom part of Figure 1, we can see a node &r1 connected by a paints arc to the node &r2, which reflects the fact that &r1 (a painter with first name Pablo, and last name Picasso) painted another resource &r2 (a painting). The meaning of the nodes and arcs is derived from the connection of these nodes and arcs to a vocabulary (the top part of the figure). The vocabulary contains describes types of entities i.e. classes (e.g. Museum) and types of properties (e.g. creates) for the domain. The vocabulary description and is done using the companion specification to RDF called the RDF Schema specification [17]. For example in Figure 1, classes like Painter, Museum and properties such as Paints, are defined. Resources are connected to classes using an rdf:typeof property indicating an instantiation relationship.
2.2 MOTIVATING EXAMPLE
Although the focus of our current evaluations involves scenarios in the National Security domain, for brevity and pedagogical reasons, for this paper we have chosen to use a modified version of the example from [39]. We will now illustrate Semantic Associations by way of a simple example shown in Figure 1. The figure shows an RDF model base containing information to be used in the development of a cultural portal, given from two perspectives, reflected in two different schemas (the top part of the figure). The top left section of the picture is a schema that reflects a museum specialist’s perspective of the domains using concepts like Museum, Artist, Artifact, etc. The top right section is a schema that reflects a Portal administrator’s perspective of the domains using administrative metadata concepts like file-size , mime-type , etc. to describe resources. The lower part of the figure is the model base (or description base in the linguo of [39]), that has descriptions about some Web resources, e.g., museum websites (&r3, &r8), images of artifacts (&r2, &r5, &r7) and for resources that are not directly present on the Web, e.g., people, nodes representing electronic surrogates are created (&r1, &r4, &r6 for the artists Pablo Picasso, Rembrandt, and Rodin August respectively).
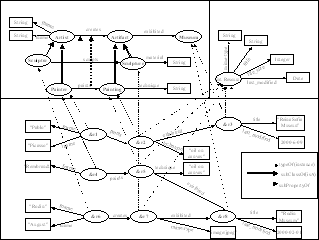
Figure 1: Cultural Portal Information in RDF
Typically, a query language allows you to find all entities that are related by a specific relationship. For example, we may ask a query to retrieve all resources related to resource &r1 via a paints relationship, or via a paints.exhibited relationship, and get &r2 as a result for the first query and &r3 as the answer for the second query. However, we are unable to ask queries such as “How are resources &r1 and &r3 related? Such a query should return for example that “&r1 paints &r2 which is exhibited in &r3”, indicating a path connecting the two entities. With a query such as this one, the user is trying to determine if there is a relationship between entities, and what the nature of the relationship(s) is(are). It should be possible to ask such a query without any type of specification as to the nature of the relationship, such as using a path expression to give information about the structure of the relationship. For example, the following example RQL query
select * from {;Artist}@P{X}.{;Sculpture}@Q{Y}.@R{Z}
finds all data paths that traverse the class hierarchies Artist and Sculpture , containing three schema properties, one for each property variable (@variable). However, we notice that the query requires that a property variable be added for every edge in the required path. That is, the user is required to have some idea of at least the structure e.g. length, of the relationship. One approach that some of these systems offer to alleviate this problem is that they provide mechanisms for browsing or querying schemas to allow users to get the information they need. While this may be a reasonable requirement when querying specific domains with a few schemas involved, on the Semantic Web, many schemas may be involved in a query, and requiring a user to browse them all would be a daunting task for the user. In fact, in some cases, such information may not be available to all users (e.g., classified information) even though the data may be used indirectly to answer queries. Furthermore, browsing schemas do not always give the complete picture, especially in the case of RDFS schemas, because, entities may belong to different schemas, creating links between entities that are not obvious from just looking at the schemas. For example in Figure 1, the relationship paints.exhibited.title connecting &r1 to “Reina Soifa Museum”, is not apparent by just looking at either schema.
So far, we have talked about relationships in terms of a directed path connecting two entities. However, there are some other interesting types of relationships. Let us take for example, resources &r4 and &r6. Both resources could be said to be related because they have both created artifacts (&r5, and &r7) that are exhibited at the same museum (&r8). In this case, having some relationship to the same museum associates both resources. This kind of connectivity is an undirected path between the entities. Another closely related kind of association is class membership. For example, &r1 and &r6 are both Artists, even though of a different kind, and therefore are somewhat associated. Also, &r1 and &r6 could be said to be associated because they both have creations (&r2, and &r7) that are exhibited by a Museum (&r3 and &r8 respectively). In this case, the association is that of a similarity. So, in the first three associations the relationships capture some kind of connectivity between entities, while the last association captures a similarity between entities. Note that the notion of similarity used here is not just a structural similarity, but a semantic similarity of paths (nodes and edges) that the entities are involved in. Nodes are considered similar, if they have a common ancestor class. For example in the relationship involving &r1 and &r6, although one case involves a painting and the other a sculpture, we consider them similar because sculptures and paintings are kinds of Artifacts and sculpting and painting are both kinds of creative activities (the notion of similarity is extended to properties as well).
The Semantic Associations shown in this example are fairly simple involving only short paths and are useful only for the purpose of illustration. However, in environments that support information analytics and knowledge discovery involve longer paths, especially undirected paths, which are not easily detectable by users in fast-paced environments. For example at airport security portals, agents may want to quickly determine if a passenger has any kind of link to terrorist organizations or activities.
3. FRAMEWORK
The framework described in this section provides a formal basis for Semantic Associations. It builds on the formalization for the RDF data model given in [39], by including a notion of a Property Sequence. A Property Sequence allows us to capture paths in the RDF model and forms the basis for formalizing Semantic Associations as binary relations on Property Sequences. Secondly, we some complex queries called r-queries for querying about Semantic Associations.
3.1 Formal Data Model
In section 2.1, we describe the RDF data model informally as a labeled directed graph. To recap, the RDF Schema specification [17] provides a special vocabulary for describing classes and properties in a domain. A Property is defined by specifying its domain (the set of classes that it applies to), and its range (either a Literal type e.g. String, Integer, etc or the classes whose entities it may take as values). Classes are defined in terms of their relationship to other classes using the rdfs:sublassOf property to place them at the appropriate location in a class hierarchy, as well as other user specified properties that may include them in their range or domain thereby linking them to other classes. Properties may also be organized in a hierarchy using the rdfs:subProperty Of property.
The formalization in [39] defines a graph data model along with a type system that connects the RDF Model & Syntax specification with the RDFS schema specification using an interpretation mechanism. It forms the basis for a typed RDF query language called RQL [39]. RQL is fairly expressive and supports a broad range of queries. Its type system T is the set of all possible types that can be constructed from the following types:
t = t C | t P | t M | t U | t L | {t} | [1:t 1, 2:t 2, ..., n:t n] | (1:t 1 + 2:t 2 + ... + n:t n)
where t C indicates a class type, t P a property type, t M a metaclass type, t L a literal type in the set L of literal type names (string, integer, etc.), and tU is the type for resource URIs. For the RDF multi-valued types we have {.} as the Bag type, [.] is the Sequence type, and (.) is the Alternative type. The set of values that can be constructed using the resource URIs, literals and class property names is called V. Then, the interpretation of types in T is given naturally by the interpretation function [[ ]], which is a mapping from t to the set of values in V. For example, a class C is interpreted as unary relation of type {tU}, which is the set of resources (i.e. of type tU ) that have an rdf:typeOf property with range C, and includes the interpretations of the subclasses of C. For a property p, [[p]] is given by
{[v1, v2] | v1 Î [[ p.domain ]], v2 Î [[ p.range ]] } È
{ [[ p’ ]] | p’ is a subpropertyOf p}
It defines an RDF schema as a 5-tuple RS = (VS, ES, y, l, H) where: VS is the set of nodes and ES is the set of edges. y is an incidence function y: ES ® VS × VS, and l is a labeling function that maps class and property names to one of the types in T, i.e. l: VSÈ ES ® T. H = (N, <), where N = C È P, C and P are the set of class and property names in RS, respectively. H is a well-formed hierarchy, i.e., < is a smallest partial ordering such that: if p1, p2 Î P and p1 < p2, then p1.domain £ p2.domain and p1.range £ p2.range. It also formalizes an instance of an RDFS schema called a description base which contains all the asserted instances of classes and properties of an RDF schema.
We generalize these definitions to sets of RDF schemas and description bases as basic notion of context for a r -query.
3.1.1 Definition 1
The RDFS schema set of RDFS Schemas RSS = {RSi: 1£ i £ n}.
Let C = CS1 È CS2 È… È CS2 where CSi is the set of class names in schema RSi and P = PS1 È PS2 È … È PSn, where PSi is the set of property names in RSi then N = C È P.
[39] defines a description base RD which is an instance of an RDFS schema RS containing all the asserted instances of the classes and properties in RS. We generalize that definition here to the union of instances of the set of schemas in an RDFS schema set.
3.1.2 Definition 2
An instance of an RDF schema set RSS = {RS1, RS2, .. RSn}, is a description base RDS defined as a 5-tuple = (VDS, EDS, y, n, l), where VDS = VD1 È VD2 È… È VDn and VDi is the set of nodes in the description base of the schema RSi, and EDS is defined similarly. y is the incidence function y: EDS ® VDS × VDS, n is a value function that maps the nodes to the values in V i.e. n: VDS ® V, l is a labeling function that maps each node either to one of the container type names (Seq, Bag, Alt) or to a set of class names from the schema set RSS whose interpretations contain the value of the node, and each edge e = [v1, v2] to a property name p in RSS, where the interpretation of p contains the pair [n(v1), n(v2)], i.e., the values of v1 and v2. Formally, l: VD È ED ® 2N È {Bag, Seq, Alt} in the following manner:
i. For a node n in RDS, l(n) = {c | c Î C and n(n) Î[[c]]}
ii. For an edge e from node n1 to n2, l(e) = p Î P and the values of n1 to n2 belong in the interpretation of p: [n(n1), n(n2)] Î [[p]].
In order capture paths in the RDF graph model, we need to define a notion of a Property Sequence, represented in the graph as a sequence of edges (i.e. properties). There is a choice to be made in the method for realizing such a notion in a query language such as RQL. One option is to add paths or property sequences as types in a query language making them first class citizens. The second option is to realize them as complex operations such as Cartesian product, on property types. We choose the later approach because attempting to make paths as first class citizens brings up additional issues such as defining path subsumption and so on. We will now define the notion of a Property Sequence.
3.1.3 Definition 3 (Property Sequence)
A Property Sequence PS is a finite sequence of properties [P1, P2, P3, … Pn] where Pi is a property defined in an RDF Schema RSj of a schema set RSS. The interpretation of PS is given by:
[[PS]] Í ´ i=1 n [[Pi]] where for ps Î [[PS]], called an instance of PS, ps[i] Î [[Pi]] for 1£ i £ n and ps[i][1] = ps[i+1][0]).
ps[i][1] refers to the second element of the ith ordered pair and ps[i+1][0] refers to the first element of the i+1th ordered pair. We define a function NodesOfPS()which returns the set of nodes of a Property Sequence PS, i.e.
PS.NodesOfPS()= {C1, C2, C3, … Ck} where Ci is a class in either the domain or range of some Property Pj in PS, 1£ j £ n.
For example in Figure 1, for PS = c reates.exhibited.title, PS. NodesOfPS () = {Artist, Artifact, Museum, Ext. Resource, String}.
Let PS = [P1, P2, P3, … Pn], a description base RDS is said to satisfy or be a model of PS (RDS |= PS) if there exists a sequence of edges e1, e2, e3, … en in the description base RDS such that for all i, l(ei) = Pi, y(ei) = (vi, vi+1) and ´ i=1 n (vi, vi+1) = ps for some ps Î [[PS]].
We define a function PSNodesSequence() on Property Sequence instances that returns its sequence of nodes, i.e. ps.PSNodesSequence()= [v1, v2, v3, … vn+1]. The node v1 is called the origin of the sequence and vn+1 is called the terminus.
Next, we define a set of binary relations on Property Sequences.
3.1.4
Definition 4 (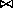 r Joined Property Sequences)
r Joined Property Sequences)
PS1 ![]() r PS2 is true if:
r PS2 is true if:
NodesOfPS(PS1) Ç NodesOfPS(PS2) ¹ 0.
The Property Sequences PS1 and PS2 are called joined, and for C Î (NodesOfPS(PS1) Ç NodesOfPS(PS2)), C is called a join node. For example, in Figure 2, the sequences creates.exhibited. and paints.exhibited are joined because they have a join node Museum.
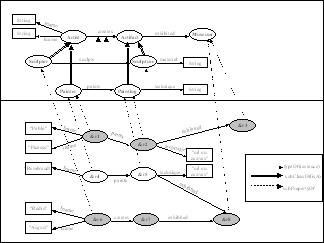
Figure 2 : Isomorphic Property Sequences
3.1.5 Definition 5 (@ r r-Isomorphic Property Sequences)
Two property sequences PS1 = P1, P2, P3, … Pm, and PS2 = Q1, Q2, Q3, … Qm, are called r -isomorphic (PS1 @ r PS2), if
for all i, 1 £ i £ m: Pi = Qi or Pi Í Qi or Qi Í Pi ( Í means subpropertyOf )
3.1.6 Definition 6 (Length)
The length of a Property Sequence is equal to the number of properties in the Property Sequence. In the case of a Joined Property Sequence its length is the sum of all the properties in its constituent Property Sequences, i.e. the length of the undirected path from origin of one Property Sequence to the origin of the other Property Sequence. For example, in Figure 2, the Joined Property Sequences [creates.exhibited, paints.exhibited] has a length of 4.
3.2 Semantic Associations
We can now define some binary relations on the domain of entities i.e. resources, based on the different types of Property Sequences.
3.2.1 Definition 7 (r-pathAssociated)
r -pathAssociated (x, y) is true if there exists a Property Sequence with ps Î [[PS]] and, either x and y are the origin and terminus of ps respectively, or vice versa, i.e. y is origin and x is terminus. Then ps is said to satisfy r -pathAssociated (x, y) written as ps|= r -pathAssociated (x, y).
3.2.2 Definition 8 (r-joinAssociated)
Let PS1 and PS2 be two
Property Sequences such that PS1 ![]() r PS2 with a join node C, and there exists
ps1 and ps2 such that ps1
Î [[ PS1 ]]
and ps2 Î
[[ PS2 ]] and, n
Î
ps1.PSNodesSequence()
Ç
ps2.PSNodesSequence(),
then
r
-joinAssociated (x, y) is true if either of the conditions
are satisfied.
r PS2 with a join node C, and there exists
ps1 and ps2 such that ps1
Î [[ PS1 ]]
and ps2 Î
[[ PS2 ]] and, n
Î
ps1.PSNodesSequence()
Ç
ps2.PSNodesSequence(),
then
r
-joinAssociated (x, y) is true if either of the conditions
are satisfied.
1) x is the origin of ps1 and y is the origin of ps2 or
2) x is the terminus of ps1 and y is the terminus of ps2.
This means that either ps1.PSNodesSequence = [ x, b, c … n, .,., r ] and ps2.PSNodesSequence = [ y, b, c, p. . n, x, y], or ps1.PSNodesSequence = [ a, b, c … n, .,., r ,x] ] and ps2.PSNodesSequence = [ a, b, c, p. . n, x, y] and n Î [[ C ]].
We say that (ps1, ps2) |= r -joinAssociated (x, y).
3.2.3 Definition 9 (r-cpAssociated)
This is a special case of Definition 5 that captures an inclusion or sibling relationship (i.e. common parent) between resources.
r
-cpAssociated (x, y) is true if there exists two Property
Sequences PS1 and PS2 such that
PS1 ![]() r PS2 which satisfy
r
-joinAssociated (x, y) and, both PS1 and
PS2 are of the form:
rdf.typeOf.(rdfs:subclassOf)*.
This relation is used to capture the notion that entities are
related if they either belong to the same class or to sibling
classes. For example,
&r1 and
&r6 are related
because they are both
Artists. We say that
(ps1,
ps2) |=
r
-cpAssociated (x,
y). However, in order to reduce the possibility of
meaningless associations e.g. both x and y belong to
rdfs:Resource,
we make further restrictions. We say that
r
-cpAssociated (x,
y) is strong
if
r PS2 which satisfy
r
-joinAssociated (x, y) and, both PS1 and
PS2 are of the form:
rdf.typeOf.(rdfs:subclassOf)*.
This relation is used to capture the notion that entities are
related if they either belong to the same class or to sibling
classes. For example,
&r1 and
&r6 are related
because they are both
Artists. We say that
(ps1,
ps2) |=
r
-cpAssociated (x,
y). However, in order to reduce the possibility of
meaningless associations e.g. both x and y belong to
rdfs:Resource,
we make further restrictions. We say that
r
-cpAssociated (x,
y) is strong
if
1) For the join node j of the Joined Property Sequence (inducing the association (i.e. the common parent of x and y), j Í é ù, where é ù called the ceiling, refers to the most general class in the hierarchy that is to be considered, which is usually user-specified.
2) the length of the Joined Property Sequence inducing the association is minimal. By minimal we mean that it is less than a specific value indicated by context or specified by user.
The first restriction ensures that we do go to far up the hierarchy looking for a common parent, while the second ensures that the relationship is not too distant to be meaningful in the user’s context.
3.2.4 Definition 10 (r-IsoAssociated)
We say that x and y are semantically associated if either r-pathAssociated(x, y), r-cpAssociated(x, y), r-IsoAssociated(x, y), or r-joinAssociated(x, y).
3.3 r-Queries
A r-Query Q is defined as a set of operations that map from a pair of keys (e.g. resource URIs) to the set of Property Sequences PS in the following manner:
1. r : tU (2)à 2 PS
2.
r![]() r:
tU
(2)
à2
PS
(2)
r:
tU
(2)
à2
PS
(2)
3. r @r : tU (2) à2 PS (2)
tU (2) = { {x, y} : x, y Î tU and x ¹ y. Similarly, PS (2) is the set of pairs of Property Sequences. In 1., we map from a pair of keys x and y to a set of Property Sequences that induces a r-pathAssociation of x and y. In 2., we map from (x, y) to a set of binary tuples of Property Sequences that induces either a r-joinAssociation or a strong r-cpAssociation of x and y and in 3., we map from (x, y) to a set of binary tuples of Property Sequences that induces a r-isoAssociation.
4. STRATEGIES FOR PROCESSING r-QUERIES
Our strategy for implementation involves investigating alternative approaches to implementing the r-operator, and evaluate their merits and demerits. We consider two major categories. The first category, which we have developed a partial implementation for, involves leveraging existing RDF persistent data storage technologies. Here, a r-query processing layer is developed above the RDF data storage layer, which performs some of the computation and, relegates a specific portion of the computation to the data store layer. In the second approach, the implementation involves the use of a memory resident graph representation of the RDF model, along with the use of efficient graph traversal algorithms. We will outline how query processing is done using both approaches.
4.1 Exploiting RDF Data Management Systems
In this approach, we leverage existing RDF data storage technologies such as RDFSuite [8] and SESAME [18] and develop a r-query processing layer which performs some of the computation and, relegates a specific portion of the computation to the data store layer. Figure 3 gives an illustration of this approach, (although, this is somewhat of an oversimplification, it adequate for the purposes of this discussion). Here the processing of a r-query is broken down to 4 phases. Phases 2 and 4 occur at the data store layer and phases 1 and 3 occur at the r-query processing layer.
Phase 1 captures the query, i.e. the resources and context (i.e. schema set). In the second stage, the resources are classified i.e., the classes that entities belong to, within the given context, are identified. This involves a query to the data store layer, which exploits the rdf:typeOf statements to answer the query. Much of the processing is done in the third phase where, potential paths involving the entities in the query are discussed by querying a PathGuide (a combination of index structures that stores information about paths that exist between resources classes). There are two kinds of paths that are kept in the PathGuide. The first kind of path is those that are obvious from the schema. The second kind is those paths that exist at the data level but are not evident at the schema level. This is because of the fact that the RDF data model allows multiple classifications of entities. Consequently, every instance of a multiple classification may induce an edge between two classes that does not exist at the schema level, and thus is not general to all entities of those classes. Therefore, a query to the PathGuide yields potential property sequences paths between entities, since some of the paths are not general to entire classes but specific to the entities that are multiply classified. For example in Figure 1, the paints.exhibited.title sequence is not a sequence in either the left or right schema, but is present in the description base (i.e. between &r1 and the literal node “Reina Sofia Museum”). The reason for this is &r3‘s membership in both the Museum and the Ext.Resource classes, this can be seen as having created an intermediate class node that collapses Museum and the Ext.Resource classes, and consequently links the paints.exhibited sequence to the title property.
The fourth stage of query processing involves the validation of the paths found in the PathGuide for the specific entities in the query, by executing queries on the underlying data store. The output of this stage selects only those paths whose queries do not return an empty result.
Figure 3: Illustration of r-Query Processing
4.1.1 Issues
One issue that arises in implementing this strategy, is how to deal with large size of the indices and large number of queries that is generated in order to validate these potential paths at the data store layer, caused by storing all potential paths between classes. However, heuristics could be employed to reduce these problems. For example, to minimize the size of the indices, we could choose to avoid adding every single potential path between classes in the index, but include only those whose support value is at least as large as a user supplied threshold value, where thesupport value represents the percentage of resources that are involved in multiple classification for any given pair of classes. The idea here is that if there are very few resources that induce a connection between two otherwise unconnected schema classes because of a multiple classification, then avoiding the addition of the paths that include that edge can reduce the size of the indices. The rationale for this is that the probability of those paths being involved in the result of a query is low therefore the additional cost of storing the paths in the indices may not be worth it. A second heuristic is to prune the number of paths to have to be validated by the data storage layer. This could be done weights to assigning Semantic Associations weights based on the contextual relevance and the validating only those associations with the highest relevance. Our work in this area is still in progress.
An additional problem with processing r-queries on existing RDF storage systems is that some of these systems represent each property as a separate relation in a relational database model. . Therefore, the computation of a Property Sequence results in a large number of joins which has a negative impact of the speed of query processing. Currently, we do not see any easy solution to this problem.
4.2 Using Graph Algorithms
The approach involves the use of a memory-resident graph representation of the RDF model such as JENA [55], or the memory representation of the schema set as in SESAME [18], to which graph traversals algorithms can be applied. In the case of r-pathAssociation we can search for paths between entities, and in the case of a r-joinAssociation we check if the two entities belong in the same connected component. One issue with this approach is that that trying to find all paths between entities could easily lead to an algorithm whose complexity is exponential. However, [51] provides promising fast algorithms for solving path problems which may be employed for such computations. In particular, it offers linear algorithms for computing a path expression representing the set of all paths between nodes in a graph. Such a representation may then be processed using contextual information to prune paths that are not very relevant in the given context. In addition, other heuristics may be added. For example, a user may be asked to characterize the desired result set, e.g. shortest paths or longest paths, which will also help to reduce the result set. Similar heuristics to those discussed in the first approach that use context to prune paths based on degree of relevance can also be used here. In that case, the complexity of the problem can be analyzed along the number of semantic paths retrieved
Complexity = S (n-1) (l=1) (# paths of length l) (probability of keeping path of length l).
Another issue is the complexity of graph isomorphism problem which is known to be NP-complete. However, certain classes of graphs have properties making them amenable to efficient manipulation. For example, [12] describes a polynomial time algorithm for detecting isomorphism in rooted directed path graphs, which includes the exact class of graphs that are required for checking r-isomorphism. We are currently working on a prototype implementation of this approach.
5. RELATED WORK
We not aware of any work that focuses on supporting retrieval of complex semantic relationships such as Semantic Associations, except for our preliminary discussion of these so-called Semantic Associations in [1]. There is a reasonable amount of work [2][3][19][22][23][24][33] on querying object and semi-structured data using path expressions. This enables users to query for data without having in-depth schema knowledge. While this provides powerful and expressive capability, the premise of these systems is still to find data entities that satisfy the query. We have argued earlier that such a querying paradigm is unsuitable for querying about Semantic Associations. Some of these systems [19][22] support paths as first class entities and allow for path variables to be used outside of the FROM clause i.e. to be returned as a result of a query which may suggest that a query about a r-pathAssociation could easily be supported. However, these systems typically assume a rooted directed graph data model, which does not exist for RDF. [22] provides some functions that range over path variables e.g. the difference function, which returns the difference in the two sets of paths. This provides rich queries to be made about paths. However, some of the operations that we have discussed here such as the r-Isomorphism are not supported.
With respect to RDF, the current generation of RDF query languages RQL[39], SquishQL[44], RDQL[47], do not support path variables as first class entities and so cannot even be used for querying for path relationships. Furthermore, in order to represent inference rules or queries to capture Semantic Associations in the logic-based RDF querying systems such as TRIPLE [50], formalisms beyond FOL would be required.
The DISCOVER system [37] provides keyword search capability over relational databases where associations connecting the entities in the queries are returned, called Joining Sequences. The connections are based on primary key to foreign key relationships. However, due to the lack of semantics in the relational model, the interpretation of the association is left to the user. Furthermore, other associations such as the similarity cannot be captured.
This difference between our work and that done in the data mining community is articulated in a statement made in [31], where information access techniques are describes as goal-driven while data mining is said to be opportunistic. Traditional data mining [21][26] focuses on discovering patterns and relationships in data that can be used to develop models of the data. In association analysis [7] rules that associate attribute values are learned from patterns of co-occurrences of attribute values in data. to capture co-occurrence relationships between sets of data. On the contrary, we do not try to learn rules from data rather, we provides specific rules for inferring associations based on structural properties, and focus on providing methods for verifying whether these kinds of associations exist between entities given in a query. In addition, our association rules involve sequences of binary predicates while association rules involve sets of attribute value pairs. We view data mining as a complimentary technology. For example, the association rules learnt from patterns in data can provide knowledge that can be used to guide the search for Semantic Associations or to rank resulting Semantic Associations based on how close the follow the patterns.
6. CONCLUSION & FUTURE WORK
Most RDF query systems do not provide adequate querying paradigms to support querying for complex relationships such as Semantic Associations. Support for such querying capabilities is highly desirable in many domains. We have presented a formal framework for these Semantic Associations for the RDF data model, and reviewed some implementation strategies for computing them. There are many open research issues that we plan to focus on in the near future. First, it may be necessary to develop data organization techniques for data that will adequately the range of queries we are interesting support. Such techniques should eliminate the need for an excessive number of expensive computations such as joins during query processing. Secondly, we develop techniques for dealing with the space complexity problem of the indices used in the PathGuide. For example we may use encoding schemes that compress path information, or heuristics for managing the size of the indices. Another top priority is the development of ranking algorithms for ranking results of a query which takes into account a notion of context while ranking those results that are most relevant in the context highest. Finally, we will perform a comparative study of the two implementation strategies discussed in Section 4 over a testbed consisting of large amount of automatically extracted metadata generated using the SCORE system [41].
7. ACKNOWLEDGMENTS
Our thanks to Drs. Bob Robinson, John Miller, Krys Kochut, and Budak Arpinar for the illuminating discussions and insightful contributions, and to Boanerges Aleman-Meza on his revision comments. We are also indebted to Dr. Vassilis Christophides whose comments and suggestions were invaluable in preparing the final version of the paper.
This work is funded by NSF-ITR-IDM Award # 0219649 titled “Semantic Association Identification and Knowledge Discovery for National Security Applications.”
8. REFERENCES
[2] S. Abiteboul. Querying Semi-Structured data. In Proc. of ICDT, Jan 1997. http://citeseer.nj.nec.com/abiteboul97querying.html
[4] S. Abiteboul, R. Hull, and V. Vianu. Foundations of Databases. Addison-Wesley, 1995.
[5] Agrawal. Alpha: An Extension of Relational Algebra to Expressa Class of Recursive Queries. IEEE Transactions on Software Engineering. 14(7):879-- 885, July 1988
[9] S. Alexaki, G. Karvounarakis, V. Christophides, D. Plexousakis, and K. Tolle. On Storing Voluminous RDF descriptions: The case of Web Portal Catalogs. In 4th International Workshop on the Web and Databases (WebDB), Santa Barbara, CA, 2001. Available at http://139.91.183.30:9090/RDF/publications/webdb2001.pdf
[10] K. Anyanwu, A. Sheth, The r Operator: Discovering and Ranking Associations on the Semantic Web. SIGMOD Record ( Special issue on Amicalola Workshop), December 2002
[12] L. Babel, I. Ponomarenko, G. Tinhofer. The Isomorphism Problem for Directed Paths and For Rooted Directed Path Graphs. Journal of Algorithms, 21:542-564, 1996.
[13] T. Berners-Lee, J. Hendler, and O. Lassila. The Semantic Web. Scientific American, May 2001.
[15] A. Branstadt, V. B. Le, J. P. Spinrad. Graph Classes: A Survey. SIAM 1999
[16] T. Bray, J. Paoli, and C.M. Sperberg-McQueen. Extensible Markup Language (XML) 1.0. W3C Recommendation, February 1998.
[19] P. Buneman, M. Fernandez, D. Suciu. UnQL: A Query Language and Algebra for Semistructured Data Based on Structural Recursion. VLDB Journal, 9(1):76-- 110, 2000.
[20] W. W. Chang, A Discussion of the Relationship Between RDF-Schema and UML. A W3C Note, NOTE-rdf-uml-19980804.
[24] D. Chamberlin, D. Florescu, J. Robie, J. Simeon, and M. Stefanescu. XQuery: A Query Language for XML. Working draft, World Wide Web Consortium, June 2001. http://www.w3.org/TR/xquery/
[25] M. Dean, D. Connolly, F. Harmelen, J.Hendler, I. Horrocks, D. McGuinness, P. F. Patel-Schneider, and L.Stein. OWL Web Ontology Language 1.0 Reference, W3C Working Draft 29 July 2002. Latest version is available at http://www.w3.org/TR/owl-ref/.
[27] R. Fikes. DAML+OIL query language proposal, August 2001. http://www.daml.org/listarchive/joint-committee/0572.html.
[28] R. H. Guting. GraphDB: Modeling and querying graphs in databases. In Proceedings of the International Conference on Very Large Data Bases, pp. 297--308, 1994
[32] M. Hearst. Distinguishing between Web Data Mining and Information Access. Position statement for Web Data Mining KDD 97
[33] Y. E. Ioannidis, R. Ramakrishnan, L.Winger: Transitive Closure Algorithms Based on Graph Traversal. TODS 18(3): 512-576 (1993)
[35] P. Hayes. RDF Model Theory. W3C Working Draft, September 2001.
[36] I. Horrocks, S. Tessaris. The Semantics of DQL. http://www.cs.man.ac.uk/~horrocks/Private/DAML/DQL-semantics.pdf
[37] I. Horrocks and S. Tessaris. A Conjunctive Query Language for Description Logic Aboxes. In Proc. of AAAI-00, 2000
[38] V. Hristidis and Y. Papakonstanti-nou. DISCOVER : Keyword search in relational databases . In Procs. VLDB, Aug. 2002.
[39] ICS-FORTH. The ICS-FORTH RDFSuite web site. Available at http://139.91.183.30:9090/RDF , March 2002.
[40] G. Karvounarakis, S. Alexaki, V. Christophides, D. Plexousakis, M. Scholl, RQL: A Declarative Query Language for RDF, WWW2002, May 7-11, 2002, Honolulu, Hawaii, USA.
[41] M. S. Lacher and S.Decker. On the Integration of Topic Maps and RDF Data. In Proc. of Semantic Web Working Symposium. Palo Alto. California. August 2001
[43] M. Mannino, L. Shapiro, L. Extensions to Query Languages for Graph Traversal Problems. TKDE 2(3): 353--363,1990
[44] A. O. Mendelzon and P. T. Wood. Finding Regular Simple Paths in Graph Databases. SIAM J. Comput., 24(6):1235-1258, 1995.
[46] Nanopoulos A. and Manolopoulos Y.: “ Mining Patterns from Graph Traversals”, Data and Knowledge Engineering, Vol.37, No.3, pp.243-266, 2001.
[48] A. Seaborne. RDQL: A Data Oriented Query Language for RDF Models. 2001. http://www.hpl.hp.com/semweb/rdql-grammar.html
[49] A. Sheth, C. Bertram, D. Avant, B. Hammond, K. Kochut, Y. Warke, Semantic Content Management for Enterprises and the Web, IEEE Internet Computing, July/August 2002, pp. 80-87.
[51] M. Sintek and S. Decker. TRIPLE---A Query, Inference, and Transformation Language for the Semantic Web. International Semantic Web Conference (ISWC), Sardinia, June 2002. (http://www.dfki.uni-kl.de/frodo/triple/ )
[53] DQL: DAML Query Language. http://www.daml.org/2002/08/dql/
[54] Inkling: RDF query using SquishQL, 2001. http://swordfish.rdfweb.org/rdfquery/.
[55] ISO/IEC 13250: 2000 Topic Maps , Jan 2000 http://www.topicmaps.org/
[56] JENA - A Java API for RDF. http://www-uk.hpl.hp.com/people/bwm/rdf/jena/index.htm.
[57] Whitepaper on National Security and Intelligence, Semagix Inc. 2002. http://www.semagix.com/pdf/national_security.pdf