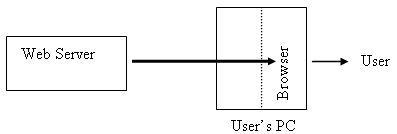
Figure 1. Document Browsing on PC
Access to the Internet through mobile phones and other handheld devices is growing significantly in recent years. The Wireless Application Protocol (WAP) and Wireless Markup Language (WML) provide the universal open standard and markup language. In this age of information, many information-centric applications have been developed for the handheld devices [4][5][6][7][25]. For example, users can now surf the web, check e-mail, read news, quote stock price, etc. using handheld devices. At present, most of mobile applications are customer-centered m-services applications. However, the mobile computing should not be limited to user-centered applications only. It should be extended to decision support in an m-commerce organization. With a fast paced economy, organization needs to make decisions as fast as possible, access to large text documents or other information sources is important during decision making. There is an increasing need for corporate knowledge management, m-commerce organizations must gain competitive advantage by having access to the most current and accurate information available to help them to make better decision. As a result, there is an urgent need of a tool for browsing large document on handheld devices. The convenience of handheld devices allows information access without geometric limitation; however, there are other limitations of handheld devices that restrict their capability.
Although the development of wireless handheld devices is fast in recent years, there are many shortcomings associated with these devices, such as screen size, bandwidth, and memory capacity. There are two major categories of wireless handheld devices, namely, WAP-enabled mobile phones and wireless PDAs. At present, the typical display size of popular WAP-enabled handsets and PDAs are relatively small in comparison with a standard personal computer. The memory capacity of a handheld device greatly limits the amount of information that can be stored. A large document cannot be entirely downloaded to the handheld device and present to user directly. The current bandwidth available for WAP is relatively narrow. It is not comparable with the broadband internet connection for PC.
Although handheld devices are convenient, they impose other constraints that do not exist on desktop computers. The low bandwidth and small resolution are major shortcomings of handheld devices. Information overloading is a critical problem; advance-searching techniques solve the problem by filtering most of the irrelevant information. However, the precision of most of the commercial search engines is not high. Users may only find a few relevant documents out of a large pool of searching result. Given the large screen and high bandwidth for desktop computing, users may still need to browse the searching result one by one and identify the relevant information using desktop computers. However, it is impossible to search and visualize the critical information on a small screen with an intolerable slow downloading speed using handheld devices. Automatic summarization summarizes a document for users to preview its major content. Users may determine if the information fits their needs by reading their summary instead of browsing the whole document one by one. The amount of information displayed and downloading time are significantly reduced.
Traditional automatic summarization does not consider the structure of document but considers the document as a sequence of sentences. Most of the traditional summarization systems extracted sentences from the source document and concatenated together as summary. However, it is believed that the document summarization on handheld devices must make use of "tree view" [6] or "hierarchical display" [23]. Similar techniques have been applied to web browsing [3], an outline processor organizes the web page in a tree structure and the user click the link to expand the subsection and view the detail. Hierarchical display is suitable for navigation of a large document and it is ideal for small area display. Therefore, a new summarization model with hierarchical display is required for summarization on mobile devices.
Summarization on mobile devices has been investigated. Buyukkokten et al. presented the summarization of web pages on handheld devices [4][5][6][7]. However, a large document exhibits totally different characteristics from web pages. A web page usually contains a small number of sentences that are organized into paragraphs, but a large document contains much more sentences that are organized into a more complex hierarchical structure. Besides, the summarization on webpage is mainly based on thematic features only [5]. However, it has been proved that other document features play role as important as the thematic feature [8][16]. Therefore, a more advance summarization model combined with other document features is required for browsing of large document on handheld devices.
In this paper, we propose the fractal summarization model based on the statistical data and the structure of documents. Thematic feature, location feature, heading feature, and cue features are adopted. Summarization is generated interactively. Experiments have been conducted and the results show that the fractal summarization outperforms the traditional summarization. In addition, information visualization techniques are presented to reduce the visual loads. Three-tier architecture which reduces the computing load of the handheld devices is also discussed.
Two-tier architecture is typically utilized for Internet access. The user's PC connects to the Internet directly, and the content loaded will be fed to the web browser and present to the user as illustrated in Figure 1.
Figure 1. Document Browsing on PC
Due to the information-overloading problem, a summarizer is introduced to summarize a document for users to preview before presenting the whole document. As shown in Figure 2, the content will be first fed to the summarizer after loading to the user's PC. The summarizer connects to database server when necessary and generates a summary to display on the browser.
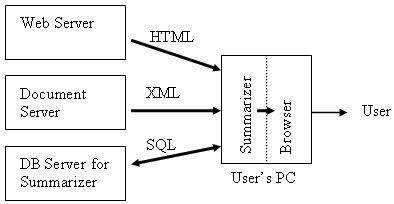
Figure 2. Document Browsing with Summarizer on PC
The two-tier architecture cannot be applied on handheld devices since the computing power of handheld devices is insufficient to perform summarization and the network connection of mobile network does not provide sufficient bandwidth for navigation between the summarizer and other servers.
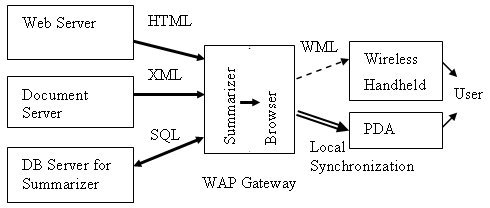
Figure 3. Document Browsing with Summarizer on WAP
The three-tier architecture as illustrated in Figure 3 is proposed. A WAP gateway is setup to process the summarization. The WAP gateway connects to Internet trough broadband network. The wireless handheld devices can conduct interactive navigation with the gateway through wireless network to retrieve the summary piece by piece. Alternatively, if the PDA is equipped with more memory, the complete summary can be downloaded to PDA through local synchronization.
Because there are a lot of shortcomings associated with handheld devices, the traditional summarization model cannot be implemented on handheld device. A novel summarization model based on hierarchical document structure and fractal theory will be presented.
Traditional automatic text summarization is the selection of sentences from the source document based on their significance to the document [8][21]. The selection of sentences is conducted based on the salient features of the document. The thematic, location, heading, and cue features are the most widely used summarization features.
Typical summarization systems select a combination of summarization features [8][19][20, the total sentence weight (Wsen) is calculated as,
Wsen=a1 x wthematic+a2 x wlocation+a3 x wheading+a4 x wcue
where wthematic, wlocation, wheading and wcue are thematic weight, location weight, heading weight and cue weight of the sentence respectively; and a1, a2, a3, and a4 are positive integers to adjust the weighting of four summarization features. The sentences with sentence weight higher than a threshold are selected as part of the summary. It has been proved that the weighting of different summarization features do not have any substantial effect on the average precision [19]. In our experiment, the maximum weight of each feature is normalized to one, and the total weight of sentence is calculated as the sum of scores of all summarization features without weighting.
Fractals are mathematical objects that have high degree of redundancy [22]. These objects are made of transformed copies of themselves or part of themselves (Figure 4). Mandelbrot was the first person who investigated the fractal geometry and developed the fractal theory [22]. In his well known example, the length of the British coastline depends on measurement scale. The larger the scale is, the smaller value of the length of the coastline is and the higher the abstraction level is. The British coastline includes bays and peninsulas. Bays include sub-bays and peninsulas include sub-peninsulas. Using fractals to represent these structures, abstraction of the British coastline can be generated with different abstraction degrees. Fractal theory is grounded in geometry and dimension theory. Fractals are independent of scale and appear equally detailed at any level of magnification. Such property is known as self-similarity. Any portion of a self-similar fractal curve appears identical to the whole curve. If we shrink or enlarge a fractal pattern, its appearance remains unchanged.
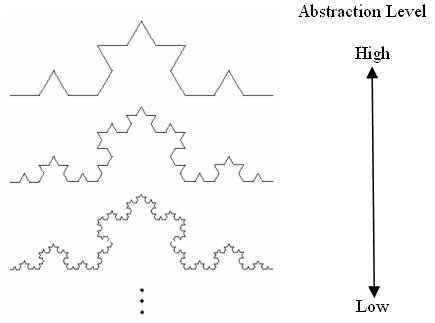
Figure 4. Koch Curve at Different Abstractions Level.
Fractal view is a fractal-based method for controlling information displayed [17]. Fractal view provides an approximation mechanism for the observer to adjust the abstraction level and therefore control the amount of information displayed. At a lower abstraction level, more details of the fractal object can be viewed.
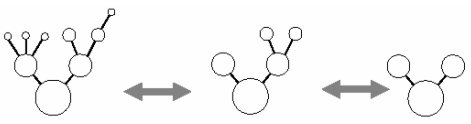
Figure 5. Fractal View for Logical Trees at Different Level.
A physical tree is one of classical example of fractal objects. A tree is made of a lot of sub-trees; each of them is also tree. By changing the scale, the different levels of abstraction views are obtained (Figure 5). The idea of fractal tree can be extended to any logical tree. The degree of importance of each node is represented by its fractal value. The fractal value of focus is set to 1. Regarding the focus as a new root, we propagate the fractal value to other nodes with the following expression:
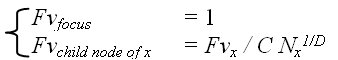
where Fvx is the fractal value of node x; C is a constant between 0 and 1 to control rate of decade; Nx is the number of child-nodes of node x; and D is the fractal dimension.
A threshold value is chosen to control the amount of information displayed, the nodes with a fractal value less than the threshold value will be hidden (Figure 6). By change the threshold value, the user can adjust the amount of information displayed.
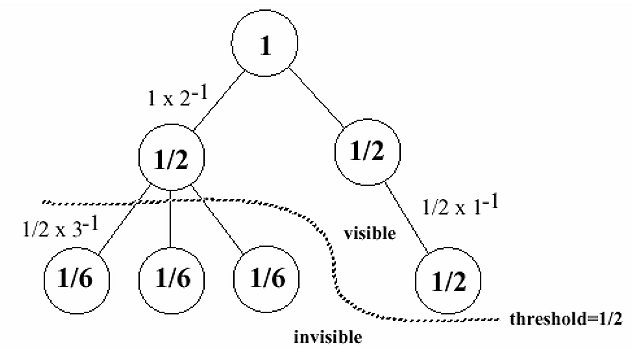
Figure 6. An Example of the Propagation of Fractal Values.
Advance summarization techniques take the document structure into consideration to compute the probability of a sentence to be included in the summary. Many studies [9][11] of human abstraction process has shown that the human abstractors extract the topic sentences according to the document structure from the top level to the low level until they have extracted sufficient information. However, most traditional automatic summarization models consider the source document as a sequence of sentences but ignoring the structure of document. Some summarization systems may calculate sentence weight partially based on the document structure, but they still extract sentences in a linear space. In conclusion, none of the traditional summarization model is entirely based on document structure. Fractal Summarization Model is proposed here to generate summary based on document structure. Fractal summarization generates a brief skeleton of summary at the first stage, and the details of the summary on different levels of the document are generated on demands of users. Such interactive summarization reduces the computation load in comparing with the generation of the entire summary in one batch by the traditional automatic summarization, which is ideal for m-commerce.
Fractal summarization is developed based on the fractal theory. In our fractal summarization, the important information is captured from the source text by exploring the hierarchical structure and salient features of the document. A condensed version of the document that is informatively close to the original is produced iteratively using the contractive transformation in the fractal theory. Similar to the fractal geometry applying on the British coastline where the coastline includes bays, peninsulas, sub-bays, and sub-peninsulas, large document has a hierarchical structure with several levels, chapters, sections, subsections, paragraphs, sentences, and terms. A document is considered as prefractal that are fractal structures in their early stage with finite recursion only [10].
A document can be represented by a hierarchical structure as shown on Figure 7. A document consists of chapters. A chapter consists of sections. A section may consist of subsections. A section or subsection consists of paragraphs. A paragraph consists of sentences. A sentence consists of terms. A term consists of words. A word consists of characters. A document structure can be considered as a fractal structure. At the lower abstraction level of a document, more specific information can be obtained. Although a document is not a true mathematical fractal object since a document cannot be viewed in an infinite abstraction level, we may consider a document as a prefractal. The smallest unit in a document is character; however, neither a character nor a word will convey any meaningful information concerning the overall content of a document. The lowest abstraction level in our consideration is a term.
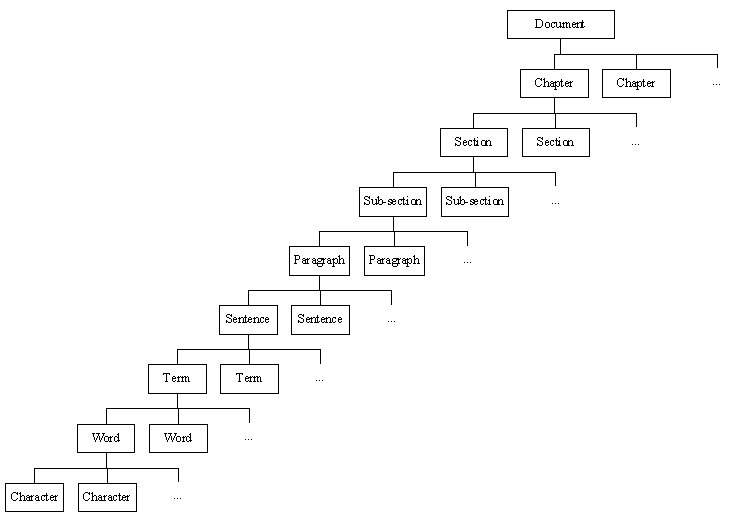
Figure 7. Prefractal Structure of Document
The Fractal Summarization Model applies a similar technique as fractal view and fractal image compression [1][15]. An image is regularly segmented into sets of non-overlapping square blocks, called range blocks, and then each range block is subdivided into sub range blocks, until a contractive mapping can be found to represent this sub range block. The Fractal Summarization Model generates the summary by a simple recursive deterministic algorithm based on the iterated representation of a document. The original document is represented as fractal tree structure according to its document structure. The fractal value of each node is calculated by the sum of sentence weights under the node by traditional summarization methods.
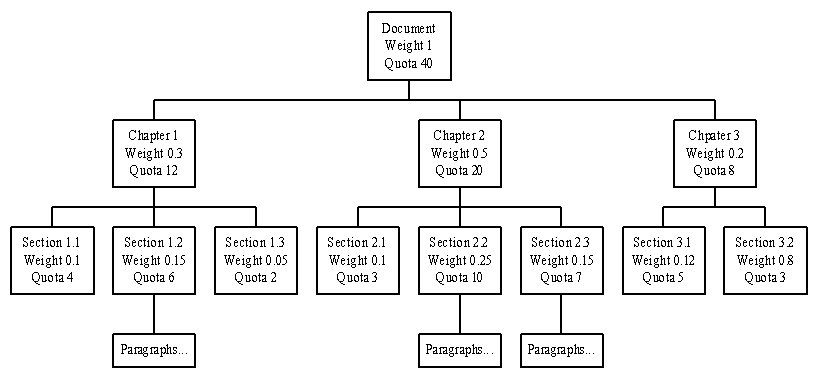
Figure 8. An Example of Fractal Summarization Model
Given a document, a user will specify compression ratio to specific the amount of information displayed. The summarization system calculates the number of sentences to be extracted as summary accordingly and the system assigns the number of sentences to the root as the quota of sentences. The quota of sentences is allocated to child-nodes by propagation, i.e., the quota of parent node is shared by its child-nodes directly proportional to the fractal value of the child-nodes. The quota is then iteratively allocated to child-nodes of child-nodes until the quota allocated is less than a threshold value and the range-block can be transformed to some key sentences by traditional summarization methods (Figure 8). The detail of the Fractal Summarization Model is shown as the following algorithm:
Fractal Summarization Algorithm

The compression ratio of summarization is defined as the ratio of number of sentences in the summary to the number of sentences in the source document. It was chosen as 25% in most literatures because it has been proved that extraction of 20% sentences can be as informative as the full text of the source document [24], those summarization systems can achieve up to a 96% precision [8][16][28]. However, Teufel pointed out the high-compression ratio abstracting is more useful, and 49.6% of precision is reported at 4% compression ratio [27]. In order to minimize the bandwidth requirement and reduce the pressure on computing power of handheld devices, the default value of compression ratio is chosen as 4%. By the definition of compression ratio, the sentence quota of the summary can be calculated by the number of sentences in the source document times the compression ratio.
A threshold value is the maximum number of sentences can be extracted from a range block, if the quota is larger than the threshold value, and the range block must be divided into sub-range block. Document summarization is different from image compression, more than one attractor can be chosen in one range block. It is proven that the summarization by extraction of fixed number of sentences, the optimal length of summary is 3 to 5 sentences [12]. The default value of threshold is chosen as 5 in our system.
The weights of sentences under a range block are calculated by the traditional summarization methods described in Section 3.1. However, the traditional summarization features cannot fully utilize the fractal model of a document. In traditional summarization mode, the sentence weight is static through the whole summarization process, but the sentence weight should depend on the abstract level at which the document is currently viewing at, and we will show how the summarization features can integrate with the fractal structure of document.
Among the thematic features proposed previously, the tfidf score of keyword is the most widely used approach; however, in the traditional summarization, it does not take into account of the document structure, therefore modification of the tfidf formulation is derived to capture the document structure and reflect the significance of a term within a range block.
tfidf score of term ti is calculated as followed:
wij = tfij log2 (N/n |ti|)
where wij is the weights of term ti in document dj, tfij is the frequency of term ti in document dj, N is the number of documents in the corpus, n is the number of documents in the corpus in which term ti occurs, and |ti| is the length of the term ti.
Many researchers assume that the weight of a term remains the same over the entire document. However, Hearst thinks that a term should carry different weight in different location of a full-length document [14]. For example, a term appears in chapter A once and appears in chapter B a lot of times, the term is obviously more important in chapter B than in chapter A. This idea can be extended to other document levels, if you look at document-level, a specific term inside a document should carry same weight, if you look at chapter-level, a specific term inside a chapter should carry same weight but the a specific term inside two chapters may carry different weight, etc.
As a result, the tfidf score should be modified to different document levels instead of whole document. In fractal summarization model, the tfidf should be defined as term frequency within a range block inversely proportional to frequency of range blocks containing the term, i.e.
wir = tfir log2 (N'/n' |ti|)
Here, wir is the weights of term ti in range block r, tfir is the frequency of term ti in range block r, N' is the number of range blocks in the corpus, n' is the number of range blocks in the corpus in which term ti occurs, and |ti| is the length of the term ti.
Table 1. tfidf Score of the Term, 'Hong Kong', at Different Document Levels
| Term frequency | Text block frequency | No of Text Block | tfidf Score | |
|---|---|---|---|---|
| Document-Level | 1113 | 1 | 1 | 3528 |
| Chapter-Level | 70 | 23 | 23 | 222 |
| Section-Level | 69 | 247 | 358 | 256 |
| Subsection-Level | 16 | 405 | 794 | 66 |
| Paragraph-Level | 2 | 787 | 2580 | 10 |
| Sentence-Level | 1 | 1113 | 8053 | 6 |
Taking the 'Hong Kong' in the first chapter, first section, first subsection, first paragraph, first sentence of Hong Kong Annual Report 2000 as an example (Table 1), the tfidf score at different document levels differ a lot, the maximum value is 3528 at document-level, and minimum 6 at sentence-level.
Traditional summarization systems assume that the location weight of a sentence is static, where the location weight of a sentence is fixed. However, the fractal summarization model adopts a dynamic approach; the location weight of sentence depends on which document level you are viewing at.
As it is known that the significance of a sentence is affected by the location of the sentence inside a document. For example, the sentences at the beginning and the ending of document are usually more important than the others. If we consider the first and second sentences on the same paragraph at the paragraph-level, the first sentence has much more impact on the paragraph than the second sentence. However, the difference of importance of two consecutive sentences is insignificant at the document-level. Therefore, the importance of the sentence due to its location should depend on the level we are considering.
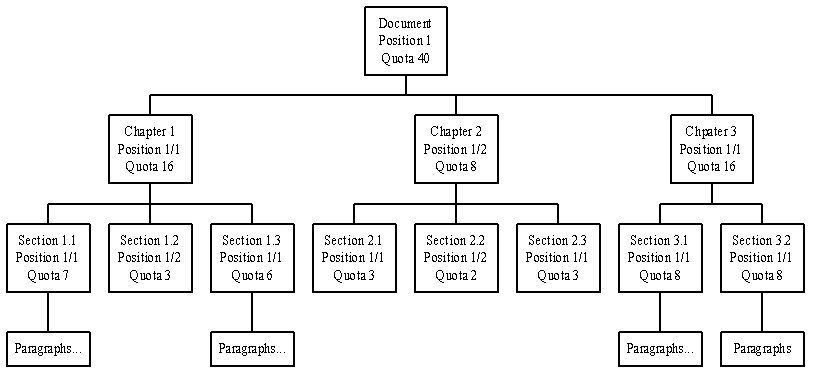
Figure 9. The Fractal Summary with Location Feature Only.
In the fractal summarization model, we calculate the location weight for a range block instead of individual sentence, all the sentences within a range block will receive same location weight. The location weight of a range block is 1/p, where p is the shortest distance of the range block to the first or last range block under same parent range block. Consider the previous example of generic Fractal Summarization Model (Figure 8), the new quota system is changed to Figure 9 if only location feature is considered.
The heading weight of sentence is dynamic and it depends on which level we are currently looking at the document. At different abstraction level, some headings should be hidden and some headings must be emphasized.
Taking the first sentence from the first chapter, first section, first subsection, and first paragraph as an example, if we consider at the document-level, only the document heading should be considered. However, if we consider at the chapter-level, then we should consider the document heading as well as the chapter heading. Since the main topic of this chapter is represented by the chapter heading, therefore the terms appearing in the chapter heading should have a greater impact on the sentence. Most the internal nodes above the paragraph-level in the document tree usually associate with a heading and there are two types of heading, structural heading and informative heading. For the structural headings, they indicate the structure of the document only, but not any information about the content of the document; for example, "Introduction", "Overview" and "Conclusion" are structural headings. The informative headings can give us an abstract of the content of the branch, and they help us to understand the content of the document, and they are used for calculation of heading weight. On the other hand, the structural headings can be easily isolated by string matching with a dictionary of those structural headings, and they will be used for cue feature at sub-section 3.2.4.
The terms in the informative headings are very important in extracting the sentences for summarization. Given a sentence in a paragraph, the headings of its corresponding subsection, section, chapter, and document should be considered. The significance of a term in the heading is also affected by the distance between the sentence and the heading in terms of depth in the hierarchical structure of the document. Propagation of fractal value [17] is a promising approach to calculate the heading weight for a sentence.
The first sentence of Section 3.1 in this paper is taken as an example to illustrate the propagation of the heading weight. As shown in Figure 10, the sentence, "Traditional automatic text summarization is the selection of sentences from the source document based on their significance to the document", is located in Section 3.1, where the heading of Section 3.1 is "Traditional Summarization", the heading of Section 3 is "Automatic Summarization", and the heading of the document is "Fractal Summarization for Mobile Devices to Access Large Document on the Web". To compute the heading weight of the sentence, we shall propagate the term weight of the terms that appearing in both the sentence and the headings based on the distance between the headings and the sentences and the degrees of the heading node.
wheading = wheading in document + wheading in section+ wheading in subsection
where
wheading in document = (w"summarization" + 3 x w"document") in headingdocument / (8x3)
wheading in section = (w"automatic"+w"summarization") in headingsection 3 / 3
wheading in subsection = (w"traditional"+w"summarization") in headingsubsection 3.1
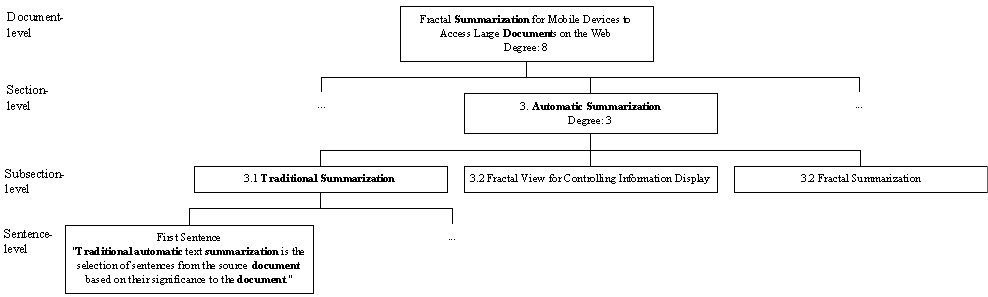
Figure 10. Example of Heading Feature in Fractal Summarization.
The abstracting process of human abstractors can help to understand the cue feature at different document levels. When human abstractors extract the sentences from a document, they will follow the document structure to search the topic sentences. During the searching of information, they will pay more attention to the range block with heading contains some bonus words such as "Conclusion", since they consider it as a more important part in the document and they extract more information for those important parts. The cue feature of heading sentence is usually classified as rhetorical feature [27].
As a result, we proposed to consider the cue feature not only in sentence-level, but also in other document levels. Give a document tree, we will examine the heading of each range block by the method of cue feature and adjust their quota of entire range block accordingly. This procedure can be repeated to sub range blocks until sentence-level.
It is believed that a full-length text document contains a set of subtopics [14] and a good quality summary should cover as many subtopics as possible, the fractal summarization model will produce a summary with a wider coverage of information subtopic than traditional summarization model.
The traditional summarization model extracts most of sentences from few chapters, take the Hong Kong Annual Report 2000 as an example (Table 2), the traditional summarization model extracts 29 sentences from one chapter when the sentence quota is 80 sentences, and total 53 sentences are extracted from top 3 chapters out of total 23 chapters, no sentence is extracted from 8 chapters. However, the fractal summarization model extracts the sentences distributively from each chapter. In our example, it extracts maximum 8 sentences from one single chapter, and at least one sentence is extracted from each chapter. The standard deviation of sentence number extracted from chapters is 2.11 sentences in fractal summarization against 6.55 sentences in traditional summarization.
Table 2. No. of Sentences Extracted by Two Summarization Models from Hong Kong Annual Report 2000.
| Fractal Summarization | Traditional Summarization | |
|---|---|---|
| Maximum No of sentences extracted from one single chapter | 8 | 29 |
| Minimum No of sentences extracted from one single chapter | 1 | 0 |
| Standard deviation of No of sentences extracted from chapters | 2.11 | 6.55 |
A user evaluation is conducted. Five subjects were asked to evaluate the quality of summaries of 23 documents generated by fractal summarization and traditional summarization with four unweighted features described in section 3.1. Both summaries of all documents are assigned to each subject in random order without telling the users the generation methods of the summaries. The results show that all subjects consider the summary generated by fractal summarization method as a better summary against the summary generated by traditional summarization model. In order to compare the result in more great detail, we calculate the precision as number of relevant sentences in the summary accepted by the user divided by the number of sentences in the summary (Table 3). The precision of the fractal summarization outperforms the traditional summarization. The fractal summarization can achieve up to 88.75% precision and 84% on average, while the traditional summarization can achieve up to maximum 77.5% precision and 67% on average.
Table 3. Precision of Two Summarization Models.
| User ID | Fractal Summarization | Traditional Summarization |
|---|---|---|
| 1 | 81.25% | 71.25% |
| 2 | 85.00% | 67.50% |
| 3 | 80.00% | 56.25% |
| 4 | 85.00% | 63.75% |
| 5 | 88.75% | 77.50% |
The summary generated by Fractal Summarization Model is represented in a hierarchical tree structure. The hierarchical structure of summary is suitable for visualization on handheld devices, and it can be further enhanced by two approaches, (i) Fractal View to adjust the size of the tree structure of summary (ii) displaying the sentences in different font sizes according to their importance to help user to focus on important information.
The fractal view [17] determines the size of the hierarchical tree for visualization; branches with fractal values less than a threshold are trimmed off. In the visualization of summaries generated by fractal summarizations, weights of sentences are computed based on the salient features; nodes with weights lower than a threshold will be hidden.
In additional to weights computed by the salient features, we control the information displayed according user's focus as well. Nodes that are further away from the focus point are considered less significant, the system should not describe them in same degree of detail as the focus point. Some detail information of the nodes that are further should be hidden. The quota allocated to the child node will change dynamically based on the user's focus point. The quota of sentences allocated to a child branch is calculated by a function of total sentence weight under the branch times the fractal value of the branch node base on the current user's view.
The original fractal value function does not adjust the magnification parameter of the focus point. The fractal value (Fv) function is modified to take the magnificent parameter into accounts:
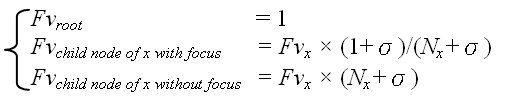
where Nx is the number of child nodes of node x, and the magnification parameter (σ) is a non-negative real number to change magnification effect. The larger the value is, the higher the magnification effect is. If the value is set to 0, there is no magnification effect.
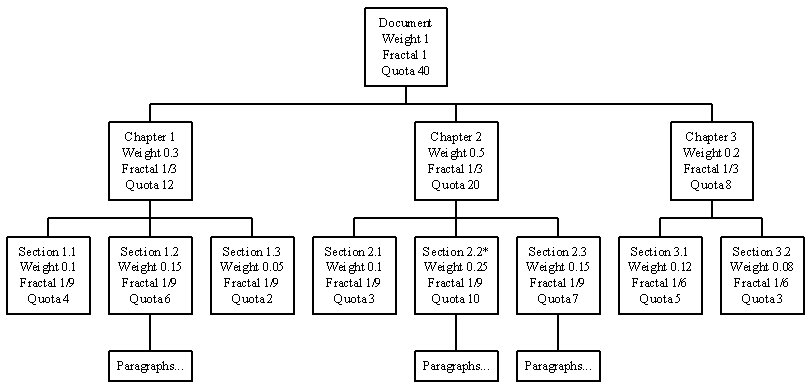
(a) σ=0
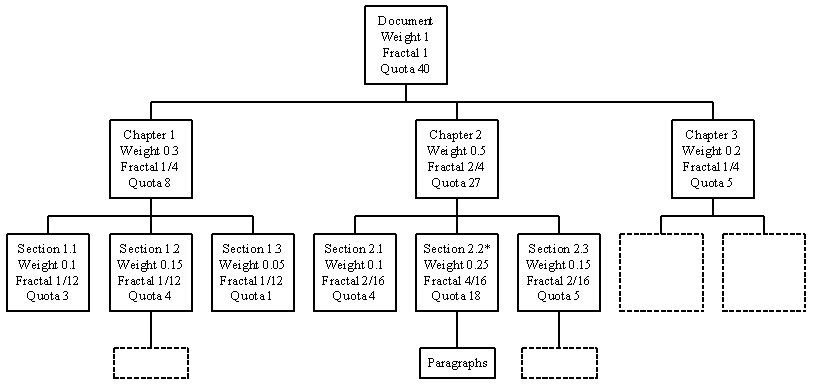
(b) σ=1
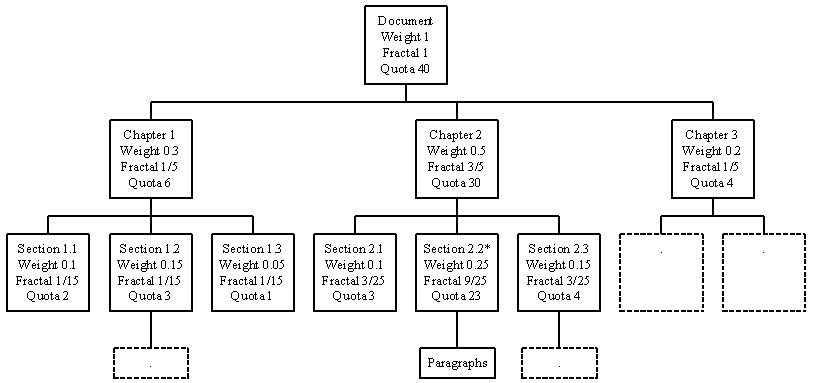
(c) σ=2
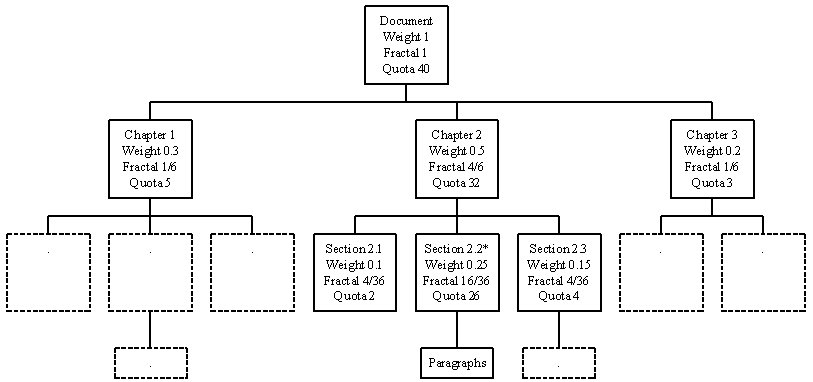
(d) σ=3
Figure 11. Fractal Summary with Magnification Parameter = 0, 1, 2, 3.
Consider the previous example in Figure 8, if the user change his focus point to Section 2.2, then the quota assigning to the nodes in the hierarchal will be changed accordingly (Figure 11). Since the quotas of some nodes are reduced significantly, they will be collapsed into a single node. On the other hand, since a large value of quota is allocated to the node with focus, it may need to stretch out to sub-levels.
where Nx is the number of child nodes of node x, and σ is a non-negative real number to change magnification effect as fisheye view. The larger the value is, the higher the magnification effect is. If the value is set of 0, there is no magnification effect.
Consider the previous example in Figure 8, if the user change his focus point to Section 2.2, then the quota system will change a lot (Figure 12). Since the quotas of some nodes are greatly cut, therefore they will collapse into a single node. On the other hand, since a large value of quota is allocated to the node with focus, it may need to be stretched out to sub-levels.
A summary displayed in small area without visualization effect is difficult to read. Displaying the sentences in different font size according to their importance can help user to focus on important information.
WML is the markup language supported by wireless handheld devices. The basic unit of a WML file is a deck; each deck must contain one or more cards. The card element defines the content displayed to users, and the card cannot be nested. Each card links to another card within or across decks. Nodes on the fractal tree of fractal summarization model are converted into cards, and anchor links are utilized to implement the tree structure. Given a card of a summary node, there may be a lot of sentences or child-nodes. A large number of sentences in a small display area make it difficult to read. In our system, the sentences are displayed in different font size according to their significance. We have implemented the system with 3-scale font mode available for WML. The sentences or child-nodes are sorted by their sentence weights or fractal value and separated evenly into 3 groups. The group with highest value is displayed in "Large" font size, and the group with middle value and the group with lowest value are displayed in "Normal" and "Small" font size respectively.
The prototype system using Nokia Handset Simulator is presented on Figure 12 and Figure 13. The document presenting is the Hong Kong Annual Report 2000. There are totally 23 chapters in the annual report, 8 of them are in large font, which means that they are more important, and the rest are in normal font or small font according to their importance to the report (Figure 12). The number inside the parentheses indicates the number of sentences under the node that are extracted as part of the summary.

Figure 12. Screen Capture of WAP Summarization System (Hong Kong Annual Report 2000)
The main screen of the Hong Kong Annual Report 2000 gives user a general idea of overall information contents and the importance of each chapter. If the user wants to explore a particular node, user can click the anchor link, and the mobile device sends the request to the WAP gateway, and the gateway then decides whether to deliver another menu or the summary of the node to the user depends on its fractal value and quota allocated. Figure 13 shows the summary of Chapter 19 of Hong Kong Annual Report 2002, "Communication, the Media and Information Technology".

Figure 13. Screen Capture of WAP Summarization System (Chapter 19 of Hong Kong Annual Report 2000, 'Communications, the Media and Information Technology')
A handheld PDA is usually equipped with more memory, and the complete summary can downloaded as a single WML file to the PDA through local synchronization. To read the summary, the PDA is required to install a standard WML file reader, i.e. KWML for Palm [18].
Mobile commerce is a promising addition to the electronic commerce by the adoption of portable handheld devices. However, there are many shortcomings of the handheld devices, such as limited resolution and low bandwidth. In order to overcome the shortcomings, fractal summarization and information visualization are proposed in this paper. The fractal summarization creates a summary in tree structure and presents the summary to the handheld devices through cards in WML. The adoption of thematic feature, location feature, heading feature, and cue feature are discussed. Users may browse the selected summary by clicking the anchor links from the highest abstraction level to the lowest abstraction level. Based on the sentence weight computed by the summarization technique, the sentences are displayed in different font size to enlarge the focus of interest and diminish the less significant sentences. Fractal views are utilized to filter the less important nodes in the document structure. Such visualization effect draws users' attention on the important content. The three-tier architecture is presented to reduce the computing load of the handheld devices. The proposed system creates an information visualization environment to avoid the existing shortcomings of handheld devices for mobile commerce.
[1]: Application of recurrent iterated function systems to images. , In Proceedings SPIE Visual Communications and Image Processing'88, 1001, 122-131, 1988.
[2]: Machine-Made Index for Technical Literature - An Experiment. , IBM Journal (October), 354-361, 1958.
[3]: Zippers: A Focus+Context Display of Web Pages. , In Proceedings of WebNet'96, 1996.
[4]: Power Browser: Efficient Web Browsing for PDAs. , Human-Computer Interaction Conference 2000. Hague, The Netherlands, 2000.
[5]: Seeing the Whole in Parts: Text Summarization for Web Browsing on Handheld Devices. , In Proceedings of the 10th International WWW Conference. (WWW10). Hong Kong, 2001.
[6]: Accordion Summarization for End-Game Browsing on PDAs and Cellular Phones. , Human-Computer Interaction Conf. 2001 (CHI 2001). Washington, 2001.
[7]: Text Summarization of Web pages on Handheld Devices. , In Proc. of Workshop on Automatic Summarization 2001 in conj. with NAACL 2001, 2001.
[8]: New Method in Automatic Extraction. Journal of the ACM, 16(2) 264-285, 1968.
[9]: How to Implement a Naturalistic Model of Abstracting: Four Core Working Steps of an Expert Abstractor. , Information Processing and Management 31(5) 631-674, 1995.
[10: Fractals., Plenum, New York, 1988.
[11]: The discovery of grounded theory; strategies for qualitative research., Aldine de Gruyter, New York, 1967.
[12]: Summarizing text documents: Sentence selection and evaluation metrics., In Proceedings of SIGIR'99, 121-128, 1999.
[13]: Ranking algorithms., In Information Retrieval: Data Structures and Algorithms, W.B. Frakes and R. Baeza-Yates, Eds, chapter 14, Prentice-Hall, 363-392, 1992.
[14]: Subtopic Structuring for Full-Length Document Access., In Proc. of the 16th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, 56-68, 1993.
[15]: Fractal image coding: A review., In Proceeding of the IEEE, 81(10) 1451-1465.
[16]: A Trainable Document Summarizer., In Proc. of the 18th Annual International ACM Conference on Research and Development in Information Retrieval (SIGIR), 68-73, 1993.
[17]: Fractal Views: A Fractal-Based Method for Controlling Information Display,, ACM Transactions on Information Systems, ACM, 13(3) 305-323, 1995.
[18]: KWML - KVM WML (WAP) Browser on Palm., http://www.jshape.com/kwml/index.html, 2002
[19]: Applying summarization Techniques for Term Selection in Relevance Feedback,, In Proceeding of SIGIR 2001, 1-9, 2001
[20]: Identifying Topics by Position. , In Proc. of the Applied Natural Language Processing Conference (ANLP-97), Washington, DC, 283-290, 1997.
[21]: The Automatic Creation of Literature Abstracts., IBM Journal of Research and Development, 159-165, 1958.
[22]: The fractal geometry of nature,, New York: W.H. Freeman, 1983.
[23]: Recent Development in Text Summarization,, ACM CIKM '01, pp 529-531, Georgia, USA, 2001.
[24]: The effect and limitation of automated text condensing on reading comprehension performance, , Information System Research, 17-35, 1992.
[25]: PALM: Providing Fluid Connectivity in a Wireless World,, White Paper of Palm Inc., http://www.palm.com/wireless/ProvidingFluidConnectivity.pdf. 2002
[26]: Term-Weighting Approaches in Automatic Text Retrieval, , Information Processing and Management, 24, 513-523, 1988.
[27]: Sentence Extraction and rhetorical classification for flexible abstracts, , AAAI Spring Symposium on Intelligent Text summarization, Stanford, 1998.
[28]: Sentence Extraction as a Classification Task, , In Workshop of 'Intelligent and Scalable Text Summarization', ACL/EACL, 1997.