 |
| Sean C. Rhea | Kevin Liang | Eric Brewer |
| srhea@cs.berkeley.edu | asiavu3@uclink4.berkeley.edu | brewer@cs.berkeley.edu |
Department of Electrical Engineering and Computer Science
University of California, Berkeley
Berkeley, CA 94720-1776
Copyright
is held by the author/owner(s).
WWW2003, May 20-24, 2003, Budapest, Hungary.
ACM 1-58113-680-3/03/0005.
Despite traditional web caching techniques, redundant data is often transferred over HTTP links. These redundant transfers result from both resource modification and aliasing. Resource modification causes the data represented by a single URI to change; often, in transferring the new data, some old data is retransmitted. Aliasing, in contrast, occurs when the same data is named by multiple URIs, often in the context of dynamic or advertising content. Traditional web caching techniques index data by its name and thus often fail to recognize and take advantage of aliasing.
In this work we present Value-Based Web Caching, a technique that eliminates redundant data transfers due to both resource modification and aliasing using the same algorithm. This algorithm caches data based on its value, rather than its name. It is designed for use between a parent and child proxy over a low bandwidth link, and in the common case it requires no additional message round trips. The parent proxy stores a small amount of soft-state per client that it uses to eliminate redundant transfers. The additional computational requirements on the parent proxy are small, and there are virtually no additional computational or storage requirements on the child proxy. Finally, our algorithm allows the parent proxy to serve simultaneously as a traditional web cache and is orthogonal to other bandwidth-saving measures such as data compression. In our experiments, this algorithm yields a significant reduction in both bandwidth usage and user-perceived time-to-display versus traditional web caching.
C.2.2 [Computer-Communications Networks]: Network Protocols--Applications; C.2.4 [Computer-Communications Networks]: Distributed Systems--Client/server
Algorithms, Performance, Design, Experimentation, Security
aliasing, caching, duplicate suppression, dynamic content, HTTP, Hypertext Transfer Protocol, privacy, proxy, redundant transfers, resource modification, scalability, World Wide Web, WWW
With the widespread deployment of broadband, it is often assumed that bandwidth is becoming cheap for the common Internet user. Although this notion is true to an extent, a surprising number of users still connect to the Internet over 56 kbps modems. America Online, for example, has 33 million users who connect primarily via modems, and many other Internet service providers (ISPs) primarily support modem users. Moreover, the emerging deployment of universal wireless connectivity ushers in a new wave of users connecting over low-bandwidth links. In this paper we present a technique called Value-Based Web Caching (VBWC) that aims to mitigate the limitations of such connections.
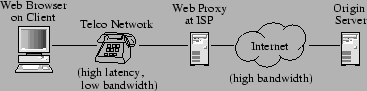
We begin by assuming that our user has a very low-bandwidth (less than 80 kb/s) connection over a telephone or wireless network to an ISP, as illustrated in Figure 1. This service provider may run a web-proxy and/or cache on behalf of the user and is in turn connected to the Internet at large. In such a situation, the bandwidth through the telephone or wireless network is a fundamental limitation of the system; it is the largest contributor to client-perceived latency for many files. For example, in 1996 Mogul et al. [14] found that the average response size for a successful HTTP request was 7,882 bytes, which takes a little over a second to transmit over a modem; in contrast, the round-trip time between the client and server more often falls in the 100-300 ms range. Other traces show mean response sizes of over 21 kB [10].
In the Mogul et al. study, the authors also showed that much of the limited bandwidth available to clients was being wasted. Some of this waste is easy to eliminate: as many as 76.7% of the full-body responses in the studied trace were shortened by simple gzip compression, resulting in a total savings of 39.4% of the bytes transferred. Other bandwidth waste is more difficult to correct.
|
|
One example of bandwidth waste that is difficult to eliminate occurs when the data represented by a single Uniform Resource Identifier (URI) changes by small amounts over time. This phenomenon is called resource modification; it it tends to occur often with news sites such as cnn.com. Mogul et al. showed that 25-30% of successful, text-based responses were caused by resource modification, and they found that using delta encoding over the response bodies eliminated around 50% of the data transferred. Our results confirm that when used between the requesting client and the origin server, delta encoding produces significant reductions in bandwidth consumed.
When an origin server does not compute deltas itself, a proxy may compute them on behalf of clients. Banga, Douglis, and Rabinovich proposed optimistic deltas [2], in which a web cache sends an old version of a given resource to a client over a low bandwidth link immediately after receiving a request for it. The cache then requests the current version of the resource from the origin server, and sends a delta to the client if necessary. To provide for the largest number of possible optimistic responses for dynamic web page content, it is desirable that the cache be able to transmit the response sent by the origin server for one client as the optimistic response to another. Unfortunately, since the cache does not know the semantic meaning of the page, this technique has the potential to introduce privacy concerns. Ensuring that no single client's personal information leaks into the response sent to another is a non-trivial task.
A second type of bandwidth waste occurs when two distinct URIs reference the same or similar data. This phenomenon is commonly termed aliasing; and can occur due to dynamic content, advertising, or web authoring tools. It was studied in 2002 by Kelly and Mogul [10], who studied the case in which one or more URIs represent exactly the same data. They found that 54% of all web transactions involved aliased payloads, and that aliased data accounted for 36% of all bytes transferred. The standard web caching model identifies cacheable units of data by the URIs that reference them; as such, it does not address the phenomenon of aliasing at all. Even if it is known in advance that two or more URIs share some data, there is no way to express that knowledge under the standard model.
In this paper, we present Value-Based Web Caching, a technique by which cached data is indexed by its value, rather than its name. Our algorithm has the following interesting properties.
In this section we present the Value-Based Web Caching algorithm; we begin with an overview before discussing the details.
Consider a web resource, such as the main page of a news web site. This page changes over time, and it contains references to other resources such as images and advertising content. In a traditional web cache, the data for each of these resources would be stored along with some freshness information and indexed under the URI by which it is named. The fundamental idea behind VBWC is to index cached data not only by its name, but by its value as well. To achieve this goal efficiently, we break the data for a resource into blocks of approximately 2 kB each, and name each block by its image under a secure hash function, such as MD5 [19]. This image is called the block's digest; by the properties of the hash, it is highly unlikely that two different blocks map to the same digest under the secure hash. A web cache using VBWC stores these blocks as its first-class objects. In order to also be able to find data by its name, a second table may be used to map resources to the blocks of which they are composed.
First request:
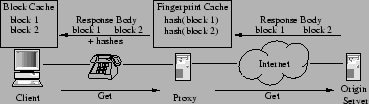
Subsequent request: 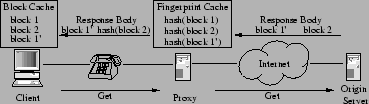
|
Indexing web resource data in this manner can result in better utilization of storage resources [1,12]. For example, when aliasing occurs, the aliased data is stored only once. However, the real benefit of value-based caching comes when resources are transferred between caches. Figure 2 shows the basic algorithm. The first time a resource is requested by the client, the proxy fetches its contents from an origin server. These contents are broken into blocks and hashed. The proxy stores each block's digest, then it transmits both the digests and the blocks to the client. The client caches the blocks indexed by their digests and associated URIs. Later, the proxy can detect that a subsequent request contains an already transmitted block by checking for that block's digest in its cache. In such cases, only the digest is retransmitted to the client, which reassembles the original response using the data in its block cache.
Before delving into the details of this algorithm, let us consider its benefits. First, as shown in Figure 2, it does not matter whether the second request is for the same URI as the first request; all that is important is that the two responses contain identical regions. By naming blocks by their value, rather than the resources they are part of, we recognize and eliminate redundant data transfers due to both resource modification and aliasing with the same technique.
A second benefit of VBWC is the way in which it distributes load among the parties involved. As mentioned above, while the proxy may store the contents of blocks (as it would if it were also acting as a web cache, for instance), it is only required to store their digests. As such, the proxy only stores a few bytes (16 for MD5) for each block of several kilobytes stored by the client. A proxy may possess considerable storage resources; however, assuming it has only as much storage as a single client, this storage ratio allows a single proxy to support hundreds of clients.
A third benefit of our algorithm is that the digests only need to be computed at the server; the client simply reads them from the data transmitted to it. In the case where the client is a low-power device such as a cellular phone or PDA, this computational savings could result in a significant reduction in latency. On the other hand, the Java implementation of our algorithm can process blocks at a rate of 7.25 MB/s on a 1 GHz Pentium III, a rate equivalent to the download bandwidth of over 1,000 modern modems; we thus expect the additional per-client computational load on the server to be small enough to allow it to scale to large numbers of clients.
A final benefit of Value-Based Web Caching is that it requires no understanding of the contents of a resource. For example, a delta-encoding proxy (such as that in used in the WebExpress project [8]) will generally make use of the responses that an origin server sends to many different clients in order to choose a base page for future use in delta compression. If this process is performed incorrectly, there is the possibility that one client's personal information may become part of the base page transmitted to other clients. Specifically, this information leakage is a result two interacting performance optimizations: using a single base page for multiple clients to save storage resources, and using delta-encoding on responses marked uncacheable by the origin server. In contrast, a client using VBWC only receives either the blocks sent to it by an origin server or the digests of those blocks.
| Before insert:
After insert: 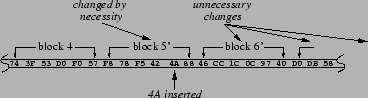 |
Above we mentioned that we break each response into blocks; in this section, we describe how we choose block boundaries. Naïvely, we could use a fixed block size, 2 kB for example. Figure 3 illustrates one problem with this approach: an insertion of a byte into a block early in the file (into block 5 in the figure) offsets the boundaries of every block that follows. As a consequence, our algorithm would only notice common segments in two resources up to their first difference; common segments that occurred later in the resources would not be identified.
One solution to this problem was discovered by Manber in an
earlier work [11]:
choose block boundaries based on the value of the blocks rather
than their position. Let ![]() be a function mapping
be a function mapping ![]() one-byte inputs uniformly and randomly to the set
one-byte inputs uniformly and randomly to the set
![]() . In other words,
. In other words,
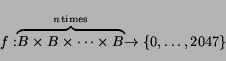
The benefit in picking block boundaries by the value of the
underlying data is illustrated in the lower half of Figure 4, where the byte 1A has been
inserted into the stream. In this example,
![]() , so this change
introduces a new boundary, splitting the original block in two.
However, since
, so this change
introduces a new boundary, splitting the original block in two.
However, since ![]() , the boundaries of all blocks
three or more positions after the change are unaffected; in
particular, the next block still starts with the byte value D0. In
general, the insertion, modification, or deletion of any byte
either changes only the block in which it occurs, splits that block
into two, or combines that block with one of its neighbors. All
other blocks in the stream are unaffected.
, the boundaries of all blocks
three or more positions after the change are unaffected; in
particular, the next block still starts with the byte value D0. In
general, the insertion, modification, or deletion of any byte
either changes only the block in which it occurs, splits that block
into two, or combines that block with one of its neighbors. All
other blocks in the stream are unaffected.
Before insert:
 After insert: 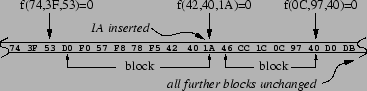 |
To implement ![]() , Manber used Rabin functions [18], a decision we follow. Let
, Manber used Rabin functions [18], a decision we follow. Let ![]() represent byte
represent byte ![]() in a stream and let
in a stream and let
![]() be a prime. A Rabin function
be a prime. A Rabin function ![]() is
a function
is
a function
Consider an HTTP client loading a web page through a proxy. The
main page is stored on a server ![]() , and it includes two
embedded images, one stored on server
, and it includes two
embedded images, one stored on server ![]() and the other
on server
and the other
on server ![]() . The client opens a connection to the
proxy and enqueues the request for the resource on
. The client opens a connection to the
proxy and enqueues the request for the resource on ![]() .
Once it receives the response body, it parses it and discovers it
must also retrieve the resources on
.
Once it receives the response body, it parses it and discovers it
must also retrieve the resources on ![]() and
and ![]() in order to display the page. To perform these retrievals,
the client could enqueue the request for the resource on
in order to display the page. To perform these retrievals,
the client could enqueue the request for the resource on ![]() followed by the request for the resource on
followed by the request for the resource on ![]() on the connection it already has open to the proxy, one
after the other. However, because of the request-response semantics
of the HTTP protocol, doing so would require the proxy to transmit
the response for
on the connection it already has open to the proxy, one
after the other. However, because of the request-response semantics
of the HTTP protocol, doing so would require the proxy to transmit
the response for ![]() before the response for
before the response for ![]() , regardless of which of them was available first. If server
, regardless of which of them was available first. If server
![]() was under heavy load or simply far away in
latency from the proxy, a significant delay could result in which
the data from
was under heavy load or simply far away in
latency from the proxy, a significant delay could result in which
the data from ![]() was available but could not be sent to
the client, resulting in idle time on the low bandwidth link. This
situation is commonly termed head-of-line blocking.
was available but could not be sent to
the client, resulting in idle time on the low bandwidth link. This
situation is commonly termed head-of-line blocking.
To reduce the occurrence of performance problems due to head-of-line blocking, most HTTP clients open several connections to a proxy at a given time. The Mozilla web browser, for instance, will open up to four connections to its parent proxy. For the same reason, we would like our child proxy running the VBWC algorithm to be able to open multiple connections to its parent. This decision introduces complications into the algorithm as follows. As discussed in the algorithm overview, the child proxy in our algorithm maintains a cache of previously transmitted blocks, and the parent proxy maintains a list of the digests of the blocks the child has already seen. Because the child only has finite storage resources available, it must eventually evict some blocks from its cache. Were the parent to later transmit a digest for a block the child had evicted, the child would have no way to reproduce the block's data. Thus there must be some way to keep the list of blocks on the parent consistent with the blocks actually cached by the child.
In the case where there is only one connection between the parent and the child, keeping the parent's list of blocks consistent with the child's block cache is simple. Both sides simply use some deterministic algorithm for choosing blocks to discard. For example, Spring and Wetherall [23] used a finite queue on either end. When the parent transmitted a block, it placed its digest on the head of the queue, and the child did the same on receiving a block. When the queue became full, the parent would remove a digest from its tail; the child would again do the same, but would also discard the block corresponding to the received digest. To decide whether to transmit a whole block or only its digest, the parent need only examine the queue; if the digest of the block in question is already there, the block is cached on the child and only the digest must be transmitted. Unfortunately, with multiple connections between the parent and child, the order in which blocks are sent is no longer necessarily the same as the order in which they are received, so a more sophisticated algorithm must be used.
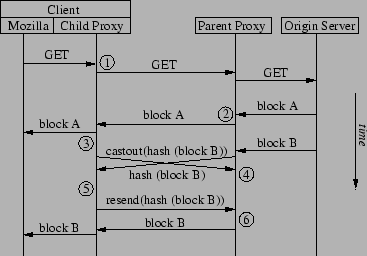 |
To allow for multiple connections between the child and parent proxies, we abandon the idea of using a deterministic function on either end of the link between them, and instead use the following optimistic algorithm. First, the server records the digests of the blocks that it has transmitted in the past, and assumes that unless it is told otherwise, the child still has the data for those blocks cached. The child, in turn, uses a clock algorithm to approximate LRU information about the blocks, discarding those least-recently used when storage becomes scarce. After discarding a block, the client includes its digest in the header of its next request to the parent, using a new ``X-VBWC-Castout'' header field. So long as the list of references to to the blocks contains some temporal locality, it is very unlikely that the parent will transmit the digest of a block that the child has just cast out--rather, the castout message will reach the server in time. If, however, this unfortunate case does occur, the child uses a request with a dummy URI to retrieve the data for the missing block. This entire process is illustrated in Figure 5.
A final modification is necessary to finish the optimistic
algorithm. Before, the server only cached the digests of blocks it
transmitted, not their values. If the child were to re-request a
block as described above, the server would not be able to reproduce
the data for it. To prevent this problem, we add to the server a
queue of the last few blocks transmitted, which we call the
transmit buffer. The size of this queue is determined by the
bandwidth-delay product of the link between the parent and its
child, plus some additional space to handle unexpected delays. For
example, if the parent is on a link with a one-way latency of ![]() seconds and a bandwidth
seconds and a bandwidth ![]() , a queue
size of
, a queue
size of ![]() will allow the child
will allow the child ![]() seconds from the time it receives a unrecognized digest to send a
retrieval request before that block is discarded from the transmit
buffer. If the parent proxy is also acting as a web cache with an
LRU eviction policy, the storage used for the transmit buffer can
be shared with that used for general web caching.
seconds from the time it receives a unrecognized digest to send a
retrieval request before that block is discarded from the transmit
buffer. If the parent proxy is also acting as a web cache with an
LRU eviction policy, the storage used for the transmit buffer can
be shared with that used for general web caching.
The transmit buffer in our algorithm might seem unnecessary; after all, the server can always retrieve a resource from the relevant origin server in order to re-acquire the data for a particular block. This is not the case, however, and the reasoning why it is not is somewhat non-obvious, so we present it here.
In building a web proxy, one possible source of lost performance
is called a store-and-forward delay. Such a delay occurs
when a web proxy must store an entire response from an origin
server (or another proxy) before forwarding that response on to its
own clients. Our algorithm does not suffer from such delays (except
as necessary to gather all of the data from a given block), and
this feature is an important one for its performance. Consider a
single HTML page with a reference to a single image early in the
page. If the page is transmitted without store-and-forward delays,
the requesting client sees the reference early in the page's
transmission and can begin fetching the corresponding image through
another connection.![]() Otherwise, it
must wait until the entire file is available before it has the
opportunity to see the reference, so the image retrieval begins
much later. Since the bandwidth of the modem is low and its latency
is long, it is crucial that the child proxy forward each block of a
response to the client as quickly as possible, in order to minimize
the time until the client sends subsequent requests for embedded
objects.
Otherwise, it
must wait until the entire file is available before it has the
opportunity to see the reference, so the image retrieval begins
much later. Since the bandwidth of the modem is low and its latency
is long, it is crucial that the child proxy forward each block of a
response to the client as quickly as possible, in order to minimize
the time until the client sends subsequent requests for embedded
objects.
Unfortunately, eliminating store-and-forward delays conflicts with the notion of an optimistic algorithm as follows. First, modern web sites are rich with dynamic content, both due to advertising and due to extensive per-user and time-dependent customization. Two requests for the same resource, even when issued at almost the same time, often return slightly different results. If the child proxy in our algorithm were to receive a digest for a block that it did not have cached, the parent proxy might not be able to retrieve the contents of that block via a subsequent request to the associated origin server. If the child proxy has already forwarded some of the response to the client program, it cannot begin transmitting a different response instead.
We would like our algorithm to provide semantic transparency; that is, any response a client receives through our pair of proxies should be identical to some response it could have received directly from an origin server. Under normal circumstances, this notion means that the response received is one that the server sent at a given point in time, not the mix of several different responses it has sent in the past. Of course, it is always possible for a server to fail during the transmission of a response, in which case a client must by necessity see a truncated response. By increasing the size of the transmit buffer in our algorithm, we can provide the same apparent consistency. Under almost all circumstances, the child proxy is able to re-request a missing block before it leaves the transmit buffer. In the extremely rare case that it does not, and the block cannot be recovered, the connection to the client may be purposefully severed. By always using either a ``Content-Length'' header or chunked transfer encoding (rather than indicating the end of a response through a ``Connection: close'' header), we can also ensure that in this rare case the client program is able to detect the error and display a message to the user. The user can then manually reload the page. In summary, connections may be dropped even without our pair of proxies, and by manipulating the size of the transmit buffer, we can drive the probability of additional drops due to unavailable blocks arbitrarily low.
An important difference between our algorithm and conventional web caching is that conventional web caches are stateless with respect to their clients. As pointed out by Sandberg et al. [21], stateless protocols greatly simplify crash recovery in network protocols; in stateless protocols, a server that has crashed and recovered appears identical to a slow server from a client's point of view. Furthermore, a stateless protocol prevents a server from keeping per-client state, eliminating a potential storage and consistency burden. For these reasons a stateless protocol is generally preferred over a stateful one. We justify our use of a stateful protocol as follows: it outperforms a stateless one, especially over high-latency links, and the state it stores is used only for performance, not correctness. We discuss these two points in detail below.
In a delta-encoding protocol such as RFC 3229 [13], a client submits information about earlier responses of which it is aware with each subsequent request for the same resource. If the proxy serving the client is also aware of one of those responses, it can compute a delta and send it to the client. However, this technique cannot eliminate redundant transfers due to aliasing; by definition, an aliased response contains redundant data from resources other than that requested. Unless a client were to transmit information about earlier responses for all resources to the proxy, some aliasing could be missed. Kelly and Mogul presented an algorithm that uses an extra round trip to catch aliasing [10], but over high-latency modem lines this additional round trip could introduce significant performance reductions. By storing a small amount of state per client on the proxy, our algorithm avoids extra round trips in the common case.
Moreover, while our protocol is not stateless, it utilizes only soft state to achieve its performance gains. A protocol is termed soft-state if the state stored is used only for performance, not correctness. If the proxy in our algorithm loses information about which blocks the child has cached, it will result only in the redundant transfer of data. If the parent thinks the child is caching data that it is not (either due to corruption on the parent or data loss on the child), the child will request the data be resent as described in Section 2.3.1. If a sufficient number of such resends occur, the child proxy could proactively instruct its parent to throw out all information about the contents of the child's cache through a simple extension to our protocol. Such an extension would be particularly valuable if a child were periodically to switch proxies. In conclusion, we believe the use of per-client state in our protocol is justified by the combination of its performance benefits and its absence of an effect on correctness.
|
 |
In this section we describe a detailed evaluation of the ability of VBWC to reduce bandwidth consumed and--more crucially--reduce user-perceived time-to-display (TTD). In this evaluation we concentrate on the domain in which the elimination of redundant transfers is likely to be fruitful. An evaluation based on full traces of user activity is left for future work. We start by describing our methodology and experimental setup, then present our results.
In order to test the ability of our algorithm to reduced the
user-perceived TTD of common web pages, we built the following test
suite. First, we instrumented Mozilla version 1.0.1 to read URIs
from a local TCP port. After reading each URI, our instrumented
browser loads the resource and sends the total load time back over
the socket. This time corresponds to the time from when a user of
an uninstrumented version of the program types a URI into the URI
field on the toolbar until the Mozilla icon stops spinning and the
status bar displays the message, ``Done. (![]() seconds)''.
seconds)''.
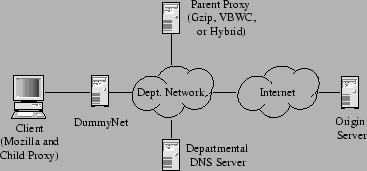
To this web browser we added a Perl script that takes as input a list of URIs, then loads each one through an instrumented browser running without a proxy and a second one running through a proxy using the VBWC algorithm. We simulate a modem using a FreeBSD machine running DummyNet [20], which adds latency and bandwidth delays to all traffic passing through it. In our experiments, we configured DummyNet to provide 56 kb/s downstream and 33 kb/s upstream bandwidth, with a 75 ms delay in either direction. These parameters mimic the observed behavior of modern modems. The use of DummyNet also allows us to monitor the total number of bytes transferred across the simulated modem in each direction, and the Perl script records this number after each load. After each iteration through the list, the script sleeps for twenty minutes before repeating the test, resulting in each URI being loaded through the algorithm and control approximately every thirty minutes. This experimental configuration is illustrated in Figure 6.
In our experiments, Mozilla and the child proxy run on a 750 MHz Pentium III with 1 GB of RAM, while the parent proxy runs on a 1 GHz Pentium III with 1.5 GB of RAM (as noted below, however, we limit our caches to a small fraction of the total available memory). The machine running DummyNet is an 866 MHz Pentium III with 1 GB of RAM. Both the child and parent machines were otherwise unloaded during our tests; the DummyNet machine was not completely isolated, but saw only light loads.
Mozilla consists of over 1.8 million lines of C++ source code. Rather than familiarize ourselves with the full extent of this code base necessary to add the VBWC algorithm to it, we implemented our algorithm in Java atop the Staged Event-Driven Architecture (SEDA) [26]. Implementing the algorithm in a separate proxy has the advantage of making it browser neutral (we have also run it with Internet Explorer), but adds some latency to local interactions. Worse, it forces us to utilize two separate web caches; one internal to Mozilla and one in the proxy itself. As such, in the control experiments Mozilla runs with a 10 MB memory cache, while in the VBWC experiments Mozilla and the proxy each have a 5 MB cache. We leave quantifying the advantages of integrating these two caches as future work, but it is clear that the caches will have some overlapping data, putting our algorithm at some disadvantage. Our results are somewhat pessimistic in this sense. The parent proxy in our tests is also implemented in Java atop SEDA. Altogether, the parent and child proxy are made up of about 6,000 lines of Java code, including an HTTP parser and a specialized string-processing library.
To compare VBWC against something other than just Mozilla itself, we implemented a second parent-child proxy pair that simply compressed each response from any web server using gzip before sending it over the modem. We do not compress any response that contains a ``Content-Type'' header starting with ``image'', since in our workload these are all GIF and JPEG files that are already compressed. Also, Mozilla includes an ``Accept-Encoding: gzip'' header in all its requests, and some origin servers take advantage of this, responding with ``Content-Encoding: gzip'' in their response headers. We do not try to further compress such responses.
Finally, we implemented a hybrid algorithm that uses VBWC but compresses each new block before sending it to the client. Non-image responses that are compressed by the origin server are uncompressed by the hybrid algorithm before they are broken into blocks; the resulting blocks are recompressed before being transmitted to the client.
Many previous studies in this field have measured bandwidth saved as a performance metric for algorithms similar to our own. Instead, we chose to instrument a full web browser. As we will show below, simple bandwidth savings do not necessarily guarantee an equivalent improvement in TTD, the main component of the quality of a user's experience.
 |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
In this section we examine the results of our experiments, which ran from approximately 7 PM on November 12, 2002 until approximately 5:30 PM on November 14, 2002.
For our first result, we analyze the costs of the parent proxy's digest cache being only loosely synchronized with the child proxy's block cache. In all of our experiments, the transmit buffer on the parent was limited to 100 kB of block data. During our experiments, the parent in our algorithm transmitted a total of 17,768 digests without their corresponding data to the client; for 42 of these, the child had already cast out the blocks' data from its cache, a 0.24% miss rate. Since the cost of a miss is only an additional round-trip time over the modem, we feel that this low miss rate clearly justifies our use of an optimistic algorithm.
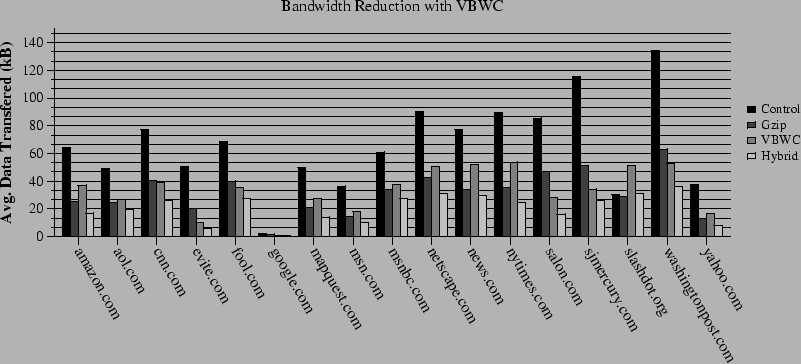
Next, we examine the bandwidth savings provided by our algorithm. Figure 7 shows the average kilobytes transferred per web page as a function of the algorithm used. In most cases, the combination of VBWC and gzip (called the Hybrid algorithm in our figures) outperforms all three other algorithms. However, the simple Gzip algorithm performs quite well. The HTTP 1.1 standard allows for such compression to start at the origin server when requested by a client (using the ``Accept-Encoding'' header field), but in our experience, very few servers take advantage of this portion of the standard. In the cases where they do (such as slashdot.org), the control case is much closer in bandwidth usage to the Gzip case.
In cases where the Hybrid algorithm underperforms Gzip, it is often due to the granularity of resource modification on those sites. For example, the spacing between differences on successive versions of slashdot.org is under 2 kB, and there are many small differences. Because of this, over the course of our experiments, only 24% of the main slashdot.org page sent from the parent to the child was sent as the digests of previously transmitted blocks. In contrast, 64% of the main nytimes.com page was sent as the digests of previously transmitted blocks. Using a smaller average block size would presumably mitigate the effects of small changes, at the cost of more overhead. In theory, one could also choose the average block size dynamically in response to past performance, but we have not yet investigated this technique.
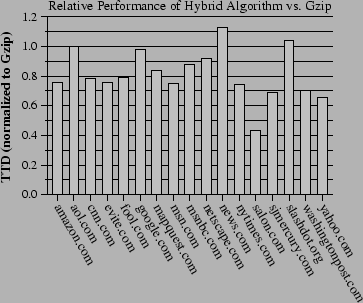
Figure 8 shows the median TTD of the Hybrid algorithm for various web sites, normalized against the TTD of the Gzip algorithm. We use medians instead of means when reporting TTD numbers because web server response time distributions show very long tails, especially on loaded web servers like those used in our experiments. In contrast, server load does not affect the sizes of responses. The relative performance of the control case and VBWC without gzip are less interesting--they roughly follow the bandwidth differences shown in Figure 7. Table 1 shows the actual times for each point in Figure 8, as well as the percent improvement the Hybrid algorithm achieves over Gzip for each web site. The benefits of VBWC are clear from the table and graph. For one web site, the Hybrid algorithm achieves a 56.8% improvement in TTD; for three others, it achieves at least a 30% improvement; and for another six it achieves at least a 20% improvement. It performs worse that compression alone in only two cases. We are quite satisfied with the performance of the algorithm in general.
As a final result, we characterized our workload so as to compare it to previous traces. To do so, we instrumented our VBWC code to print the name of each block it receives, the block's size, and the URI with which that block is associated. For every occurrence of a particular block, we noted whether the block had been seen earlier in the workload in the payload for the same or another URI. The transfer of blocks seen in the payloads of earlier transactions on the same URI could be eliminated through sophisticated name-based techniques such as delta encoding. The transfer of blocks seen only in the payloads of earlier transactions on different URIs, however, can only be eliminated through value-based caching. In this analysis, we found that a total of 34.0 MB of the 61.6 MB transferred could be eliminated by name-based caching. (Note that choosing blocks differently could improve this number; our blocking algorithm is sub-optimal for small deltas.) In contrast, 35.3 MB of the transferred data could be saved by value-based caching, leaving 1.3 MB that could be saved only by value-based caching. This potential 57% savings is over the transactions performed by Mozilla, which is already maintaining a 5 MB conventional cache of its own.
Overall, the above numbers indicate that there is a good deal of
bandwidth to be saved using named-based caching, while there is
less clear benefit to value-based caching if named-based caching
with delta encoding is already being performed. To qualify the
potential benefits of our algorithm on a more general trace, we
analyzed our workload in the style of Kelly and Mogul [10]. They call a transaction
a pair ![]() where
where ![]() is a request URI and
is a request URI and
![]() is a reply data payload. They say that a
reply payload is aliased if there exist two or more
transactions
is a reply data payload. They say that a
reply payload is aliased if there exist two or more
transactions
![]() where
where
![]() . They say that a URI is
modified if there exist two or more transactions
. They say that a URI is
modified if there exist two or more transactions
![]() where
where
![]() . We extend their nomenclature
as follows. We say that a payload
. We extend their nomenclature
as follows. We say that a payload ![]() is a sequence
of blocks
is a sequence
of blocks
![]() . We say that a block
. We say that a block
![]() is aliased if there exist two or more
transactions
is aliased if there exist two or more
transactions
![]() with
with
![]() .
.
Table 2 shows that 12% of transactions in our workload have aliased payloads, as compared to the 54% that Kelly and Mogul observed in their WebTV trace. Furthermore, we found that aliased payloads account for only 3% of the bytes transferred, as opposed to 36% in the WebTV trace. These results indicate that our chosen workload demonstrates a comparatively small opportunity for value-based caching to reduce redundant transfers due to aliasing. As such, a clear avenue for future research is to test our algorithm on the WebTV trace. Finally, we note that Table 2 shows 18% of transactions contain aliased blocks, an additional 6% over the number that contain completely aliased payloads, indicating the importance of looking for aliasing at the block level.
We believe there are a number of unique features to our algorithm and our experimental approach, but there are also a number of prior studies that have touched upon many of the same ideas. We review them here.
The first work on delta encoding in the web that we know of was in the context of the WebExpress project [8], which aimed to improve the end-user experience for wireless use of the web. They noted that the responses to POST transactions often shared similar responses, and utilized delta encoding to speed up transaction processing applications with web interfaces. Deltas were computed with standard differencing algorithms. Mogul et al. performed a trace-driven study to determine the potential benefits of both delta encoding and data compression for HTTP transactions [14].
An innovative technique for delta encoding, called optimistic deltas, was introduced by Banga, Douglis, and Rabinovich [2]. In their scheme, a web cache sends an old version of a given resource to a client over a low bandwidth link immediately after receiving a request for it. It then requests the current version of the resource from the origin server, and sends a delta to the client if necessary. This approach assumes there exists enough idle time during which the origin server is being contacted to send the original response over the low bandwidth link, and the authors perform some analysis to show that such time exists. In any case, their algorithm is capable of aborting an optimistic transfer early as soon as the cache receives a more up-to-date response and decides the transfer is no longer profitable. We believe that optimistic deltas are effectively orthogonal to our technique, although we have yet to try to combine the two. Ionescu's thesis [9] describes a less aggressive approach to delta encoding.
Several studies of the nature of dynamic content on the web were performed by Wills and Mikhailov, who demonstrated that much of the response data in dynamic content is actually quite static. For example, they found that two requests with different cookies in their headers often resulted in the exact same response, or possibly responses that differed only in their included advertising content [27]. Later, they found a 75% reuse rate for the bytes of response bodies from popular e-commerce sites [28].
Several studies of which we are aware looked at the rate of change of individual web sites. Brewington and Cybenko studied the rate of change of web pages in order to predict how often search engines must re-index the web [3]; Padmanabhan and Qiu studied the rates and nature of change on the msnbc.com web site [17]. The latter study found a median inter-modification time of files on the server of around three hours. Looking back at our Figure 7 this result is intriguing, as we found a much higher rate of change in the actual server response bodies (recall that we sampled the site approximately every 30 minutes).
Studies of aliasing came later to the web research community. The earliest of these that we are aware of was by Douglis et al. [5], who studied a number of aspects of web use, including resource modification. They noted that 18% of full body responses were aliased in one trace (although the term ``aliasing'' was not yet used). Interestingly, they did not consider this aliasing to be a useful target of caching algorithms since most of these responses were for ``uncacheable'' responses. We note that caching data by its value as we have done in this study does not suffer from such a limitation.
Alias detection through content digests has been used in the past to prevent storing redundant copies of data. The Inktomi Traffic Server [12] and work by Bahn et al. [1] both used this approach. The main advantage of this technique is that it allows a server to scale well in the number of clients; as opposed to simply compressing cache entries, the use of digests allows common elements in the responses to distinct clients to be stored only once.
The HTTP Distribution and Replication Protocol [25] was designed to efficiently mirror content on the web and is similar to the Unix rsync utility [24]. It uses digests, called content identifiers, to detect aliasing and avoid transferring redundant data. The protocol also supports delta encoding in what they call differential transfers.
Santos and Wetherall presented the earliest work of which we are aware that used digests to directly suppress redundant transfers in networks by using a child and parent proxy on either end of a low bandwidth connection [22]. Spring and Wetherall added the idea of using Rabin functions to choose block boundaries [23]. We have used both of these ideas in our work. In contrast to ours, both these algorithms are targeted at the network packet layer. Spring and Wetherall note that their caching technique introduces the problem that the caches can become unsynchronized due to packet loss, and they note that more sophisticated algorithms for caching might be used. In our optimistic algorithm we address both of these problems: we allow castout decisions to be driven completely by the client, where the most information about the actual usage patterns of data is available, and we provide recovery mechanisms to deal with inconsistencies. Like the Santos and Wetherall algorithm, we use MD5 hashes rather than chains of fingerprints to name blocks. This technique removes from the server the burden of storing all of the response bodies that the client stores; for a large client population this can be a significant savings. Finally, Spring and Wetherall found only a 15% improvement in bandwidth usage using gzip; we find this result curious and believe it might have occurred because they were compressing packets individually, whereas the gzip algorithm is more efficient with larger block sizes.
Rabin fingerprinting was used earlier by Manber [11] to find similar files within a file system. Muthitacharoen, Chen, and Mazières combined his techniques with those of Spring and Wetherall to build a network file system for use over low bandwidth links [15]. In their system, before writing new data to the server, a client first sends only the digest of each new block; the server then asks for the data corresponding to any digests it does not recognize. In web parlance, their technique is successful because a great deal of file system writes are due to both resource modification and aliasing. For example, they note that a file and the backup generated for it by many popular text editors share much of the same data, but have different names. Their application is not suited to the optimistic techniques we present here, and thus their protocol requires an extra round trip. The addition of this extra round trip over a high-latency link is acceptable if the potential savings is large; we believe the small size of the average web resource precludes the use of such round trips, however.
Kelly and Mogul performed a detailed study of aliasing on the web using traces from the WebTV network and the Compaq corporate network [10]. We recommend their related work section as an excellent introduction to the space. In that work, they found a very high percentage of transactions included aliased responses (54%) versus the percentage whose responses contained redundant data due to resource modification (10%). Our workload is more limited; this limitation may explain the disparity in our observed results. Nevertheless, since aliased payloads are often incompressible, such a distribution would probably improve our relative performance versus gzip. Kelly and Mogul also proposed the basics of a scheme to take advantage of aliasing over low bandwidth links. They index caches by both URI and digest. In a response, the parent proxy in their scheme first sends the digests for every block to the child proxy. Then, the server may optimistically start sending the resource's data and accept cancel requests from the child, or the child may send explicit requests for the data corresponding to unrecognized digests. We are not aware of an implementation or performance results thereof for this algorithm.
Finally, another body of work addresses the aliasing problem in a different way. Chan and Woo [4] use similarity in URIs to find cached resources from the same origin server related to a given request, then use a delta encoding algorithm to compute a response based on one or more cached items. Like our algorithm, theirs uses specialized child and parent proxies, but they do not specify a mechanism for keeping these in sync. In a similar approach, Douglis, Iyengar, and Vo [7] use a fingerprinting algorithm in the style of Manber as well as URI similarity to identify related documents. In contrast to our algorithm, they use an extra round trip to coordinate the client and server. Because they use delta encoding algorithms rather than a block-based algorithm such as ours, these algorithms have the potential to save more bandwidth, as their deltas can be at a finer granularity. The addition of an extra round trip in the latter protocol eliminates the need to maintain per-client state on the server, but it may prevent the algorithm from providing an overall reduction in TTD over high-latency links. Douglis and Iyengar [6] performed a study of several bodies of data, including web resources, to quantify the ability of algorithms to recognize similarities in resources between which no relationship is known a priori.
We have presented Value-Based Web Caching, a new technique for eliminating redundant transfers of data over HTTP links. Our algorithm detects and eliminates redundant transfers due to both resource modification and aliasing. In the common case, our algorithm adds no extra round trips to a normal HTTP transaction, and it does not require any understanding of the response bodies transferred to achieve performance improvements.
We have used a detailed performance study to compare our algorithm against simple gzip compression, and found that it improves user-perceived time-to-display (TTD) up to 56.8%. On 58% of the web sites we studied, our algorithm achieved at least a 20% TTD improvement. Ours is the first study of which we are aware to present performance numbers for this class of algorithm using a full featured web browser and to report TTD improvements.
There are three areas in which we would like to continue this work. First, an important step in quantifying the performance of our algorithm is the use of trace-driven simulations. Our current workload was designed to test our algorithm in the areas where we felt it would be most useful. As such, our results do not guarantee that users will see a net improvement in TTD by using our algorithm. Furthermore, comparing our workload with the WebTV trace used by Kelly and Mogul seems to indicate that there are other opportunities to take advantage of aliasing that are not captured by in our work to date. As such, a trace-driven simulation of our algorithm would likely provide valuable additional insight into its behavior.
Second, our current implementation uses a child proxy that is separate from the Mozilla web browser. This architecture made the implementation of our algorithm easy, but limits its performance. It hides some of the reference stream from the child proxy, degrading the quality of the information fed to the LRU algorithm with which castout decisions are made. Moreover, by having two separate caches, our effective cache size is smaller. Often, Mozilla's internal cache and the cache in the child proxy contain the same data; for fairness of evaluation, we have limited their combined size to the size of Mozilla's cache in the control case. An integrated cache should produce strictly better performance results than we have presented here.
Finally, we would like quantify the scalability of the parent proxy. As we argued in Section 2, there are good reasons to believe that the parent proxy should be able to support many simultaneous clients. It needs several orders of magnitude less storage resources than any one client, and the throughput of our block recognition and digesting algorithm is sufficient to support over 1,000 clients on a modest processor. Nonetheless, the scalability of the server plays an important role in the economic feasibility of deploying our algorithm within ISPs, so we feel it is important to quantify.
This document was generated using the LaTeX2 HTML translator Version 2K.1beta (1.48)
Copyright © 1993, 1994, 1995, 1996, Nikos Drakos,
Computer Based Learning Unit, University of Leeds.
Copyright © 1997, 1998, 1999, Ross Moore, Mathematics
Department, Macquarie University, Sydney.
The command line arguments were:
latex2html -split 0 -no_navigation
p657-rhea.tex
The translation was initiated by Sean C. Rhea on 2003-02-28