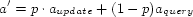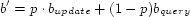
Figure 1: Architecture of LOCUS Spatial Indexing Testbed.
First-generation Location-Based Services (LBS) performed relatively trivial spatial lookups to determine the location of restaurants or other businesses nearest a user. An important observation, and one that is particularly relevant for this paper, is that while the reference point was moving, the data being queried was highly static. The yellow-pages applications were later complemented by more innovative ones, for example sending electronic discount coupons to users near or at a shopping mall. However, in many cases these applications operated with very coarse-grained location information, the reason being that user locations could only be determined at the cell level of the underlying wireless network. The employment of a comprehensive LBS infrastructure in the presence of limited location accuracy seemed like an overkill. Indeed, an entirely feasible and potentially preferable solution would have been to simply equip wireless cells with beacons that transmit any information that needs to be broadcast in the local area (yellow pages, electronic coupons, etc.) which wireless devices within range would then pick up by virtue of their physical proximity.
Second-generation LBS applications work on moving queries and highly dynamic data. Consider queries such as ``where are my friends?'' (buddy tracking [2]) and ``is someone following me?'' These queries relate the position of the user asking the question to the position of other users. Effective evaluation of these types of queries requires a dynamic spatial index, an index that is continuously kept up-to-date with the current (potentially also past and future) position of all users. The maintenance of the index induces a very high update and query load, an issue that is receiving increasing interest in literature [12,13].
Proposals have been made to reduce the number of required updates by filtering the location updates of the objects being tracked, thereby trading off some amount of accuracy for higher performance, or storing in the index trajectories of the objects and updating the information only when those trajectories change [8]. For instance, if a user is traveling on a relatively straight road, there is no reason to constantly update the index. Instead, it is sufficient to mark the position and velocity vector of the user at the start of a linear segment of the road and update the index only when the road or the user makes a turn.
Regardless of whether one stores simple geographic coordinates or trajectories in an index, the issue remains that the index needs to be updated and queried as quickly as possible. A trade-off that LBS middleware should be ready to make is not to try to store all location data persistently - current external storage technologies simply cannot sustain the update rates required. If a future storage technology provides the speed of main-memory chips and happens to be persistent, that's all the better, but for now transient data structures should be accepted for high-performance location tracking. We note that, in the event of main-memory loss, the index can be recreated within a short period of time with the continuously arriving location data from the objects being tracked. We also note that persistent storage should be used for accumulating historical location data, making it amenable to non-realtime analysis e.g. pattern discovery [5].
Our research on dynamic spatial indexing has focused on building the necessary tools and analysis methods for performance experimentation on proposed dynamic spatial indexing methods. In [7], we defined the DynaMark benchmark with associated metrics for measuring the cost (elapsed time) of inserting a user's location, the cost of updating a user's location, the size of a spatial index, and the cost of executing various classes of spatial queries. The performance experiments are carried out in the LOCUS Dynamic Spatial Indexing Testbed [6], an extensible system for conducting performance experiments on dynamic spatial indexing methods. The testbed is easily extended to include new spatial indexing methods, new location data sources (both simulated and real), new spatial query types, and new data visualization or analysis methods.
In this paper, we use the LOCUS testbed to analyze the performance and scalability of three spatial indexing methods: an R-tree, a ZB-tree, and a custom array/hashtable method. An R-tree is a widely used multi-dimensional indexing method intended for large volumes of static data. Our investigation measures its performance under dynamic data and query loads. A ZB-tree maps multi-dimensional geographical coordinates to one dimension using the Z-order space-filling curve method [10]. The resulting Z-values are then indexed by a regular balanced tree. The array/hashtable method provides a baseline and sanity check for the experiments. Coordinate data is stored in a hashtable, providing extremely fast updates but slower queries. Any real index should perform better than this baseline method.
The paper is organized as follows. In Section 2, we review existing literature on wireless communication, location tracking, and spatial indexing. In Section 3, we briefly describe the DynaMark benchmark and LOCUS testbed. Section 4 introduces the setup for our performance experiments, and in Section 5 we review and analyze the performance results obtained. Conclusions and directions for future work are presented in Section 6.
Location-based services build upon two well-established areas of information technology: wireless communication and spatial data management. While the primary role of wireless communication is to provide a connection between a mobile subscriber and others, its proper function - routing of data packets and voice calls - requires knowledge about the position of each mobile subscriber to some degree of accuracy [14].
New applications for real-time location information are emerging. These applications are largely driven by the expanding use of mobile phones, but also the United States Federal Communications Commission's (FCC) mandate that the originating location of all emergency 911 calls from mobile phones in the United States be determined with some minimum accuracy. Today, mobile phone operators have a choice of half a dozen technologies for location determination, each with distinct power consumption, handset compatibility, time-to-first-fix, and in-building coverage characteristics.
The focus in spatial data management has traditionally been on Geographic Information Systems (GIS), VLSI design, and mechanical CAD applications [3]. Dozens of multidimensional access methods have been proposed for managing spatial data, including grid indices, quadtrees, R-trees, k-d-trees, and space-filling curves such as Z-order [10]. Most of this research has been done in the context of static data (e.g. cartographic data) and few albeit relatively expensive queries (e.g. spatial joins). Moreover, the data usually consists of complex spatial objects, e.g. polylines and polygons with hundreds of vertices or more [11].
In contrast, a spatial index for location-based services contains a very large number of simple spatial objects (e.g. points) that are frequently updated. These ``moving object databases'' pose new challenges to spatial data management [13]. The workload is characterized by high index update loads and relatively simple but frequent queries (e.g. range queries). A location update may merely contain the position of a user or include a user's trajectory (direction and speed over time) [12,8]. Supporting trajectories adds additional requirements to the index and query scheme [1]. A location update may also expire at a certain point in time [9]. Finally, location data is inherently imprecise because location determination yields only an estimate of a user's location.
In this paper we analyze the performance and scalability of three main-memory spatial indexing methods: an R-tree, a ZB-tree, and an array/hashtable method. The performance experiments are carried out in our LOCUS Dynamic Spatial Indexing Testbed [6] and are driven by data from the City Simulator dynamic spatial data generator [4]. Our analysis focuses on range queries, the most common query type in LBS applications. The experiments store in an index every single location update received (i.e. generated by the generator), but the performance difference would be very small even if the data contained trajectory information instead of simple geographical coordinates because few additional attributes (velocity vector) need to be stored. Hence, we argue that the maximum update and query rates shown in this paper would apply to trajectory-based schemes reasonably well.
The DynaMark benchmark measures the performance and scalability of a spatial data management system [7]. The benchmark executes a set of standard, dynamic spatial queries against a set of location trace files produced with City Simulator [4]. Performance metrics consist of the cost of updating a user's location in the spatial index and the cost of spatial queries against the index.
The size of an individual benchmark run is determined by the number of mobile users contained in the location trace file and ranges from 10,000 to one million or above. Each record in the location trace file represents a location update that contains the following information: object ID (identifies mobile user), timestamp (indicates the time when the location was determined or reported by the user), and X, Y, and Z coordinates of the location. The X and Y coordinates represent the longitude and latitude values of the location, and Z indicates elevation in meters.
The benchmark defines three types of queries: proximity queries,
k-nearest neighbor (kNN) queries, and sorted-distance queries. The
queries are typically centered around the location of a user
issuing the request. A proximity query finds all objects
(mobile or stationary) that are within a certain range, while a
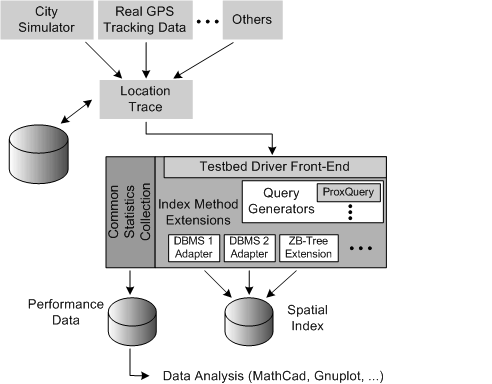
kNN query finds the 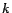 nearest objects. A sorted-distance query lists
objects in increasing distance order relative to some reference
point.
nearest objects. A sorted-distance query lists
objects in increasing distance order relative to some reference
point.
Figure 3: Raw query cost for ZB-tree.
The LOCUS testbed provides a convenient way to run performance experiments on spatial data management systems and produce performance data that conform to the DynaMark benchmark specification. The testbed is written in portable C and has been tested on several platforms, including Windows, AIX, and Solaris. We are currently making the testbed code available on the IBM alphaWorks developer Web site at http://alphaworks.ibm.com.
The testbed is extensible with new spatial indexing methods, query generators, and index visualization methods (Figure 1). The testbed defines a C API for each of the extension types, using function pointer arrays to achieve something analogous to the Java ``interface'' concept. An indexing method extension provides a spatial indexing capability and supports API calls for creating, managing, and searcing an index. A query generator creates one or more spatial queries, typically using the location of an existing user as a reference. For example, a proximity query is a range query around a user's location. An index visualization method provides a simple way for the testbed to plot an index, e.g. minimum bounding rectangles in an R-tree index.
Location trace files for the testbed are produced with City Simulator [4], a scalable, three-dimensional model city that simulates an arbitrary number of mobile users moving about in a city, driving on streets or walking on sidewalks and entering and moving inside buildings. We typically simulate population sizes ranging up to 1 million users.
The testbed has been adapted to use most commercial database systems and their spatial extensions, as well as several main memory indexing methods. The public version of the testbed comes with two main memory extensions: a naive array extension and a ZB-tree extension. The array extension implements a combination of a simple array and hashtable which work together to record the position of moving objects. Updates into this data structure are extremely fast but queries obviously perform poorly. The array method is intended to be used as a baseline and sanity check for the experiments. Any real index should perform better than this baseline method.
The ZB-tree method calculates a Z-order value for a moving object in the extension code and stores it in a binary tree. We used a readily available implementation of binary trees, namely the libavl library that implements several varieties of them. Z-order values are stored in a right-threaded AVL-tree which performs very well for proximity queries, requiring only a left-to-right traversal of the leaf nodes of the tree. Sentinel entries representing the lower-left and upper-right corners of the proximity query window are first inserted into the ZB-tree. Leaf nodes between the sentinel entries are traversed and returned, followed by removal of the sentinel entries from the tree.
The testbed has also been adapted to use a custom implementation of a memory-resident R-tree and its variants. Updates to the tree are done in two steps. Realizing that objects make only slight movements between location updates, the update first checks to see if the current leaf node that contains the object can continue to hold it, albeit with new coordinates. Failing that, a delete followed by a normal top-down insertion is done. This scheme dramatically improves the update performance of the tree index. Lookups are currently performed top-down, however an improved scheme would be to search bottom-up until the desired window for a range query, or the number of items found for a kNN query, has been satisfied.
A location tracking system that scales up to a hundred million moving objects and beyond is achievable by partitioning the problem and data space into smaller, local problems that each can be solved using a single machine. Our task therefore was to measure the scalability of the three main-memory spatial indexing methods on one standalone machine. We ran the experiments on an IBM xSeries 330 server, a commodity machine equipped with one 1 GHz Pentium III processor and 1 GB RAM, half of which was reserved for the spatial index (however none of the methods required more than 50 megabytes to index even the largest population size). We varied the size of the mobile user population in the experiments from 10,000 users to 1,000,000 users. The server was dedicated to the performance tests and there were no other processes on it during the tests.
The City Simulator toolkit was used to produce location trace files for each of the population sizes tested (10K, 50K, 100K, 200K, 500K, and 1M users). The trace files were stored on a 7200 RPM SCSI disk whose data transfer rate far exceeded the update performance of the indexing methods, guaranteeing that the testbed was never waiting for a disk read.
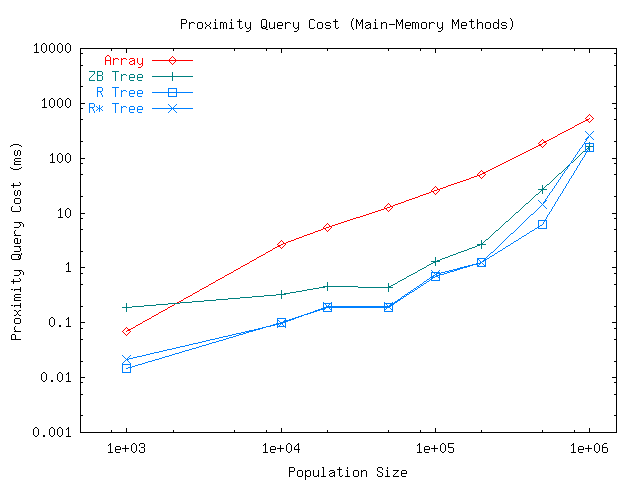
Figure 5: Steady-state query cost.
We ran the UPDATE test and query type Q1 of the QUERY tests defined in the DynaMark benchmark. The UPDATE test updates the position of each mobile object once in each 30-second period (in simulated time) and was executed until either the trace file was completely processed or an upper time limit of 6 hours had elapsed. Update cost, index size, and other metrics measured by the LOCUS testbed were collected at an interval of 2500 updates.
Query type Q1 of the QUERY test represents a sequence of random proximity queries (details below). The total execution time of the test was limited to 12 hours, which allowed the slowest indexing method to process several iterations of even the largest population size, that is, even for the one million population size the position of every object was updated and queried numerous times. Query cost and other statistics were measured after every 2500 location trace records.
Proximity (range) queries were created by picking an object from the index at random (uniform distribution) and then constructing a fixed-size window around that object. The size of the window was approximately 1% of the total area of the coordinate space in these experiments. Consequently, the number of results returned by these queries was, on average, 1% of the corresponding population size. Only after the objects in the result set had been extracted from the index and stored in a vector (ready to be returned to a potential application program) was the execution of the query considered complete.
The correct coding of the R-tree index, the most complicated of the three methods investigated, was validated by running several scaled-down experiments where the tree was visualized and inspected. We experimented with two variations of R-trees: the basic R-tree, which splits nodes by minimizing the total area of the split nodes but permits an overlap between nodes, and the R*-tree, which eliminates overlap but leads to potential deadlocks where non-overlapping splits do not exist. In our experiments deadlocks were not possible, however, since we indexed point objects only and a clean split was always found.
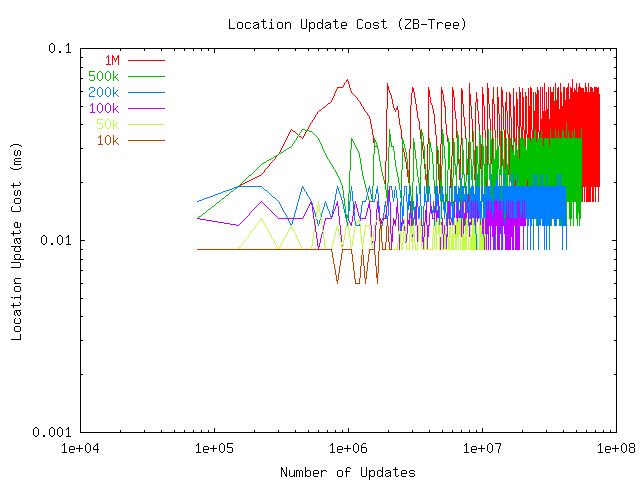
Figures 2 and 3 show the location update and proximity (range) query cost of the ZB-tree method as a function of population size and number of updates performed. The X axis corresponds to the time dimension during the experiments, with the left edge of each curve corresponding to the start of the experiment and the right edge corresponding to the conclusion. We see that the update and query cost experience initial randomness but eventually stabilize after the position of each object has been updated several times and the index has grown to its full size.
We have plotted the graphs with the number of updates performed (number of trace file records processed) on the X axis to make it easier to compare the population size with the corresponding record numbers. For instance, with the 1M population size the first 1 million records merely populate (insert) the index, with subsequent records causing actual updates to the index. In Figure 2, we can clearly see a change in the behavior of the update cost from the initial steady increase to the eventual settling and minor oscillation (most of which is due to operating system and clock measurement artifacts, given that the measurements are on microsecond scale). Similarly, Figure 3 shows that the query cost plateaus at the insert/update knee point.
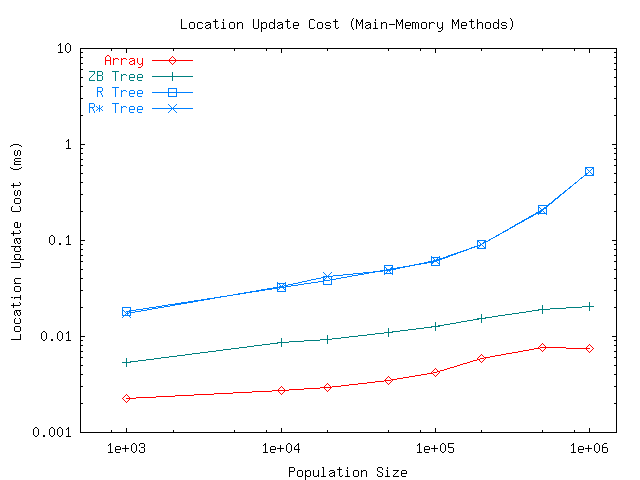
The values of the curves shown in Figures 2 and 3 at the end of the experiments correspond to the final, steady-state performance of the ZB-tree. We also extracted the corresponding steady-state update and query cost values for the R-tree and array/hashtable methods. In Figure 4 we show the steady-state update cost of each method as a function of population size. We observe that the array/hashtable method dominates the tree methods, as is expected, given its simple processing requirements. The average update cost of the array method increases from 2 to 8 microseconds as the population size increases to one million. In other words, with an index of one million moving objects, the array method can process 125,000 updates per second.
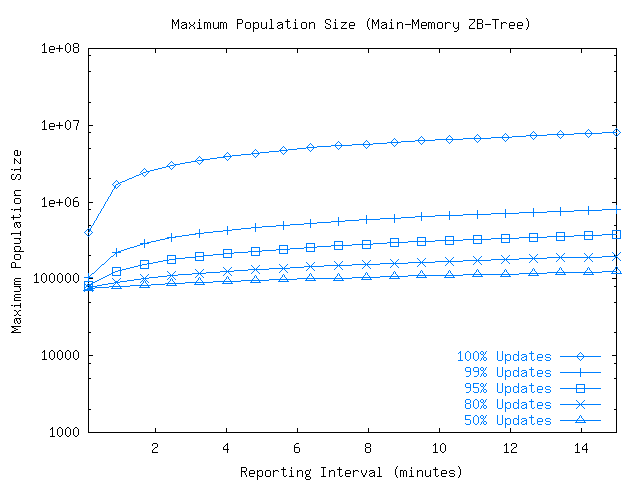
Figure 7: Maximum population size at different update/query workloads.
The update cost of the ZB-tree method trails that of the array method roughly by a constant factor of 3. With one million moving objects, the ZB-tree can process just over 40,000 updates per second. The R-tree and R*-tree methods are almost identical in their performance. With small population sizes, up to 200K, their performance has roughly a factor of 5 disadvantage compared to the ZB-tree. The disadvantage increases with larger population sizes, however. With one million moving objects, the R-tree and R+-tree methods can process only 2,000 updates per second.
The steady-state query cost of the methods is shown in Figure 5. What was a performance disadvantage for the R-tree and R*-tree during index updates, has turned into a performance advantage during lookups. Their performance dominates that of the other methods, if by only a factor of 2 margin or less. It is interesting to note that while the naive array/hashtable method performs poorly with small-to-medium population sizes, its simplicity contributes to the narrowing of the performance gap at larger population sizes. Whereas at population size 100K the gap is roughly a factor of 15, at population size 500K it is less than 10, and at 1M it is down to 4 or less.
A likely explanation for the deterioration of query performance of R-tree and R*-tree is that with very large population sizes the indices become too fragmented and their selectivity decreases. Too many moving objects compete for space in the same node of the tree, resulting in frequent node splits and small bounding boxes. The precise behavior of the index may depend on the relationship between the number of objects that fit into a node (in our case, 204 objects in each 8 kB node) and the areal density of moving objects. Also note that the size of query boxes created by our query generator is independent of the population size. Hence, the same query at population size 1M will return 10 times as many matching objects as with population size 100K, on average. However, all indexing methods tested in our experiments were subject to the same increase in result set size.
In summary, with one million objects in the index, the R-tree method can process 7 requests per second, while the R*-tree and ZB-tree methods can process 5 requests per second, and the array method 2 requests per second.
To estimate the maximum population size supported by an indexing
method, we fitted a function
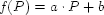 to the
measured update and query costs of the indexing methods. Parameter
to the
measured update and query costs of the indexing methods. Parameter
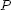 is population size and
is population size and
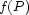 is the estimated cost
of the database update or query for that population size. We assume
that the workload consists of a sequence of database requests,
issued at an average interval of
is the estimated cost
of the database update or query for that population size. We assume
that the workload consists of a sequence of database requests,
issued at an average interval of  seconds per moving object, where a given request is an
update with probability
seconds per moving object, where a given request is an
update with probability  and query with probability
and query with probability 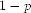 . Therefore, in a system where moving objects report
their location every 5 minutes and every update is followed by a
query, the values are
. Therefore, in a system where moving objects report
their location every 5 minutes and every update is followed by a
query, the values are 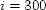 and
and 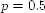 .
.
A distinct cost function and parameters  and
and 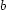 are needed to represent updates and queries. By solving
the simultaneous linear cost equations for queries and updates one
can define new parameters
are needed to represent updates and queries. By solving
the simultaneous linear cost equations for queries and updates one
can define new parameters 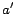 and
and 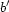 based
on the weighted average:
based
on the weighted average:
where 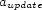 and
and
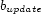 are parameters
and for update, and parameters
are parameters
and for update, and parameters
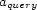 and
and
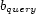 are for query.
Next, we combine the total number of requests in a cycle (every object is updated once
on average) with the estimated cost of individual update and query
operations. If the cost of an individual operation is
, the total cost of a
workload cycle
are for query.
Next, we combine the total number of requests in a cycle (every object is updated once
on average) with the estimated cost of individual update and query
operations. If the cost of an individual operation is
, the total cost of a
workload cycle 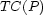 is:
is:
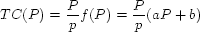 |
(2) |
In order for a location tracking application to function in real time, it holds that the total number of requests handled in time period must have a lower overall cost than itself. Therefore:
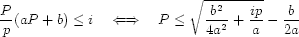
|
(3) |
The weighted parameter values and from
Equation 1 can now be applied to
Equation 3 to determine the maximum
population size supported under different workloads, update/query
ratios, and location reporting intervals.
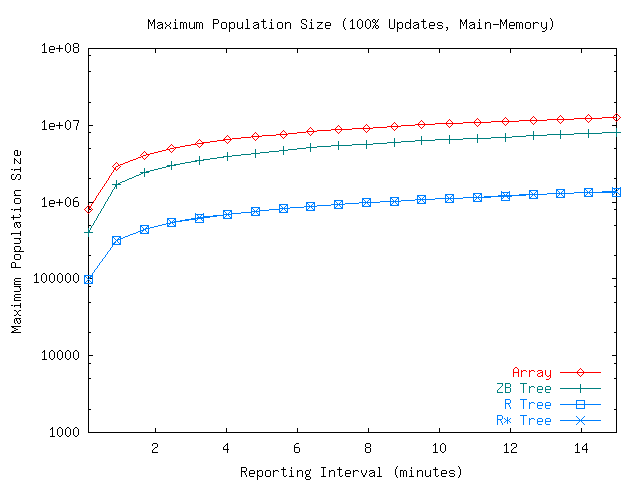
Using the estimates provided by
Equation 3, in
Figure 6 we show the maximum
population sizes supported by the indexing methods at different
reporting intervals (values of ) in an update-only tracking application. We observe that
the array/hashtable method supports up to ten million moving
objects when the reporting interval ranges between 1 and 15
minutes. A reporting interval of 30 seconds reduces the maximum
population size to just under one million. The ZB-tree method is
roughly a factor of 2 less capable. Still, with a realistic
reporting interval of a few minutes it can support a population of
several million objects. In contrast, the R-tree and R*-tree
methods were limited to population sizes of less than one million
with a comparable reporting interval.
Figure 7 shows the maximum population size supported by the ZB-tree method under various update/query workloads. When the workload consisted of updates only and each moving object reported its location every 5 minutes, the indexing method could handle roughly 5 million moving objects. The high capacity was made possible by the low update cost of the ZB-tree shown in our experiments, approximately 20 microseconds per update. The maximum population size dropped quickly as the fraction of queries increased. With a 99% update ratio, maximum population size was 0.5 million, and with 95% updates it dropped to 0.3 million. With higher query loads the maximum population size settled at the 100,000 to 250,000 range.
Tracking the location of a large population of moving objects requires very high update and query performance of the underlying spatial index. In this paper we have investigated the performance and scalability of three main-memory based spatial indexing methods under dynamic update and query loads: an R-tree, a ZB-tree, and an array/hashtable method.
Our performance experiments and analyses provided several important observations. First, even with a low-cost, commodity server one can comfortably maintain and query an index of up to several million moving objects in real time. In the worst case where every index update is accompanied by a query (``I am here, where is everybody else?'') at least 100,000 moving objects can be tracked in realtime on the server. By using filtering mechanisms or storing trajectory information instead of individual location updates, one can boost the performance even further.
The second observation is that the index workload produced by an LBS application directly influences the choice of the indexing method. Specifically, the relative frequency of updates vs. queries favors either update-optimized or query-optimized indexing methods. We point out that there may very well be location tracking applications where updates dominate the workload and sheer update power is called for, at the expense of query performance. For these applications, even the naive array/hashtable solution provides the scalability to populations of several million objects on a single processor.
In contrast, applications where at least a moderate fraction of requests are queries will want to trade off update performance for query performance. Our experiments showed that, for all the three indexing methods, query cost is typically 1 to 3 orders of magnitude higher than update cost on the same population size.
We are motivated to direct our future work toward methods for further improving the update and query performance of these and other indexing methods. In particular, we plan to investigate trajectory and other filtering techniques that will dramatically reduce the number of index updates required.