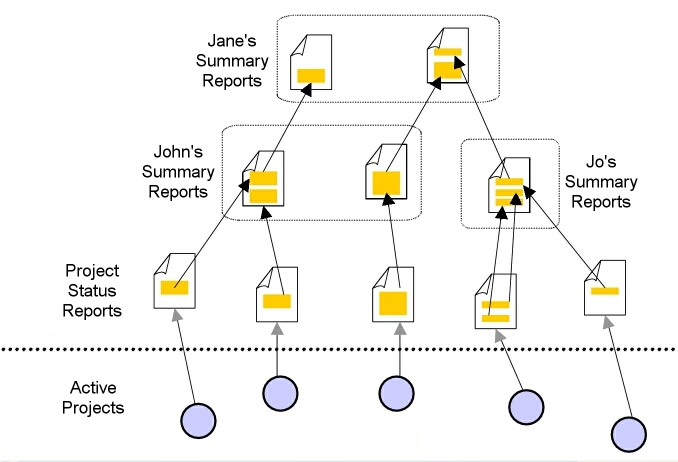
Figure 1: Multilevel report scenario
To the casual surfer, the Web is a read-only medium. Although Tim Berners-Lee's early graphical browsers allowed users to create arbitrary new pages and links, the NCSA Mosaic ``read-only'' browser later became the predominant interface to the Web, and formed the basis of modern Web browsers. However, the fact that the Mosaic browser was free, easy to use, and ran on many platforms arguably led to the exponential increases in online information that have been observed ever since. The Web has become the most visible manifestation of a new medium: a global, populist hypertext [19].
Despite the fact that material is frequently created outside the Web environment and subsequently published on a Web server, there still remain a number of applications which are made much easier if the entire information life-cycle is explicitly supported by a Web hypermedia environment. In this paper we describe one such application from the business world (management reporting) for which hypertext linking is a fundamental modelling requirement, rather than a superficial navigational aid.
Management reporting is a complex, multistage activity which takes place in the context of other business processes and makes use of the multiple information systems that may have been provided for other purposes -- general documentation, project management, financial control, email communication and business presentation. Managers treat information from these sources as ``harvestable, contextualisable data'' [29], which is combined, summarised, and reinterpreted in management reports. This paper shares our experiences in relating the management reporting process to existing Web, open hypermedia, and Semantic Web research, and describes why we chose to develop a bespoke solution - the Management Reporting System (MRS) - rather than employ an existing system to support this process.
MRS combines elements of open hypermedia (fitting hypertext functionality to the tools and environments that the author naturally uses), document creation (rather than link or annotation creation or document storage) and knowledge reuse (instead of text reuse), to provide support for Web-based management reporting.
We start by describing the scenario presented to us by a client, a legal firm, and then present our analysis of the key activities involved in the management reporting process. The way in which managers within the firm carry out this process (and associated problems arising from this current approach) is described, and the key requirements for improving support for the process are identified. We then use each of these requirements to relate the management reporting process to existing Web, open hypermedia and Semantic Web research. A further set of ``informational requirements'' for management reporting applications is derived and used to compare the different aspects of support offered by existing approaches. We then describe our own bespoke system, which attempts to meet each of these requirements, and conclude with a discussion of the implications of our work.
This section summarises the different aspects of the management reporting scenario described by our client. Staff in the Information Technology (IT) department are assigned to numerous small to medium sized projects, and must regularly produce status reports outlining the current progress of the projects (including, but not limited to, the main activities undertaken, details of staff changes, measurement of key performance indicators, and evaluation of progress against specified targets). IT managers may oversee several projects, and may share responsibilities for some projects. The following scenario is given from the perspective of an IT manager, and illustrated by Figure 1:
As an IT manager, John is responsible for several projects (for example, research, support, administrative). John must frequently publish status reports summarising the latest achievements and issues emerging from the projects in his charge. The target audience for John's status reports is John's immediate supervisor Jane, who herself may be responsible for the management of several staff, including John.
At any particular time, John's immediate business information space will contain the latest status reports produced by projects in his charge, and the previous summary reports that he has produced and published in the report repository. Part of John's management task is therefore to collate and summarise the latest activities described in the project status reports, and then refocus these issues in the wider context of his project responsibilities (``Of all the projects I am responsible for, which issues will be most important to my supervisor?'') and previous reports he has produced (``How do the issues I will raise in this summary report follow on from issues I have raised in my previous reports?''). John may also revisit previous project reports to explore how a particular issue has evolved over time (for example, ``Are there any longstanding issues which require urgent attention?''), or browse summary reports published by other managers (for example, ``Have similar issues been raised and subsequently solved in previous projects?'').
Jane carries out a similar management task. Her information space contains the latest status reports produced by John and the other managers for which she is responsible, as well as the previous summary reports which she has produced and published for her immediate supervisor. The higher-level overview of the IT projects available to Jane through these summary reports enables her to identify areas where projects efficiency could be improved, for example identifying instances where:
The three main managerial activities we identified from the above scenario are outlined:
Reading/Collating Information
IT managers must read and collate information from the latest published project status reports (and perhaps previous summary reports) to form the basis of summary reports targeted at their immediate supervisors.
Management Reporting
IT managers must bring together collated information to form a coherent perspective of the most important aspects of projects in their charge.
Issue Tracking
When an issue raised in a project status report is summarised by an IT manager in a summary report, a hypertextual connection between these reports is implied. As an issue evolves over time (toward resolution), it may appear (in different forms) in many different management reports. In order to trace the evolution of an issue, or to identify potential conflicts/solutions, IT managers must follow issue ``trails'' through reports.
This section describes the management reporting process currently employed by IT staff to carry out the activities listed above, highlighting problems that were identified.
Currently, project reports are created in Microsoft Word format and published in one of a number of distributed ``report repositories''; essentially ad-hoc shared intranet directories which can be accessed by managers and other staff.
IT managers browse these reports by loading them into Microsoft Word, and copy-and-paste material from these reports into their own ``working document'', where they add notes and comments, and reformat the material to suit the target audience. This process of combining reading with critical thinking and understanding, involving not just reading per se, but also underlining, highlighting and commenting has been described as active reading [26]. The collated material is moulded into a coherent summary report which is emailed to supervising managers and copied into the report repository.
The process of sorting through relevant materials and organising them to meet the needs of the task at hand has been described as information triage [23]. IT managers not only read multiple project reports, but they do so in parallel in an attempt to uncover potential conflicts and shared interests between projects; [2] has previously reported the frequent occurrence of this practice in work-related reading. The ``working document'' is not available to any staff other than the authoring manager (being stored on the local machine rather than in the report repository), which makes it difficult for managers to share their notes and comments or collaborate on the production of a summary report (such communication currently takes place over email, which leaves no record connected to the document that such a discussion has taken place).
The copy-and-paste process of constructing new summary reports does not explicitly link copied issues to their original source documents. In order to trace the development of an issue, or to identify potential conflicts/solutions between projects, managers must therefore revisit and trace implicit issue trails using contextual cues (for example, references to published reports/projects/dates) and ``brute force'' retrospective searches through potentially large amounts of information (``Under what circumstances did this issue arise?'', ``This issue was reported over 6 months ago; did it ever get solved?''). This process becomes especially difficult if managers are trying to find out information about unfamiliar projects.
The organisation was keen to move away from the ad-hoc shared ``report repositories'' towards an (intranet) Web-based environment, with improved, structured, access to project reports. Managers and staff would continue to use Microsoft Word as their preferred tool for report composition, but would publish these reports in the Web.
The information portal, OntoPortal [18,25], was selected as a solution for providing structured access to our client's Web-based reports. OntoPortal is a Web portal that projects intelligently interlinked hypertext over a particular domain (in this case, the domain of management reporting), according to an underlying domain ontology. The domain ontology defines the concepts (for example, Staff, Reports, Projects) and relationships (for example, Staff work on Reports), in order to provide principled and intelligent navigation of the knowledge in the domain.
However, the use of a standard Web-based infrastructure (that is, Web servers and browsers) to publish material on the corporate intranet renders the published information read-only. With knowledge and ``ownership'' of Web server space, anyone can compose and publish new information in the Web, and can link their contribution to any other Web document (without having to own it). However, the information repository essentially remains unalterable (and hence ``read-only'').
Publishing in the Web (or Web-based environments) is characterised by the addition of new content -- authors cannot modify existing content. By contrast, our client's management reporting activity is not entirely characterised by the composition of new (original) material; IT managers annotate and collate relevant information from multiple sources (including latest project status reports, previous status reports, and summary reports) which forms the basis of new content presenting this information according to a different set of constraints.
The remainder of this paper focuses on our approach to solving this problem -- given our client's requirement to provide a Web-based publishing environment, how could we support the publication cycle arising from the management reporting process? Firstly, we suggest the following requirements:
Writable Web
The report publication web should be a ``Writable Web'' -- IT managers should be able to add notes and comments to reports in situ as they are actively read. These notes and comments should be available for other managers to view as they read documents that have previously been annotated (with appropriate security restrictions -- comments added by top-level managers may not be intended for lower-level management and project staff). Managers who share responsibilities for projects should be able to facilitate simple discussion through these annotations.
Information Foraging
IT managers should be able to collate and organise notes and comments to form the basis of new summary reports. Collated notes need not belong to the collector; the comments and opinions of several managers could form the basis of a new summary report (John, on the phone to his colleague Jill: ``Could you take a look at this report and add your opinions of the issues I've highlighted?'').
Linkable Web
The web of hypertextual connections which is implicitly woven through the publish/collate cycle (reports which summarise information collated from other reports are implicitly connected to the source reports) should be captured and made explicit. Connections can then be analysed to provide overviews of the evolution of particular a issue and allow managers to quickly ``home in'' on potential problems (for example, ``Are there any issues which haven't been addressed in the past six months?'').
This section takes each of the requirements identified in the previous section and discusses relevant related work in the literature that may be useful in considering how to successfully address that requirement.
Our first requirement for supporting the management reporting process was that managers should be able to add ad-hoc shared notes and comments to reports. Although the World-Wide Web was originally developed as a shared, writable, hypertext medium, modern browsers offer a far more restricted ``read only'' view. We report here on significant efforts to bring about a widespread Writable Web.
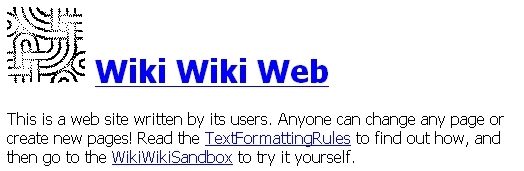
A wiki is a Web-based tool for collaborative idea exchange and writing in the Web, and is informal, quick and accessible [21]. Wikis are freely expandable collections of interlinked pages which are easily editable by any user with a forms-capable Web browser. Indeed, wikis are not carefully crafted sites for casual visitors; instead they seek to involve the visitor in an ongoing process of creation and collaboration that constantly changes the landscape of the site. Each wiki invites all users to edit any page or to create new pages within the site, and does so on a democratic basis -- every user has exactly the same capabilities as any other user, and accounts and passwords are not required.
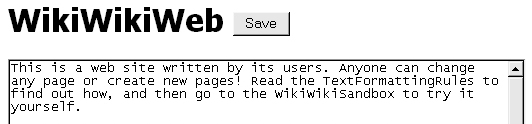
Wiki authoring takes place in a text environment using simple markup conventions (Figure 2). Hypertext links in wikis are designed to be as simple to create as possible. Every page has a title consisting of joined capitalised words (``EmbeddedCapitals''), called ``WikiWords''. To create a link in edit mode, the author just types a WikiWord.
Also integral to wiki sites is a simple search mechanism. In addition to searching the entire wiki for specific terms, each page title is linked to a search engine lookup which finds ``backlinks'' (other wiki pages that link to the current page).
WebDAV (Web Distributed Authoring and Versioning) is a set of extensions to the HTTP protocol to allow distributed, collaborative sharing and creation of resources [32]. It is a technical underpinning for web authoring tools, but is not user-oriented. It is supported by the Apple's Macintosh and Microsoft's Windows operating systems, allowing any WebDAV-enabled website to be treated as a network file system. Unlike wiki it provides no methods for creating linked pages, only the ability to store and retrieve them.
BSCW (Basic Support for Cooperative Work) is a Web-based groupware tool for online collaboration using the metaphor of shared workspaces [5], particularly suited for supporting cooperation in locally dispersed, cross-organisational groups. Shared workspaces allow collaborating users to collect and structure any kind of information (including, but not limited to, documents, images, spreadsheets, software, and URL links to other Web pages or FTP sites) in order to achieve their goals of collaboration. The content of shared workspaces are usually arranged in a folder hierarchy based on structuring principles agreed upon by members of a workspace. Users primarily access workspaces through a normal browser (no additional software required), making the main interaction with BSCW through HTTP and HTML. BSCW workspaces therefore primarily supports asynchronous modes of communication, but also provides some synchronous collaboration user notification when other members upload, download, edit, rename or move objects in the workspace.
BSCW provides a rich set of functions specific to different tasks, mostly introduced by user request. These include: authentication (users have to identify themselves with username and password before accessing workspaces), version management and locking, threaded discussion forums, sophisticated access rights model (users can be granted full or read-only access, or denied access to specific objects in workspace), search facilities (users can search for objects in the workspace by name, by content, or by properties such as modification date), annotation and rating (users may add notes to objects in the workspace), support for meetings (users can select and invite participants, and distribute meeting agendas etc.), and interfaces to third-party synchronous communication tools (such as audio/video conferencing, and shared whiteboards).
A key milestone in building the Semantic Web is the association of high-quality metadata with content [7]. Automating this task is difficult due to the unstructured nature of content on the Web, and so manually annotating Web documents is an important technique for creating the metadata [15]. The World-Wide Web Consortium's Annotea project aims to provide such a mechanism to allow users to add shared annotations to Web documents [17], based on an infrastructure which combines existing open W3C RDF, XPointer, and HTTP standards as part of a more general-purpose Semantic Web initiative.
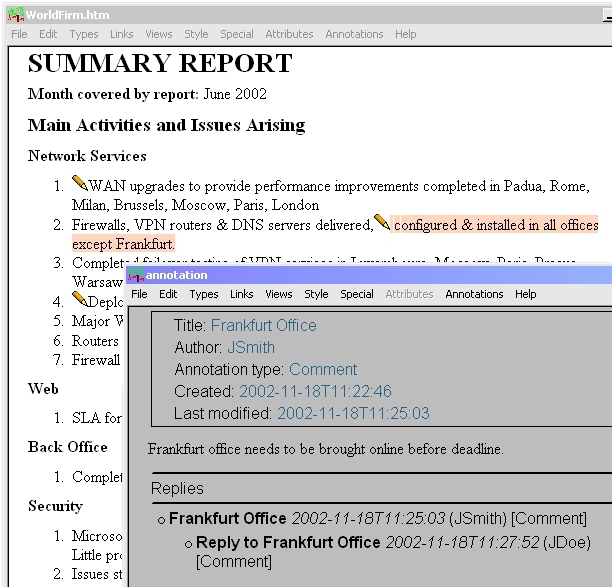
The W3C's own Amaya browser (or plug-ins for the Internet Explorer and Mozilla browsers) can be configured to communicate with a number of annotation servers. As each document is viewed in the browser, the servers are queried for annotations that have been made on that document. Annotation `icons' are inserted into the document to show annotated text -- clicking on the icon causes the content of the annotation to be displayed in a separate window (Figure 3). Heavily annotated documents can be filtered according to author name, annotation type, and annotation server. Behind the scenes, a more powerful filtering mechanism allows expert queries to made to the server, for example requesting only annotations of a particular type made in the past week by a particular author.
To create an annotation, the user highlights a text span and chooses ``Annotate selection'' from the menu (alternatively, an entire document can be annotated by choosing ``Annotate document''). This causes a separate window to open, in which the user's comments can be entered, and the semantic type of the annotation specified (by default, Amaya provides the following types: Advice, Change, Comment, Example, Explanation, Question, See Also). The id of the user is also stored, along with the creation date and an XPointer to the location of the annotated text. The use of an RDF Schema type hierarchy for representing annotations allows authors or application developers to define new types of annotation. For example, [20] demonstrates how Annotea can be extended to support ``threaded annotation discussions'' by adding a reply-to property which defines which annotation or reply was the previous one in the thread, and a root-of-thread property which is the first annotation in the thread.
Our second requirement states that IT managers should to be able to ``harvest'' issues, notes and comments from project reports published on the departmental Web, to form the basis of new summary reports. Previous approaches have used a number of techniques for supporting this activity, including browser-based bookmarking facilities [1], collection visualisation based on a book metaphor [9], and organising thumbnails of Web pages in a 3D workspace [27,3].
However, such approaches tend to deal with the Web page as the smallest unit of consideration; our scenario requires a finer level of granularity -- managers need to be able to deal with specific information components from within pages. It seems that this is not a unique requirement for a Web-based environment -- [28] report from Web user surveys that users have expressed a need to create collections from material within Web pages, but are limited by poor application support (those surveyed said that they created such collections infrequently as a result).
[29] points out that Web editors such as Microsoft Frontpage and Netscape Composer provide some support for collecting information from within Web pages, as users can drag content and images from browser to editor and arrange it in any way they wish (cf. managers dragging content from project reports to a ``working document''). However, in both cases, no information about the source travels with the dragged content: managers must explicitly add this information (e.g. title, URL) by hand to maintain the implicit hypertext connection between a summary report and its sources.
Web Squirrel is an information management tool that provides more specific support for collecting and organising information from the Web. Although the main use of the tool is to organise Web bookmarks (by dragging and dropping URLs), users can also drag (or copy and paste) information from Web pages into a large 2D workspace, where it is represented as a small rectangular `node'. The visual appearance of nodes can be manipulated in a variety of ways, including assigning different colours and font characteristics. Nodes are then dragged around the canvas to form ad-hoc spatial organisations. Software `agents' may also be instructed to sift through the collected nodes and suggest connections that the user may have overlooked. Each node has fields for storing a name, URL, and notes as well as content (users must grab the URL of copied information to retain a reference to the source). Web Squirrel workspaces (or ``information farms'' [30]) can be shared with other Web Squirrel users.
Hunter Gatherer [29] is a browser-based tool which allows users to harvest content from within Web pages into editable collections by simply highlighting the content of import and then pressing a key to add it to the current collection. The system automatically gives each piece of content a title, adds the URL as a link back to the source document, and renders the location of the selected information as an XPointer (there is no copying of content, only referencing of content addresses via XPointers). The browser integration and subsequent transparency of the select/add process means that user can focus their main attention on the information gathering task rather than continually shift that focus to other applications, such as a Web editor or Web Squirrel. Hunter Gatherer therefore minimises the ``forced divided attention'' introduced by shifting between information triage and management [29]. Collections can be distributed to other Hunter Gatherer users, but are not centrally managed.
The cycle of reading and annotating, harvesting, writing and publishing weaves a web of implicit hypertextual connections between the issues summarised in management reports and their sources. Our third requirement is that these implicit connections be captured in order that the resulting web of connections can be analysed. As we have discussed, the Web is in essence a read-only medium. Approaches to enabling a ``Writable Web'' have been discussed in previous sections, but we have yet to consider approaches which allow users to interconnect Web pages without the restrictions of ownership (Section 2.3). Several approaches have demonstrated how ``open'' hypermedia principles can be applied to the Web to allow users to create links, hyperstructures and knowledge structures over arbitrary Web pages.
``Open'' hypermedia is about hypertext which is not confined to the boundaries of a single system, be it Web browser, text editor, video streamer or midi player. An open hypertext system achieves this openness or extensibility through a ``link service'' or (more generally) ``structure service'', which undertakes the management and deployment of the hypertext links independently of the documents or data which are being interconnected. Although the Web was developed largely independently of the research in open hypermedia systems at the time, the ubiquity of the Web along with the problems inherent in its design has motivated researchers to retro-fix their systems to it [24,11,4,8], enhancing the functionality of the Web via a structure service to enable a ``Linkable Web''.
Information in Web pages is distributed across the Web, connected by HTML links. Semantic Web research strives to augment this global information network with machine-understandable metadata in order that software as well as human agents can ``understand'' it [7]; this metadata is distributed across the Web, and must also be interlinked.
Web Annotation tools such as Third Voice [22], Annotea, and those used in the KA2 initiative [6] share the idea of authors creating comments on existing Web pages (Annotea goes further to allow an RDF ``template'' to guide these annotations) -- users create simple metadata describing the page by attaching ``attributes'' to it (for example a comment ``This is very important!'' could be related to an issue in a status report using an attribute hasComment), but it is more difficult to generate interconnected metadata.
WebVise is an open hypermedia system which augments the Web's limited hypertext model with a hypermedia structure service [13], allowing authors to apply shared hypertextual structures such as multi-headed links (one-to-many or many-to-many destinations), annotations, and guided tours to Web documents. These elements are grouped into hypermedia ``contexts'' (collections of related structure, which could be used for example to represent the collaborative efforts of a small group of managers sharing responsibilities for a number of projects). WebVise integrates with the Internet Explorer browser, and with the Microsoft office applications Word and Excel. As each document is displayed, the structure service is queried for hyperstructures that apply to that document; returned links and annotations (in the form of pop-up ``post-it'' notes) are then inserted into the document.
WebVise adds extra functions to Internet Explorer's context menu, and adds custom toolbars and menus to Microsoft Word and Excel (where links can be anchored across ranges of cells in a worksheet). To create a link, the user first highlights a text span and chooses ``New Link''. Related content can be added to the link by highlighting further text spans in related documents and choosing ``Add Anchor'' from the menu. Links may also be attributed a semantic type [16] (which may have specific attributes) from a user-defined hierarchy of types constructed using a Link Types editor. Although only Internet Explorer is currently supported, hyperstructures created in WebVise can be explored in any Web browser by using a proxy service, albeit with the inherent weaknesses of this design [31].
Links, annotations, collections, and guided tours authored in WebVise can be utilised as metadata for Web resources by using the Open Hypermedia Interchange Format (OHIF) to represent the structures [12]. WebVise is extended to allow for users to create, manipulate, and share OHIF structures together with Web pages and Microsoft Office documents stored on WebDAV servers, allowing fully distributed open hypermedia linking between metadata, Web pages and WebDAV aware applications.
The CREAM [15] (CREAting Metadata) system provides Web annotation tools with which to create interconnected (or relational) Semantic Web metadata in accordance with a real-world model or domain ontology. The CREAM display is typically split between an Ontology Browser (loaded with an ontology describing the domain of interest) and a Document Viewer. Users browse to a Web document in the Document Viewer by entering a URL. Firstly, the document as a whole is defined as an instance of a particular concept in the ontology (for example Project Report). The document is then annotated by dragging and dropping pieces of content into attribute ``slots'' in the Ontology Browser (for example, the title of the report, and the date it was created). The document can also be related to other Web documents (according to the valid relationships for that document type in the domain ontology) by selecting appropriate instances from the Ontology Browser and dragging them onto the relation slots of the current instance (for example, selecting the instance which corresponds to the Project for which the Project Report was produced and dragging it onto a reports_on attribute). This relational metadata is stored by a knowledge server, and is available to any other CREAM user (in this example, the Project instance may well have been created by different user). Each time a document is displayed in the Document Viewer, any corresponding metadata is retrieved from the knowledge server and displayed in the alongside the document in the Ontology Browser.
CREAM's ``authoring mode'' attempts to address a major drawback of the original design; that in order to provide metadata about the contents of a (new) Web document, users must first create the content and second annotate the content [14]. In the revised design, metadata from the Ontology Browser can be dragged into a new document -- dropping instances, attributes, and relationships from the Ontology Browser into the document creates content and, where possible, hypertext links.
Management report creation is a complex, multistage process which takes place in the context of other business processes and makes use of the multiple information systems that may have been provided for other purposes -- general documentation, project management, financial control, email communication and business presentation. The three requirements laid out in Section 2.3, and subsequently used as a basis for the investigation of related work, can now be further broken down into more specific informational requirements for management reporting applications:
Document storage
the ability to effectively `store' and `retrieve' collections of documents.
Browsing
mechanisms to help an author locate and trace relevant information.
Organisation
the ability to impose one or more helpful views on the natural storage structure to assist in information discovery.
Annotation
the ability to mark, manipulate and comment on information that is identified as relevant.
Extraction
the ability to extract specific information from the document/annotation domain and use it as a `knowledge item' with well-specified attributes for the purposes of sorting or selection.
Document authorship
the ability to create new material which forms a document in its own right.
Linking
the ability to record hypertextual connections between the newly created material and the existing content on which it is based.
Table 1: How existing approaches support management reporting
| Wiki | WebDAV | BSCW | Annotea | Web Squirrel | Hunter Gatherer | WebVise | CREAM | |
| document storage |  |
|
|
|||||
| browsing | |
|
 |
|
||||
| organisation | |
|
|
|
|
|||
| annotation | |
|
|
|
||||
| extraction | |
|||||||
| document authorship | |
|
||||||
| linking | |
|
|
|
| Key: |
| : Full Support |
| : Partial or restricted Support |
The various approaches described in this section are candidates for supporting the management reporting task and tackle some aspects of these informational requirements (see Table 1), but a solution that covered all the key aspects required a bespoke system to be created. This system combines elements of the approaches described here, and is described in detail in the next section.
The Management Reporting System (MRS) augments the management reporting process and assists managers by enabling new project summary reports to be written and delivered (fully linked) onto the Web for other managers to read and reuse.
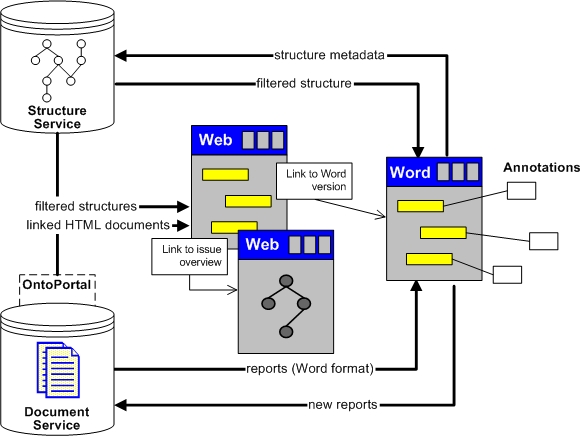
Figure 4 illustrates the architecture of the MRS system. The Document Service is used as a centralised shared repository that stores and serves management reports. The Structure Service provides a supplementary mechanism for managing issues (as references to content in documents held by the Document Server) and the network of connections between them.
The Document Service provides two main services which serve to augment the existing publication cycle. Firstly, it is responsible for providing central access to a published project repository over HTTP. The Document Service represents reports internally as XML, which can be transformed into HTML or Microsoft Word format when requested by a client. The Web interface to the Document Service is through an OntoPortal [18,25] application, which provides structured and intuitive navigation of the reports in the repository according to a simple domain model. Through the OntoPortal interface, reports can be requested in Microsoft Word format for reading, annotation, and collation of issues. Secondly, new reports created in Microsoft Word can be uploaded to the Document Service, where they are stored in XML and published through the OntoPortal interface. The Document Service also serves a number of empty ``template'' documents for creating new reports, ensuring a standard writing practice across a department.
The Structure Service is responsible for storing and serving the issues made by IT managers over project reports. It also manages a personal ``repository'' of harvested issues for each IT manager to use when collating issues -- this repository forms the basis of a new report. As issues are harvested and subsequently redressed in management summary reports, the Structure Service records the implicit hypertextual connections between the new summary report and its sources.
All reports can be viewed by any manager (with appropriate security clearance) through the OntoPortal interface of the Document Service. This also provides a convenient method (using hypertextual connections) of viewing and navigating between reports authored by a particular manager or about a particular project.
When a report is viewed through this interface, the relevant issues are retrieved from the Structure Service and merged into the report. This allows managers to quickly identify the important points raised by a report. For managers who prefer the customary Microsoft Word interface, a link is provided to open the report in Word with the issues also merged in.
In the Web interface, each issue is a hypertext link that can be followed to determine other reports that use the issue (for example, to address, solve, extend, or counter it) or other issues that are somehow related to it. This provides a unique method of exploring and collating related reports and issues and allows managers to fully understand the provenance of a problem and make subsequent pertinent contributions.
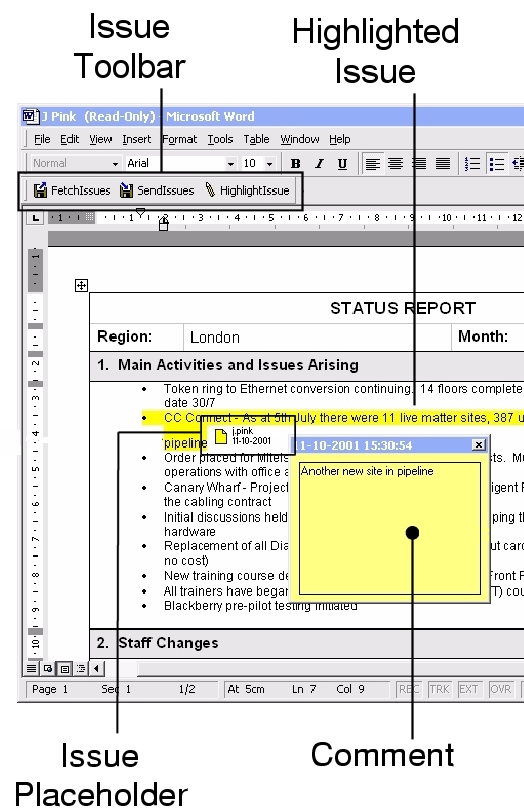
Using Microsoft Word, managers can annotate issues in reports by selecting the relevant text in the report and clicking on the ``Highlight Issue'' button (Figure 5). The manager is then able to add comments and notes to help other managers understand the precise nature of the problem. When the manager has finished annotating the report, the ``Send Issues'' button is clicked which forces all annotations to be sent to the Structure Service and recorded. Annotation metadata (which includes the id of manager who created the annotation, the time of creation, and an XPointer into the XML representation of the document held internally by the Document Server) is currently stored and communicated throughout the system using the Annotea RDF template (we have defined a special type of Issue annotation). We hope to incorporate an Annotea server as part of our Structure Service in future extensions of the system, in order to take advantage of the sophisticated annotation filtering mechanisms.
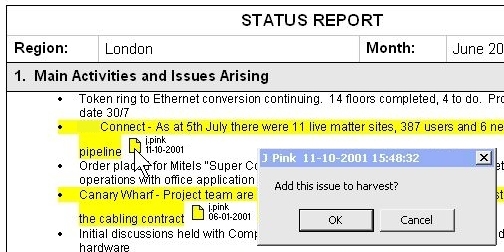
Any issue located through the Web or Word interfaces can be ``harvested'' to a manager's personal repository (Figure 6), and subsequently used to help build new summary reports (Figure 7). Collated issues need not explicitly `belong' to the collector -- with appropriate security clearance, the comments and opinions of several managers could form the basis of a new summary report. Issues are collected by double-clicking on an `issue placeholder' (see Figure 5), a mechanism informed by Hunter Gatherer's attempts to minimise the ``forced divided attention'' [29] introduced by shifting between information triage and management. Further organisation of the collection (for example, Web Squirrel's spatial canvas) is currently not supported.
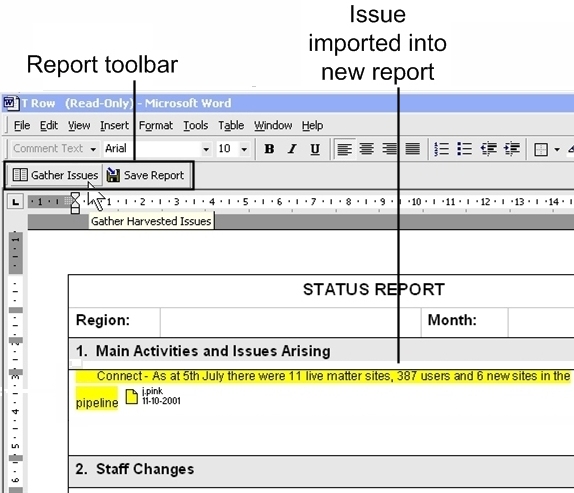
Reports are authored using the familiar Word environment. Managers click on the ``New Report'' button provided by the OntoPortal interface. This launches Word using a template provided by the Document Service, thus enforcing a consistent department-wide ``look and feel'' for all management reports. The harvested issues are then incorporated into the report by clicking on the ``Gather Issues'' button on the custom MRS toolbar (Figure 7): the content of each issue is copied (by dereferencing its XPointer) and inserted into the new report. Behind the scenes the otherwise implicit hypertextual connection between the copied issue in the new report and the original issue in the source report is explicitly captured and recorded by the Structure Service.
This behind-the-scenes process augments the existing way of working, rather than introducing a new application which forces authors to explicitly record the relationship as would be the case with existing open hypermedia systems such as WebVise and CREAM. The process is also far more informal than an equivalent process in CREAM -- MRS is a lightweight tool for supporting hypertext writing; by contrast CREAM is a more heavyweight tool for formal, knowledge based composition.
After the report has been edited by the manager, it is saved onto the Document Server by clicking on the ``Save Report'' button. This records the report in an XML format, enabling conversion back to Word and for publishing on the Web. The report subsequently becomes the source of further annotations by other (higher-level) managers and the input for other reports and summaries.
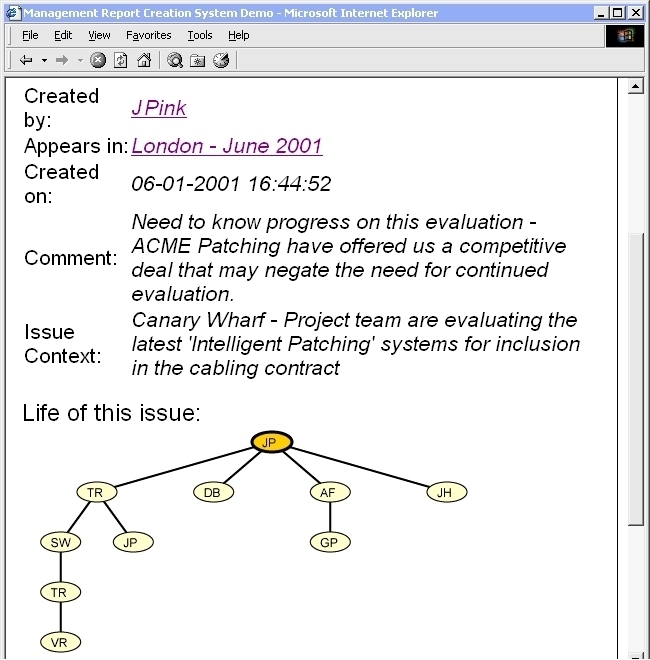
An issue's history can be graphically viewed to allow managers to get an overview of its `evolution' (Figure 8). Each node of the overview map is clickable and leads to the source report, allowing managers to quickly and easily revisit each stage in the evolution of the issue in its original context.
The Structure Service also provides filters for direct access to longstanding issues (``Which (unsolved) issues have not been active in the last 6 months?'') and unaddressed issues (``Which issues have not yet been solved?'') for a particular project or manager. These issue tracking facilities combine to present a web of hypertextual connections allowing managers to quickly ``home in'' on potential problem areas or retrospectively analyse exactly where a problem began to emerge.
Report creation is a complex, multistage cognitive process which takes place in the context of other business processes and makes use of the multiple information systems that may have been provided for other purposes -- general documentation, project management, financial control, email communication and business presentation.
Most of the activities which are employed in report creation were supported only peripherally by the IT infrastructure of the organisation in question. As the purchase of an integrated document management system was under review at the time of this work, the only support which the management team enjoyed were in document creation (Microsoft Office) and a shared (albeit ad-hoc) storage environment, where organisation and discovery was achieved by the judicious use of file naming and directory organisation. The remaining areas were filled in by human nous, effort, memory and detective work.
Writing is a complex cognitive activity which is inextricably bound in with the reading process, and not a simple one-dimensional analogue of ``content uploading''. Even the limited Web writing task described in this article has revealed the extent to which computer support is lacking for the author engaged in creating material which is related to and based upon an existing corpus (i.e. hypertext writing).
The various systems (Section 3) which are candidates for deployment tackle some of the aspects of the writing task (see Table 1), but a solution that covered all the key aspects required a bespoke system to be created (MRS). This system combined elements of open hypermedia (fitting hypertext functionality to the tools and environments that the author naturally uses), document creation (rather than link or annotation creation or document storage) and knowledge reuse (instead of text reuse).
Further work is being undertaken to adapt MRS into a general-purpose writing tool for use in the World Wide Web and to adapt Web site design methods to encompass the writing of these kinds of linked texts ([10]). MRS is also being extended to deal with academic community ontologies (representing people, projects, publications and meetings) in a Semantic Web environment and so being used to track documentary evidence for Research Project Activities as part of the Advanced Knowledge Technologies project.
This work is partly funded by the EPSRC's Advanced Knowledge Technologies IRC (GR/N15764/01) in the UK.
We would like to thank the reviewers of this paper for their encouraging comments and valuable feedback.
[1] : Information archiving with bookmarks: personal Web space construction and organisation, ,In Proceedings of CHI '98 Human Factors in Computing Systems Conference, Los Angeles, California, USA, pages 41-48, 1998.
[2] : A Diary Study of Work-Related Reading: Design Implications for Digital Reading Devices, In Proceedings of CHI '98 Human Factors in Computing Systems Conference, Los Angeles, California, USA, volume 1 of Reading and Writing, pages 241-248, 1998.
[3] : Topicshop, enhance support for evaluating and organising collections of Web sites, In Proceedings of the 13th annual ACM Symposium on User Interface Software and Technology, pages 210-209, 2000.
[4] : Integrating Open Hypermedia Systems with the World Wide Web, In Proceedings of the ACM Hypertext '97 Conference, Southampton, UK, pages 157-166, 1997.
[5] : WWW Based Collaboration with the BSCW System, In Proceedings of the 26th Annual Conference on Current Trends in Theory and Practice of Informatics (SOFSEM99), Milovy, Czech Republic, pages 66-78, 1999.
[6] : KA2: Building Ontologies for the Internet: A Midterm Report, International Journal of Human Computer Studies, 51(3), 1999.
[7] : The Semantic Web, Scientific American, May 2001.
[8] : Unifying Strategies for Web Augmentation, In Proceedings of the ACM Hypertext '99 Conference, Darmstadt, Germany, pages 91-100, 1999.
[9] : The WebBook and the Web Forager: An Information Workspace for the World-Wide Web, In Proceedings of CHI '96 Human Factors in Computing Systems Conference, Vancouver, British Columbia, Canada, 1996.
[10] : Rethinking Web Design Models: Requirements for Addressing the Text, Technical Report ECSTR-IAM03-002, University of Southampton, Southampton, UK, 2001.
[11] : The Distributed Link Service: A Tool for Publishers, Authors and Readers, Proceedings of the Fourth International World Wide Web Conference, Boston, Massachusetts, USA, 1:647-656, 1995.
[12] : Open Hypermedia as User Controlled Meta Data for the Web, In Proceedings of the Ninth International World Wide Web Conference, Amsterdam, NL, pages 553-566, 2000.
[13] : Webvise: Browser and proxy support for open hypermedia structuring mechanisms on the world wide web, In Proceedings of the Eighth International World Wide Web Conference, Boston, Massachusetts, USA, 1999.
[14] : Authoring and Annotation of Web Pages in CREAM, In Proceedings of the Eleventh International World Wide Web Conference (WWW2002), Honolulu, Hawaii, USA, May 2002.
[15] : CREAM -- Creating relational metadata with a component-based, ontology-driven annotation framework, In Proceedings of the First International Conference on Knowledge Capture (KCAP 2001), Victoria, B.C., Canada, Oct. 2001.
[16] : Dynamic use of digital library material - supporting users with typed links in open hypermedia, In European Conference on Digital Libraries, pages 254-273, 1999.
[17] : Annotea: An Open RDF Infrastructure for Shared Web Annotations, In Proceedings of the Tenth International World Wide Web Conference (WWW2001), Hong Kong, May 2001.
[18] : Linking with Meaning: Ontological Hypertext for Scholars, Technical Report 0-854327-37-1, University of Southampton, Southampton, UK, 2001.
[19] : Hubs, authorities, and communities, ACM Computing Surveys, 31(4es), Dec. 1999.
[20] : Metadata Based Annotation Infrastructure offers Flexibility and Extensibility for Collaborative Applications and Beyond, In Proceedings of the First International Conference on Knowledge Capture (KCAP 2001), Victoria, B.C., Canada, Oct. 2001.
[21] : The Wiki Way: Quick Collaboration on the Web, Addison Wesley Professional, 2001.
[22] : Third Voice: Vox Populi Vox Dei?, First Monday, 4(10), Oct. 1999.
[23] : Spatial Hypertext and the Practice of Information Triage, In Proceedings of the ACM Hypertext '97 Conference, Southampton, UK, Structure and Spatiality, pages 124-133, 1997.
[24] : Hyper-G now Hyperwave: the next generation Web solution, Addison Wesley, 1995.
[25] : Hypertext in the Semantic Web, In Proceedings of the ACM Hypertext 2001 Conference, Aarhus, Denmark, pages 237-238, Aug. 2001.
[26] : XLibris: The Active Reading Machine, In Proceedings of CHI '98 Human Factors in Computing Systems Conference, Los Angeles, California, USA, volume 2 of Demonstrations: Dynamic Documents, pages 22-23, 1998.
[27] : Data mountain: using spatial memory for document management, In Proceedings of the 11th annual ACM Symposium on User Interface Software and Technology, pages 153-162, 1998.
[28] : Preliminary Requirements Gathering for the Design of User-determined, Within-page, Web-based Collections, Technical Report CSRG-433, Department of Computer Science, University of Toronto, Toronto, Canada, 2001.
[29] : Hunter Gatherer: Interaction Support for the Creation and Management of Within-Web-Page Collections, In Proceedings of the Eleventh International World Wide Web Conference (WWW2002), Honolulu, Hawaii, USA, May 2002.
[30] : Experiences with the Web Squirrel: My Life on the Information Farm, In Proceedings of the ACM Hypertext 2001 Conference, Arhus, Denmark, 2001.
[31] : On Web Annotations: Promises and Pitfalls of Current Web Infrastructure, In Proceedings of the 32nd Hawaii International Conference on Systems Sciences, Jan. 1999.
[32] : WebDAV: A network protocol for remote collaborative authoring on the Web, In Proceedings of the Sixth European Conference on Computer Supported Cooperative Work (ECSCW'99), Copenhagen, Denmark, pages 291-310, Sept. 1999.