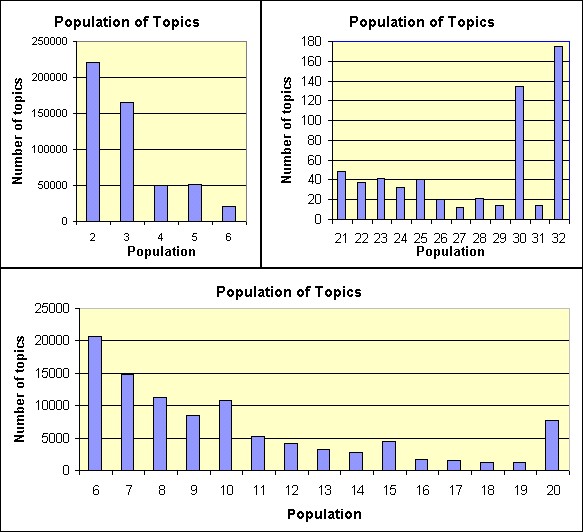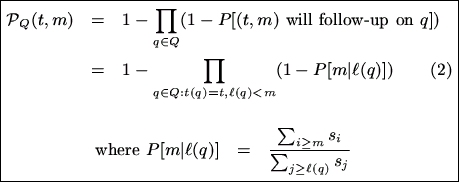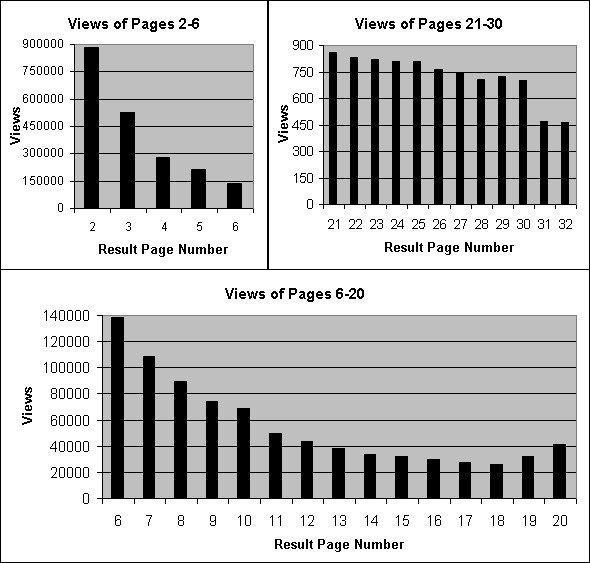
Figure 1: Views of result pages 2-32
Popular search engines receive millions of queries per day on any and every walk of life. While these queries are submitted by millions of unrelated users, studies have shown that a small set of popular queries accounts for a significant fraction of the query stream. Furthermore, search engines may also anticipate user requests, since users often ask for more than one page of results per query. It is therefore commonly believed that all major search engines perform some sort of search result caching and prefetching. An engine that answers many queries from a cache instead of processing them through its index, can lower its response time and reduce its hardware requirements.
Jónsson et al. [7], in their work on buffering inverted lists for query evaluations, noted that knowledge of the access patterns of the retrieval algorithm to the buffers can be tapped for devising effective buffer replacement schemes. By analogy, understanding the access patterns of search engine users to query results can aid the task of caching search results.
Users interact with search engines in search sessions. Sessions begin when users submit initial queries to search engines, by typing some search phrase which describes their topic of interest. From the users' point of view, an engine answers each initial query with a linked set of ranked result pages, typically with 10 results per page. All users browse the first page of results, which contains the results deemed by the engine's ranking scheme to be the most relevant to the query. Some users scan additional result pages, usually in the natural order in which those pages are presented. Technically, this involves querying the engine for the desired additional result pages, one page at a time. We refer to such requests as follow-up queries. A search session implicitly terminates when the user decides not to request additional result pages on the topic which initiated the session.
Three studies have analyzed the manner in which users query search engines and view result pages: a study by Jansen et al. [6], based on 51473 queries submitted to the search engine Excite; a study by Markatos [11], based on about a million queries submitted to Excite on a single day in 1997; and a study by Silverstein et al. [14], based on about a billion queries submitted to the search engine AltaVista over a period of 43 days in 1998. Two findings that are particularly relevant to this work concern the number of result pages that users view per query, and the distribution of query popularities. Regarding the former, the three studies agree that at least 58% of the users view only the first page of results (the top-10 results), at least 15% of the users view more than one page of results, and that no more than 12% of users browse through more than 3 result pages. Regarding query popularities, it was found that the number of distinct information needs of users is very large. Silverstein et al. report that 63.7% of the search phrases appear only once in the billion query log. These phrases were submitted just once in a period of six weeks. However, popular queries are repeated many times: the 25 most popular queries found in the AltaVista log account for 1.5% of the submissions. The findings of Markatos are consistent with the later figure - the 25 most popular queries in the Excite log account for 1.23% of the submissions. Markatos also found that many successive submissions of the same query appear in close proximity (are separated by a small number of other queries in the query log).
Caching of results was noted in Brin and Page's description of the prototype of the search engine Google as an important optimization technique of search engines [2]. In [11], Markatos used the million-query Excite log to drive simulations of query result caches using four replacement policies - LRU (Least Recently Used) and three variations. He demonstrated that warm, large caches of search results can attain hit ratios of close to 30%.
Saraiva et al. [13] proposed a two-level caching scheme that combines caching query results and inverted lists. The replacement strategy they adopted for the query result cache was LRU. They experimented with logged query streams, testing their approach against a system with no caches. Overall, their combined caching strategy resulted in a threefold increase in the throughput of the system, while preserving the response time per query.
In addition to storing results that were requested by users in the cache, search engines may also prefetch results that they predict to be requested shortly. An immediate example is prefetching the second page of results whenever a new query is submitted by a user. Since studies of search engines' query logs [6,14] indicate that the second page of results is requested shortly after a new query is submitted in at least 15% of cases, search engines may prepare and cache two (or more) result pages per query. The prefetching of search results was examined in [10], albeit from a different angle: the objective was to minimize the computational cost of processing queries rather than to maximize the hit ratio of the results cache.
The above studies, as well as our work, focus on the caching of search results inside the search engine. The prefetching discussed above deals with how the engine itself can prefetch results from its index to its own cache. The caching or prefetching of search results outside the search engine is not considered here. In particular, we are not concerned with how general Web caches and proxy servers should handle search results. Web caching and prefetching is an area with a wealth of research; see, for example, [16] for a method that allows proxy servers to predict future user requests by analyzing frequent request sequences found in the servers' logs, [15] for a discussion of proxy cache replacement policies that keep a history record for each cached object, and [4] for a proposed scheme that supports the caching of dynamic content (such as search results) at Web proxy servers. In both [17] and [9], Web caching and document prefetching is integrated using (different) prediction models of the aggregate behavior of users. Section 3.2.2 has more details on these two works.
This work examines the performance of several cache replacement policies on a stream of over seven million real-life queries, submitted to the search engine AltaVista. We integrate result prefetching into the schemes, and find that for all schemes, prefetching substantially improves the caches' performance. When comparing each scheme with prefetching to the naive version that only fetches the requested result pages, we find that prefetching improves the hit ratios by more than what is achieved by a fourfold increase in the size of the cache.
Another contribution of this paper is the introduction of a novel cache replacement policy that is tailored to the special characteristics of the query result cache. The policy, which is termed PDC (Probability Driven Cache), is based on a probabilistic model of search engine users' browsing sessions. Roughly speaking, PDC prioritizes the cached pages based on the number of users who are currently browsing higher ranking result pages of the same search query. We show that PDC consistently outperforms LRU and SLRU (Segmented LRU) based replacement policies, and attains hit ratios exceeding 53% in large caches.
Throughout this paper, a query will refer to an ordered pair (t,k) where t is the topic of the query (the search phrase that was entered by the user), and k is the number of result page requested. For example, the query (t,2) will denote the second page of results (which typically contains results 11-20) for the topic t.
The rest of this work is organized as follows. Section 2 describes the query log on which we conducted our experiments. Section 3 presents the different caching schemes that this work examined, and in particular, defines PDC and the model on which it is based. Section 4 reports the results of the trace-driven simulations with which we evaluated the various caching schemes. Concluding remarks and suggestions for future research are brought in Section 5.
The log contained 7175151 keyword-driven search queries, submitted to the search engine AltaVista during the summer of 2001. AltaVista returns search results in batches whose size is a multiple of 10. For r>=1, the results whose rank is 10(r-1)+1,...,10r will be referred to as the r'th result page. A query that asks for a batch of 10k results will be thought of as asking for k logical result pages (although, in practice, a single large result page will be returned). Each query can be seen as a quadruple q=(z,t,f,l) as follows:
In order to ease the implementation of our simulations, we discarded from the trace all queries that requested result pages 33 and beyond (results whose rank is 321 or worse). There were 14961 such queries, leaving us with 7160190 traced queries. These queries contained requests for 4496503 distinct result pages, belonging to 2657410 distinct topics.
The vast majority of queries (97.7%) requested 10 results, in a standard single page of results (in most cases, f equaled l). However, some queries requested larger batches of results, amounting to as many as 10 logical result pages. Table 1 summarizes the number of queries requesting different bulks of logical result pages (i.e., different values of f-l+1). Table 1 implies that the total number of requested logical pages, also termed as page views, is 7549873.
Table 1: Number of queries requesting different bulks of logical result pages (bulk size equals f-l+1 )
| No. result pages | 1 | 2 | 3 | 4 | 5 | 6 | 7,8,9 | 10 |
|---|---|---|---|---|---|---|---|---|
| No. queries | 6998473 | 31477 | 84795 | 939 | 42851 | 125 | 0 | 1530 |
As discussed in the Introduction, most of the requests were for the first page of results (the top-10 results). In the trace considered here, 4797186 of the 7549873 views (63.5%) were of first pages. The 885601 views of second pages accounted for 11.7% of the views. Figure 1 brings three histograms of the number of views for result pages 2-32. The three ranges are required since the variance in the magnitude of the numbers is quite large. Observe that higher ranking result pages are generally viewed more than lower ranking pages. This is due to the fact that the users who view more than one result page, usually browse those pages in the natural order. This sequential browsing behavior allows for predictive prefetching of result pages, as will be shown in Section 4.
Figure 1 shows a sharp drop between the views of result pages 20 and 21. This drop is explained by the manner in which AltaVista answered user queries during the summer of 2001. ``Regular'' users who submitted queries were allowed to browse through 200 returned results, in 20 result pages containing 10 results each. Access to more than 200 results (for standard search queries) was restricted by the engine.
Having discussed the distribution of views per result page number, we examine a related statistic - the distribution of the number of distinct result pages viewed per topic. We term this as the population of the topic. In almost 78% of topics (2069691 of 2657410), only a single page was viewed (usually the first page of results), and so the vast majority of topics have a population of 1. Figure 2 shows the rest of the distribution, divided into three ranges due to the variance in the magnitude of the numbers. Note the unusual strength of topics with populations of 10, 15 and 20.
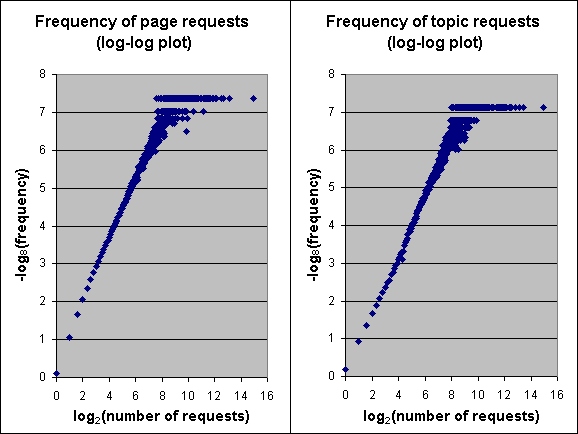
From topic populations we turn to topic (and page) popularities. Obviously, different topics (search phrases) and result pages are requested at different rates. Some topics are extremely popular, while the majority of topics are only queried once. As mentioned earlier, the log contained queries for 2657410 distinct topics. 1792104 (over 67%) of those topics were requested just once, in a single query (the corresponding figure in [14] was 63.7%). The most popular topic was queried 31546 times. In general, the popularity of topics follows a power law distribution, as shown in Figure 3. The plot conforms to the power-law for all but the most popular topics, which are over-represented in the log. A similar phenomenon is observed when counting the number of requests for individual result pages. 48% of the result pages are only requested once. However, the 50 most requested pages account for almost 2% of the total number of page views (150131 of 7549873). Again, the distribution follows a power law for all but the most oft-requested result pages (also in Figure 3). The power law for page[topic] popularities implies that the probability of a page[topic] being requested x times is proportional to x-c. In this log, c is approximately 2.8 for page popularities and about 2.4 for topic popularities.
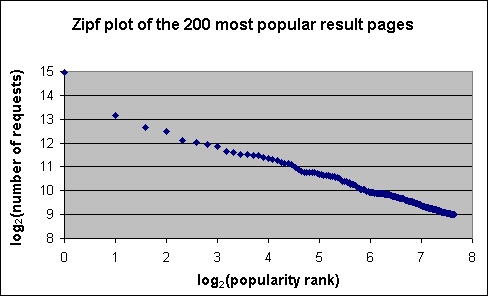
The log contained exactly 200 result pages that were requested more than 29=512 times. As seen in Figure 3, these pages do not obey the above power law. However, they have a distinctive behavior as well: the number of requests for these pages conforms to a Zipf distribution, as Figure 4 shows. This means that the number of requests for the r'th most popular page is proportional to r-c; in Figure 4, c is approximately 0.67. This is consistent with the results of Markatos [11], who plotted the number of requests for the 1000 most popular queries in the Excite log, and found that the plot conforms to a Zipf distribution. Saraiva et al. [13], who examined 100000 queries submitted to a Brazilian search engine, report that the popularities of all queries follow a Zipf distribution.
Studies of Web server logs have revealed that requests for static Web pages follow a power law distribution [1]. The above cited works and our findings show that this aggregate behavior of users carries over to the browsing of dynamic content, where the users define the query freely (instead of selecting a resource from a fixed ``menu'' provided by the server). We also note that the complex, distributed social process of creating hyperlinked Web content gives rise to power law distributions of inlinks to and outlinks from pages [3]. See [12] for a general survey of power law, Pareto, Zipf and lognormal distributions.
In many search engine architectures, the computations required during query execution are not greatly affected by the number of results that are to be prepared, as long as that number is relatively small. In particular, it may be that for typical queries, the work required to fetch several dozen results is just marginally larger than the work required for fetching 10 results. Since fetching more results than requested may be relatively cheap, the dilemma is whether storing the extra results in the cache (at the expense of evicting previously stored results) is worthwhile. Roughly speaking, result prefetching is profitable if, with high enough probability, those results will be requested shortly - while they are still cached and before the evicted results are requested again. One aspect of result prefetching was analyzed in [10], where the computations required for query executions (and not cache hit ratios) were optimized.
In our simulations, all caching schemes will fetch results in bulks whose size is a multiple of k, a basic fetch unit. Formally, let q be a query requesting result pages f through l for some topic. Let a and b be the first and last uncached pages in that range, respectively (f <= a <=b <= l). A k-fetch policy will fetch pages a,a+1,...,a+mk-1, where m is the smallest integer such that a+mk-1>=b. Recall that over 97% of the queries request a single result page (f=l). When such a query causes a cache fault, a k-fetch policy effectively fetches the requested page and prefetches the next k-1 result pages of the same topic. When k=1, fetching is performed solely on demand.
For every fetch unit k, we can estimate theoretical upper
bounds on the
hit ratio attainable by any cache replacement policy on our specific query
log. Consider a cache of infinite size, where evictions are never necessary.
For each topic t,
we examine Pt, the subset of the 32 potential
result pages that were actually requested in the log.
We then cover Pt with the minimal number
of fetch units possible. This number, denoted by
f k ( t ),
counts how many k-fetch query executions are required
for fetching Pt. The sum
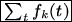 is a close approximation to the minimal number of faults that any
policy whose fetch unit is k will have on our query log.
Table 2 brings these
theoretical bounds for several fetch units.
is a close approximation to the minimal number of faults that any
policy whose fetch unit is k will have on our query log.
Table 2 brings these
theoretical bounds for several fetch units.
Table 2: Upper bounds on hit ratios for different values of the fetch unit
| Fetch Unit | Number of Fetches | Hit Ratio |
| 1 | 4496503 | 0.372 |
| 2 | 3473175 | 0.515 |
| 3 | 3099268 | 0.567 |
| 4 | 2964553 | 0.586 |
| 5 | 2861390 | 0.600 |
| 10 | 2723683 | 0.620 |
| 20 | 2658159 | 0.629 |
| 32 | 2657410 | 0.629 |
Note the dramatic improvement in the theoretic hit ratio as the fetch unit grows from 1 to 3.
We experimented with five cache replacement policies. The first four are adaptations of the well-known LRU and SLRU policies [8]. The complexity of treating a query is O(1) for each of those policies. The fifth policy, which we call Probability Driven Cache (PDC), is a novel approach tailored for the task of caching query result pages. It is more complex, requiring O(log(size-of-cache)) operations per query. The following describes the data structures that are used in each scheme, and the manner in which each scheme handles queries. For this we define, for a query q that requests the set of pages P(q), two disjoint sets of pages C(q) and F(q):
Cache replacement policies attempt to keep pages that have a high probability of being requested in the near future, cached. The PDC scheme is based on a model of search engine users that concretely defines the two vague notions of ``probability of being requested'' and ``near future''.
We describe the model by presenting the rules which define search sessions (see Section 1.1) in it. For this, let { qiu=( ziu, tiu, fiu, liu) }i >=1 denote the sequence of queries that user u issues, where ziu is the time of submission of qiu, tiu is the topic (search phrase) of the query, and fiu <= liu define the range of result pages requested.
Consider qiu and
qi+1u,
two successive queries issued by user u.
In this model,
qi+1u
may either be a follow-up on
qiu,
or start a new search session.
Furthermore, search sessions in this model view result pages
strictly in their natural order, and in a prompt manner. Therefore,
if qi+1u
is a follow-up on
qiu
(denoted
qiu
![]() qi+1u), then
qi+1u
is submitted no more that W time units after
qi
(that is,
zi+1u <=
ziu+W)
and
fi+1u=
liu+1.
Obviously, in this case
ti+1u =
tiu.
On the other hand,
qi+1u
starts a new search session whenever
fi+1u =1.
We also assume that the first query of every user u,
q1u,
requests the top result page of some topic. Thus,
qiu,...,qju
(i <= j) constitute a search session whenever
fiu=1,
qku
qi+1u), then
qi+1u
is submitted no more that W time units after
qi
(that is,
zi+1u <=
ziu+W)
and
fi+1u=
liu+1.
Obviously, in this case
ti+1u =
tiu.
On the other hand,
qi+1u
starts a new search session whenever
fi+1u =1.
We also assume that the first query of every user u,
q1u,
requests the top result page of some topic. Thus,
qiu,...,qju
(i <= j) constitute a search session whenever
fiu=1,
qku
![]() qk+1u
for all i<=k<j,
and qj+1u is not a
follow up on qju.
qk+1u
for all i<=k<j,
and qj+1u is not a
follow up on qju.
This model of search behavior limits the ``attention span'' of search engine users to W time units: users do not submit follow-up queries after being inactive for W time units. Long inactivity periods indicate that the user has lost interest in the previous search session, and will start a new session with the next query. Following are several implications of this model:
Q =
{ qzu, u
![]() U:
qzu was submitted after z-W }
(1)
U:
qzu was submitted after z-W }
(1)
The model assumes that there are topic and user independent probabilities sm, m>=1, such that sm is the probability of a search session requesting exactly m result pages. Furthermore, the model assumes that it is familiar with these probabilities.
For a query q, let t(q) denote the query's topic and let l(q) denote the last result page requested in q. For every result page (t,m), we can now calculate PQ(t,m), the probability that (t,m) will be requested as a follow-up to at least one of the queries in Q:
P[m|l] is the probability that a session will request result page m, given that the last result page requested so far was page l. PQ(t,m) depends on the number of users who are currently searching for topic t, as well as on the last t-page requested by every such user. PQ(t,m) will be large if many users have recently (within W time units) requested t-pages whose number is close to (but smaller than) m. Note that for all t, PQ(t,1)=0; the model does not predict the topics that will be the focus of future search sessions. PDC prioritizes cached (t,1) pages by a different mechanism than the PQ(t,m) probabilities.
Kraiss and Weikum also mention setting the priority of a cached entry by the probability of at least one request for the entry within a certain time horizon [9]. Their model for predicting future requests is based on continuous-time Markov chains, and includes the modeling of new session arrivals and current session terminations. However, the main prioritization scheme that they suggest, and which is best supported by their model, is based on the expected number of requests to each cached entry (within a given time frame). Prioritizing according to the probability of at least one visit is quite complex in their model, prompting them to suggest a calculation which approximates these probabilities. As the model behind PDC is simpler than the more general model of [9], the calculations it involves are also significantly less expensive.
The PDC scheme is based on the model described above in a manner that allows it to handle real-life query streams, which do not necessarily conform to the strict rules of the model. PDC attempts to prioritize its cached pages using the probabilities calculated in Equation 2. However, since these probabilities are zero for all (t,1) pages, PDC maintains two separate buffers: (1) an SLRU buffer for caching (t,1) pages, and (2) a priority queue PQ for prioritizing the cached (t,m>1) pages according to the probabilities of Equation 2. The relative sizes of the SLRU and PQ buffers are subject to optimization, as will be discussed in Section 4.2. For the time being, let CPQ denote the size (capacity) of PQ. In order to implement PQ, PDC must set the probabilities sm, m>=1, and keep track of the set of queries Q, defined in Equation 1:
Each query q=(z,t,f,l) is processed in PDC by the following four steps:
In order to implement the above procedure efficiently, PDC maintains a topic table, where every topic (1) links to its cached pages in PQ, (2) points to its top result page in the SLRU, and (3) keeps track of the QW entries associated with it. When the number of different result pages that may be cached per topic is bounded by a constant, and when PQ is implemented by a heap, the amortized complexity of the above procedure is O(log(CPQ)) per query. Amortized analysis is required since the number of topics affected by the QW updates while treating a single query, may vary. Other implementations may choose to have QW hold a fixed number of recent queries without considering the time frame. Such implementations will achieve a non-amortized complexity of O(log(CPQ)). See [5] for discussions of the heap data structure and of amortized analysis.
As noted above, the cache in PDC is comprised of two separate buffers of fixed size, an SLRU for (t,1) pages and a priority queue for all other pages. Two buffers are also maintained in [17]; there, the cache buffer is dedicated to holding pages that were actually requested, while the prefetch buffer contains entries that the system predicts to be requested shortly. Pages from the prefetch buffer migrate to the cache buffer if they are indeed requested as predicted.
This section reports the results of our experiments with the various caching schemes. Each scheme was tested with respect to a range of cache sizes, fetch units and other applicable parameters. Subsection 4.1 concretely defines the terms cache size and hit ratio in the context of this work. Subsection 4.2 discusses the schemes separately, starting with the LRU-based schemes, moving to the more complex SLRU-based schemes, and ending with the PDC scheme. A cross-scheme comparison is brought in Subsection 4.3.
Cache sizes in this work are measured by page entries, which are abstract units of storage that hold the information associated with a cached result page of 10 search results. Markatos [11] estimates that such information requires about 4 kilobytes of storage. Since the exact amount of required memory depends on the nature of the information stored and its encoding, this figure may vary from engine to engine. However, we assume that for every specific engine, the memory required does not vary widely from one result page to another, and so we can regard the page entry as a standard memory unit. Note that we ignore the memory required for bookkeeping in each of the schemes. In the four LRU-based policies, this overhead is negligible. In PDC, the query window QW requires several bytes of storage per kept query. We ignore this, and only consider the capacity of the SLRU and PQ buffers of PDC.
As shown in Table 1, the queries in our trace file may request several (up to 10) result pages per query. Thus, it is possible for a query to be partially answered by the cache - some of the requested result pages may be cached, while other pages might not be cached. In our reported results, a query counts as a cache hit only if it can be fully answered from the cache. Whenever one or more of the requested pages is not cached, the query counts as a cache fault, since satisfying the query requires processing it through the index of the engine. It follows that each query causes either a hit or a fault. The hit ratio is defined as the number of hits divided by the number of queries. It reflects the fraction of queries that were fully answered from the cache, and required no processing whatsoever by the index.
We begin all our simulations with empty, cold caches. In the first part of the simulation, the caches gradually fill up. Naturally, the number of faults during this initial period is very high. When a cache reaches full capacity, it becomes warm (and stays warm for the rest of the simulation). The hit ratios we report are for full, warm caches only. The definition of a full cache for the PLRU and TLRU schemes is straightforward - the caches of those schemes become warm once the page queue is full. The PSLRU and TSLRU caches become warm once the probationary segment of the SLRU becomes full for the first time. The PDC cache becomes warm once either the probationary segment of the SLRU or the PQ component reach full capacity.
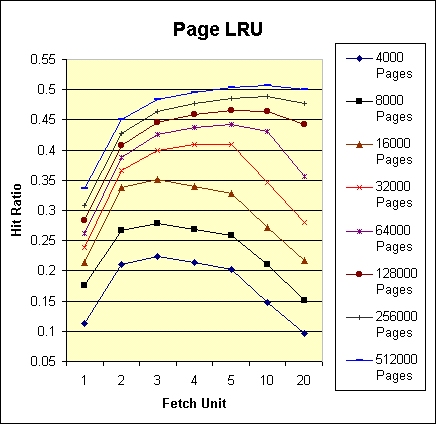
Both schemes were tested for the eight cache sizes 4000*2i, i=0,...,7, and for fetch units of 1,2,3,4,5,10 and 20 (56 tests per scheme). The hit ratios achieved with both schemes was nearly identical; Figure 5 displays the results of PLRU.
The following discussion addresses both PLRU and TLRU. We denote the hit ratio of either policy with fetch unit f and cache size s by LRU(s,f).
Table 3 summarizes the effect of the fetch unit on the hit ratios of PLRU and TLRU. For each cache size s, the hit ratio LRU(s,1) is compared to the hit ratio achieved with the optimal fetch unit (fopt). Note that the former ratios, which are between 0.3 and 0.35 for the large cache sizes, are consistent with the hit ratios reported by Markatos [11]. Also note that PLRU outperforms TLRU for small caches, while TLRU is better for large caches (although the difference in performance is slight).
Table 3: Impact of the fetch unit on the performance of PLRU and TLRU
| Cache size (s) | PLRU(s,1) | PLRU fopt , resulting hit ratio |
TLRU(s,1) | TLRU fopt , resulting hit ratio |
| 4000 | 0.113 | 3, 0.224 | 0.107 | 3, 0.228 |
| 8000 | 0.176 | 3, 0.278 | 0.168 | 3, 0.276 |
| 16000 | 0.215 | 3, 0.350 | 0.215 | 3, 0.349 |
| 32000 | 0.239 | 5, 0.410 | 0.241 | 4, 0.411 |
| 64000 | 0.261 | 5, 0.442 | 0.265 | 5, 0.445 |
| 128000 | 0.284 | 5, 0.465 | 0.288 | 10, 0.469 |
| 256000 | 0.308 | 10, 0.488 | 0.314 | 10, 0.491 |
| 512000 | 0.336 | 10, 0.508 | 0.343 | 10, 0.511 |
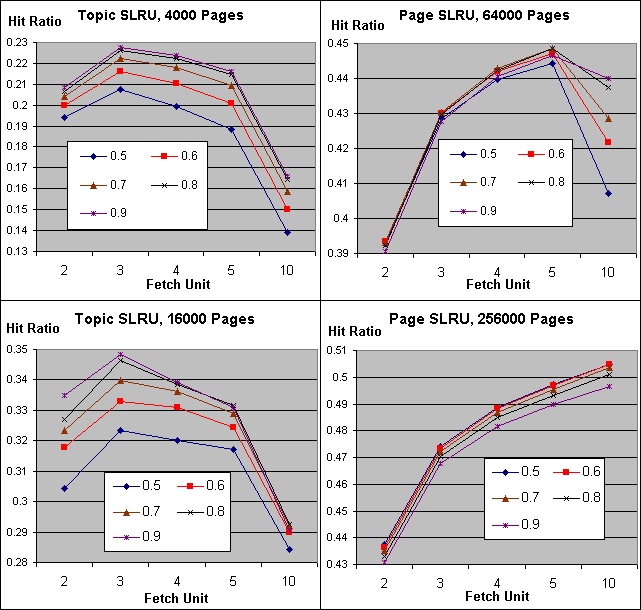
These two schemes have an additional degree of freedom as compared with the LRU based schemes - namely, the ratio between the size of the protected segment and that of the probationary segment. Here, we tested four cache sizes (s=4000*4i, i=0,...,3) while varying the size of the probationary segment of the SLRU from 0.5s to 0.9s, in 0.1s increases. Having seen the behavior of the fetch unit in the LRU-based schemes, we limited these simulations to fetch units of 2,3,4,5 and 10. Overall, we ran 100 tests per scheme (4 cache sizes x 5 fetch units x 5 Probationary segment sizes). As with PLRU and TLRU, here too there was little difference between the behavior of PSLRU and TSLRU. Therefore, Figure 6 shows results of a single scheme for each cache size. The label of each plot describes the corresponding relative size of the probationary SLRU segment.
The effect of the fetch unit is again dramatic, and is similar to that observed for the PLRU and TLRU schemes. As before, the optimal fetch unit increases as the cache size grows. Furthermore, the optimal fetch unit depends only on the cache size, and is independent of how that size is partitioned among the two SLRU segments.
The effect of the relative sizes of the two SLRU segments on the hit ratio is less significant. To see that, we fix the optimal fetch unit for each cache size s, and examine the different hit ratios that are achieved with different SLRU partitions. For s=4000 and s=16000, the hit ratio increased as the probationary segment grew. However, the increase in hit ratio between the best and worst SLRU partitions was at most 0.025. For the larger sizes of s=64000 and s=256000, the results were even tighter. The optimal sizes of the probationary segment were 0.7s and 0.6s respectively, but all five examined SLRU partitions achieved hit ratios that were within 0.01 of each other. We conclude that once the fetch unit is optimized, the relative sizes of the two cache segments are marginally important for small cache sizes, and hardly matter for large caches.
The PDC scheme has two new degrees of freedom which were not present in the SLRU-based schemes: the length of the window QW, and the ratio between the capacity of the SLRU, which holds the (t,1) pages of the various topics, and the capacity of the priority queue PQ, that holds all other result pages. We tested three window lengths (2.5, 5 and 7.5 minutes), four cache sizes (s=4000*4i, i=0,...,3), and 7 fetch units (1,2,3,4,5,10,20). For every one of the 84 combinations of window length, cache size and fetch unit, we tested 20 partitionings of the cache: four PQ sizes (0.3s, 0.35s, 0.4s and 0.45s), and the same 5 internal SLRU partitionings as examined for the PSLRU and TSLRU schemes. To summarize, 560 different simulations were executed for each window size, giving a total of 1680 simulations. Our findings are described below.
The most significant degree of freedom was, again, the fetch unit. As with the previous schemes, the optimal fetch unit grew as the size of the cache grew. Furthermore, the optimal fetch unit depended only on the overall size of the cache, and not on the specific boundaries between the three storage segments. When limiting the discussion to a specific cache size and the corresponding optimal fetch unit, the hit ratio is quite insensitive to the boundaries between the three cache segments. The difference in the hit ratios that are achieved with the best and worst partitions of the cache was no more than 0.015. As an example, we bring the hit ratios for a PDC of 64000 total pages, with a window of 5 minutes. The optimal fetch unit proved to be 5. Table 4 brings the hit ratios of 20 different partitionings of the cache - four PQ sizes (corresponding to 0.45,0.4,0.35 and 0.3 of the cache size), and five partitionings of the remaining pages in the SLRU (the x:1-x notation denotes the relative sizes of the probationary and protected segments, respectively). The trends are clear - a large PQ and an equal partitioning of the SLRU outperform smaller PQs or skewed SLRU partitionings. However, all 20 hit ratios are between 0.453 and 0.468.
Table 4: Insensitivity of the PDC scheme to internal partitions of the cache (5-minute window, 64000 pages, fetch unit=5).
| PQ size (pages) | SLRU 0.5:0.5 | SLRU 0.6:0.4 | SLRU 0.7:0.3 | SLRU 0.8:0.2 | SLRU 0.9:0.1 |
| 28800 | 0.468 | 0.467 | 0.466 | 0.464 | 0.462 |
| 25600 | 0.468 | 0.467 | 0.466 | 0.464 | 0.462 |
| 22400 | 0.466 | 0.465 | 0.464 | 0.462 | 0.459 |
| 19200 | 0.460 | 0.460 | 0.458 | 0.456 | 0.453 |
Table 5: Optimal parameters and hit ratios for the tested PDC settings
| window (minutes) | cache size (result pages) |
fetch unit | PQ size | SLRU Probationary segment size |
hit ratio |
| 2.5 | 4000 | 3 | 0.45 | 0.8 | 0.2430 |
| 2.5 | 16000 | 4 | 0.45 | 0.6 | 0.3728 |
| 2.5 | 64000 | 5 | 0.45 | 0.5 | 0.4668 |
| 2.5 | 256000 | 10 | 0.35 | 0.5 | 0.5300 |
| 5 | 4000 | 3 | 0.45 | 0.8 | 0.2290 |
| 5 | 16000 | 5 | 0.45 | 0.6 | 0.3691 |
| 5 | 64000 | 5 | 0.45 | 0.5 | 0.4680 |
| 5 | 256000 | 10 | 0.35 | 0.5 | 0.5309 |
| 7.5 | 4000 | 3 | 0.45 | 0.9 | 0.2165 |
| 7.5 | 16000 | 5 | 0.45 | 0.6 | 0.3627 |
| 7.5 | 64000 | 5 | 0.45 | 0.5 | 0.4627 |
| 7.5 | 256000 | 10 | 0.35 | 0.5 | 0.5319 |
Table 5 brings the optimal parameters for the 12 combinations of cache sizes and window lengths that were examined, along with the achieved hit ratio. The PQ size is relative to the size of the cache, while the size of the probationary segment of the SLRU is given as a fraction of the SLRU size (not of the entire cache size). The results indicate that the optimal window length grows as the cache size grows. For the smaller two caches, the 2.5-minute window outperformed the two larger windows (with the margin of victory shrinking at 16000 pages). The 5-minute window proved best when the cache size was 64000 pages, and the 7.5-minute window achieved the highest hit ratios for the 256000-page cache. With small cache sizes, it is best to consider only the most recent requests. As the cache grows, it pays to consider growing request histories when replacing cached pages.
As for the internal partitioning of the cache, all three window sizes agree that (1) the optimal PQ size shrinks as the cache grows, and (2) the probationary segment of the SLRU should be dominant for small caches, but both SLRU segments should be roughly of equal size in large caches.
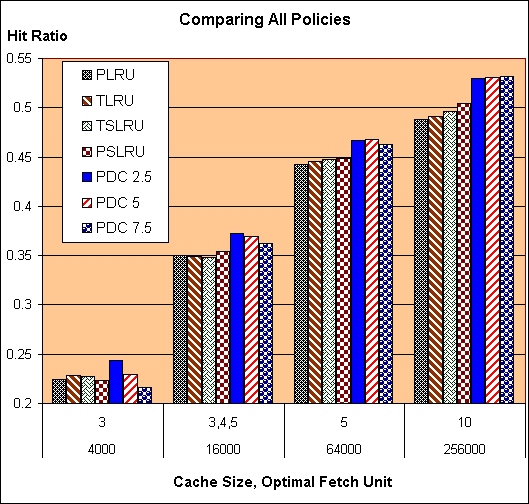
Figure 7 shows the optimal hit ratios achieved by 7 cache replacement policies: PLRU, TLRU, PSLRU, TSLRU and PDC schemes with windows of 2.5, 5 and 7.5 minutes. Results for cache sizes of 4000, 16000, 64000 and 256000 result pages are shown. For each cache size and policy, the displayed hit ratios are the highest that were achieved in our experiments (with the optimal choice of the fetch unit and the partitioning of the cache). The optimal fetch unit was consistent almost throughout the results - for cache sizes of 4000, 64000 and 256000 pages, the optimal fetch units were 3,5 and 10 respectively, in all schemes. For caches of 16000 pages, the optimal fetch unit varied between 3 and 5, depending on the scheme.
As Figure 7 shows, the best hit ratios for all cache sizes were achieved using PDC. In fact, the 2.5 and 5 minute PDCs outperformed the four LRU and SLRU based schemes for all cache sizes, with the 7.5-minute PDC joining them in the lead for all but the smallest cache. Furthermore, in all but the smallest cache size, the hit ratios are easily clustered into the high values achieved using PDC, and the lower (and almost equal) values achieved with the other four schemes. For large cache sizes, The comparison of PDC and TLRU (which is better than PLRU at large sizes) reveals that PDC is competitive with a twice-larger TLRU: the optimal 64000-page PDC achieves a hit ratio of 0.468 while the 128000-page TLRU has a hit ratio of 0.469, and all three 256000-page PDC schemes outperform the 512000-page TLRU (0.53 to 0.51). Recall, however, that the improved hit ratios with PDC come at the cost of more computationally expensive caching operations, as discussed in Section 3.2.
The hit ratios of all three 256000-page PDC schemes were above 0.53, and were achieved using a fetch unit of 10. Recall that Table 2 brought upper bounds on the hit ratio that is achievable on the query log examined. These bounds correspond to infinite caches with prior knowledge of the entire query stream. For a fetch unit of 10, the upper bound was 0.62, and the bound for any fetch unit was 0.629. Thus, PDC achieves hit ratios that are beyond 0.84 of the theoretic upper bound.
When limiting the discussion to the LRU and SLRU based schemes, Page SLRU is the best scheme for all but the smallest cache size. This is consistent with the results of Markatos [11], where PSLRU outperformed PLRU (with the fetch unit fixed at 1).
We have examined five replacement policies for cached search result pages. Four of the policies are based on the well-known LRU and SLRU schemes, while the fifth is a new approach called PDC, which assigns priorities to its cached result pages based on a probabilistic model of search engine users. Trace-driven simulations have shown that PDC is superior to the other tested caching schemes. For large cache sizes, PDC outperforms LRU-based caches that are twice as large. It achieves hit ratios of 0.53 on a query log whose theoretic hit ratio is bounded by 0.629.
We also studied the effect of other parameters, such as the fetch unit and the relative sizes of the various cache segments, on the hit ratios. The fetch unit proved to be the dominant factor in optimizing the caches' performance. Optimizing the fetch unit can double the hit ratios of small caches, and can increase these ratios in large caches by 50%. With optimal fetch units, small caches outperform much larger caches whose fetch unit is not optimal. In particular, a size-s cache with an optimal fetch unit will outperform caches of size 4s whose fetch unit is 1. The impact of the fetch unit on the hit ratio is much greater than the impact achieved by tuning the internal partitioning of the cache. Furthermore, the optimal fetch unit depends only on the total size of the cache, and not on the internal organization of the various segments.
An important benefit that a search engine enjoys when increasing the hit ratio of its query result cache, is the reduction in the number of query executions it must perform. However, while large fetch units may increase the hit ratio of the cache, the complexity of each query execution grows as the fetch unit grows [10]. Although the increase in the complexity of query executions may be relatively small in many search engine architectures, it should be noted that the hit ratio is not the sole metric by which the fetch unit should be tuned.
An important and intuitive trend seen throughout our experiments is that large caches can take into account longer request histories, and prepare in advance for the long term future. Planning for the future is exemplified by the increase of the optimal fetch unit as the cache size grows. In all schemes, the optimal fetch unit grew from 3 to 10 as the cache size increased from 4000 to 256000 pages. Since the fetch unit essentially reflects the amount of prefetching that is performed, our results indicate that large caches merit increased prefetching. As for considering longer request histories, this is exemplified by the PDC approach, where the optimal length of the query window increased as the cache size grew.
The schemes employing some form of SLRU (PSLRU, TSLRU and PDC) also exhibit an increased ``sense of history'' and ``future awareness'' as their caches grow. In these schemes, the relative size of the protected segment increased with the cache size. A large protected segment is, in a sense, a manner of planning for the future since it holds and protects many entries against early removal. Additionally, only long request histories contain enough repeating requests to fill large protected segments.
The following directions are left for future research:
We thank Farzin Maghoul and Prashanth Bhat from AltaVista, and Andrei Broder, formerly of AltaVista and currently with IBM Research, for helpful discussions and insights on query result caches, and for providing us with the query log for our experiments.
[1] The nature of markets in the world wide web. Quarterly Journal of Economic Commerce, 1:5-12, 2000.
[2] The anatomy of a large-scale hypertextual web search engine. Proc. 7th International WWW Conference, 1998.
[3] Graph structure in the web. Proc. 9th International WWW Conference, 2000.
[4] Active cache: Caching dynamic contents on the web. In Proc. of the IFIP International Conference on Distributed Systems Platforms and Open Distributed Processing (Middleware '98), pages 373-388, 1998.
[5] Introduction to Algorithms. MIT Press and McGraw-Hill, 1990.
[6] Real life, real users, and real needs: A study and analysis of user queries on the web. Information Processing and Management, 36(2):207-227, 2000.
[7] Interaction of query evaluation and buffer management for information retrieval. In SIGMOD 1998, Proceedings ACM SIGMOD International Conference on Management of Data, Seattle, Washington, USA, pages 118-129, June 1998.
[8] Caching strategies to improve disk system performance. Computer, 27(3):38-46, 1994.
[9] Integrated document caching and prefetching in storage hierarchies based on markov-chain predictions. VLDB, 7(3):141-162, 1998.
[10] Optimizing result prefetching in web search engines with segmented indices. In Proc. 28th International Conference on Very Large Data Bases, Hong Kong, China, 2002.
[11] On caching search engine query results. Proceedings of the 5th International Web Caching and Content Delivery Workshop, May 2000.
[12] A brief history of generative models for power law and lognormal distributions. Invited Talk in the 39th Annual Allerton Conference on Communication, Control and Computing, October 2001.
[13] Rank-preserving two-level caching for scalable search engines. In Proc. 24rd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, New Orleans, Louisiana, USA, pages 51-58, 2001.
[14] Analysis of a very large altavista query log. Technical Report 1998-014, Compaq Systems Research Center, October 1998.
[15] Proxy cache replacement algorithms: A histroy-based approach. World Wide Web, 4(4):277-297, 2001.
[16] Prediction of web page accesses by proxy server log. World Wide Web, 5(1):67-88, 2002.
[17] Integrating web prefetching and caching using prediction models. World Wide Web, 4(4):299-321, 2001.
This document was partially generated using the LaTeX2HTML translator Version 98.1p7 (June 18th, 1998)
Copyright © 1993, 1994, 1995, 1996,
Nikos Drakos,
Computer Based Learning Unit, University of Leeds.
Copyright © 1997, 1998,
Ross Moore,
Mathematics Department, Macquarie University, Sydney.