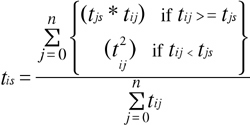
The so-called "Web of Trust" is one of the ultimate goals of the Semantic Web. Research on the topic of trust in this domain has focused largely on digital signatures, certificates, and authentication. In this paper, we describe an approach for building a web of trust in a more social respect. This paper describes the applicability of social network analysis to the semantic web, particularly discussing the multi-dimensional networks that evolve from ontological trust specifications. As a demonstration of algorithms used to infer trust relationships, we present TrustBot and TrustMail, two applications that allow users to take advantage of these metrics.
Social Networks, Trust, Semantic Web, Small Worlds
"Trust" is a word that has come to have several very specific definitions on the Semantic Web. Much research has focused on authentication of resources, including work on digital signatures and public keys. Confidence in the source or author of a document is important, but trust has many aspects beyond this that are ignored by authentication.
Just because a person can confirm the source of documents does not have any implication about trusting the content of those documents. This project addresses "trust" as credibility or reliability in a much more human sense. It opens up the door for questions like "how much credence should I give to what this person says about a given topic," and "based on what my friends say, how much should I trust this new person?" In this paper, we will discuss the of a social networks on the semantic web, and their implementation in applications.
While the graph of the entire Semantic Web itself is interesting, much smaller sub-graphs generated by restricting the properties, and thus edges, to a subset of interest allows us to see the relationships among distributed data. Applications in this space are vast. Semantic markup means that it is easy to retrieve instances of specific classes and their properties for a particular project. Furthermore, merging data collected from many different places on the web is trivial when the same ontology is used.
On the semantic web, information about individuals is maintained in distributed sources. Individuals can manage data about themselves and their friends. While security measures, like digital signatures of files, build trust about the authenticity or data contained within the network, they do not describe trust between people in the network. This latter element lies at the core of trust networks.
There are many ways to construct a social network. Binary relationships are most common in the social network analysis literature: either two people know each other or they don't. By treating a "Person" as a node, and the "knows" relationship as an edge, an undirected graph emerges. Techniques developed to study naturally occurring social networks apply just as well to those on the semantic web. When dealing with trust networks, several issues beyond those of basic social networks need attention. First, edges in a trust network are directed. A may trust B, but B may not trust A back. Edges are also weighted with some measure of the trust between two people. By building such a network, it is possible to make an estimate of how much A should trust an unknown individual to whom there is a path in the network. Essentially, we are using information in the graph to infer the weight of a non-existent edge. This paper describes one metric for making such inferences in the context of two implementations.
The semantic web of trust requires that users describe their beliefs about others. Once a person has a file that lists who they know and how much they trust them, social information can be automatically compiled and processed.
The FOAF schema [3] is an RDF vocabulary that a web user can use to describe information about himself, such as name, email address, etc, as well as information about people he knows. People are identified in FOAF by their email addresses, since they are unique for each person.
Large networks form when users link from their FOAF file to others. The connections and expansion is primarily achieved when one person references another person's FOAF URI. These links allow a few seeds to produce a large graph by spidering along those links to new descriptions.
This project introduces a schema designed to extend foaf:Person, allowing users to indicate a level of trust for people they know (see http://www.mindswap.org/~golbeck/). Our trust schema specifies trust on a scale of 1-9, where 1 is absolute distrust, 5 is neutral, and 9 is absolute trust. Trust ratings can be given in general, or limited to a specific topic. That means that users can specify several different trust levels for a person on several different subject areas. The emergent graph can then be used for generating trust recommendations.
Direct edges between individual nodes in this graph obviously represent trust. Beyond knowing that a given user explicitly trusts another, the graph can be used to infer the trust that one user should have for individuals to whom they are not directly connected.
This research computes five pieces of information about the trust links between a source and sink: minimum and maximum path length, minimum and maximum capacity paths, and a weighted average of trust ratings. Path length is just a measure of the number of edges between the source and the sink. Minimum and maximum capacity paths are determined by making a network flow calculation for each individual path between the source and sink. The weighted average is designed to give a calculated recommendation on how much the source should trust the sink.
For any node that has a direct edge to the sink, we ignore paths and use the weight of that edge as the trust rating. For any node that is not directly connected to the sink, the trust rating is determined by a weighted average of the values for each of its neighbors. This function recourses for each neighbor until it grounds out in direct connections. More formally, the calculated trust t from node i to node s is given by the following function:
where i has n neighbors with paths to s. In calculating the average, this formula also ensures that we do not trust someone down the line more than we trust any intermediary.
TrustBot is an IRC bot that has implemented algorithms to make trust recommendations to users based on the trust network. Using the IRC interface, users can query TrustBot for a variety of information about two individuals in the network., including maximum and minimum length paths, weighted averages, and the maximum and minimum capacity paths.
Using the network built up by the community, TrustBot calculates ratings on demand. Users can retrieve values with explanations of the graph properties used in the calculations to find out information about new people. TrustBot also serves as a "Trust Server" in the next application.
TrustMail is an email client based on Mozilla Messenger that provides an inline trust rating for each email message. Since our graph uses email address as a unique identifier, it is a natural application to use the trust graph to rank email. As with TrustBot, users can configure TrustMail to show trust levels for the mail sender either on a general level or with respect to a certain topic. Since the trust rating is displayed in the folder views, users can sort their message according to trust rating.
Though the mail program may have some utility as a spam filter, its much greater benefit comes from the fact that it can provide information about mail we actually want to read. For example, a graduate student may email a professor at a distant university. If a colleague of the professor has corresponded with this student and sees insightful comments, he may give the student a high trust rating. This, in turn, will notify colleagues that the student is someone worth talking to. Alternatively, people who often send irrelevant email may be given low ratings, advising others to push that message further down on their attention lists.
The examples given above are a nice extension to FOAF and useful in several domains. More importantly, however, these examples illustrate how social networks can be used to build a web of trust. Once we understand these techniques of network analysis, much information on the semantic web can be analyzed with respect to its trust implications and used in interesting applications.
For applications such as TrustMail to come to full realization, developing appropriate algorithms and trust metrics is a top priority. This paper presented a simple weighted average for calculating trust, this ignoring many features. More complex metrics will be necessary, with an eye to their actual use by people in applications. This research, which will co-evolve with the development of trust applications, is a prime space for future work in this area.