Current search engines generally employ link analysis techniques to web-page re-ranking. However, the same techniques are problematic in small webs, such as websites or intranet webs, because the link structure is different from the global Web. We propose a re-ranking mechanism based on implicit links generated from user access patterns. Experimental results indicate that our method outperforms keyword-based method, explicit link-based PageRank and DirectHit.
Small web search, user access pattern, link analysis, PageRank.
Web users usually search within a website to obtain more specific and up-to-date information. Intranet search is another increasing application area which enables search within enterprise. In both cases, search occurs in a closed sub-space of the Web, which is called small web search in this paper. However, the performances of existing small web search engines are problematic. As reported in Forrester survey [6], current site-specific search engines fail to deliver all the relevant content, instead returning too much irrelevant content to meet the user's information needs. Furthermore, in the TREC-8 Small Web Task, little benefit is obtained from the use of link-based methods [1].
The reason of failure lies in several aspects. First, it is generally accepted that ranking by keyword-based similarity faces difficulties such as shortness and ambiguity of queries. Second, link analysis technologies could not be directly applied because the link structure of a small web is different from the global Web. We will explain this difference in detail in Section 2. Third, users' access log could be utilized to improve search performance. However, so far few efforts in this direction were made except DirectHit [2].
We propose to generate implicit link structure based on user access pattern mining from Web logs. The link analysis algorithms then use the implicit links instead of the original explicit links to improve the search performance. Experimental results reveal that implicit links contain more recommendation links than explicit links, and thus can improve search result.
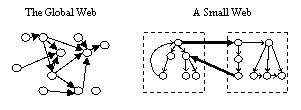
Link analysis algorithms such as PageRank [5] and HITS [4] identify authoritative Web pages based on hyperlink structures. However, there is a basic assumption underlying those link analysis algorithms: the whole Web is a citation graph (see the left plot in Figure 1), i.e. each hyperlink represents a citation or recommendation relationship. On the global Web, the recommendation assumption is generally true because hyperlinks encode a considerable amount of authors' judgment. However, this assumption is commonly invalid in the case of a small web. As depicted in the right part of Figure 1, the majority of hyperlinks in a small web are more "regular" than that in the global Web. Most links are from a parent node to children nodes, between sibling nodes or from leaves to the root (e.g. "Back to Home"). The reason is primarily because hyperlinks in a small web are created by a small number of authors; and the purpose of the hyperlinks is usually to organize the content into a hierarchical or linear structure. Thus the existing link analysis algorithms are not suitable.
In a small web, hyperlinks could be divided into navigational links and recommendation links. The latter is useful for link analysis. However, only filtering out navigational links from all hyperlinks is insufficient for our purpose because the remaining recommendation links are incomplete. In other words, there are many implicit recommendation links (hereafter called "implicit links" for short) in a small Web, which will be discovered by our proposed user access pattern mining.
Generally the global Web is modeled as a directed graph G = (V, E) where the set V of vertices consists of all the pages wi(1£i£n), and the set E represents the explicit hyperlinks between pages. Instead, we propose to model a small web as a new implicit link graph, i.e. a weighted directed graph G'= (V, E'), where the set V is same as above and the set E' represents the implicit links between pages. Moreover, each link (wi®wj)ÎE' is associated with a probability P(wj|wi), which represents the conditional probability of the next page wj to be visited given current page wi.
To extract implicit recommendation links among web-pages, we seek to find patterns that reflect such kind of recommendation relationship. In particular, we seek to find two-item sequential pattern, which is an ordered pair of (A®B) with s%, indicating that in a browsing session, if a user visits page A, he will visit page B after a few steps with probability s%.
All implicit recommendation links could be discovered by two-item sequential pattern mining, because each implicit link embodies many users' intention from the source page to the destination page and many users will traverse from the source page through different paths but finally arrive at the destination. However, because users' traversal paths are composed of explicit links, user access patterns are subject to explicit link structures, and access patterns might include unnecessary navigational links. We demonstrate that when the following assumptions are true, the navigational links can be filtered out..
The Web log can be first preprocessed and segmented into browsing sessions S=(s1, s2, , sm), where si=(ui: pi1, pi2, , pik), ui is the user id and pij are web-pages in the browsing path ordered by timestamp. Given this dataset, we use a gliding window with window size t to move over the path within a session to generate the ordered pairs. All possible ordered pairs with their frequency are calculated from all the browsing sessions, and infrequent occurrences are filtered by a user-specified minimum support min-supp.
After two-item sequential patterns are generated, they are used to update the implicit link graph G' = (V, E') described in Section 2. For each two-item sequential pattern (i®j), we add its support supp(i®j) to the weight of the edge (i, j)ÎE. The graph can be further converted to a n´n adjacency matrix A, where the entries A[i, j] is edge (i, j)ÎE. Each row of the matrix A is normalized. Then we apply an algorithm similar to PageRank [5] on the obtained implicit graph to rerank the returned web-pages.
The adjacency matrix is used to compute the rank score of each page. In an "ideal" form, the rank score xi of page i is evaluated by a function on the rank scores of all the pages that point to page i:
![]() (1)
(1)
This recursive definition gives each page a fraction of the rank of each page pointing to itinversely weighted by the strength of the links of that page. To avoid zero values of the matrix eigenvectors, the basic model is modified to obtain an "actual model" using random walk. Specifically, upon browsing a web-page, with the probability 1-e, the user randomly chooses one of the links on the current page and jumps to the page it links to; and with the probability e, the user "reset" by jumping to a web-page picked uniformly from the collection. Therefore the ranking formula is modified to the following form:
![]() (2)
(2)
In our experiment, we set e to 0.15. Furthermore, instead of computing an eigenvector, the simplest iterative method--Jacobi iteration is used to resolve the equation.
The re-ranking mechanism is based on the order based re-ranking, i.e. a linear combination of pages' positions in two lists in which one list is sorted by content similarity scores and the other list is sorted by PageRank values.
![]() (3)
(3)
where O1 and O2 are positions of page P in content similarity score list and PageRank list, respectively.
We took 4-months server log from the website at http://www.cs.berkeley.edu/logs/ for our experiment. After preprocessing, the log contains about 300,000 transactions, 170,000 pages and 60,000 users. The original web-pages and link structure is downloaded from the website. About 170,000 pages are downloaded and indexed by the well-known Okapi system [7]. For each page, an HTML parser is used to remove tags and extract links in pages. There are 216,748 hyperlinks in total. The mining process is conducted with window size t=4 and minimum support min_supp=7. We obtain about 336,812 implicit links finally.
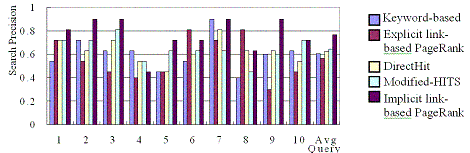
Several volunteers were asked to evaluate precision of search results for the selected 10 queries (which are Jordan, Vision, Artificial Intelligence, Bayesian Network, wireless Network, Security, Reinforcement, HCI, Data Mining, and CS188). The final relevance judgment for each document is decided by majority votes, as the result in Figure 2. The average precision outperforms the keyword-based 16%, PageRank 20%, DirectHit 14% and modified-HITS [3] 12%.
In this paper, we proposed a new re-ranking mechanism based on the users' browsing behaviors in a small web. The future works include the combination of implicit links and explicit links to achieve higher accuracy.