Focused Co-citation: Improving the Retrieval of
Related Pages on the Web
Gabriela Moise
University of Alberta
gabi@cs.ualberta.ca
Jörg Sander
University of Alberta
joerg@cs.ualberta.ca
Davood Rafiei
University of Alberta
drafiei@cs.ualberta.ca
ABSTRACT
We
study the problem of effectively finding related pages, where given the URL of
a page, we want to find other pages that are related or similar to the given
page in some context. We propose three new notions of focus of a collection of
links: link-based, content-based and hybrid. The goal is that in order to
produce better results when looking for related pages an algorithm has to give
more focused collections of links a higher influence on the final ranking than
less focused collections. We embed these notions into a "focused"
version of the Co-citation algorithm and show in an experimental evaluation
that these focused versions of Co-citation significantly outperform the
unfocused version with respect to the precision of the retrieved results.
Keywords
Co-citation, Related Pages, Focus of Web Pages.
1. INTRODUCTION
We have analyzed Co-citation ([1]) and identified a number of problems that
frequently arise on the Web and affect the precision of algorithms that use the
link structure of the Web to find related pages: 1) Navigational links 2)
Near-duplicate pages 3) “unfocused” pages, which are, intuitively speaking,
pages that contain a non-related collection of links.
Some proposals to deal with these problems have been described in the
literature. Techniques to eliminate navigational links and near-duplicate pages
have been discussed in [1] and [4]. To
deal with unfocused pages, the notion of a “pagelet” has been introduced in
[3]. The notion of pagelet is topic-independent, and our experimental
evaluation, shows that only slight improvements in the results are obtained
when using these methods.
Our content-based
notion of focus is similar to the notion proposed in [2], which was
successfully applied for finding the reputation of Web pages.
2. Focused Co-citation
Intuitively, the focus of a collection of links
should capture the degree of agreement, in terms of a topic, between the
corresponding pages pointed to by the links in the collection.
The first method that we propose for computing the
focus, LinkFocus, takes into account only the link information that we
already collected for the Co-citation algorithm, and is therefore
computationally inexpensive. According to co-citation, the more in-links two
pages have in common, the more likely they are on the same topic. Given a
collection of links and the corresponding pages, the more in-links of these
pages exist that agree on more of these pages, the more focused the collection
is. Given a page A, any other page B that shares i links with A
should contribute to the focus of A proportionally to the number of
shared links and to the total number of links that A and B have
individually. We formalize this intuition in the following definition of the
focus of a page A:
![]()
where | . | denotes the number of elements of a
set.
Our experiments show that the LinkFocus does not
always capture the intuitive notion of a focus of a collection of links, e.g.,
if the same collection of links appears on several sites, and the links are not
necessarily related. This is why we propose another notion of focus that is
based on content information, ContentFocus.
We will consider that a topic is given by a
set of keywords k1, ..kt. The topic of a
given URL is obtained by extracting keywords from its title and the anchor text
of all the incoming links (anchor text of a link has been successfully used as
an indication of the topic of the page pointed to by the link e.g., [7]). Stop
words and infrequent terms are removed, and a light stemming is applied.
For each link in a given collection, we gather
textual content by taking its anchor text and from the page that the link
points to, we take the title (actually, we investigated three more alternatives
to collect increasingly more textual content, i.e., meta description, headings
and the full content, but for space limitations we do not discuss the results
here.).
Let N be the total number of links in a
collection of links, and assume that keyword ki appears in
the text gathered for Nki links. We define the focus of the
keyword ki with respect to this collection as:
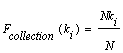
We define the focus of a
collection of links with respect to the topic given by a set of keywords {k1,
..kt} as:
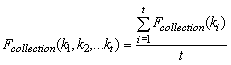
We call this type of
focus ContentFocus. We extract a set of keywords, k1, ..kt,
representing the topic of a query URL, as explained above, and then we compute
the focus of each parent page
with respect to k1, ..kt.
We also explored a
hybrid method, the HybridFocus, that combines LinkFocus and ContentFocus,
in order to see if the results of the single methods can be improved. We define the hybrid focus for a page A
as following:
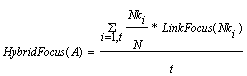
where LinkFocus(Nki)
is the LinkFocus computed for page A considering page A
composed only of the links Nki.
We propose a weighting
scheme that will adjust the co-citation rank of a sibling s of the query
URL according to the relative focus of the common parents between s and the
query URL; the more focused parents a sibling has in common with the query URL,
the higher the sibling’s rank:
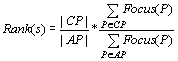
3. Experimental Evaluation
We compare the performance of four algorithms: Co-citation,
LinkFocus, ContentFocus and HybridFocus. Elimination of
navigational links and near-duplicate pages, and extraction of pagelets are
performed as preprocessing steps in all algorithms.
To measure the effectiveness of our algorithms we
want to assess the percentage of “relevant” URLs returned by each algorithm.
The notion of “relatedness” is
subjective and difficult to measure. To make the results more objective, we use
the Open Directory [6] as a form of “ground truth” for relatedness. Open
Directory has been used in previous work as a "ground truth" for
evaluation of diverse similarity strategies [5]. Pages categorized under the
same node as the starting URL are considered relevant and receive the score 1;
all other pages receive the score 0. We consider only the first 10 results
returned by each algorithm. To estimate the relative performance of our
algorithms, we use the precision at R for a given algorithm, which is
defined as the total number of answers receiving a score of ‘1’ within the
first R answers divided by R times the number of query URLs [1].
We tested 100 URLs in our experiments. We used
Yahoo! [6] to obtain parents of query URLs (using the link query).
Figure 1 shows the precision at 10 for each of the
four algorithms. The results clearly show that all our focused methods
consistently outperform Co-Citation.
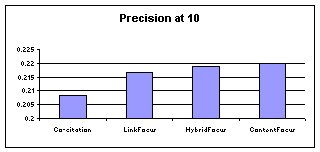
Figure 1. Precision at 10
As an example, given the
query URL www.cs.ubc.ca (the computer science department of the
University of British Columbia), we expect to find as related the homepages of
other computer science departments, preferably in Canada. Co-citation retrieves
only two computer science departments’ homepages at positions 9 and 10, four
homepages of other departments within the UBC domain and the remaining results
are unrelated pages. Our method based on ContentFocus retrieves seven computer
science departments’ homepages and three homepages of other departments within
the UBC domain.
4. Conclusions
We have investigated problems with the original
Co-citation algorithm and argued that these problems are mainly due to the
existence of unfocused pages on the Web. To overcome the identified problems we
formalized a notion of focus in different ways, one link-based, another
content-based, and a hybrid one. All approaches were experimentally evaluated.
The results showed that our focused versions of Co-citation consistently
outperform the plain version.
We have also measured the improvement for ContentFocus
when taking increasingly more content into account. The results did not
improve, the reason being that having more keywords in the definition of a
topic allows more diverse pages to share keywords.
The Open Directory
used as a “ground truth” is incomplete (many related pages found by our
algorithms simply do not appear in the Open Directory). As future research, we
plan to look into alternative ways to evaluate our algorithms such as a
systematic user study. We also plan to investigate the focus notion in other
link-based analysis methods.
5. REFERENCES
1.
Dean, J.,
Henzinger, M. Finding Related Pages in the World Wide Web. In Proc. of the 8th Int. WWW
Conf., 1999.
2. Mendelzon, A.O., Rafiei, D. What do the neighbours think?
Computing Web Page Reputations. IEEE Data Engineering Bulletin, 23(3): 9-16,
September 2000.
3. Bar-Yossef, Z., Rajagopalan, S. Template Detection via
Data Mining and its Application. In Proc. of WWW Conf., 2002.
4. Davison, B. Recognizing Nepotistic Links on the Web.
Artificial Intelligence for Web Search, Technical Report WS-00-01, pp. 23-28,
AAAI Press.
5.
Haveliwala, T., Gionis, A., Klein, D. Indyk, P. Evaluating Strategies for
Similarity Search on the Web. WWW 2002.
6. Open Directory Project (ODP). http://www.dmoz.org/
7. Yahoo! http://www.yahoo.com/.
8. Google http://www.google.com/