A communication-based approach to detect and quantify semantic differences between the knowledge expressed using heterogeneous knowledge representations is described in this poster. The approach intends to allow the computer-based integration of decentraly created knowledge representations on demand, and thus it enables a fully decentralized creation of semantic markup, as for example for the Semantic Web. A communication-based approach to detect and quantify semantic differences between the knowledge expressed using heterogeneous knowledge representations is described in this poster. The approach intends to allow the computer-based integration of decentraly created knowledge representations on demand, and thus it enables a fully decentralized creation of semantic markup, as for example for the Semantic Web.
Semantic Web, Knowledge negotiation
An important success factor for the Web is the fact that it is created in a decentralized way, allowing to leverage individual efforts to support information dissemination. It is a reasonable assumption that the creation of the Semantic Web [2] can only succeed, if it is also created in a fully decentralized way. That means, that knowledge representations need to be created individually at different sites, and is to be used commonly by all sites. However, such individual creation of knowledge representations usually requires continuous mutual agreement on different aspects of the knowledge representation, which is a conceptually centralized process. Without this centralization, heterogenous knowledge representations will emerge.
In our model, the Semantic Web is built as a number of individual entities. Every entity is an artifact, created by a creator. An entity contains a knowledge representation that contains knowledge about its associated resources. The creation of the knowledge representation is part of the creation of the entity. The knowledge representation is instantiated as an internal representation that is not visible to the outside, except for the creator of the entity. The entity creation does not necessarily include the implementation of a novel internal representation. The creation process might consist of taking an existing entity and only specifying the knowledge in an appropriate notation.
Entities communicate by exchanging symbols. A symbol is a syntactic construct that is created according to a set of rules that are known by all entities, e.g. production rules of a grammar. Symbols may be single words or more complex structures, e.g. RDF documents, linearized concept graphs, or DAML description.
Associated with each entity are two functions that allow to map between symbols and the internal representation of the knowledge:
The expression function is determined by the symbols the creator chose for the represented knowledge. The interpretation function is usually parameterized by the knowledge represented in an entity because symbols are usually put in context to the available knowledge during interpretation.
Communication between entities always involves expression of an internal state into a symbol and the interpretation of this symbol into an internal state. The model presented here covers only the communication between entities and is not concerned with reasoning. It is assumed, that reasoning is performed completely in the individual entities. An entity may communicate with other entities to integrate knowledge from these entities into its local reasoning process.
During the creation process a creator decides what knowledge should be represented in the entity and how this knowledge should be represented. This process involves a large number of individual decisions, that fall into the following two categories:
| Selection | The creator selects the knowledge that is to be represented in the entity. The selection is dependent on the creators assessment of relevancy of that knowledge. |
| Implementation | The creator chooses a representation for the selected knowledge. This includes the granularity of the knowledge as well as the embedment of the knowledge into supporting structures. The implementation is dependent on the creators assessment of usage of the concepts. |
The large number of individual decisions makes it likely that different creators will create entities with differing knowledge representations. This will in turn lead to differences in the expression and interpretation function. As a result different entities will: not necessarily map identical symbols on internal representations of identical concepts, and not necessarily map different symbols on internal representations of different concepts. This differences can only be prevented, if every aspect of selection and implementation is defined and agreed upon, which would be a centralized process.
In order to decentralize the creation of knowledge descriptions for the Semantic Web, we are looking for a solution that does not rely on a such a conceptually centralized process. Our basic idea is to leverage the large amount of knowledge that is shared between the creators of semantic markup, i.e. common knowledge.
Individual persons acquire their knowledge in isolation. We can not decide whether our knowledge is identical -or compatible- because there is no introspection. Communication is used to detect and resolve differing interpretations of symbols. Individuals exchange symbols which they usually interpret in a compatible way, because they share a large amount of knowledge. But they may at some point of the communication experience a semantic mismatch and redirect their communication to disambiguate their interpretation of the exchanged symbols. So the disambiguation process consists of two steps:
| Detection | of a semantic mismatch. |
| Resolution | of the discovered semantic mismatch. |
This situation is analogous to the individually created knowledge descriptions in the Semantic Web. Our idea is to enable entities of the Semantic Web to perform a similar communication to automatically resolve semantic mismatches.
In order to resemble the communication between individuals, we
enable entities to verify their interpretation of a symbol. From
what was said above, it is clear, that this verification can not
be based on comparison of symbols alone. Our approach is to let
the entity that uttered a symbol verify its interpretation. In
order to do this, other entities can ask for a verification of
their interpretation. Assume that we have two entities,
entity A and entity B. Entity A wants to use the
knowledge represented in the internal representation of
entity B. Entity B expresses a part of its knowledge as
the symbol ![]() . Entity A interprets the symbol
. Entity A interprets the symbol ![]() which
yields the internal representation
which
yields the internal representation ![]() . In order to verify its
interpretation entity A relates its interpretation to the
knowledge it possesses and asks entity B whether this is the
intended interpretation. To do so, it sends a request like
. In order to verify its
interpretation entity A relates its interpretation to the
knowledge it possesses and asks entity B whether this is the
intended interpretation. To do so, it sends a request like ![]() to entity B. Entity B calculates a
distance value between its own and entity A's interpretation
of the symbol
to entity B. Entity B calculates a
distance value between its own and entity A's interpretation
of the symbol ![]() and returns this distance
value to entity A. Entity A can now use this distance
value as an indicator that shows how confident entity A can
be in its interpretation of the symbol
and returns this distance
value to entity A. Entity A can now use this distance
value as an indicator that shows how confident entity A can
be in its interpretation of the symbol ![]() and in turn, how
confident it can be in conclusions that have been drawn by using
the symbol
and in turn, how
confident it can be in conclusions that have been drawn by using
the symbol ![]() . The communication between
the entities is illustrated in figure 1.
. The communication between
the entities is illustrated in figure 1.
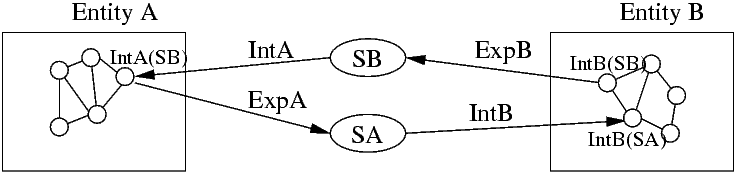 |
We believe that this approach works, if every concept is set in relation to a sufficiently large number of other concepts. Because individuals share the same knowledge, the overall structure of the individually represented knowledge will be almost identical. There may be individual differences in limited parts of the individual knowledge, but the overall picture will be similar. If we relate a concept to a large number of other concepts, we can locate this concept in the space of concepts and this location will be comparable to the location calculated by other entities. Therefore it makes sense to base a distance calculation on the symbols received by a foreign entity.
Disambiguating symbols requires communication, leading to endless recursion. To avoid this the communication between the entities has to be grounded. That is it has to be based on symbols whose interpretation is not questioned further, i.e. that unambiguously identify one concept. Defining these symbols is usually a conceptually centralized process involving the rigorous definition of concepts.
In order to avoid a centralized process we propose to use a large set of not exactly defined, but commonly understood symbols. A possible source for these symbols may be a natural language ontology like WordNet [4] or a semantic network like Lexical FreeNet [1]. Of course there will be individual differences in the interpretation of the symbols. But again, these differences will be limited to individual subsets of the symbols. If we compare individual interpretations of a sufficiently large set of symbols, we will find a large number of compatible interpretations.
The measurement of distances between parts of knowledge representations is a difficult and not yet solved problem. We are currently investigating different approaches. On possibility may be to classify relations and calculate distances between two concepts in a knowledge representation from the relations between them. Approaches for ontology comparison (for example [3]) might also be applicable to this problem.
We presented an approach to resolve heterogeneity in individually created knowledge descriptions through communication. This allows interoperation of individually created knowledge descriptions, without the need for a mutual a priori agreement between the creators of the knowledge descriptions. Instead we rely on existing structures, e.g. natural language ontologies like WordNet, and resolve the differences that are introduced by individual interpretation of these structures through communication. We believe that the use of a large number of reference points in this communication will allow to reliably detect different interpretations.
This approach allows to omit the a priori centralized synchronous n-to-n communication between all creators to agree on an interpretation. Instead there is only an asynchronous 1-to-n communication in our approach, when the creators refer to the basic structure. The synchronous communication to overcome heterogeneity is then automatically performed on-demand between two entities. We are currently looking into the problem of distance measurement as future work.
Part of this work was supported by an ERCIM fellowship grant.