Small languages represent a non-negligible portion of the Web with interest for a large population with less literacy in English. Existing search engine solutions however vary in quality mostly because a few of these languages have a particularly complicated syntax that requires communication between linguistic tools and "classical" Web search techniques. In this paper we present development stage experiments of a search engine for the .hu or other similar national domains. Such an engine differs in several design issues from large-scale engines; as an example we apply efficient crawling and indexing policies that may enable breaking news search.
Web crawling, search engines, database freshness, refresh policies.
While search engines face the challenge of billions of Web pages with content in English or some other major language, small languages such as the Hungarian represent a quantity sizes of magnitude smaller. A few of the small languages have particularly complicated syntax--most notably Hungarian is one of the languages that troubles a search engine designer the most by requiring complex interaction between linguistic tools and ranking methods.
Searching such a small national domain is of commercial interest for a non-negligible population; existing solutions vary in quality. Despite of its importance the design, experiments or benchmark tests about small-range national search engine development only exceptionally appear in the literature.
A national domain such as the .hu covers a moderate size of not much more than ten million HTML pages and concentrates most of the national language documents. The size, concentration and network locality allows an engine to run on an inexpensive architecture while it may by orders of magnitude outperform large-scale engines in keeping the index up to date. In our experiments we use a refresh policy that may fit for the purpose of a news agent. Our architecture will hence necessarily differ from those appearing in published experiments or benchmark tests at several points.
In this paper we present development stage experiments of a search engine for the .hu or other similar domain that may form the base of a regional or a distributed engine. Peculiar to search over small domains is our a refresh policy and the extensive use of clustering methods. We revisit documents in a more sophisticated way than in [13]; the procedure is based on our experiments that show a behavior different from [7] over the Hungarian web. Our method for detecting domain boundaries improves on [8] by using hyperlink graph clustering to aid boundary detection. We give a few examples that show the difficulty of Web information retrieval in agglutinative and multi-language environments; natural language processing in more detail is however not addressed in this work.
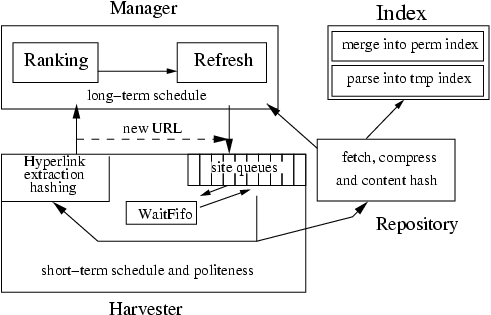
The high-level architecture of a search engine is described in various surveys [2, 4, 13]. Since we only crawl among a few tens of millions of pages, our engine also contains a mixture of a news agent and a focused crawler. Similar to the extended crawl model of [5], we include long-term and short-term crawl managers. The manager determines the long-term schedule refresh policy based on PageRank [2] information. Our harvester (modified Larbin 2.6.2 [1]) provides short-term schedule and also serves as a seeder by identifying new URLs. Eventually all new URLs are visited or banned by site-specific rules. We apply a two-level indexer (BerkeleyDB 3.3.11 [12]) based on [11] that updates a temporary index in frequent batches; temporary index items are merged into permanent index at off-the-peak times and at certain intervals the entire index is recompiled.
Due to space limitations a number of implementation issues is described in the full paper such as the modifications of the crawler, its interface to long-term refresh scheduler as well as indexing architecture and measurements.
Figure 1: Search engine architecture
Hungarian is one of the languages that troubles a search engine designer with lost hits or severe topic drifts when the natural language issues are not properly handled and integrated into all levels of the engine itself. We found single words with over 300 different word form occurrences in Web documents (Figure 2); in theory this number may be as large as ten thousand while compound rules are near as permissive as in German. Word forms of stop words may or may not be stop words themselves. Technical documents are often filled with English words and documents may be bi- or multilingual. Stemming is expensive and thus, unlike in classical IR, we stem in large batches instead of at each word occurrence.
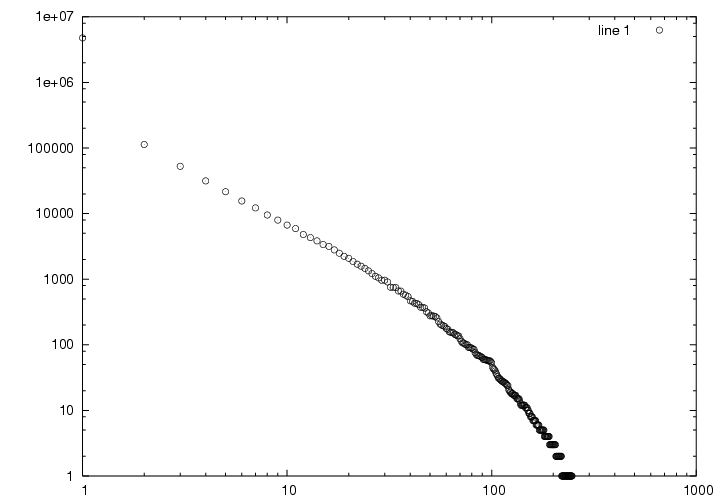
Figure 2: number of word stems with given number of word form occurrences in 5 million Hungarian language documents
Polysemy often confuses search results and makes top hits irrelevant to the query. "Java", the most frequently cited example of a word with several meanings, in Hungarian also means "majority of", "its belongings", "its goods", "its best portion", a type of pork, and may also be incorrectly identified as an agglutination of a frequent abbreviation in mailing lists. Synonyms "dog" and "hound" ("kutya" and "eb") occur nonexchangeably in compounds such as "hound breeders" and "dog shows" while one of them also stands for the abbreviation of European Championship. Or the name of a widely used data mining software "sas" translates back to English as "eagle" that in addition frequently occurs in Hungarian name compounds.
In order to achieve acceptable precision in Web information retrieval for multilingual environments or agglutinative languages with a very large number of word forms we need to consider a large number of mixed linguistic, ranking and IR issues.
A unique possibility in searching a moderate size domain is the extensive and relative inexpensive application of clustering methods. As a key application we determine coherent domains or multi-part documents. As noticed by Davison [8], hyperlink analysis yields accurate quality measures only if applied to a higher level link structure of inter-domain links. The URL text analysis method [8] however often fails for the .hu domain, resulting in unfair PageRank values for a large number of sites without using our clustering method.
Our refresh policy is based on the observed refresh time of the page and its PageRank [2]. We extend the argument of Cho et al. [6] by weighting freshness measures by functions of the PageRank pr: given the refresh time refr, we are looking for sync, the synchronization time function over pages that maximize PageRank times expected freshness. The optimum solution of the system can be obtained by solving
pr * (refr - (sync + refr) exp (-sync / refr)) = u
We propose another fine tuning for efficiently crawling breaking news. Documents that need not be revisited every day may be safely scheduled for off-peak hours, thus during daytime we concentrate on news sites, sites with high PageRank and quick changes. At off-peak hours however, frequent visits to news portals are of little use and priorities may be modified accordingly.
We estimate not much more than ten million "interesting" pages of the .hu domain residing at an approximate 300,000 Web sites. In the current experiment we crawled five million; in order to obtain a larger collection of valuable documents we need refined site-specific control over in-site depth and following links that pass arguments.
Among 4.7 million files of size over 30 bytes, depending on its settings the language guesser finds Hungarian language 70-90% while English 27-34% of the time (pages may be multilingual or different incorrect guesses may be made at different settings). Outside the .hu we found an additional 280,000 pages, mostly in Hungarian, by simple stop word heuristics; more refined language guessing turned out too expensive for this task.
We conducted a preliminary measurement for the lifetime of HTML documents. Unlike suggested by [7], our results in Figure 3 do not confirm a relation of refresh rates and the PageRank of any kind. Hence we use the computed optimal schedule based on observed refresh rate and the PageRank; in this schedule documents of a given rank are reloaded more frequently as their lifetime decreases until a certain point where freshness updates are quickly given up.
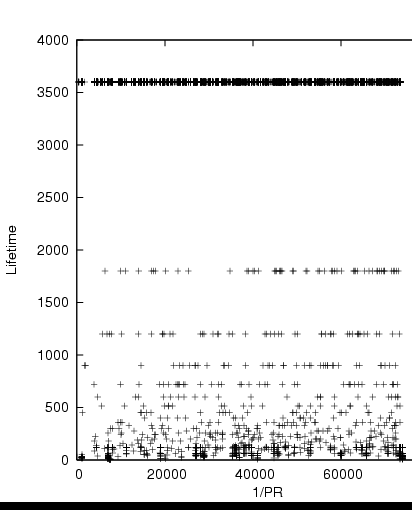
Figure 3: Scatterplot of PageRank and average lifetime (in minutes) of 3 million pages of the .hu domain. In order to amplify low rank pages we show 1/Pagerank on the horizontal axis.
We found that pre-parsed document text as in [10] provides good indication of a content update. Portals and news sites should in fact be revisited by more sophisticated rules: for example only a few index.html's need to be recrawled and links must be followed in order to keep the entire database fresh. Methods for indexing only content and not the automatically generated navigational and advertisement blocks are given in [9].
To MorphoLogic Inc. for providing us with their language guesser (LangWitch) and their Hungarian stemming module (HelyesLem).
Research was supported from NKFP-2/0017/2002 project Data Riddle and various ETIK, OTKA and AKP grants.