![]() , (1)
, (1)
Dimensions of Web Genre
Maya Dimitrova
Institute of Control and System Research, Bulgarian Academy of Sciences
Acad. G. Bonchev Str., Bl. 2, POBox 79, 1113 Sofia, Bulgaria
Nicholas Kushmerick
Smart Media Institute, University College Dublin
Belfield, Dublin 4, Ireland
ABSTRACT
Users assess the “appropriateness” of Web documents in many ways. Traditionally, appropriateness has been solely a matter of relevance to a particular topic. But users are concerned with other aspects of document “genre”, such as the level of expertise assumed by the author, or the amount of detail. In previous work, we have used machine learning to automatically classify documents along a variety of genre dimensions, and we have developed a graphical interface that depicts documents visually along orthogonal genre dimensions. In order to validate the design of our interface, we describe two experiments that measure whether users perceive genre dimensions independently.
Keywords
Web genre, graphical interface, visualisation, web-based survey
1. INTRODUCTION
Many factors influence the “appropriateness” of web documents, for example, topic relevance, but also degree of expertise, level of details, whether a product review is positive or negative, etc. [1, 4]. We call these dimensions “genre”. Traditional search/retrieval focuses on the “relevance” dimension. Novel graphical search interfaces like [12] also emphasize relevance. We have set up two research goals: can we automatically assess document’s position on other dimensions? And how can we display this information to help users find appropriate document?
Some ideas about the first goal have been investigated. For example, the “subjectivity” dimension (i.e. opinion vs. fact) is well captured by a part-of-speech classifier and has shown good domain transfer [1]. Other ideas are the dimensions of level of expertise, and the level of detail of the requested document. These are just preliminary approaches: genre classification per se is not the main focus of this paper. The implemented classifier deals with a few text features whose relative contribution to genre will be further explored. Instead, we focus on the second goal: our proposal is to visually display genre characteristics in multiple dimensions [4, 5]. For example, in two dimensions (expertise, detail) the interface would look like in Figure 1.
Our main focus is whether such a graphical interface is meaningful to the users. To answer this question, we have empirically investigated whether these two dimensions are indeed perceived independently of each other. This is done in two ways: an informal “brainstorming session”, and a web-based survey where users rate documents for level of expertise and technical detail.
2. Experimental Design
Brainstorming Session.
Five participants from a cognitive science course were asked to generate first-come-to-mind associations with documents drawn from four categories – brief-technical, extended-technical, brief-popular, extended-popular, which were subsequently analyzed.Web-based Survey. In the web-based survey 20 users participated – students, staff and volunteers from the web. They were asked to rate on a 5-point scale 7 documents presented on 8 successive pages, which were randomly generated from the experimental corpus. The instruction to rate either the amount of detail or the expertise level of the document was randomly generated, too. The rating method we use is common in personalisation studies and is comparable to other techniques such as making choice on a continuous scale, etc. [e.g. 10]. The survey interface is at http://www.smi.ucd.ie/misty/IR.html.
Genre Classification. The classifier is based on two simple formulae, which include the proportion of high-to-low frequency long English words gathered from the “Brown corpus” (Kucera & Francis, 1968), indices of “technical elements” (HTML tags like <SUB>, <SUP>, etc.) and the ratio of long words to the encountered by the classifier tokens. The experimental corpus consists of 430 words equal to or longer than 9 characters of natural language frequency higher than 49 per million [3]. The X dimension is computed as:
![]() , (1)
, (1)
where P(D) is the detail dimension, P(L) is an index of document length, P(W) is the ratio of long words to HTML tokens, and P(G) is an index of the presence of images. The Y dimension is computed as:
![]() , (2)
, (2)
where P(E) is the expert dimension, P(F) is an index of high-to-low word frequency ratio, and P(T) is an index of technical HTML elements.
3. The Interface
The first 20 URLs returned by one of the big search engines on 18.02.2002 in response to 4 queries (“Pearson Correlation”, “Implicit Memory”, “Java Servlets” and “Neural Networks”) are plotted according to the model along the two dimensions – expert level and amount of detail (Figure 1). The users can view the documents by clicking on the light boxes. The arrowed boxes in Figure 1 give examples of detailed/popular vs. detailed/expert documents visualized by the classifier. The interface to the classifier is at
http://www.smi.ucd.ie/misty/IR50 and the online version is at http://www.smi.ucd.ie/misty/IROnline.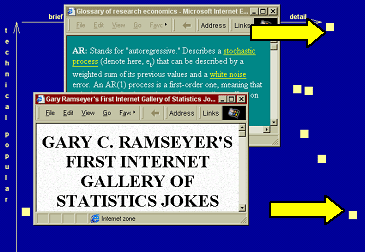
Figure 1. Visualization of the search results
4. Results and Discussion
Brainstorming Session.
The participants gave 16 descriptive items for the brief/technical, 23 for the brief/popular, 35 for the extended/technical and 26 for the extended/popular documents. Only two words – “abridged” and “summary”- are repeated for the brief documents, all the rest differ, which suggests independence in user assessment of web documents.Web-based survey. The results of the study reveal independence of the proposed dimensions – near-zero correlation between the detail and expert dimensions. The detail dimension is better fitted with the user ratings than the expert dimension. The relative contribution of the classifier for diagnosis of expertise along with other approaches for genre classification [e.g. 2, 9] is a subject for next study. At present, either component – word frequency ratio and index of technical detail - contribute equivalently to the overall classification (r = 0.46, r = 0.64, respectively), neither is closer to user ratings than the other (in total r = 0.20). A trained neural network slightly increased the match of theory to user ratings (r = 0.24) [11]. We have focused mainly on the independence assumption, user satisfaction with the classifier will be explored next.
5. Related Work
Expert level and amount of detail have not been fully automatically dealt with to our knowledge yet. For example the new graphical metasearch engine KartOO visualizes mainly the link structure than the style of the documents [12]. It displays the same search examples as in Figure 1 in completely unrelated places. Various aspects of web sites have been visualised, such as the web as hyperbolic space [8], the visitors to web sites as “crowds” [7], the cluster structure of contents of comparable sites [6] etc. We add to web visualisation document style, complementing the content.
6. Conclusion
The paper presents some results of an empirical study to identify independent dimensions of user perception of web genre – expert level and amount of detail. Independence of genre dimensions is essential for design of search visualization tools. The utility of the present study is also for design of personalised search tools for users of different style and expert level.
7. ACKNOWLEDGEMENTS
This research was supported by grants SFI/01/F.1/C015 from Science Foundation Ireland, and N00014-00-1-0021 from the US Office of Naval Research.
8. REFERENCES