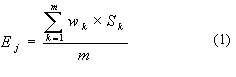
This paper proposes a document logistics approach for cooperative research based on the web and Knowledge Grid. The approach realizes effective research document collection, organization and provision as well as knowledge sharing by incorporating the following functions: construction of semantic profiles representing interests, continuous discovery and collection of potentially relevant documents, synthesis of feedback evaluations, and support of flexible management operations and document recommendation services. The prototype has been implemented and is available for use online.
Feedback synthesis, Knowledge Grid, Logistics, Profile, Web application.
The rapid expansion of research documents available on the Web has led to researchers constantly fighting information overload in their pursuit of knowledge. Though the Scientific Literature Digital Library [3] and other citation indices of scientific literature (such as NCSTRL, LTRS, etc.) have alleviated the information overload to some extent, researchers have to still expend a great deal of time and effort looking for new documents that may interest them.
Information logistics is an innovative technology that aims
to efficiently collect, organize and provide personalized heterogeneous
information on demand. Document logistics is a special case of information
logistics, which aims at enhancing the cooperation and efficiency of research
groups by effectively organizing and managing the research documents. Knowledge
Grid is a platform that enables sharing and managing the distributed
heterogeneous resources spread across the Internet in a uniform way [5,6,7].
Based on the web information retrieval and the Knowledge Grid, this paper proposes a document logistics approach serving research groups across the Internet.
Taken the terms specified by the researchers as core concepts, more related concepts can be discovered by mining and inferring concept associations in a collection of documents. The automatic profile construction process is as follows:
l
Concept
Extraction. Concepts
usually refer to the nouns or noun phrases that characterize a document, so we
mainly extract concepts from the specified sections of a
document by eliminating
the noises or useless words.
l
Co-occurrence
Analysis. The
co-occurrence analysis is performed by adopting the concept
space approach with some revisions
[2], e.g., terms occur in different location are
assigned different weight.
l
Authority Identification.
The heuristics and statistics method based on the
association weight are used to automatically identify the authorities that indicate the well-known journals,
conferences, experts, documents, communities and websites.
Profiles
can be automatically updated by tracking users’
searching and browsing behaviors.
Group members can also
contribute to the profiles explicitly by manually
editing and tuning of the profiles through the system's interface at anytime.
The representation of resources and
profiles in the Knowledge Grid is based on the markup
languages like XML and RDF in the semantic web [1]. Based on the profiles, we have developed a
tool GruDexer to continuously collect relevant
research documents with three methods including manually
uploading, customized collection
and meta-search engine.
Peers’ evaluations on documents are useful for researchers’ reference. We adopt a dynamic mechanism for research groups to generate different evaluation criteria for their own research goal by consulting a set of general evaluation criteria specified by the experts and research students. Currently, we simply combine the comments inputted by users to form one text, and use the following two formulas to compute the overall evaluation score denoted as Ej for the jth document.
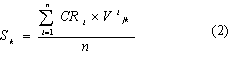
Where m is the total number of evaluation criteria, wk is the weight assigned to the kth evaluation criterion, and the default value is 1. Sk is the evaluation score corresponding to the kth evaluation criterion, n is the number of members who give feedback for the same document, Vijk indicates the value assigned to the kth evaluation criterion of jth document according to the ith member’s option, and CRi indicates the credibility of the ith member in a specified research domain.
![]()
Where, Ei denotes the number of documents that are evaluated by the ith member, |D| denotes the total number of documents, Pi (or Ni) denotes that the number of documents on which the ith user’s evaluation is confirmed (or negated) by others. WE, WP and WN respectively is the assigned value with respect to each case.
The
Knowledge Grid provides users a set of management operations (such
as put, get, browse, delete,
etc)
to cooperatively
manage the research documents. We herein mainly illustrate the document
retrieval approach in terms of get operation.
By
making use of the keyword-based approach and the PageRank
method [4], we propose a profile-based matching approach to make an estimation
of document relevance, which considers two factors: the semantics associative
keywords and the citation times that reflect the quality of a paper. Given a
query k inputted
by the user, we firstly determine the appropriate
profile according to the keyword matching method. Second,
calculate the similarity score of each document with the selected profile based
on the cosine similarity method, and then select the documents whose similarity
scores are bigger than the threshold. Third, re-rank the selected documents by
further considering their average citation times per year. Finally the documents
are displayed to the user in the order of the relevance score. The following two
formulas respectively computes the similarity score denoted as Si and
the relevance score denoted as Ri for the ith document.
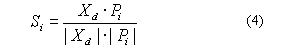
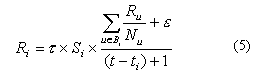
Where Xd ={xd1,xd2
,
…,xdn
} is a document feature vector extracted from document d where each
component indicates the degree of importance of a term in the document, Pi
={ki1,ki2,…,kim
} denotes the selected ith profile vector where m denotes the
number of general terms in the profile and
kij denotes the weight of the jth term in
the profile. Bu is the set of documents that cite the ith
document, Nu is the number of citations of the uth
document,
![]() is a adjustment factor to avoid the numerator is zero when the ith
document hasn’t been cited, and here
is a adjustment factor to avoid the numerator is zero when the ith
document hasn’t been cited, and here
![]() is assigned initial value 0.01. t and ti are
respectively the current year and the publication year of the ith
document, and
is assigned initial value 0.01. t and ti are
respectively the current year and the publication year of the ith
document, and
![]() is a factor used for normalization.
is a factor used for normalization.
Additionally, the system can continuously check for new documents that match the user’s profile and notify group members of new recommendations through the interface of Knowledge Grid or by email. The general framework is illustrated in Figure. 1.
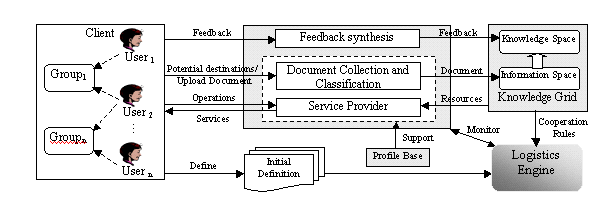
Figure1. The framework of document logistics platform.
The proposed document logistics approach enhances cooperative research by incorporating the following three characteristics. First, it continuously discovers and collects new potentially relevant documents based on the semantic profiles. Second, it allows distributed group members to collaborate on organizing and evaluating shared documents with the support of Knowledge Grid. Third, it provides flexible management operations and recommendation services for group members to efficiently access relevant documents. We have implemented the prototype of document logistics based on the Knowledge Grid platform VEGA-KG (available at http://kg.ict.ac.cn).