Interests and knowledge differ from person to person. Such differences are reflected in the semantics of words and terms. For example, the terms ``notebook computer'' and ``PDA'' may be similar to a particular user from the perspective of portability, but the term ``desktop computer'' is not similar on this basis. For another user, the terms ``notebook computer'' and ``desktop computer'' are similar because both are computers, but the term ``PDA'' is not.
The authors have proposed a collaborative Information Retrieval (IR) scheme for personal documents with a mechanism for adapting to divergence in word semantics [4]. This scheme is targeted to IR on personal repositories. A personal repository is storage space in a personal computer that stores personal documents such as emails and technical papers that the user writes or downloads. The IR function of a personal repository provides a search capability to the user as well as a knowledge circulation capability to the user's acquaintances by accepting queries from them and answering the queries.
This collaborative IR scheme personalizes the IR function by utilizing concept bases, which are personal cooccurrence-based thesauri constructed from documents in personal repositories. A cooccurrence-based thesaurus [2] represents the similarity between two words as the cosine of the corresponding vectors, and it is constructed by reducing the dimensionality of a cooccurrence matrix for a corpus. The collaborative IR scheme constructs a cooccurrence-based thesaurus by regarding the set of documents in the personal repository as a corpus. Therefore, the constructed thesaurus reflects the tendency of word usage in the documents written or read by the user.
In the case of doing a search on a personal repository in response to a query from another user, it might be problematic to utilize a thesaurus that is personalized to the repository's owner. The understood meaning of the query keyword may differ between the query sender and the repository owner. To overcome this difficulty, the scheme performs an automated relevance feedback for each query.
Although the feasibility of this scheme was validated in the authors' previous paper, the validation experiment used an intentionally created `personal' corpus. Therefore, it is important to examine how much personal cooccurrence-based thesauri really differ from person to person. Additionally, a systematic method for examining differences in personal thesauri can be used to find relations among people based on their interests and knowledge, as the method proposed by Hamasaki et al. [1] does by measuring the differences among the structures of bookmark folders of Web browsers.
At the development stage of the collaborative IR scheme, privacy issues prevent us from preparing real data on personal repositories for experiments. Fortunately, however, we can obtain a substitute for a personal repository by retrieving Web pages starting at the homepage or the bookmark file of the user.
Accordingly, we present in this paper a method of constructing a personalized cooccurrence-based thesaurus from a personalized corpus obtained from the Web. We also propose a scale to measure the difference between two thesauri. Moreover, we report on the results of our experiment.
We propose a method for constructing a personalized cooccurrence-based thesaurus, which is divided into two parts: personal corpus retrieval and thesaurus construction.
A personal corpus is a set of Web pages that are retrieved from the Web by using a Web crawler. The Web crawler starts its task at the user's homepage or bookmark file and then gathers Web pages by following links in a breadth-first order until the number of pages in the corpus reaches into the thousands.
After the corpus is retrieved, it is used as the basis for constracting
a cooccurrence-based thesaurus, in the same way as
in [2,3].
The thesaurus construction process is outlined as follows.
First, a cooccurrence matrix ![]() is built for all pages in the corpus.
An element
is built for all pages in the corpus.
An element ![]() of
of
![]() corresponds to the number of times the
word
corresponds to the number of times the
word ![]() and
the word
and
the word ![]() cooccur
within the corpus.
Then the matrix is decomposed with the singular value
decomposition (SVD) method so that
cooccur
within the corpus.
Then the matrix is decomposed with the singular value
decomposition (SVD) method so that
In this section, we propose a scale for measuring the differences between personal thesauri built by the method described in the previous section.
The scale is based on the root mean square of differences between
the similarity values of words in each thesaurus. Namely, when a pair
of words is given, the cosine value of their vectors in
thesaurus ![]() differs from that
in thesaurus
differs from that
in thesaurus ![]() . We calculate the
difference between the cosine value
in
. We calculate the
difference between the cosine value
in ![]() and the cosine
value in
and the cosine
value in ![]() for every pair of words and sum those difference values by
calculating the root mean square.
for every pair of words and sum those difference values by
calculating the root mean square.
More precisely, we define the scale as follows. The feature vector of
the word ![]() in thesaurus
in thesaurus ![]() is the corresponding
row vector of
is the corresponding
row vector of ![]() , which
we denote as
, which
we denote as
![]() . The similarity value between two words
. The similarity value between two words
![]() and
and ![]() in thesaurus
in thesaurus ![]() is
is
The difference ![]() can be calculated when both
can be calculated when both ![]() and
and ![]() are included in both
are included in both ![]() and
and ![]() . However, this is not applicable
if
. However, this is not applicable
if ![]() or
or ![]() is not included
in
is not included
in ![]() or
or ![]() .
By considering this, we extend the
definition of
.
By considering this, we extend the
definition of ![]() to
to
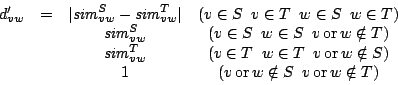
Here, we add the difference values throughout the thesauri.
Let ![]() be
the number of words in a thesaurus. By calculating the above formula
for all pairs of words,
we get
be
the number of words in a thesaurus. By calculating the above formula
for all pairs of words,
we get ![]() difference values.
The scale is
the root mean square of them:
difference values.
The scale is
the root mean square of them:
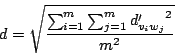
We built personalized cooccurrence-based thesauri as follows. We selected six computer science researchers as target users, and each user's personal corpus was retrieved by a Web crawler. The personal corpus retrieval results are shown in Table 1.
We examined how extensively documents were shared within each pair of these personal corpora. The propotion of shared documents was about 5% for each pair of corpora. This confirms that personal corpora significantly differ from each other.
A cooccurrence-based matrix and corresponding cooccurrence-based thesaurus
were constructed as follows. First, for a corpus that includes tens of
thousands of words, we
made a 5,000 by 2,000 cooccurrence matrix,
![]() . Here, each row
of
. Here, each row
of ![]() corresponds to one of the 5,000
most frequently appearing words in the corpus, while each
column corresponds to one of 2,000 most frequently appearing words, and element
corresponds to one of the 5,000
most frequently appearing words in the corpus, while each
column corresponds to one of 2,000 most frequently appearing words, and element
![]() records the number of times
that words
records the number of times
that words ![]() and
and ![]() cooccur.
Here, words
cooccur.
Here, words ![]() and
and ![]() are regarded as cooccuring
if they are in a
symmetric window of total size 41 that is centered
on word
are regarded as cooccuring
if they are in a
symmetric window of total size 41 that is centered
on word ![]() .
Consequently, the cooccurrence-based
thesaurus is produced by SVD
to reduce the dimensionality
of matrix
.
Consequently, the cooccurrence-based
thesaurus is produced by SVD
to reduce the dimensionality
of matrix ![]() to 5,000 by 100.
to 5,000 by 100.
For instance, the similarity values in the thesauri of user `p' and user `q' are compared for two words in Table 2. These results show that for user `p', the word ``Web'' is semantically close to the word ``applications''; however, for user `q' it is distant. On the other hand, for user `p', the word ``Web'' is not so similar to the word ``Search'', but for user `q', it is similar.
Accordingly, the difference values among these thesauri by using the proposed scale are shown in Table 3. The underlines indicate that the corresponding users are actually coauthors of a paper. This result shows that coauthors, who are expected to share interests and knowledge, tend to have low difference values.
In this paper we described a method for obtaining a personalized corpus from Web pages and for constructing a personalized thesaurus for the corpus. To measure the differences among thesauri, we proposed a scale. The results reveal differences between users' thesauri, and the difference values measured by the proposed scale reflect the users' similarity in interests and knowledge.
A personal corpus is a substitute for a personal repository, which contains not only Web pages but also various other types of information sources. To realize a collaborative personal repository system, such variations need to be adapted. Further work will involve combining the thesaurus equalization method proposed in [4] and the thesaurus construction method proposed in this paper.