 .
.
Information Systems Applications, Miscellaneous,
Web-based Question Answering System, Experimentation
Quiz, Question Answering System, answer scoring
Japanese Quiz Television [QUIZ] is a popular television show where participants are gathering to answer questions from the animator. The questions are usually a specific or common sense one on Japanese or worldwide culture. The participants learn the answers from the previous quiz or books. It is also possible to get the answers from the World Wide Web.
Our system is trying to answer question such as ``how many meter is the summit of Mount Fuji?'', ``Which highschool is the baseball player Matsui from?'' or ``Who is the prime minister of Japan originated from Iwate?'' but not the question such as ``How to cook a curry rice?''. Indeed, the last question is difficult to answer by the existing question answering systems.
Web-based Question Answering System is becoming a tool to help users to answer specific or common sense questions such as AnswerBus[Zheng], START [Katz] or Mulder [Kwok et al.]. This paper provides a preliminary result of our experiments to solve Japanese quiz television program with Web-based question answering system. Our system accepts questions in Japanese natural language and provides a list of keywords as possible answers. The system extracts the phrases or keywords from the question, then it uses a search engine to retrieve Web pages that are relevant to the question. From the Web pages, it extracts keywords around the matched keywords by the search engine that are determined to be the answers. In our experiments, for 20 questions, the correct answers found in the top 5 of the list is 50% and the correct answers found in the top 6 to 20 of the list is 35%. 15% of the questions do not have answers from the system.
The paper presents the development and experiments of our system to answer the quiz. The next section describes the system architecture. Then, the answer extraction algorithm and scoring module are explained. Finally, we conclude with the preliminary result of the experiments.
The system architecture is depicted in the figure .
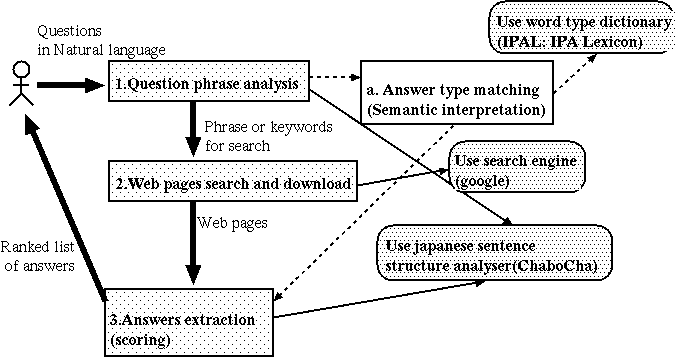
Figure: System architecture: user enters question in natural language
and obtains a list of possible answers.
This module consists with the construction of the search query for the search module. The question in natural language is transformed into phrase and keywords list. The phrase is the positive or negative form of the sentence obtained from the interrogative form. For example, a question such as ``Who is the prime minister of Japan?'' is then transformed into textit ``The prime minister of Japan is''. The question also is converted into keywords with the help of the parser (ChaboCha)[ChaboCha]. From the previous example, the system gives two keywords textit prime minister and textit japan.
A submodule called answer types matching has a task to determine the
type of the answer according to a lexicon (IPAL)[IPAL]. The IPAL
lexicon provides 10 types of word (see table ). We use
three types of answer at the moment respectively Human (names),
Quantity (number) and Time (date, hour, minute and seconds).
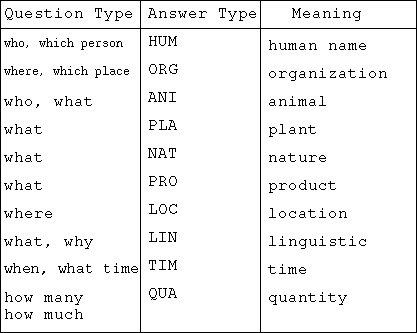
Table: IPAL lexicon word types
For example, the previous question (who is the prime minister in Japan?) has an answer type textit Human because the word ``Who'' is matched with type `Human names'. The answer type is also used in the answer extraction module.
After the conversion of the question into search query, this module searches the relevant Web pages by using an existing search engine such as google [Google]. The result of the search engine is a list of Web pages relevant to the search query according to the search engine criteria. This module crawls the Web by downloading the Web pages in HTML formats referred by results list. Those Web pages are saved in the local disk of the machine where the system is running. The HTML Web pages are converted into ascii text files. Tags are removed and replaced with commas or periods according to their type.
This module concerns to extract the potential answers (called also
candidates) from the text files output of the search module.
Firstly, the result of the search query as phrase is processed. The
process is a pattern matching of the regular expression. The
extraction also depends on the type of the answer.
Secondly, if there is no result from the search module according to
the phrase query, the keyword search query result is processed.
We used similar process as described in Mulder system [Kwok et al.]
for the answers extraction. We implemented the extraction area (called
summary in Mulder system) for each Web pages as 150 Japanese
characters or five sentences around the phrase or keywords. The areas that are not close to any query keywords are unlikely to contain the answer.
The measure of the distance of keywords each other is based on the
following formula (square-root-mean of the distances between keywords) :
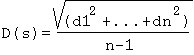
d1,...d
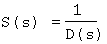
This scoring is a little different with the one used in Mulder system.
Rules are written to identify the type of the answer by pattern
matching. The candidates with numeric characters are classified into
quantity or time types and the others are
names as human type if the question is started with ``who''. The other types are detected with the table .
A scoring is done for each answer candidate. The score1 S1(a) is the result of the distance with the keyword contained in the extraction area and the answer candidate. The score1 is obtained as follows:
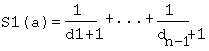
where d1,...d
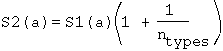
where n
When the answer candidate exists many times within the same page, it is collected in one, and the score is cumulated. the final score is the result of the score2 S2(a) .
The answer candidates are sorted in order descendant according to the highest score. A minimum value is defined to limit the candidates to the first to the top 30.
In our experiments, for 20 questions, the correct answers
found in the top five of the list are 50% and the correct answers
found in the top 6th to 20th of the list are 35%. 15% of the
questions do not have answers from the system. Some questions
about the Japanese history thousand years ago are difficult to find in
the Web. In the real Quiz, some questions have multiple given answers which should be sorted. We plan to add such functionalities.
Our system is still heavy and the performance of the computation is
very slow. We work only with Japanese language and the syntactic
analyzer in Japanese we used is very slow. We need to improve the
system to be competitive with AnswerBus or Mulder in terms of response time.