List detection and understanding is an important component of the web page re-authoring process. Lists are high level logical elements within a web document, and web pages re-authored to view on small screen handheld devices often perform a poor job of keeping this construct intact. The separation of logical association of the list elements in the re-authored output often leads to poor readability and difficult navigation. In this poster, we propose and demonstrate how simple heuristics can be used to detect and analyze lists within HTML pages and how the list can be re-authored in a way to maximize the readability and navigability of web browsing in small screen devices. The proposed technique can be used in web page re-authoring, summarizing, web archiving, web search and conversion of HTML documents to other formats.
Web page re-authoring, list detection and re-creation, small screen devices.
Web page re-authoring is becoming an important research topic due to the proliferation of various small screen handheld devices capable of browsing the web. Since most of the web pages are now written using HTML, with java, CSS and Imagemap support, re-authoring becomes a difficult task, specifically as the display capability of the various devices vary widely. On top of that, since spatial coordinates of the web page components can only be known after rendering with a browser, such as Microsoft® Internet Explorer® or Netscape®, and is often not available to third party vendors, it sometimes becomes difficult to know how to re-author a web page given the unknown spatial association of web page elements. An example of this problem is an HTML list. Often such a list is created with HTML table construct, and while re-authoring, the content associated with this construct gets separated into smaller blocks with no apparent association. But it is highly desirable to reproduce a list as a list on the re-authored output. This poster shows how heuristics can be used to create very dependable solutions to this problem.
Over the years, researchers have proposed different solutions to the problem of web page re-authoring. Handcrafting involves typically crafting web pages by hand by a set of content experts for device specific output. This process is labor intensive and expensive. Thranscoding [1] replaces HTML tags with suitable device specific tags, such as HDML, WML and others. The research on non-transcoded solutions to web page re-authoring can be broadly separated into two parts: approaches that explicitly use natural language processing (NLP) techniques based on computational linguistics [2,3], and the approaches that use non-NLP techniques [4,5]. Reported approaches are too many to mention here due to space constraints. A comprehensive bibliography can be found in [6]. Most of these approaches are concerned with content re-flowing and do not address the problem of content association in the re-authored output.
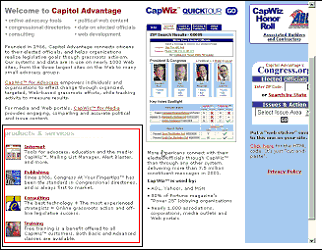
Figure 1 shows an example web page, where the red rectangle shows a possible candidate for a list. This is a very common construct encountered again and again in various web pages. The list is characterized by the fact that it has a title or heading, it has multiple horizontal (row) entries with associated hyperlinks. Each entry is in the form of a short heading and the image associated with that heading is often associated with the same hyperlink. Visually, this construct conveys the message that these entries are similar and related, only a small textual summary is provided and if interested the surfer can follow the link to more detailed content. In most cases than not, this is achieved via the HTML table construct, and when a table is a table in HTML is itself a big research area [7]. The approach described in [4] primarily creates a data structure to extract information about the HTML structure and its content. Each node within that tree is then categorized into logical classes, such as headline, story body, side bars, banners, navigation bars, and so on. Although this classification helps in re-authoring, it still does not provide association of the content blocks with each other. A list is a higher-level logical construct that needs to be created from smaller classes.

For example, Figure 2 shows a logical list structure derived by hand that represents the example web list construct most closely. Although it is not impossible to derive this based on some content analysis of the HTML table construct, often the display device is unable to display these structures and the content needs to be re-flowed.
One way of achieving this is to model the common repeating pattern in the table rows. Such a simple model might be expressed as (
If all these conditions are met, then it can be assumed that the main theme of the textual content is associated within the links and the textual content is an explanation of each of the entries to the list. Assuming such a pattern is detected, the rows are then grown in the vertical direction to produce a list. In these cases, the re-authored list can be conveniently expressed as a list of links. Figure 3 shows such an example. Each entry within this new list is a link to the rest of the textual content. For example, following Internet link will take the user to more detailed content shown in Figure 4. Any original link following from this textual and image content is preserved and can be followed from this re-authored list. The re-authored list is much easier to read and navigate on a small screen handheld device.


This poster has proposed a novel approach to identify and reconstruct lists during web page re-authoring using heuristics. In preliminary experiments, it is seen that such an approach produces high quality intelligent summary for web pages allowing fast and efficient web browsing on small display handheld devices.
Our thanks to US Army Communication Electronics Command (CECOM) for supervising the Small Business Innovation Research (SBIR) grant #DAAB07-02-C-K004 that funded this research.