ABSTRACT
Similar document search is the problem of retrieving documents that resemble a given document. In this paper, we describe a cluster-based retrieval scheme that approximates the classic nearest neighbor search scheme, by identifying the clusters that are closest to the input document and restricting attention to these clusters only. Cluster signatures play an important role in the effectiveness of this approximation, since the inclusion of a cluster in the restricted search depends entirely on whether its signature matches the given document. We study three different representations of cluster signatures and their role in performing a similar document search, while examining only a fraction of the documents from the target corpus.
Keywords
Similar document Search, WWW search, data mining, cluster-based information retrieval, cluster representation, centroid vector.
1. INTRODUCTION
In this paper, we address the problem of retrieving documents that are similar to an input document. This problem is otherwise termed query by example, where a user submits a document to the information retrieval system, which returns documents that closely match the input document. Some applications of this type of search include: finding news articles that are similar to a given article; finding resumes that are similar to a given resume; finding patents that are similar to a specified patent.
We present an overview of our retrieval system. In our system, we represent documents in high-dimensional vector space and employ the well-known nearest neighbor algorithm to find similar documents. For large document sets, we use the cluster-based retrieval scheme described in this paper to speed up the nearest neighbor search.
We group documents into units called collections, and restrict the search to within a collection. For example, we consider an input document (or news article) from the San Jose Mercury News collection and look for similar documents in the Wall Street Journal collection.
Each document is represented internally as a set of weighted terms. These terms correspond to the most important terms in the document. The set of weighted terms is called the feature vector of the document. The feature vector does not contain all the terms in the document. It only contains the salient terms that capture, in a sense, the essence of the document. The vectors are normalized to enable cosine computations. The motivation for choosing this representation over the traditional inverted index representation [8] is presented at the end of Section 3.
A similar document search is initiated when an input document D and a target collection C are presented. The first step in the search process is to retrieve the feature vector v of D. The next step is to compare the feature vector with the feature vectors of the other documents in the target collection C. The final step is to return the match results. The matching is based on the inner product or cosine distance between vectors.
The
straightforward nearest-neighbor based matching scheme compares the input
vector with the feature vectors of all the documents in the collection. This
can cause unacceptably slow searches for large collections, since it takes ![]() time, where
time, where ![]() is the number
of documents. Hence, we adopt a cluster-based retrieval scheme in which
the documents in the collection are clustered in a pre-processing step, and the
clusters are used in a retrieval phase to identify a subset of documents
to be matched with the vector v. This scheme is a constant-time
retrieval scheme, which is bounded by a parameter that specifies the maximum
number of documents that can be compared with the input vector.
is the number
of documents. Hence, we adopt a cluster-based retrieval scheme in which
the documents in the collection are clustered in a pre-processing step, and the
clusters are used in a retrieval phase to identify a subset of documents
to be matched with the vector v. This scheme is a constant-time
retrieval scheme, which is bounded by a parameter that specifies the maximum
number of documents that can be compared with the input vector.
The subset of documents that is used in the retrieval scheme is identified as follows:
(1) Compute the signature of each cluster, where a signature is a feature vector of unit length. The terms in the signature are derived from the feature vectors of the documents in the cluster. Section 3 presents three ways of computing the signature.
(2) select the clusters whose signatures are closest to v,
(3) Consider only those documents that belong to the selected clusters. For example, if a collection has 100 K documents and 300 clusters with roughly 300 documents in each cluster, we can select the top 20 clusters that best match v, and compare with these 20 * 300 = 6K documents only, as opposed to the entire set of 100K documents. The assumption is that the best matches from these 6K documents will be a good approximation to the matches obtained by examining the entire collection.
A key component of the cluster-based retrieval scheme is the signature of each cluster. The choice of terms in the signature is absolutely critical to obtaining good matches. The centroid of a cluster is the most popular and well-studied method of computing the signature. In this paper, we propose two signature representation schemes that differ from the centroid in the way in which weights are assigned to individual terms in the signature. Other representations for cluster signatures have been explored in [1,2, 5].
We use a goal-oriented evaluation method in which the goodness of a cluster signature is based on how best the retrieval scheme employing this signature approximates the nearest neighbor search over all documents in the target collection. Thus, signature A is considered to outperform signature B, if the same retrieval scheme employing A results in a closer approximation to the nearest neighbor search than while employing B. The evaluation is not based on the traditional measures of cluster goodness, like intra-cluster distance, inter-cluster distance and shape of the clusters. Instead it is based on the outcome of the similarity search that employs each of the representations.
The following sections discuss the cluster-based retrieval scheme used, the representation schemes for the signatures, and our experiments and test results.
2. CLUSTER-BASED RETRIEVAL SCHEME
The goal of the cluster-based retrieval scheme is to employ clustering as a means of reducing or pruning the search space. Instead of comparing with all the documents in the collection, the scheme allows a subset of the documents to be selected that have a high likelihood of matching the input document. There are two phases in this scheme: (a) a pre-processing phase in which the documents in a collection are clustered, and the signatures of the clusters are computed, and (b) a retrieval phase, in which the cluster signatures are used to retrieve similar documents.
2.1 Preprocessing
The
well-known k-means clustering method [4, 5, 6] is used to cluster the
documents in a collection. The number of clusters k is set to ![]() , where n is the
number of documents in the collection. This number was chosen after initial
experimentation. Initially, k documents are selected at random, and
assigned to clusters numbered 1 through k. The feature vectors of these
documents constitute the signatures of these clusters. The remaining
, where n is the
number of documents in the collection. This number was chosen after initial
experimentation. Initially, k documents are selected at random, and
assigned to clusters numbered 1 through k. The feature vectors of these
documents constitute the signatures of these clusters. The remaining ![]() documents are
considered sequentially. Each document is assigned to the cluster whose
signature is closest to the input document (i.e., has the highest inner product
similarity with this document). When all the documents have been examined and
assigned to their closest clusters, the signature of each cluster is recomputed
to represent the centroid of this cluster (see Section 3.1).
documents are
considered sequentially. Each document is assigned to the cluster whose
signature is closest to the input document (i.e., has the highest inner product
similarity with this document). When all the documents have been examined and
assigned to their closest clusters, the signature of each cluster is recomputed
to represent the centroid of this cluster (see Section 3.1).
After re-computing the cluster signatures, the next iteration through all the documents is commenced. In this iteration, if a document is found to be closer to a cluster that is different from its current cluster, then it is removed from the current cluster and reassigned to the new cluster. Experiments suggested that 4 passes or iterations suffice to obtain good clusters.
2.1 Retrieval Phase
In the retrieval phase, a document D is received as input to the similar document search, and its feature vector v is matched with the signatures of the k clusters that were computed in the pre-processing phase. The clusters are sorted in descending order of similarity with the input vector v. The sorted list is traversed, and when a cluster is considered, all the documents that belong to it are compared with the input vector. The documents with the highest similarity seen thus far are accumulated in a results list. The traversal is stopped when the number of documents compared equals or exceeds a parameter, known as max. comparisons. For example, max. comparisons can be set to 5000 to indicate that no more than this number of documents should be compared with the input vector. This allows the similarity search to be completed in fixed time. Suppose the 10 clusters that are closest to the input document contain a total of 5000 documents altogether, then the search is restricted to these top 10 clusters. The traversal of the sorted list of clusters is stopped after the documents in the 10-th cluster are examined. The results list of matched documents is then presented as the output of the similar document search.
3. CLUSTER REPRESENTATION SCHEMES
In this section, we describe how cluster signatures are computed. This signature is used in both phases of the cluster-based retrieval scheme. In the pre-processing phase, it is used to assign documents to clusters, and in the retrieval phase, it is used to select clusters for further examination. The signature is represented as a feature vector also, just like the documents in the collection. The question is: how to select the terms that constitute the signature and how to compute their weights? The sections below present three different schemes for addressing this question.
3.1 Centroid representation
The centroid of a cluster represents the average (or center of gravity) of all the documents in the cluster.
Consider a cluster with 1000 documents, each containing 25 terms in their feature vectors. Suppose that the number of unique terms over the entire space of 25 * 1000 terms is 5000. The centroid vector includes all 5000 terms, and the weight of a term is the average weight over all documents in the cluster. For example, if the term finance appears in 5 of the 1000 documents in this cluster, with weights 0.2, 0.3, 0.4, 0.1 and 0.8 respectively, the weight of this term in the signature is (0.2 + 0.3 + 0.4 + 0.1 + 0.8) / 1000, which is 0.0018.
For large document collections characterized by high dimensional sparse vectors, the centroid has the following disadvantage: if a term is found only in a small fraction of the documents in a cluster, the weight of this term in the signature is drastically reduced. The next two schemes overcome this limitation.
3.2 Maximum Weight Limited Feature (MWLF) Cluster Representation
In this representation, the weight of a term in the cluster signature is defined as the maximum weight of this term, over all occurrences of this term in the cluster. In the above example, for the term finance, the weight of this term in the signature is 0.8. Thus, if a term has a high weight in any document in the cluster, its weight in the signature is also high. This heuristic overcomes the weight reduction problem caused by averaging, but has the opposite effect of boosting weights, even if there is insufficient evidence to warrant the boosting. The next scheme addresses this problem.
3.3 Penalty Weight Limited Feature (PWLF) Cluster Representation
In this scheme, if a term occurs infrequently in a cluster, it is penalized, but the reduction is not as steep as in the centroid. The weight of a term in the signature is given by
![]()
where mx_wt is the
maximum weight of this term over all occurrences of this term in the cluster, penalty
is a number < 1.0 and m is the number of documents in the cluster
that did not contain this term. In the above example, the maximum weight of
the term finance is 0.8; m is 1000 – 5 = 995; if penalty is 0.9999, the weight
of this term in the signature is ![]() , which is 0.7242.
, which is 0.7242.
The signatures obtained from all three methods are truncated to include the 200 terms with the highest weights. This is the so-called limited feature representation of the signature. The truncation is performed to reduce the time spent in comparing the input document with the cluster signatures (see [5] for a discussion on truncating features during clustering). The number 200 was obtained after experimentation that indicated that increasing this number beyond 200 does not result in improved search performance.
Before proceeding to the next section on testing and experimentation, we pause to motivate the choice of the feature vector model over the inverted index model.
The feature vectors in our system are not static, but dynamic. Although the initial vectors are based on the contents of the documents, they can be altered through user feedback. For instance, if a user typed in a query Q and rated a document D from the search list as being the most relevant document for this query, then the query Q can be added to the feature vector of D. Since frequent updates to the inverted index are expensive, the feature vector representation is chosen.
We believe that it is faster to retrieve the features of a document with the vector representation, rather than from the inverted index. Since similar document search essentially translates to a large query search, preliminary experiments suggested that it is more efficient to use the vector model than an inverted index model for processing such queries with 50 terms or more.
4. TEST AND EXPERIMENTATION
The primary objective of the tests was the comparison of the restricted search involving a subset of the documents with the baseline search involving the entire collection. Experiments were conducted by utilizing the three cluster representations described above.
4.1 Data Set
We used two document collections consisting of news articles, The Wall Street Journal (WSJ) collection has 98600 documents and the San Jose Mercury (SJM) collection has 7000 documents. The SJM collection is the source collection from which input documents are chosen. The WSJ collection is the target collection from which similar documents are retrieved.
4.2 Pre-processing
We compute the feature vectors of all the documents, and cluster them. The feature vector length for documents is fixed at 25. The centroid representation of the clusters is used during the clustering.
4.3 Baseline Search
A set of 100 input documents is selected at random from the SJM collection. For each input document, the following steps are performed:
(a) Similar documents are retrieved from the WSJ collection by performing a baseline search (or nearest neighbor search) through all the documents in the collection.
(b) The results are sorted in decreasing order of similarity.
(c) The top 20 results are recorded. Since we restrict our evaluation to the 20 documents that are most similar to the input document, it suffices to store these results only.
Let F = { Df1, Df2, Df3, … , Dfi , … , Dfm }
be the result set for a given input document. The top 3 matches for this document is given by
F (top 3) = { Df1, Df2, Df3 }.
In general, we can define F(top x), where x is the number of results being considered. The tables shown in the next section present results related to F(top 3), F(top 10) and F(top 20).
4.4 Clustered search
We fix a cluster representation, for example, the MWLF representation for the cluster centroid. The signatures of all the clusters are re-computed using this scheme. The clustered search described in Section 2.1 is performed for the same set of 100 documents that was used in the baseline search. While performing the search, the parameter max. comparisons is used (for example, 5000), to truncate the search (see Section 2.1 for more details).
For this cluster_representation and value of max. comparisons, the results list for a given document is
C = { Dc1, Dc2, Dc3, … , Dci , … , Dcm }
Similar to the baseline search we have
C (top 3) = { Dc1, Dc2, Dc3 }
to include the 3 documents that are most similar to the input document.
We define an overlap factor that determines the degree to which the clustered search results agreed with the baseline search. In other words, the factor measures the extent to which the clustered search mimics the baseline search. Since the clustered search makes fewer comparisons than the baseline search, it is expected that the results will degrade. The overlap factor measures this degree of degradation.
4.5 Overlap factor
The overlap factor is defined as the intersection of the results from the baseline search and the clustered search, for a given input document, a cluster representation, a value of max. comparisons (mxCmp), and a top x level, where x can be 3, 10, 20 etc. The level restricts the results sets to include the first 3, 10 or 20 documents in the sorted results list.
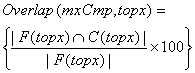 %
%
where the notation | A | is the cardinality of set A (equivalent to the number of elements of set A).
The overlap factor for a single document is averaged over all the input documents (in our case, 100).
The tests are performed for all three cluster representations, for 3 different comparison bounds:
5000 (5% of documents in the collection)
10000 (10% of the documents in the collection) and
25000 (25% of the documents in the collection).
The overlap factors averaged over the input documents for the top 3, top 10 and top 20 results levels are computed.
5. RESULTS AND DISCUSSIONS
Table 1 shows the results of the test conducted using the centroid vector as the cluster representative for cluster-based retrieval.
The entry in the first row, first column, with a value of 76 indicates that on average, 76% of the top 3 results from the baseline search were among the top 3 results in the clustered search, when the number of comparisons allowed is 5000.
Table 1. Average Overlap factors for Centroid Representation
|
MaxCmp |
Top 3 |
Top 10 |
Top 20 |
|
5000 |
76.0 |
76.8 |
76.3 |
|
10000 |
84.7 |
84.3 |
83.6 |
|
25000 |
93.3 |
93.9 |
92.9 |
The overlap factors shown in the above table essentially intersect the results from the baseline search with those of the clustered search.
In the example shown below, the input document and the top 5 results from the baseline search and the clustered search with centroid representation are presented.
Input document
sjm/001-025html/sjm_006.sjmn91-06356062.html
Results from baseline search, with 98600 comparisons
SCORE Key
0.6966 wsj/1987/wsj7_071/doc_122.txt
0.6817 wsj/1987/wsj7_007/doc_217.txt
0.6656 wsj/1987/wsj7_097/doc_313.txt
0.6308 wsj/1988/wsj8_063/doc_110.txt
0.6104 wsj/1987/wsj7_110/doc_220.txt
Results from clustered search for the
centroid representation, with 5000 comparisons
SCORE Key
0.6966 wsj/1987/wsj7_071/doc_122.txt
0.6308 wsj/1988/wsj8_063/doc_110.txt
0.6104 wsj/1987/wsj7_110/doc_217.txt
0.5840 wsj/1988/wsj8_052/doc_316.txt
0.4861 wsj/1988/wsj8_058/doc_015.txt
In this example, the clustered search searches 5000 documents from the WSJ collection, out of a possible 98600 documents. It retrieves 1 out of the top 3 results from the baseline search. Therefore the overlap (5000, top 3) is 0.33. Similarly overlap (5000, top 5) is 0.66.
Let us consider the following questions: (1) when can a document appear in the results list for baseline search only, and (2) can the relative order of results be different for baseline and clustered searches?
The first situation can happen in one of two cases:
(a) The document D was included in a cluster C, and the signature of this cluster did not match the input document, or
(b) The signature matched, but the inner product value was so low, that by the time this cluster was considered, the max. comparisons value was exhausted. Recall that in the clustered search, the clusters are traversed in sorted order and the traversal ends when the allowed number of comparisons is exhausted.
The second situation cannot happen since the same inner product measure is used in both types of searches, to match the input document with a document from a target collection.
Thus the comparison between results lists is a sequence comparison, and not a set comparison. This
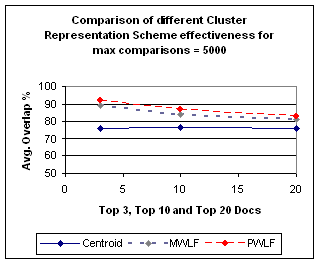
The results in Table 1 can be visualized graphically in Figure 1.
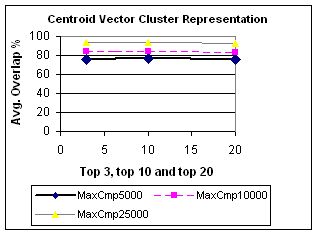
Figure 1. Centroid Cluster Representation line graphs
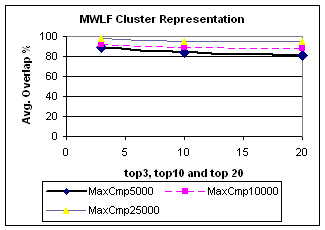
|
MaxCmp |
Top 3 |
Top 10 |
Top 20 |
|
5000 |
89.0 |
84.0 |
81.3 |
|
10000 |
92.0 |
89.1 |
88.4 |
|
25000 |
97.7 |
95.4 |
95.0 |
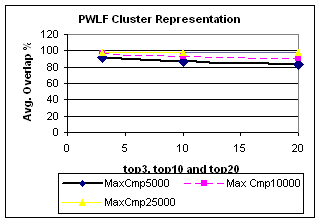
|
MaxCmp |
Top 3 |
Top 10 |
Top 20 |
|
5000 |
92.0 |
86.7 |
83.1 |
|
10000 |
96.3 |
92.8 |
90.9 |
|
25000 |
98.3 |
97.5 |
97.4 |
6. CONCLUSIONS
We have studied three different cluster representations and their impact on similar document search. The results indicate that the alternatives to the centroid representation presented in this paper are very effective in approximating nearest neighbor search, even when the number of documents being examined is less than 10% of the total.
The reduction in the average overlap factors for higher retrieval set sizes (top 10, top 20) as compared to values for top 3 needs to be explored further.
7. ACKNOWLEDGMENTS
The authors would like to thank Verity, Inc. for providing the facilities for conducting the tests and experiments. The authors would also like to thank Dr. Rajat Mukherjee and Dr. Jianchang Mao for their valuable suggestions during the testing and experimentation phase.
8. REFERENCES
[1] Bhatia., K.Sanjiv and Deogun, S. Jitender. Cluster Characterization in Information Retrieval. ACM-SAC 1993 Indiana USA, 721-727.
[2] Croft, W.Bruce. On the Implementation of some Models of Document Retrieval. ACM SIGIR 1977, 71-77
[3] Crouch, B. Donald. A Process for Reducing Cluster Representations and Retrieval Costs. Comm. ACM 38, 224 - 227.
[4] Duda, R., Hart. P. Pattern Recognition and Scene Analysis, Wiley New York, 1973.
[5] Jain, A.K., Murty, M.N. and Flynn. P.J. Data Clustering: A Review. ACM Computing Surverys (CSUR), Vol 31, No. 3, September 1999, 264 - 323.
[6] Koutroumbas, K., Thordoridis, S. Pattern Recognition, Academic Press, 1998
[7] Schutze, H., Silverstein, C., Projections for Efficient Document Clustering. SIGIR ’97, July 27 - 31, 1997, pg 74 – 81
[8] Witten, I.H., Moffat. A., Bell, T.C. Managing Gigabytes Compression and Indexing of Documents and Images, 1994.
[9] Yu, C.T., Luk, W.S. Analysis of Effectiveness of Retrieval in Clustered Files. Journal of the ACM, Vol 24, No. 4, October 1977, 607-622.