Erik Duval
Dept. Computerwetenschappen, K.U.Leuven
Celestijnenlaan 200 A, B-3001 Leuven, Belgium
Erik.Duval@cs.kuleuven.ac.be
Wayne Hodgins
Autodesk & Learnativity
258 Eucalyptus Rd., Petaluma, CA 94952, USA
wayne.hodgins@autodesk.com
Abstract
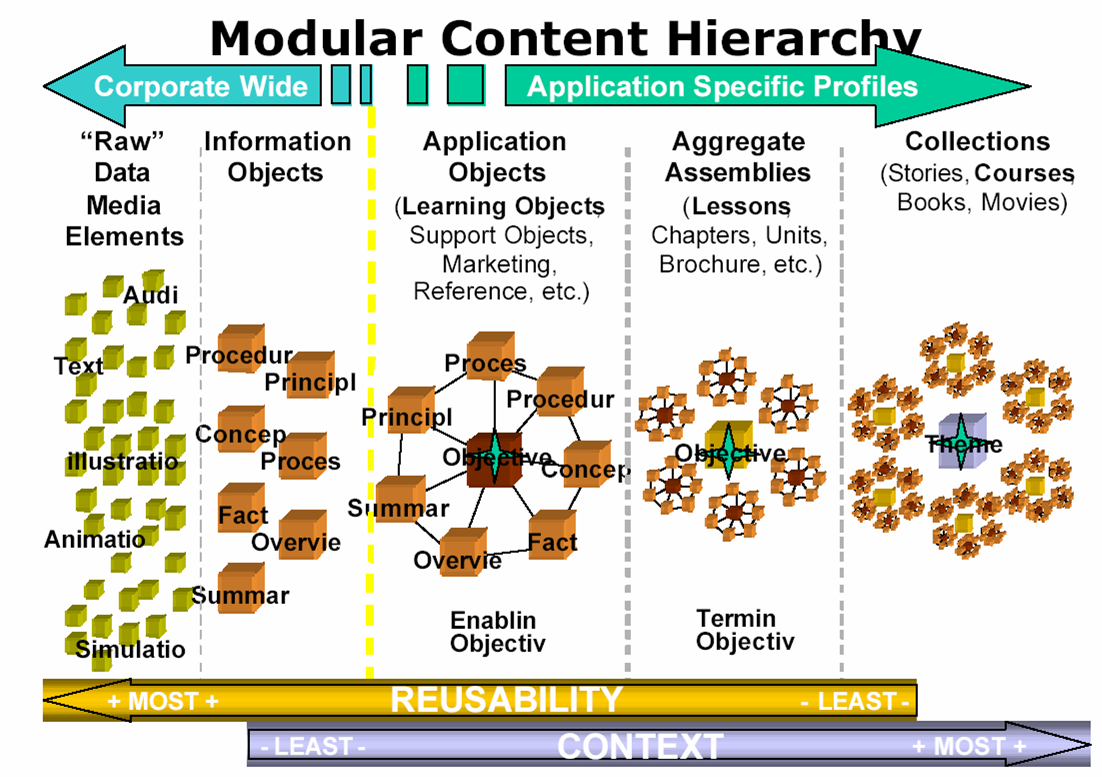
This paper presents a research agenda on Learning Objects. The main intent is to elaborate on what the authors consider important issues for research on learning objects and their use in education and training. The paper focuses somewhat on metadata related issues, but does not restrict itself to only those aspects that have a direct relationship with metadata.
Keywords
metadata, learning, training, education, knowledge management, eLearning, library and information science, information management, content management, adaptive hypermedia, learning technology standardization