
Maurice Szmurlo - Jacques Madelaine
GREYC --- CNRS UPRESA 6072, Université de Caen
Esplanade de la paix, F-14032 Caen Cedex, France.
Maurice.Szmurlo@info.unicaen.fr, Jacques.Madelaine@info.unicaen.fr
The growth of the World Wide Web has been very important in the past few years, especially because applications development is fairly easy. This is due to the simplicity of the HTTP protocol. However, developing complex applications on the Web which must access database or GIS servers is painful because HTTP is stateless. This is the case with the cartographic application we are currently developing and for which we need session management and background processing.
We propose a general framework of a companion server which takes care of all the lacks of the HTTP daemon encountered in a user session management. The server memorizes all the users actions and is able to deal with eventual refinements of parts of the query by the user. The architecture we designed is based on ``communicating automata.'' We use these basic components to build the CGI, the server, and the drivers of the specific applications.
This research is supported in part by the company Captimark
32, rue St. Augustin, 75002 Paris, France and by
the European Found FEDER.
The wide development of the World Wide Web is mainly due to the stateless nature of the HTTP protocol. This implies easiness of development of applications. The designer does not have to care about session management or about the current state of a query the user may have begun to compose, since such functionalities are not directly allowed by the protocol. Thus, actual applications are basically ``one-shot'': when the client requests a resource, either the resource exists and the server sends it back, or it doesn't, in this case the server produces it, for example, by the means of a CGI script and returns it to the client. Eventually, the connection is closed, and the server does not even remember about the request.
Such a simple model is sufficient for many applications, even important ones that can use existing toolkit to connect to a Data Base Management System(DBMS). For our concern, we developed a cartographic tool in order to experiment how to link together different software components: a Geographic Information System (GIS), a DBMS and a Data Processing System (DPS). The goal of our application is the online production of maps that represent thematic information, in order to enlighten geographical phenomena, for example, the population repartition over an area. Although relatively simple, this application is interesting because it shows the limits of the one-shot model. It will be shortly described in section 2.1.
There is unfortunately an entire class of applications where such a model is not at all sufficient, especially in concern with development of intuitive user interfaces. Lets take an example we could called ``a virtual supermarket''. Assume a shop offering its customers the possibility to order items. The application allows to select the items the user wants to buy, then displays the list of the chosen products, the total price, and an ordering form. The first implementation of the interface could show the whole list of the available items; the user would then select some of these by clicking in check boxes, for example. This solution is neither ergonomic nor acceptable due to long transfer delay since all the information must be down loaded. It would be indeed much more intuitive for the user to navigate thru a hierarchy of menus: the top level would propose the different categories, then sub-categories, based on the choice made on the previous level, and so on until the final choice of the product. This application requires several accesses to the server in order to compute the intermediate pages, to memorize the retained items, quantities, etc.. A very basic session management can be performed using the HIDDEN inputs of forms: all the information the server needs to remember from one page to another will be coded as HIDDEN inputs in the forms, and, thus, will be included in each request. This solution is however not satisfactory for three reasons:
The first problem arises if the user suspends a request and connects to the application some time later using the main entry URL. Since all the information were embedded in a dynamically generated page and not remembered by the server, they are lost and the user has to perform all the cycle again. Secondly, ``background processing'' is interesting for applications when the creation of a request is performed using several pages and where some intermediate part of the request is sufficient to perform a query to a DBMS, for example. Such a query could be executed in background by the server while the user is proposed to continue the selection of the remaining of the request. Performing parts of queries in background speeds up the application, at least from the subjective point of view of the user. For such applications, the simple session management scheme based on HIDDEN inputs is not suitable since the server has to keep in memory the state of all requests that are currently being composed and the results of the queries performed in background. It is therefore necessary to adjunct to the HTTP daemon an additional server which will keep the state of achievement of the requests, perform the queries to the specialized applications (GIS, DBMS, and DPS), and memorize their results.
Based on our previous experiment (the cartographic tool), we developed a much more complex application which allows in addition to select precisely the working geographical area, to type in the formula that represents the thematic phenomenon to be displayed on the map, etc.. The functionalities of this application will be described in section 2.2. For its conception, we used a set of software tools for server design which basic components are communicating automata that were developed for another project [8]. They will be detailed in section 3. Using a companion server with the HTTP daemon allows us to both manage the session and to keep the current state of the requests. Httpd and the companion communicate via a CGI script which is in charge of generating the HTML pages. At each step (HTML page) of the construction of the request corresponds a client automaton in the CGI and a server automaton in the server. The hierarchy of automata we build and the advantages of this architecture are fully described in section 4. Note that this framework does only not solve the problem of session management, but deals properly with the back and forward issued by an user browser.
For our experiments we developed two cartographic applications. The first one is designed using the one-shot model while the second one uses an additional server for management of the session and state memorization. The functionalities of these two applications will now be described.
The requirements concerning the user interface are directly in correspondence with the functionalities of our tool:
These three choices correspond to the three questions one has to answer in order to produce a map:
The architecture of this application is classical. The interface is designed with basic HTML, without any client-side processing (no Java applets nor JavaScript code). All the ``intelligence'' of the system is coded in a CGI script which communicates with three specific applications and which is in charge of generating the resulting HTML page. The spatial database operations are implemented with the SPACE GIS [1]. The thematic information are stored in a DBMS and are available to the application via a SQL server, mSQL [3]. Finally, all the data processing (i.e. regressions, residuals, and classifications) are performed by S+ [2].
When the HTTP server receives the first request, the CGI forks and gets its parameters from its environment. It analyzes the parameters and detects some possible incoherences the user entered. In this case, it sends back an error message. Once all the parameters of the request have been analyzed, the CGI sends in turn the appropriate requests to the specific applications. The communications with the SQL server are performed using the API provided with mSQL. SPACE implements a sub-set of the CORBA [5] (see [9] for a good introduction) specification, and therefore, the CGI acts as a CORBA client. Finally, S+, which cannot be configured to be run as a server, is forked from the CGI for each request and the communications are performed via Unix pipes. The last solution could not be satisfactory for a real application, but is sufficient for our experiment, especially because S+ launching delays are very short.
The result of a request is a map representing the chosen phenomenon over the chosen region together with a form which allows to select a new request. However, this time the user has a new possibility: he may ask for zooming or unzooming by clicking on the map. In order to allow this, it is necessary to embed in the HTML code the information related to the size of the currently displayed map. This is done by using the HIDDEN inputs of the forms.
This simple application has two important drawbacks:
Integrating ``state management'' on the server can be performed by two methods: modification of the HTTP server and of the HTTP protocol, or by developing of a specialized server which will communicate with a CGI. The first solution, explored by Trevor et al. [7] is elegant. The authors propose to clean from the server code all the unnecessary features used by the Web, and to add the specific code of the application. To our sense, however, this approach has two drawbacks: writing server code and specifying protocols is not straightforward, and, it turns the HTTP server into an application specific server.
For another project we developed tools for server design and protocol specification. This application, the ``anté-serveur documentaire'' [8] is a front server designed to asynchronously query several data banks to answer to a single user query. The basic server components are ``communicating automata'' able to communicate either with each other or with foreign applications by sending and responding to events. Server design and protocol specification becomes a very modular task: we ``only'' need to identify and to implement the different classes of automata which depend on the action they have to perform, and the event they accept or send. Due to the successful implementation of the ``anté-serveur'' incited us to adopt an automata-based architecture for the server of a more complex cartographic application which functionalities will be detailed in the next section.
In this second application we extended most of the functionalities already implemented in the first one. We separated the construction of the request in 6 pages:
In order to implement these functionalities, it is clear that using the one-shot model is not sufficient. Indeed, when a request arrives on the server, we have to solve the following problems:
The architecture of this application is shown on Figure 1. On his first connection to the main entry URL, the user is identified using the HTTP access control protocol. Once this identification is done, the browser will automatically send to the server the identification HTTP cookie. In addition, each HTML request page contains an application specific cookie used for internal purpose. These cookies are generated by the server and embedded in each response (see below). In the rest of the paper, by ``cookie'' we mean the application cookie.
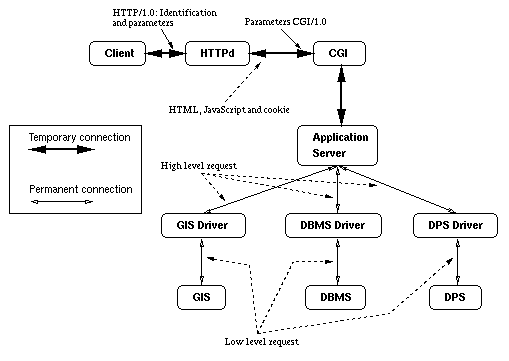
Figure 1. Architecture of the cartographic application.
Upon request, a CGI is launched by httpd. Its global task is to process request parts sent by the HTML page currently displayed on the client (we call it the previous page) and to generate a response page (called the next page). Its first action is to connect to the application server, and depending on its parameters to activate one of its specific modules which is in charge of sending the selected parameters of the previous page, and of generating the next page. The first task of each module is to insure the user identification by sending the user's cookie to the server. Once this identification is accepted, the module sends the parameters. Finally, the CGI requests for information that are necessary for building the response page, sends the response to the client, and the CGI dies. To summarize, each module in the CGI implements the following logical protocol:
Each of the specific modules in the CGI is a communicating automaton, called a client automaton, or simply CA. The connection it establishes with the server is actually done with another automaton, the session directory, which compares the userID with other users userIDs held in the list of currently active sessions. If the user is referenced in the system, the session directory forwards the request to the user session managing automaton (USMA) which is in charge of identifying the last user's request performed on the server. This second identification is based on the operationID part of the cookie. If both identifications succeed, the USMA connects the CA with its server counterpart, a server automaton, or SA, and sends to the CA a ``Identification Succeeded'' message. Since then, all the communications between the CGI and the server will actually be done between the CA and the SA.
While the user builds up a map request, he navigates from page to page on the client. On each submission, a specific CA is activated in the CGI and a specific SA is created on the server. In order to memorize the user's wandering, all the SAs are kept alive, even after completion of the request they were created for. They are organized as a hierarchy which corresponds to the hierarchy of the pages the user visited. This allows to process parts of the request for which the user has supplied enough parameters in background while the user is proposed to fill in the next page. The intermediate results are stored in the SA. Eventually, we obtain a navigation graph of SAs on the server.
As in the first cartographic application, we use three specialized applications that perform specific tasks: the GIS, the DBMS, and the DPS. They are permanently connected to our application server via drivers which task is to create the low level requests and to perform the communications. Since each of the applications uses a different communication mode (see section 2.1) and different query languages, each of the drivers is specific to its application. Queries between the server and the drivers are done in a application independent protocol, while queries between a driver and the application it controls are performed in the specific query language of the application. This ensures independence of the server against replacement of any of the applications.
The organization of the navigation graph of SAs in the server and their creation scheme upon reception of a new request will be described in section 4, but first, we will detail the functionalities of the automata.
The section presents our software basic component : automata. They are implemented in C++ and their basic characteristics are presented in section 3.1 and section 3.2 shows how we can uses them.
The automata we used are basically C++ objects which transitions functions have been defined to be executed upon reception of a given event in a given state. All the automata classes inherit from a basic class having the following primitives:
The args parameter of a send is a pointer to a polymorphic list of integers or characters strings. The send primitive just enqueues the event identified with eventId in the queue of the automaton automatonId and resumes the execution of the current transition. Thus, the execution of a transition function is warranted to be atomic and there is no transition preemption. Good manners state that transitions must execute in a (short) bounded time; long transitions must therefore be divided into smaller ones and the logical sequence be rebuild by letting the automata sending events to himself.
The argument senderId is by default the identifier of the automaton executing the send. But, it is common that an automaton receives a request by the mean of an event and don't know how to satisfy this request but know another automaton perfectly able to answer. For example, A1 sends a request to A2. A2 cannot fulfill the request by himself, but the automaton A3 can. Instead of sending an event to A3, waiting for the response and forwarding it to A1, A2 can simply directly forward the event to A3 with A1 as the senderId argument value. Thus, A3 will be able to answer directly to A1. This mechanism is a smart implementation of service delegation.
The transition functions are controlled with a logical scheduler that transforms all the external events (such as data read on a file descriptor, Unix signals, ...) into automata events. If an automaton wants to read a file descriptor, it simply register himself to the scheduler and it will receive events with chunks of data as the argument. The run-time of the scheduler also implements timers that trigger specified events after a given time.
Automata can be used, on one hand, as distributed objects and allow transparent dispatching over several processes. On the other hand, they can be used as classical C++ objects inside the same process.
The first use is possible with the addition of specialized automata in communication: the channels automata. They transmit events to distant automata across processes running on the same machine or different machines on the same local area network, by the way of pipes or sockets. They give a light-weight ad-hoc mean for distribute object programming with a simplified broker. The main advantage is that an application can be implemented transparently as one or few processes distributed on one or few machines and we primary used this feature to drive the communication between the CA running in the CGI process and the counterpart running into our server.
This feature must not be confused with the CORBA. The channels automata only allow to dispatch an existing process into few autonomous processes. They don't allow directly the connection of two existing applications. Of course, we can imagine to build another specialized automata to implement directly an Object Request Broker, but this is not our current objective.
Our automata are also plain C++ objects (and have all their advantages and disadvantages). They can have any number of data members to store internal values, or function members to access or update these values. They can also be used in a inheritance hierarchy and have virtual functions to allow true OO programming. We will see in next section how a bunch of Servers Automata (SA) is used to store all the information given by the user during its navigation in the application. In order to retrieve this information, it appears very elegant and efficient to use C++ message sending. The difference between the sending of pure C++ message and of our automata event is that the receiver of a C++ message is known by its main memory address and arguments are passed via the stack, while our automata are only reference through integral identifier.
Next section describes the server framework that use extensively these automata with theirs two properties.
The server is a process that receives all the user requests via the CGI. It transforms these requests into a set of transactions to be executed by specialized servers (such as SIG, DBMS, DPS). It must then supervise and synchronize their executions. It is also responsible for various computations needed to adapt to the various interfaces of the pre-existent servers. The server is also responsible for the user's session and request parameters management.
Unlike CAs that live only during an HTTP request, the automata in the server may have a life time equal to the session the end-user initiated.
This allow to manage each user session with an instance of automata and to remember all the user's requests of the running sessions with a forest of the so-called Servers Automata (SA).
This section presents the different automata classes the framework uses, and then focuses on the SAs showing how they operate as automata, and how they operate as ordinary C++ objects.
The server has three main problems to solve.
It uses the two following classes of automata to manage the session and the initial dispatching of message between a CA and its corresponding SA:

There exists an instance of USMA for each particular session. Each USMA knows all the SAs that compose the session and acts as the second switch, after the Session Directory, to contact a given SA automaton. Each USMA is also the root of the graph composed by the different SAs creation relationships. The house cleaning at the end of the session is simply achieved by recursively sending ``logout'' events to the directs sons which will forward this event down in the hierarchy before committing suicide.
The Drivers Directory allows a logical independence between the servers and the other automata (either the COQUINS or the SAs, if they directly use the Servers Drivers). Hence, as soon as an automata needs a service, it issues a request event to the Drivers Directory to get the correct Servers Drivers identifier (we did not choose to make the Drivers Directory to forward the request as it will be needed for him to know all about all the possible requests to the drivers).
The COQUINS use generally all the same pattern. They issue several requests to Servers Drivers, wait for the results and forward them to the demandant after they have been synthesized and/or re-formated to conform to the syntax understood by the automata that emitted the request.
SAs are the heart of this framework and next section will attempt to describe all their interesting features.
SAs are automata and use both features of our automata: autonomous automata and C++ object. First, we describe the inheritance hierarchy of the SA classes. Then, we will focus on the automata point of view and describe the transition functions of a generic SA triggered upon reception of a request. This event will be responsible for SAs creation.
Each concrete SA class derived from an abstract class: SA_base. The inheritance graph is depicted in Figure 2.
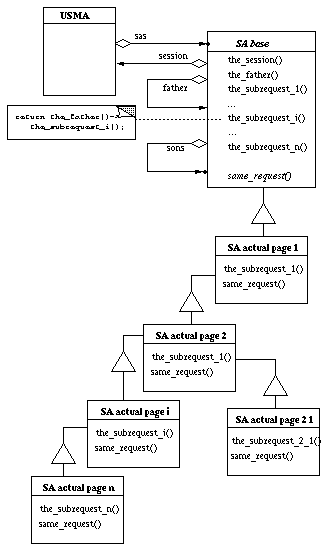
Figure 2. The SA class hierarchy
It uses the diagram notation used in [Design Patterns]. Each SA_base has three data members to code the navigation graph: session which points back to the USMA, father which is a pointer to an SA_base and sons which is a list of SA_base. There is one concrete class per specific step in user navigation. Each concrete class has additional data fields to store the information the user submit in the corresponding state. These field may be access with the family of method the_subrequest_i(). These method have a default value which is to ask the data to the father. Only the automaton in the hierarchy that holds the data corresponding to this sub-request, redefines it. This OO technique allows a simple and economic management of the whole request.
Figure 3 shows an example of SAs instances.
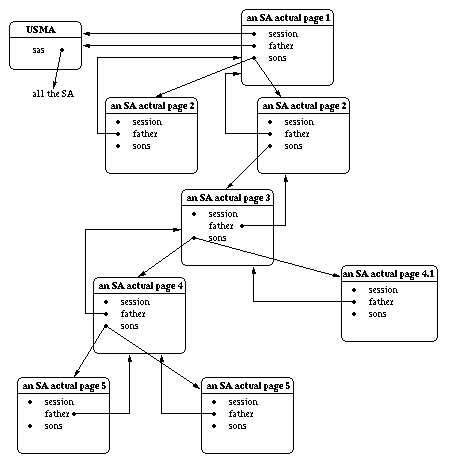
Figure 3. Example of SAs instances structure.
This example shows the user went twice through the second step of the interrogation (there are two SA_actual_page_2 automata instances). Then, it performs all the 3 remaining steps making a second choice on the fifth step. We can see he made a second choice on the fourth step that creates another type of automata.
The transition function triggered by an SA upon reception of a request depends of the state of the SA. If the request is received:
This paper has presented a framework for building servers that can deal with user sessions and transactions made up of several requests without changing the HTTP protocol. Note that this framework don't only solve the session managing problem (that could be handle by a new HTTP protocol [4]) but gives an elegant solution to store and to manage the request built step by step by the user, allowing the transparent use of ``back'' and ``forward''. Two server prototypes giving the possibility to build interactively maps are in demonstration at http://www.info.unicaen.fr/~szmurlo/SIG and http://www.info.unicaen.fr/~capti/MarkServ.
The framework is based on special automata objects. The automata can be called agents in the sense they are delegate to achieve the user's request. They can also create other agents (the COQUINS) for specific asynchronous work. But unlike true agents they don't live directly near the user interface. Their aim is mainly to store a state of the user's session. The entire tree rooted on a USMA keeps track of all the user navigation thus providing a full historic. They not only store the query (request parameters) but the results that are needed to format the HTTP server response. This feature avoids the re-computation of requests with identical parameters. As the text of the request is not entered in one step by the user, and because the user may refine his query (with the ``back'' and ``forward'' capabilities of the browser), each step of the user navigation is stored in one automaton. Thus, a node only stores the added information, the information for a query being virtually stored in a branch.
We currently work in two directions. First, as the code for corresponding CA and SA is spread over several files, we try to define a language to embed these definitions into one declaration that will avoid most of the procedural code. Secondly, we want to use the knowledge stored in a SAs tree during a user session to improve the dialog with the server and the help it can provide to the user [6].
A Network of Asynchronous Micro-Servers as a Framework for Server Development
This document was generated using the LaTeX2HTML translator Version 95.1 (Fri Jan 20 1995) Copyright © 1993, 1994, Nikos Drakos, Computer Based Learning Unit, University of Leeds.
The command line arguments were:
latex2html -split 0 WWW6.tex.
The translation was initiated by Jacques Madelaine on Fri Dec 13 21:00:51 MET 1996