|
Trip Report WWW2008 - April 22-25 2008, Beijing, China |
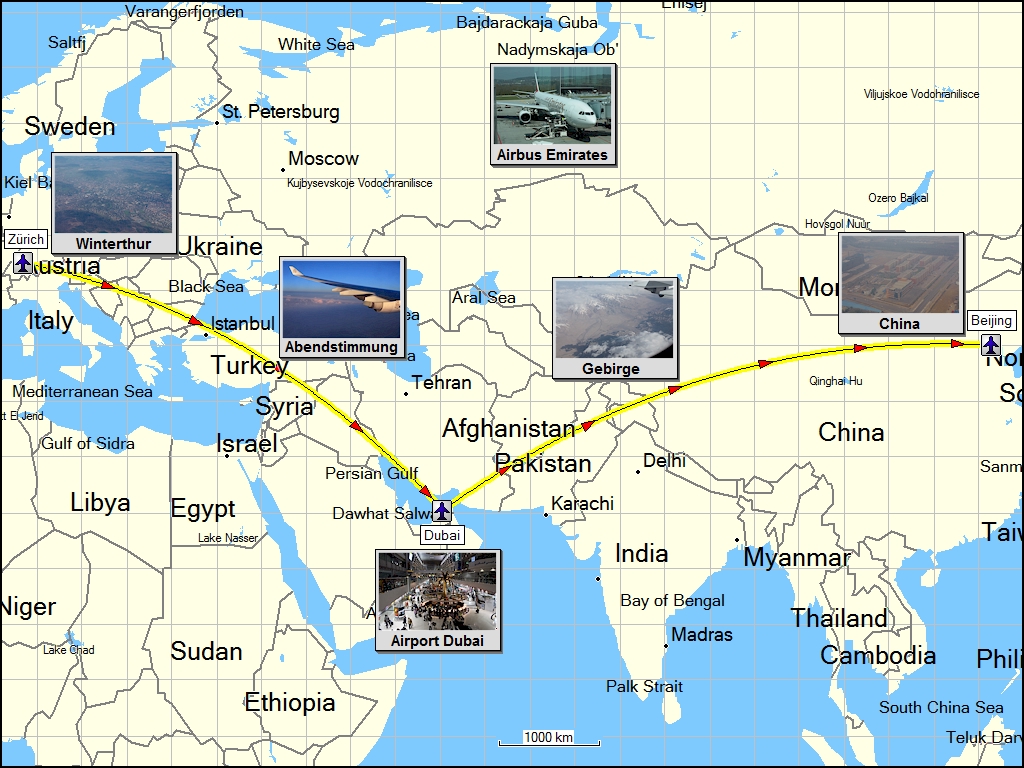
this time, i flew with emirates airlines from zürich via dubai to beijing. it was a good choice: the flights were on time, easy and comfortable and the staff very friendly. entering china was no problem at all - of course, i had the required visa. however, the ride with the taxi from the airport to the hotel was a bit adventurous because the taxi driver did not speak a word english and i don't speak any chinese at all. fortunately, the conference organizers provided the address of the hotel in chinese as a picture, so i could show the driver where i need to go to. this worked out very well.
route zürich - dubai - beijing on a flat map (left) and on Google Earth (right) on saturday, april 26, 2008 i took the reverse route back home. i left beijing 5 minutes before midnight and arrived in zürich on one o'clock on sunday afternoon (add 6 hours to the duration of the trip due to different time zones). again, i had a stopover in dubai from around 5 o'clock to 8 o'clock local time. it's worth a note that emirates airlines on all four flights took off on time and arrived up to one hour ahead of schedule. if time is precious for you, fly emirates.
beijing international airport
i had one day to explore beijing before the conference started. unfortunately, it was raining cats and dogs all day long, so i had to flee back to the hotel room after being out for two hours ...
beijing olympic stadium - known as "the nest"
park and apartment houses
heavy traffic ...
... in both directions
the conference was held at the beijing international convention center (BICC) which is located in the very northern part of beijing, just next to the new olympic stadium. i stayed at the beijing continental grand hotel which was just next to the convention center. fortunately, the two buildings are built together, because it rained a lot during the first two days.
beijing continental grand hotel
beijing international convention center
conference announcement
registration desk
Google's exhibition booth
Microsoft's exhibition booth
this was my first trip to china, so i travelled with mixed feelings. on one hand, i was very excited about the opportunity to see at least a little bit of this huge country and to get the chance to get an impression of the people and the culture of china. on the other hand, there were some recent issues particulary regarding the oncomming olympic games, that made me worried and concerned. these (political) issues had no impact on the conference, i didn't hear one single political statement. therefore i leave it like that.
the impressions i take home remain mixed: the traffic in beijing is terrible - but i must admit i didn't see any accidents at all. but i didn't want to have to run a marathon in this environment. people on the street and particularly in crowded places aren't really friendly. they don't hesitate to push and shove and some obviously don't like to join lines, they rather sneek in through the exit to avoid waiting. of course, this happens all over the world, but i found it very obvious here in beijing. on the other hand, the staff at the hotel, the restaurants and the convention center was friendly and very obliging, this is particularly true for the volounteers, students of the beihang university.
as far as the culture of this country is concerned, there are obviously huge changes going on right now. there are many modern buildings, such as the new terminal at beijing international airport, the new national grand theater just behind the great hall of the people and the olympic stadium. all these buildings are influenced by western culture, but at the same time have some typical chinese characteristics as well. it will be interesting to see how this country and its culture will evolve in the future.
the conference was officially opened on wednesday, april 23, 2008. the opening ceremony included a brief performance of various chinese artists - i liked the dancers, but i will never get used to the high pitched voices of the chinese singers. it was mentioned, that a new record high of 880 papers were submitted, of which 100 were accepted.
opening ceremonyafter the welcome note by a representative of the chinese government, dr. kai-fu lee, a vice president of engineering at Google, Inc. and president of Google greater china, gave the first plenary talk titled "cloud computing". he sees the "cloud" as the next logical step in the evolution from the mainframe to the mini computer to the personal computer. he mentioned ken olsen's company "digital equipment corporation" (DEC) as one of the pioneer in this evolution.
personal note: i generally agree with this point of view. however, i believe ken failed to recognize the PC as the next step in the evolution after the mini computer - unfortunately with the fatal consequence that DEC has disappeared from the scene instead of taking the lead.according to dr. kai-fu lee, the cloud solves user problems and therefore is "user-centric". data is no longer stored locally, but in the "cloud" and therefore follows the user and his/her devices. this provides access to data from anywhere and with any device anytime and allows to share data with others regardless of geographical location. cloud computing is also "task-centric", which means, the user has no longer to think in terms like "word processing", "spread sheet", "email" or "instant communication", instead of she or he has a task to fullfil and all the applications needed are mixed and combined in the cloud. Google has been a strong supporter of cloud computing since the very beginning. cloud computing provides much more power than a single PC to even only one user, this is way Google search is so much faster than any local search application on a personal computer. in Google's view, the "cloud" has infinite computing power and infinite disk space, assuming the work can be parallelized. this opens opportunities to perform tasks which are impossible without the "cloud". the "cloud" is made up of an enormous amount of - unreliable - hardware. dr. kai-fu lee gave some inside views of Google's file system and other technics developed to provide reliable services using fault tolerant software that runs on unreliable hardware to overcome system failures. he concluded, that the "cloud" will provide services to the users that will "just work" and that IT will become "simple and safe". it will give entrepreneurs new opportunities and free the market from monopolists.
personal note: if the "cloud" requires such a huge amount of resources that only companies like Google can afford to operate one, how exactly can the market be freed from monopolists ? it should probably rather be stated that the market will depend on monopolist "G" instead of on monopolist "M" - i'm not convinced that this is really an improvement. besides: exactly during this presentation, the connection to the Internet was so bad that it was not even possible to download some emails. how useful is data stored in the "cloud" if the "cloud" is not reachable ? maybe we need a mixture of "local" and "cloud" plus some smart applications which provide seemless synchronization between the data in the "cloud" and local data until permanent and reliable connectivity anytime anywhere is actually reality.
cloud computing - user centric
the power of cloud computing
dr. harry shum, corporate vice president responsible for search product development at Microsoft, talked about new experiences with search engines. he showed some projects Microsoft is working on. one example provided a new interface in order to assist users looking up ambiguous subjects, such as "jaguar". jaguar could be an animal, a car or an operating system. if the user starts a search using the keyword "jaguar", a number of images will show up. the user drags the image which represents the thing she or he is looking for to a particular area on the search engine's user interface and the search engine will immediately filter out only these "jaguars" which represent that particular type of object the user is looking for, for example only objects that refer to the animal "jaguar". the image helps to narrow down the search results very easy, the user doesn't have to describe what she or he is looking for, all the user has to do is to select the appropriate image.
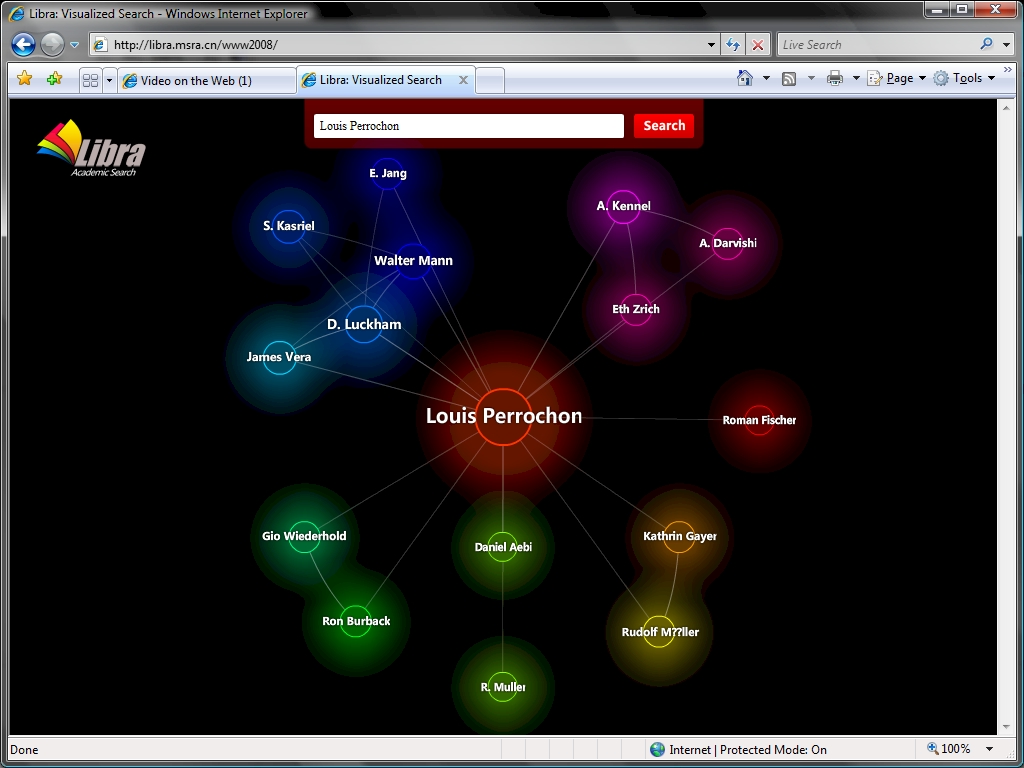
another very interesting project is libra, a free computer science bibliography search engine and also a test-bed for object-level vertical search research. in this example, libra presents search results as a colored network, each color representing a different type of relationship. a search for louis perrochon, a former ETH zürich student, results in the graph shown below. besides other connections, louis has a relationship to the organization ETH zürich as well as to some people such as daniel aebi or gio wiederhold. the user can navigate through this network of relationships simply by clicking on one of the nodes.
librareferences:
david belanger, chief scientist and vice president of information & software systems research at AT&T Labs presented his vision of the evolution of devices, services and networks. the term "three screens" refers to the three media types mobile devices, computers and TV sets, each with its own set of attributes such as bandwidth, screen size and user interface. david belanger expects an increasing choice of rich media content which users want to consume on all three screens. we may have started watching our favorite show or sports game at home on the TV when we have to leave. soon, services and technologies will be available to switch seamless from the TV to the mobile phone and continue watching the show or game while we are travelling. of course, such location independent services will not only be available for watching TV, but also for voice communication, conferencing, messaging and applications. such services require content adoption for the "three screens" based on their attributes.
three screens
- "do what i say, not what i do"
- an interesting variation of the saying "do what i mean, not what i say".
- DRY: Don't Repeat Yourself
- refers to the fact that people should use references to a single document that provides a particular set of information rather than providing the same information in many different documents over and over again.
- 3.7.1 semantic Web (RDFa):
since many years, the term "semantic Web" shows up at the top of the list of the most important subjects. this will most likely continue for the next few years. when tim berners lee brought up the subject for the first time, i was very confused and i had a very foggy idea about what "semantic Web" really means. since then, each conference helped me to get a bit less foggy view. i'm not saying my view of the sematic Web is now crystal clear, but i believe i start to catch the idea. i now understand that the semantic Web is not meant as a replacement for the existing Web of text based documents but as an extension - some also refer to it as "the next level". the idea is to bring data in a machine readable form to the Web. this would allow computers not only to show the information, but to analyze, sort and query the data and to enhance its value by putting pieces of information in relation to each other. if the computer "knows" that a particular piece of information is actually a date, it could - for example - add it automatically to my calendar.
RDF (Resource Description Framework) is very similar to a database schema, it describes the "meaning" of data and the relationship between pieces of information. RDFa is a simpler approach that allows to add descriptive attributes to parts of an HTML document and to links. for more details, see tutorial RDFa.- 3.7.2 Web science:
Web science is a relatively new term. it was suggested to investigate and research the phenomena called "World Wide Web" with scientific methods. if we understand why and how the Web evolves, we could try to engineer future developments "the right way" to make sure, everyone can benefit from the Web. for more details, see workshop web science.
- 3.7.3 HTML V5:
in this version, new features are introduced to help Web application authors, new elements are introduced based on research into prevailing authoring practices, and special attention has been given to defining clear conformance criteria for user agents in an effort to improve interoperability (taken from the HTML 5 working draft's abstract written by the W3 HTML working group). one of the main goals of version 5 of HTML is to better support Web applications. HTML 5 is a new version of HTML 4 rsp. XHTML 1 and will eventually replace WebForms 2.0 as well. backwards compatibility with previous versions of HTML is considered very important. for compatibility with existing content and prior specifications, HTML 5 describes two authoring formats: one based on XML (referred to as XHTML5) and one using a custom format inspired by SGML (referred to as HTML5).
the following elements have been introduced for better structure:
- section represents a generic document or application section.
- article represents an independent piece of content of a document, such as a blog entry or newspaper article.
- aside represents a piece of content that is only slightly related to the rest of the page.
- header represents the header of a section (not to be confused with head).
- footer represents a footer for a section and can contain information about the author, copyright information, et cetera.
- nav represents a section of the document intended for navigation.
- dialog can be used to mark up a conversation.
- figure can be used to associate a caption together with some embedded content, such as a graphic or video.
then there are several other new elements:
- audio and video for multimedia content.
- embed is used for plug-in content.
- m represents a run of marked text.
- meter represents a measurement, such as disk usage.
- time represents a date and/or time.
- canvas is used for rendering dynamic bitmap graphics on the fly, such as graphs, games, et cetera.
- command represents a command the user can invoke.
- datagrid represents an interactive representation of a tree list or tabular data.
- details represents additional information or controls which the user can obtain on demand.
- datalist together with the a new list attribute for input is used to make comboboxes.
- the datatemplate, rule and nest elements provide a templating mechanism for HTML.
- event-source is used to "catch" server sent events.
- output represents some type of output, such as from a calculation done through scripting.
- progress represents a completion of a task, such as downloading or when performing a series of expensive operations.
the input element's type attribute now has the following new values: datetime, datetime-local, date, month, week, time, number, range, email and url. the idea of these new types is that the user agent can provide the user interface, such as a calendar date picker or integration with the user's address book and submit a defined format to the server. it gives the user a better experience as his or her input is checked before sending it to the server meaning there is less time to wait for feedback. in addition, there is a huge list of new or changed attributes for a large number of elements.
on the other hand, a number of elements and attributes have been removed. this applies mainly to elements and attributes that served representational purposes, such as basefont, big, center, font, s, strike, tt and u. authors should use style sheets rather than these elements, which is tough news for me since i didn't yet manage to get used to CSS. however, i'm very glad that the elements frame, frameset and noframes finally have been removed from the HTML's specifications because their usage affected usability and accessibility for the end user in a negative way. finally, a number of APIs have been introduced that help in creating Web applications in order to support an interactive user experience. the list includes APIs for 2D drawing, playing of video and audio, editing, drag and drop and many more.
it shall be noted that HTML 5 is currently still a draft. a number of issues are under debate and changes are very likely to occur. for further details, see www.w3.org/html/wg/html5/; for a description of the differences between HTML 4 and HTML 5, see www.w3.org/TR/html5-diff/.
- 3.7.4 search:
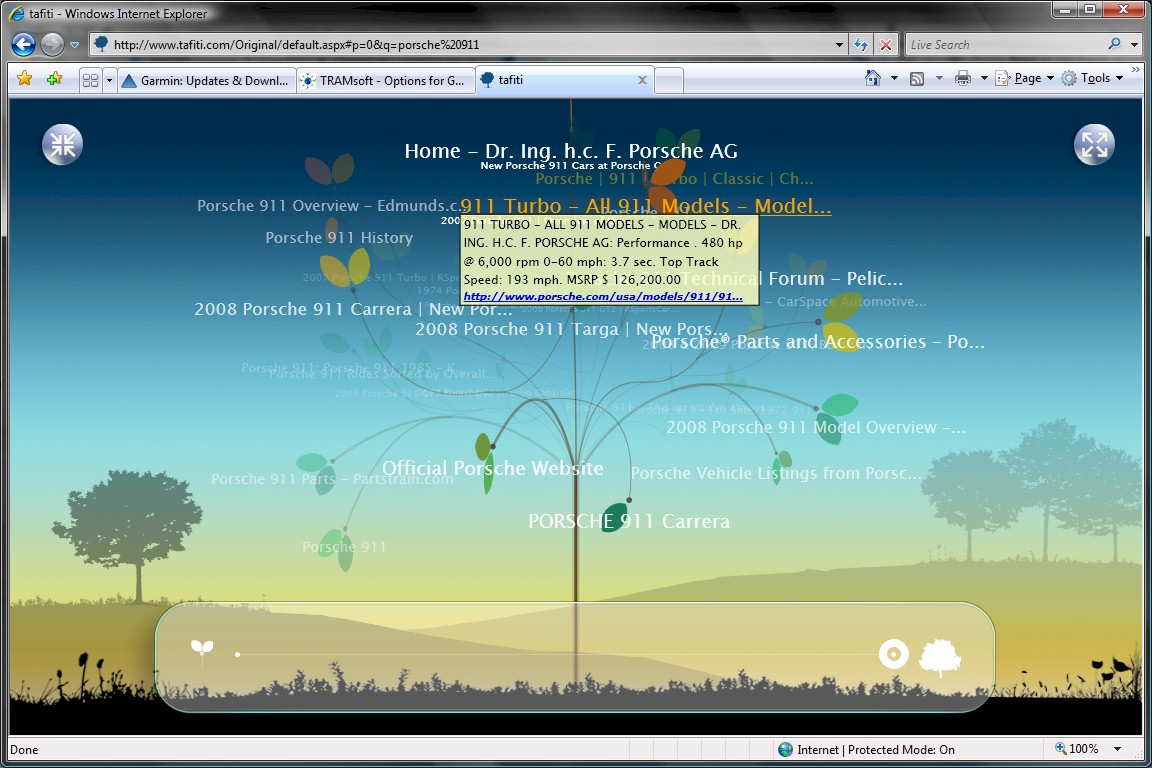
search is the other topic that has always been at the very top of the list of the most important issues. while yahoo had been very active at last year's Web conference, it seemed to me the company was kind of hiding this year. maybe they were afraid that Microsoft would try to hire their employees individually when they failed to buy the whole company. Microsoft was very active trying to show their various efforts around search, including the plenary talk given by dr. harry shum titled "taking search to new frontiers". another interesting project by Microsoft is the search engine tafiti, which however requires the installation of "silverlight", Microsoft's alternative to "Flash".
tafiti
- 3.7.5 mobile access:
this has also been a popular topic for the last few years. often, mobile access and accessibility are mentioned together for good reasons. mobile devices have limited resources and benefit from the same efforts as devices for people with disabilities such as braille devices or screen readers. unfortunately, the ETH Zürich is doing rather bad in terms of accessibility with mobile devices. the homepage is rather heavy and there is no dedicated design for mobile devices. popular applications such as the phone book are even worse. the input box is preloaded with a text that must be removed manually on a mobile phone and the result cannot be shown on a mobile phone at all. fortunately, there is an alternate phone book available, but only to those who know the address by heart (phonebook.ethz.ch). our friends at the university of Zürich did a much better job, their homepage and their phone book is easily accessible with almost any mobile device. however, the good news is, that our portal sites build with Microsoft sharepoint are very mobile friendly, because simplified access for mobile devices is build into this product.
the W3C provides a document that defines the tests that provide the basis for making a claim of "mobileOK Basic conformance". these tests are based on W3C Mobile Web Best Practices. Mobile Web Applications Best Practices are currently being developed and will be published soon. in addition, there is a beta version of an on-line mobileOK validator available.
- for further information see www.w3.org/2008/04/w3c-track.html.
the social event took place at the "great hall of the people", which is located at the western edge of tiananmen square in the center of beijing. it is the home of the national people's congress. an army of busses took us through the heavy traffic of china's capital to the location of the event. we had been warned by the conference organizers that the security checks at the entrance of the great hall of the people will be much more strict than at the airport and that it is absolutely forbidden to bring a bag. "ladies may bring a tiny bag, but we don't know how small tiny is", they said. also the information whether we were allowed to bring cameras was inconsistent and confusing. first they said cameras are "absolutely forbidden"; then they said, we "may bring a small camera but we cannot guarantee that you may actually take the camera inside". at the entrance, it turned out that there was no security check (the equipment was there but we could bypass the metal detectors) and there were cameras everywhere.
the dimensions of the building are impressive. the show included singing, dancing and stage performances. tim berners lee gave another interesting speech. the food was great and served by an armada of waiters and waitresses. we shared our table with people from all around the globe and had rewarding conversations. the time flew by and too soon we had to board the busses again which took us back to the hotel.
entrance to the "great hall of the people"
back of the "great hall of the people"pictures from the social event are available from the WWW2008 Photo Album.
the closing ceremony was basically reduced to the one sentence: "the conference is over". beside this simple statement, a number of awards were presented, such as the best paper and the best poster award. and - of course - there were a lot of "thank you"s. a delegation from madrid presented spain's capital as the site of WWW2009 and invited the attendees to the 18th World Wide Web conference, the 7th Web conference in this series to be held in europe.
award presentations during the closing ceremony
the WWW2009 delegate takes over
the 18th world wide web conference will be held on april 20..24, 2009 in madrid, spain, see WWW2009 for details.

introduction:
RDFa is a specification for attributes to be used with languages such as HTML and XHTML to express structured data. the rendered, hypertext data of XHTML is reused by the RDFa markup, so that publishers don't need to repeat significant data in the document content.
in more detail:
today, there is the Web of (text) documents and there is data, but there is hardly any interconnection between these two worlds. even worse, information is often replicated in order to be presented in a human reading form and in a machine readable form. the goal of RDFa is to give publishers options to present their data in a human readable form but at the same time, give them instruments to add semantic to the data, allowing software to interpret the "meaning" of the information provided. RDFa takes advantage of the fact, that user agents (web browsers) must ignore any information they cannot handle. if we add such things as attributes to pieces of information in a document that browsers don't understand, they must ignore it and present the remaining data according to the specifications they do understand.
example:
we assume jo smith is going to hold a last summer barbecue and invites her friends and relatives through her blog. this could look like this:
I'm holding one last summer Barbecue, on September 16th at 4pm.
Jo Smith. Web hacker at Example.org. You can contact me via email.the source of this small HTML document could look like this:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/REC-html40/loose.dtd"> <HTML> <HEAD> <TITLE>Jo's Friends and Family Blog</TITLE> </HEAD> <BODY> <P>I'm holding one last summer Barbecue, on September 16th at 4pm.</P> <P CLASS="contactinfo"> Jo Smith. Web hacker at <A HREF="http://example.org/">Example.org</A>. You can contact me <A HREF="mailto:jo@example.org">via email</A>.</P> </BODY> </HTML>these two lines of text contain a lot of information that is easy to interpret by a human reader, such as
- last summer Barbecue: kind of a title or subject
- September 16th: a date
- 4pm: time information
- Jo Smith: a name
- Web hacker: a job title
- Example.org: an organization
- email: contact information
however, a machine cannot interpret the data - some description is required. this could be achieved by adding attributes to these pieces of information, as shown in the source code below:
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML+RDFa 1.0//EN" "http://www.w3.org/MarkUp/DTD/xhtml-rdfa-1.dtd"> <html xmlns:cal="http://www.w3.org/2002/12/cal/ical#" xmlns:contact="http://www.w3.org/2001/vcard-rdf/3.0#"> <head> <title>Jo's Friends and Family Blog</title> </head> <body> <p instanceof="cal:Vevent"> I'm holding <span property="cal:summary"> one last summer Barbecue, </span> on <span property="cal:dtstart" content="20070916T1600-0500"> September 16th at 4pm. </span> </p> <p class="contactinfo" about="http://example.org/staff/jo"> <span property="contact:fn">Jo Smith</span>. <span property="contact:title">Web hacker</span> at <a rel="contact:org" hrel="http://example.org"> Example.org </a>. You can contact me <a rel="contact:email" href="mailto:jo@example.org"> via email </a>. </p> </body> </html>note the different type of attributes:
- instanceof: instantiates a particular type of data
- property: descriptive attribute of a piece of information
- class: instantiates a particular class of data
- rel: describes the relationship between two entities
this is a brief description of each attribute found in the document shown above:
- instanceof="cal:Vevent":
- marks the beginning of a calendar event.
- property="cal:summary"
- marks the description or title of an event.
- property="cal:dtstart" content="20070916T1600-0500"
- marks the start date and time of an event. in this particular case, there is actually duplicated data. the problem arises from the fact, that there are many different formats to express date and time. therefore we provide date and time in a human readable form as well as in a standardized machine readable form.
- class="contactinfo" about="http://example.org/staff/jo"
- here we provide a link to information about jo smith rather than providing the details about jo itself. this is known as DRY-data ("Don't Repeat Yourself").
- property="contact:fn"
- this is a person's name.
- property="contact:title"
- this is a person's job title.
- rel="contact:org" hrel="http://example.org"
- this describes the relationship between to entities, in this case between jo smith and her employer example.org.
- rel="contact:email" href="mailto:jo@example.org"
- description of another relationship, this time between jo smith and her email address.
the one remaining question is: how would a semantic aware user agent know the meaning of the attributes ? the "meaning" of the attributes has to be specified using RDF syntax. in order to use these specifications, you must refer to them in the opening HTML-tag of your document. attribute definitions - better known as "vocabularies", "schemas" or "ontologies" - are grouped in so called namespaces. you may reference multiple namespaces in a single document. such a reference looks like this:
xmlns:cal="http://www.w3.org/2002/12/cal/ical#" whereas cal is the namespace and the URI points to the attribute definitions.
this is an example of such a definition:
DTSTART This property specifies when the calendar component begins. default value type: DATE-TIME DATE-TIMEwhen you use an attribute definition in your document, you must not only provide the name of the attribute, but also the namespace in which this attribute is defined, such as instanceof="cal:Vevent", whereas "Vevent" is the name of the attribute and "cal:" refers to the namespace.
vocabularies:
there already exist a number of vocabularies which you can use in your documents. probably the most well known vocabulary is the so called "dublin core", see dublincore.org for details. these definitions provide classes and properties to describe various entities, such as persons and can be used for many different purposes.
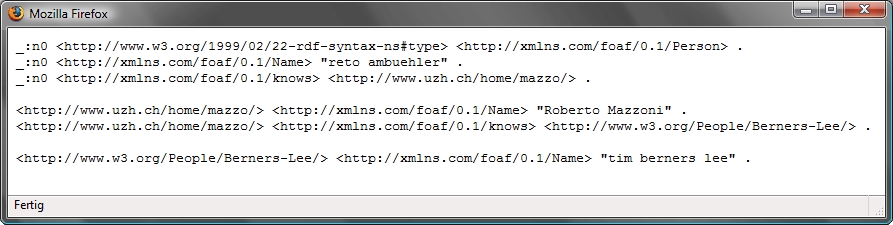
another interesting vocabulary is known as FOAF ("Friend Of A Friend"), see xmlns.com/foaf/spec/. its purpose is to describe entities such as persons, images, email addresses, homepages and relationships between these entities, such as "this is an image of A", "this is B's email address" or "X knows Y". it allows to describe a network (or web) of things and people as shown in the example below:
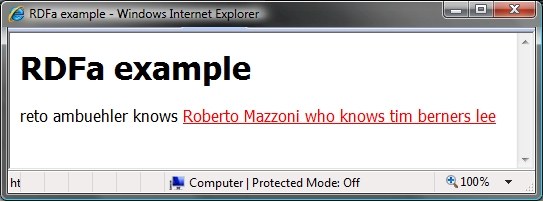
<HTML> <HEAD> <TITLE>RDFa example</TITLE> </HEAD> <BODY xmlns:dc="http://purl.org/dc/elements/1.1/" xmlns:foaf="http://xmlns.com/foaf/0.1/"> <H1>RDFa example</H1> <DIV typeof="foaf:Person"> <SPAN property="foaf:Name">reto ambuehler</SPAN> knows <A rel="foaf:knows" HREF="http://www.uzh.ch/home/mazzo/"> <SPAN property="foaf:Name">Roberto Mazzoni</SPAN> who knows <SPAN rel="foaf:knows"> <SPAN about="http://www.w3.org/People/Berners-Lee/" property="foaf:Name">tim berners lee</SPAN> </SPAN> </A> </DIV> </BODY> </HTML>if you open the HTML document shown above in Internet Explorer, it looks like an "ordinary" web page as shown below. the browser ignores all the "extra stuff" it cannot handle as defined by the user agent specifications.
however, there is a plug-in for firefox, which allows the browser to "understand" the semantic expressions in this document and to display the structure given by the attributes. you can "install" this plug-in from http://www.w3.org/2006/07/SWD/RDFa/impl/js/ - note that you cannot download "GetN3", instead, you have to drag the URI to the bookmarks of firefox. once you have installed GetN3, the above HTML document will be rendered as show below:
FOAF not only supports a vocabulary to describe entities and relationships, it could also be used to control access to documents on the web. for example, you may grant access to a set of documents to a particular person and to all direct friends of this person. or you may grant write access to a particular document to a person and to all direct friends of this person but grant only read access to all friends of his or her friends. this may have intersting implications. for example, if you and your direct friends are granted access to a web page that others are interested in, many people may want to become your friend ...
references:
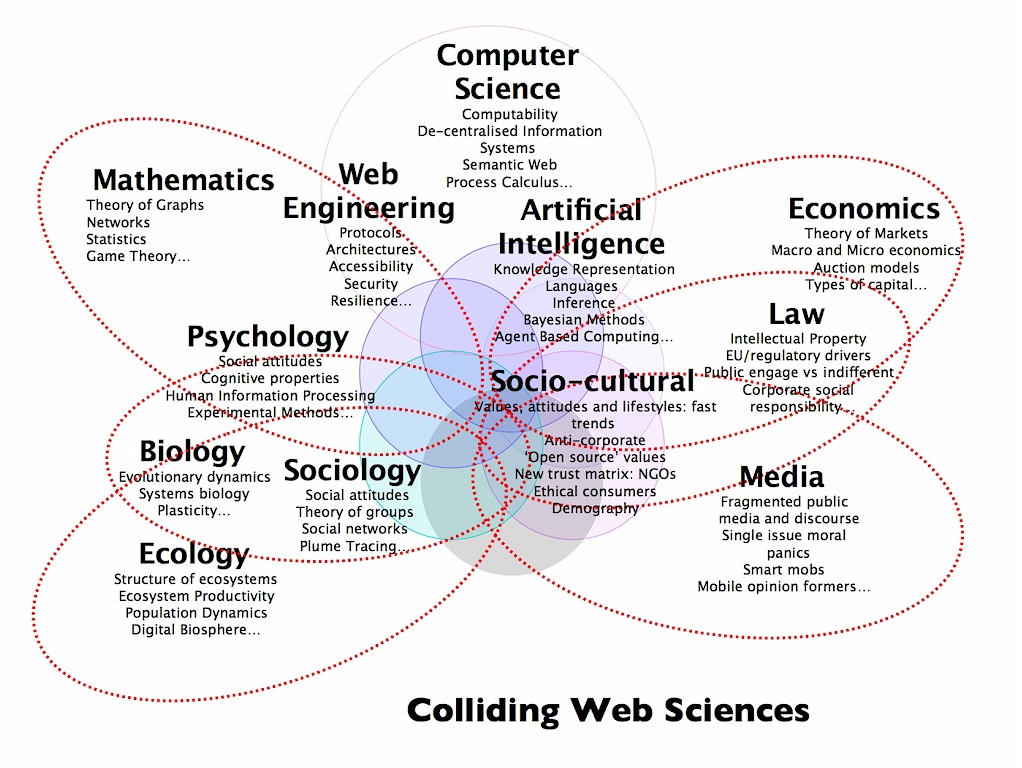
the World Wide Web was established less than two decades ago, but has an incredible impact on many people's life, including mine. tim berners lee and other leaders of the Web scene launched the "Web Science Research Initiative" (WSRI) about two years ago suggesting that the phenomena of the Web should be investigated and researched with scientific methods. at the first glance, the Web is just a man-made "thing", basically a collection of protocols and formalisms about how computers should exchange and present information. but if we take a closer look, we discover that the Web encompasses many different sciences including not only technical issues such as computer science and mathematics, but also economics, law, sociology, psychology and even biology. the image below shows the various disciplines involved and what they contribute to what is now called "Web science":
(click on the image for an enlargement)what is the motivation and what are the goals of Web science ? one of the goals is: we want to understand what the Web is. of course we know the principals (protocols etc.) since they are well defined. however, we don't necessarily understand the impact and the consequences to their full extend. the Web developed over the years and a lot of unexpected things happened - some are considered good, others bad. once we understand the basic driving factors, we may use our knowledge to engineer the Web's future to ensure its benefits for everyone.
the workshop was divided into 4 full papers and 11 rather short position papers. all the papers are available as PDFs, see references below. it was widely agreed that Web science has to be a multi-discipline approach. some presented research about the history and the growth of the Web, others suggested areas to be researched.
the presentation i liked best was given by erik wilde, a former member of the ETH zürich. it was not only the enthusiasm and agility in his presentation (see picture below), but i also liked his plea for a "plain Web" driven by evolution rather than revolution.
at the end of the workshop, we received a very interesting book titled "A Framework for Web Science", written by tim berners lee, wendy hall, james a. hendler, kieron o'hara, nigel shadbolt and daniel j. weitzner. it is not very easy to read, but extremely informative. at the beginning, it lists a number of factors that are believed are the keys to the tremendous success of the Web. they include the use of widely known and established technologies such as DNS (Domain Name System) and TCP/IP (Transport Control Protocol/Internet Protocol) plus the fact that the linking mechanism allows broken links by definition. in addition, HTML was simple enough to be understood and used not only by scientists, but also by almost anyone capable of using a computer.
references:
- papers as PDF in order of presentation:
- The Web Ecology (full paper)
- Quantitative Analysis of User-Generated Content on the Web (full paper)
- The Plain Web (erik wilde)
- Active: An Essential Nature of the (Future) Web ?
- The Massive Knowledge Web
- A Model for Universal Usability on the Web
- Economic sense of Metcalfe’s Law
- The Future of Digital Music in the Peer-to-Peer Web Position Paper
- A Method for Measuring the Evolution of a Topic on the Web – The Case of “Informetrics” (full paper)
- Values, Youngsters, and the Future Web (full paper)
- The Metadata is the Message
- A Web more Geospatial: Insights into the Location Inside
- The Semiotic Web: Don’t forget the user amongst all the semantics
- eMOTE: electronic Mutual Online Teaching Environment
- Web Evolution and its Importance for Supporting Research Arguments in Web Accessibility
- WSRI (Web Science Research Initiative): webscience.org
- program: webscience.org/events/www2008
- abstracts:journal.webscience.org/31/
i had one more day to explore beijing after the conference. this time, it was sunny and dry. together with erik wilde (formerly a student and employee at the ETH zürich and now a fellow of berkeley university in san francisco) and cesare pautasso (also a formerly student at the ETH zürich and now a professor at the Università della Svizzera italiana in lugano), i strolled through the forbidden city and the surrounding area.
great hall of the people
national grand theater
inside the forbidden city
dragon at the dragon wallmuch more pictures are available at my WWW2008 gallery.
in the late afternoon, we split up and i walked all the way back to the hotel (approximately 12 km). later, i took the taxi to the airport and left beijing five minutes before midnight.
Please check out this other trip report:
- trip report by roberto mazzoni (uni ZH)
the series of Web conferences started in spring 1994 with WWW1 held at CERN near geneva, switzerland. in fall 1994, there was a second conference in chicago, USA. because they stated that there will be two conferences each year, one in europe and one in the US, i did not attend WWW2. but at WWW3 in darmstadt, germany, they announced that in the future, there will be only one conference per year. i managed to convince my boss, that i should attend WWW4 in boston, even if i was already in darmstadt and from then on, i did attend every Web conference up to today. the table below lists all conferences and provides links to my trip reports as well as links to the official conference website where applicable.
no logo
(link to my trip report)year conference location country number of attendees* 1 1994 WWW1 geneva switzerland (CH) 380 2 1994 WWW2 chicago USA 750 3 1995 WWW3 darmstadt germany (D) 1075 4 1995 WWW4 boston USA 2000 5 1996 WWW5 paris france (F) 1452 6 1997 WWW6 santa clara USA 2000 7 1998 WWW7 brisbane australia (AUS) 1100 8 1999 WWW8 toronto canada (CAN) 1200 9 2000 WWW9 amsterdam netherlands (NL) 1400 10 2001 WWW10 hongkong hongkong (HK) 1220 11 2002 WWW2002 honolulu USA 900 12 2003 WWW2003 budapest hungry (H) 850 13 2004 WWW2004 new york USA 1000 14 2005 WWW2005 chiba japan (J) 900 15 2006 WWW2006 edinburgh scotland (UK) 1124 16 2007 WWW2007 banff canada (CA) 940 17 2008 WWW2008 beijing china (CN) 875 *) note: it is very difficult to get an accurate value for the number of attendees. the numbers are either based on the printed list of attendees where available, on the statement made by the organizers or on my own observations. the number for WWW2 is just an estimation because i missed that conference and i didn't find any numbers on the web.
this trip report was written on a Dell Latitude D820 notebook with Softquad HoTMetaL. this document is supposed to be HTML V4.0 compliant.