
Roland P. Wooster and Marc Abrams
Network Research Group, Computer Science Department, Virginia Tech
Blacksburg, VA 24061-0106
roland@csgrad.cs.v.edu, abrams@vt.edu
Do users wait less if proxy caches incorporate estimates of the current network conditions into document replacement algorithms? To answer this, we explore two new caching algorithms: (1) keep in the cache documents that take the longest to retrieve; and (2) use a hybrid of several factors, trying to keep in the cache documents from servers that take a long time to connect to, that must be loaded over the slowest Internet links, that have been referenced the most frequently, and that are small. The algorithms work by estimating the Web page download delays or proxy-to-Web server bandwidth using recent page fetches. The new algorithms are compared to the best three existing policies- LRU, LFU, and SIZE- using three measures- user response time and ability to minimize Web server loads and network bandwidth consumed- on workloads from Virginia Tech and Boston University.
Users don't like to wait to load Web pages into their browsers. The Graphic, Visualization, & Usability Center's (GVU) 6th WWW User Survey (run from October through November 1996) reports that "speed continues to be the number one problem of Web users (76.55%), and has been since the Fourth Survey when the question was first introduced." For example, the survey asked "how often people surf without images being loaded for each page automatically," and found that "as one might expect due to the slow transoceanic connection between US and Europe, more Europeans turn image loading off."
Caching, which migrates documents through the Internet closer to users, is one way to help reduce load times. Caches store copies of documents. At certain times one or more documents in a cache must be selected for removal. This might happen when the space consumed by cached documents reaches a certain threshold of the total available cache space, or on a cache miss when the requested document exceeds the free space in the cache. A removal algorithm makes this selection. A removal algorithm can optimize one of several measures:
Although the three are related, optimizing one measure one may not optimize another [ARLI96]. The GVU survey is concerned with the third, yet almost all works on removal algorithms to date [ABRA95,ARLI96,WILL96 and references therein] directly address only the first two. Bolot and Hoschka is the exception, explicitly addressing the third: "Surprisingly ... no Web cache algorithm we are aware of takes as [an] input parameter the time it took to retrieve a remote document .... Yet it seems natural that a decision to discard from the cache a document retrieved from a far out (in terms of network latency) site should be taken with greater care than the decision to discard a document retrieved from a closer site, all the more so since the time required to retrieve documents from different sites can be considerably different one from the other..." [BOLO96]. In fact, a replacement algorithm that incorporates retrieval time would appear to directly address the delay users experience in accessing sites over slow or busy links, such as the U.S./European example given earlier.
Bolot and Hoschka offered limited empirical evidence for their claim, using just one trace of Web references. More importantly, they only simulate the trace, which permitted evaluation of just miss ratio (corresponding to minimizing Web server hits) and a weighted miss ratio, but not the GVU survey problem: how long did users wait for documents?
This paper directly addresses the user waiting time question. Because simulation cannot accurately assess document retrieval delays, we instead report measurements of download times (and other measures) made from modified production proxy caches used on a university campus. Furthermore, our production cache actually runs four replacement algorithms simultaneously (least recently used [LRU], least frequently used [LFU], document size [SIZE], and an algorithm proposed here). We can directly compare the results from all policies in real time on the same workload. Besides measuring traffic at two proxies within our university, we developed a method to "replay" trace files to measure proxy performance for traffic from Boston University and one of America Online's proxies. We found that replacement based on download time only usually works worse than LRU, LFU, and SIZE. However, replacement that estimates the bandwidth of the connection to the server and incorporates document size and access frequency was the most robust in our study, in that most of the time it either gave the best performance on all measures (optimizing network bandwidth, server load, and download time), or its performance was statistically indistinguishable from the best replacement policy (at a 90% confidence level).
A cache may be used within a Web browser, within the network itself (typically in proxy servers, which might be located between a department and an enterprise network, between an enterprise network and the Internet, or on a link out of a country), and at servers. Whenever a Web document is requested from a browser, proxy, or server cache, the cache directory is checked to see if a copy of the document is contained in the cache. If it is (called a cache hit), the cached copy is returned; otherwise (a cache miss) the document is requested from some other entity (e.g., another cache or the origin server).
Caching has limitations. The only way to guarantee that a cached document is consistent with the version on the origin server is to contact the server, which means users must accept some probability of inconsistent documents or pay a performance penalty. (Algorithms to expire cached copies are not considered in this paper.) Some classes of documents usually cannot be cached: script or application generated documents and pay-per-view documents.
The type of traffic that a browser, a proxy, and a server cache must manage is different. A browser cache responds to exactly one client, but caches documents from anywhere in the world (but usually not local documents). So browser caching is effective because a client tends to revisit the same documents with some frequency. The normal use of a proxy cache (sometimes called a forward proxy) is to respond to multiple clients, but only a limited number of clients with some relationship (e.g., part of the same domain or organization).We would expect some similarity in browsing behavior from those clients. The proxy cache, like the browser cache, caches worldwide documents. There are also reverse proxy caches, that respond to HTTP requests from outside an organization, in which case the proxy serves a limited document set (e.g., only documents within an enterprise or a department) to worldwide clients. Finally, a server cache responds to worldwide clients, but manages a relatively small number of documents (just those on the server). This paper addresses forward proxy caches, and considers caching of HTTP traffic only.
The evidence in Williams et al [WILL96] is that forward proxies can minimize server loads by using SIZE as a removal algorithm, minimize wasted network bandwidth by using LFU, and achieve hit rates in the 20-50% range. The hit rate range is not higher because proxies get the traffic left over from browser caches. Little published information exists on reverse proxies, but one workload in [WILL96] found a 90% hit rate for a network containing a popular Web server. Also few published results exist on removal algorithms for browser caches. However, most browser users recognize the value of such caches. Cache hit rates up to the 80 to 90% range are possible for modest size server caches with policies like LRU and LFU [ARLI96].
A number of issues arise in cache design: which protocols to cache (e.g., HTTP, FTP, gopher), which document types to cache (e.g., video, text), whether to limit the document size range that is cached, when to expire cached copies, and whether to remove documents periodically (when the cached documents reach a certain percentage of available space), or only upon demand (when a document larger than the free space arrives). Another issue is the use of multiple caches, so that a miss from one cache is dispatched to one or more other caches (e.g., by multicast [MALP95]). Caching represents one of the major differences between HTTP 1.1 and HTTP 1.0.
We consider caching algorithms that estimate the delay associated with Web servers world-wide, and use that delay to keep in the cache either documents with a high refetch latency or documents that must be retrieved over links with low bandwidth. The estimation process is motivated by TCP's round trip time (RTT) estimation algorithm, which tries to adapt its retransmission timer to current network conditions. We'll use a similar algorithm to adapt the cache to current network conditions. We compare two alternate algorithms
The first algorithm is directly motivated by the quotation from the GVU survey at the start of the paper: estimate the time required to download a document, and then replace the document with the smallest download time. One way to do this is to keep track of how long it took to download documents in the past, and then apply some function to combine (e.g., smooth) these time samples to form an estimate of how long it will take to download the document again in the future. But this has a problem: we must keep track of past download times for many documents- even documents that have been removed (so that if they are reloaded again, we can later estimate download time). Hundreds of thousands of documents might pass through a busy proxy, so keeping a per-document estimate is probably not practical. An alternative is to keep statistics of past downloads on a per-server basis, rather than a per-document basis. This requires less storage, and it has an added benefit: a proxy can now estimate download times for documents that it never retrieved, if it fetched other documents from the same server in the past.
Because a server returns documents of differing sizes, we do not tabulate download time explicitly. Download time is equal to the sum of the time to establish a connection to a server and the time to transmit the bytes of the document. The transmission time is the product of the connection time and the file size divided by the bandwidth (e.g., in bytes per time unit). Therefore we keep an estimate of connection time and bandwidth to Web servers contacted in the past.
The estimation is done in a manner similar to RTT estimation in TCP [STEV96]. For each server j, the proxy maintains an estimated latency (time) to open a connection to the server, denoted clatj, and estimated bandwidth of the connection (in bytes/second), denoted cbwj. Whenever a new document is received from the server, the connection establishment latency and bandwidth for that document are measured (let these samples be denoted by sclat and scbw, respectively), the estimates are updated as follows:
clatj = (1-ALPHA) clatj + ALPHA sclat
cbwj = (1-ALPHA) cbwj + ALPHA scbw.
ALPHA is a smoothing constant, set to 1/8 as it is in the TCP smoothed estimation of RTT.
Let ser(i) denote the server on which document i resides, and si denote the document's size Cache replacement algorithm LAT selects for replacement the document i with the smallest download time estimate, denoted di:
di = clatser(i) + si/cbwser(i).
One detail remains: A proxy runs at the application layer of a network protocol stack, and therefore would not be able to obtain the connection latency samples sclat. Therefore the following heuristic is used to estimate connection latency. A constant CONN is chosen (e.g., 2Kbytes). Every document that the proxy receives whose size is less than CONN is used as an estimate of connection latency sclat. Every document whose size exceeds CONN is used as a bandwidth sample as follows: scbw is the download time of the document minus the current value of clatj. See [WOOS96] for details.
Our second removal algorithm, HYB, is motivated by Bolot and Hoschka's algorithm. HYB is a hybrid of several factors, considering not only download time but also number of references to a document and document size. HYB selects for replacement the document i with the lowest value value of the following expression:
(clatser(i) + WB/cbwser(i))(nrefi** WN)/ si,
where nrefi is the number of references to document i since it last entered the cache, si is the size in bytes of document i, and WB and WN are constants that set the relative importance of the variables cbwser(i) and nrefj, respectively. Therefore a document is not likely to be removed if the expression above is large, which would occur if the document resides on a server that takes a long time to connect to (i.e., large clatser(i)) and is connected via a low bandwidth link (i.e., small cbwser(i)), if the document has been referenced many times in the past (i.e., large nrefi), and if the document size is small (i.e., small si). As for the weights, as WN approaches zero, document size (si) becomes more important than number of references (nrefi). As WB is increased, the importance of clatser(i) relative to cbwser(i) is increased.
Bolot and Hoschka propose replacing first the document i that has the smallest value of W1rtti + W2 si + (W3 + W4 si)/ti, where ti is the "time since the document was last referenced," rtti is the "time it took to retrieve the document," and W1, W2, W3, W4 are weights. Differences between our HYB algorithm and the Bolot-Hoschka algorithm are summarized below:
We collect three performance measures:
We use five workloads in this study (VT-CS1,VT-CS2, VT-CS3, BU, and VT-LIB), summarized in Table 1. Note that the number of users was much greater than the number of client hosts in workload BU and VT-LIB because those hosts are public computers that anyone can sit down to use. In the VT-CS workloads, several client hosts were multi-user machines, one of which supports at least 40 users of the proxy. Further information on the workloads, such as the percentage of references and bytes transferred by file type, is in [WOOS96, Ch. 5].
|
Workload |
Source |
Number |
Number Server Hosts |
Observation Period |
No. Docs |
MBytes Transferred |
|---|---|---|---|---|---|---|
|
VT-CS1 |
Virginia Tech, |
62 |
3100 |
4 weeks, |
110,624 |
937.46 |
|
VT-CS2 |
178 |
3000 |
2 weeks, 10/31 to 11/14/96 |
89,338 |
732.56 |
|
|
VT-CS3 |
170 |
3100 |
2 weeks, 11/15 to 12/3/96 |
84,816 |
732.35 |
|
|
BU |
Boston University, |
30 |
530 |
4 months, |
47,403 |
96.12 |
|
VT-LIB |
Virginia Tech, |
34 |
1300 |
8 days, |
39,723 |
206.91 |
All experiments use a modified version of the Harvest cache [CHAN]. We modified the Harvest cache (version 1.4 patch level 3), which uses LRU, to also implement LFU, SIZE, LAT, and HYB. We can specify up to four of the algorithms to be run in parallel. In this parallel mode, a miss from any one algorithm results in the document being fetched from the server, so that we can measure, for each cache policy, all document download times.
The removal algorithm is invoked in the Harvest cache whenever the total size of cached documents exceeds a high water mark (set to 98% in our experiments). Harvest does not implement pure LRU. To minimize the time required to execute the removal algorithm, the Harvest cache sorts a set of N documents (rather than on all cached documents) on time of last document access. The M out of N with the largest access times are removed from the cache. We use the defaults of M=8 and N=256. We retain the same scheme of replacing M of N documents for LFU, SIZE, LAT, and HYB.
To minimize removal algorithm overhead, we use a hash-indexed array with overflow buckets to map server names to the values clatj and cbwj. Our implementation of LAT and HYB places no bound on the number of buckets and hence on the number of servers for which clatj, and cbwj are retained.
We use our modified Harvest cache in two modes: on-line and replay. In on-line mode, Web users in the Computer Science Department at Virginia Tech have the proxy fields in their Web browsers set to a Sun Sparc 10 with 64MB of RAM running Solaris 2.4 on which the modified Harvest cache runs in parallel the LRU, LFU, SIZE, and either the LAT or HYB policies. The cache reports the three performance measures (Time, HR, and WHR) for each hour of operation as well as a log that can later be used for replay experiments. The setting of time-to-live (TTL) parameters in the Harvest Cache are shown in Table 2.
In replay mode, a trace file of URLs collected earlier is read by an application developed in our group called WebJamma, which sends each URL in rapid succession to 4 parallel proxies. Because documents are sent in rapid succession, days of traffic can be simulated in a hours (45,000 to 85,000 URLs in 3 to 10 hours, depending on size of documents retrieved and proxy hit rates). Thus the time-to-live cache parameter were reduced by a factor of 50 from the values shown in Table 2. The proxies report Time, HR, and WHR every two minutes. We run replay experiments in the middle of the night to reduce interference from other network traffic. Replay mode is used with an RS 6000 equivalent to a model 7013-J40 (four PowerPC 604 processors at 112MHz), with 512MB of RAM and runs AIX 4.1.
Some initial experiments were done to select the disk cache size. Cache size is important to our measurements because too large a disk cache will result in few misses, and too small a disk cache may represent a degenerate, unrealistic case of mostly misses. Based on preliminary tests, we used a 50Mbyte cache for the VT-CS and VT-LIB traces, and a 10 MByte cache for the BU trace. The sizes are about 9% to 11% of the size needed for no replacements to occur in the VT-CS workloads, 36% in the VT-LIB workload, and 26% in the BU workload.
We perform four experiments (Tables 3 and 4). Experiments 1 and 2 compare the LAT and HYB algorithms from Section 3 to competing algorithms using an online proxy. HYB will turn out to be superior to LAT, and so Experiments 3 and 4 further investigate HYB. First Experiment 3 examines the effect of workload, by replaying more diverse workloads than Experiments 1 and 2. Next Experiment 4 uses a 23-1r fractional factorial experiment design [JAIN, Ch. 19] to investigate whether the settings of the weights in the HYB algorithm affect the performance measures. Each successive set of 5000 URLs in a trace file are used as a replica in Experiment 4.
| Experiment | Workload | Mode | Replacement Policies | Parameter Values |
|---|---|---|---|---|
|
1 |
VT-CS1 |
online |
LAT,LFU,LRU,SIZE |
N/A |
|
2 |
VT-CS2,VT-CS3 | online | HYB,LFU,LRU,SIZE |
WB=8Kb,WN=0.9Kb,CONN=2Kb |
|
3 |
VT-CS2,BU,VT-LIB | replay | HYB,LFU,LRU,SIZE |
WB=8Kb,WN=0.9Kb,CONN=2Kb |
|
4 |
VT-CS2,BU,VT-LIB | replay |
HYB |
See Table 4 |
| Trial |
WB |
WN |
CONN |
|---|---|---|---|
|
1 |
8 Kbyte |
0.9 |
2 Kbyte |
|
2 |
16 Kbyte |
0.9 |
0.5 Kbyte |
|
3 |
8 Kbyte |
1.1 |
0.5 Kbyte |
|
4 |
16 Kbyte |
1.1 |
2 Kbyte |
During a four-week measurement interval, users in workload VT-CS1 accessed a Harvest cache that ran in parallel the LAT, LFU, LRU, and SIZE removal algorithms. Both factors in the experiment -- removal policy and workload, more specifically the hour at which the log file was recorded, produced a statistically significant effect on all three measures. The results show that a removal algorithm that simply tries to minimize the estimated download time of a document achieves worse performance in all three measures-- Time, HR, and WHR -- than the other three algorithms! LRU and SIZE achieved the same, smallest mean value of Time. (Means are averaged over the time from the first cache miss until the end of the four weeks.) SIZE gave the maximum mean HR, 37.4%, while LAT gave the worst value (35.4%). LFU maximized mean WHR (33.8%), while LAT gave the worst value (32.3%).
The mean values do not give any sense of the variability of the measures over time; one example of this is the graph of download time as a function of wall clock time, shown in Figure 1. The graph is transformed in two ways [WOOS96, Ch. 5]. First, recall that in onine mode the proxy reports the value of Time once every hour, so the x-axis has a scale of hours. We smooth the data by averaging the Time value for each hour with the 23 preceding values. (Without smoothing, the curves would jump up and down so much that it would be impossible to distinguish them from each other.) Second, to make differences between the policies more visible, rather than plotting the actual times on the y-axis, we divide the difference between the value of Time for each hour and the mean of the values of Time for all four policies by the mean of the values of Time for all four policies. In Figure 1 Time for LAT is almost always above y=0, and hence worse than average, while SIZE is almost always the lowest curve (yielding lowest download times), but LRU occasionally yields smaller download times than SIZE.
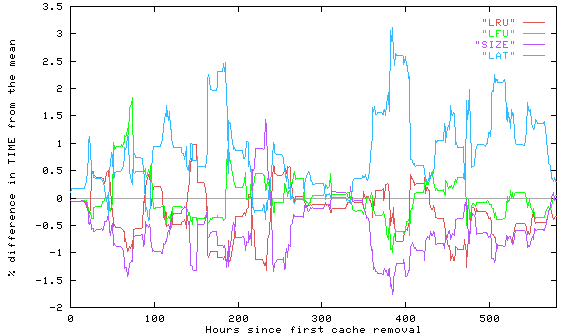
Figure 1. Variation of download time, workload VT-CS1, Experiment 1. [Larger graph]
The next experiment subjects users in the VT-CS2 and VT-CS3 workloads to the HYB removal policy, along with LFU, LFU, and SIZE. Two workloads were used to vary weights, but both workloads yielded similar results (see [WOOS96, Ch. 8] for details). HYB achieved the lowest mean Time and HR (2.88 sec. and 26.8%, respectively, compared to the worst values of 2.93 sec and 24.6% for LRU). Figure 2 shows the time-dependent comparison of download time for the four policies. HYB has smallest download time until the end, when LFU is smaller. Also download times for SIZE are poor, and LRU almost as poor. As for the other measure, WHR, HYB ranked in the middle.
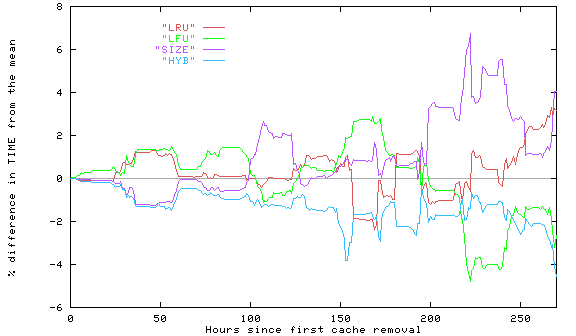
Figure 2: Variation of download time, workload VT-CS2, Experiment 2. [Larger graph]
|
HR |
WHR |
Time |
|||||
|---|---|---|---|---|---|---|---|
|
Better |
Worse | Better | Worse | Better | Worse | ||
|
Workload |
VT-CS2 | SIZE * HYB * |
LFU * LRU * |
LRU * LFU * |
SIZE * HYB * |
HYB * SIZE |
LFU * LRU |
| BU | SIZE * HYB |
LFU * LRU |
LRU HYB |
SIZE * LFU |
SIZE * HYB |
LRU * LFU |
|
| VT-LIB | SIZE * HYB * |
LFU * LRU |
LRU HYB LFU |
SIZE * | HYB SIZE |
LFU LRU |
|
In Experiment 3, we again compare HYB to LFU, LRU, and SIZE, but on a more diverse set of workloads: one trace file from the preceding online experiments (e.g., VT-CS2) along with workloads BU and VT-LIB. The replay mode is used because these trace files were all recorded in the past. Table 5 summarizes the relative performance of the algorithms, and shows that HYB ranks as better than the mean for eight out of nine cases.
In Experiment 4 we assess whether the settings of the weights WB, WN, and CONN in the formula for the HYB removal algorithm have much effect on the performance measures. We analyze the results by allocation of variation [JAIN, Ch. 18]. The value of CONN explained almost no variation in any workload. In workload VT-CS2 the exponent for WN, the number of references since last loading a document, explains as much as 11% of the variation in HR and 14% of the variation in WHR. None of the weights explains more than 3% of the variation for Time, so there is no evidence that the weights are important to Time. In workload BU WN explained up to a quarter of the variation in HR, no weight appeared to affect WHR, and WB slightly (e.g., 7%) affected Time. Workload VT-LIB was very different- both WB and WN explained up to 28% and 13% of the variation in HR, WB explained up to 13% in WHR, and WN explained up to 20% in Time. To summarize, HR is always sensitive to weight WB, Time is rarely sensitive to the weights, and WHR is sensitive to WB and sometimes WN.
We set out to investigate whether users wait less time to download Web documents if proxy caches incorporate estimates of the current network conditions into document replacement algorithms. In particular, we explored algorithm LAT, which estimates download time and replaces documents with shortest download time, and algorithm HYB, which combines estimates of the connection time of a server and the network bandwidth that would be achieved to the server with document size and number of document accesses since the document entered the cache.
Experiment 1 suggests that basing replacement only on estimated download time (algorithm LAT) is a bad idea. (We say "suggests" because we do not know how much of the bad performance can be attributed to the error in our download time estimation algorithm, the Harvest cache's implementation that replaces 8 out of 256 documents, and the use of download times.)
But using download rate along with other factors (algorithm HYB) appears successful. In Experiment 2, computation of a 90% confidence interval for the mean values of all three performance measures for both workloads, VT-CS2 and VT-CS3, shows that HYB and SIZE are superior for HR, LFU and LRU for WHR, and HYB alone for TIME. Experiment 3 shows that HYB is a robust policy: its performance was better than the mean of the four algorithms in all but one case. (In contrast, SIZE was best in five, LRU in three, and LFU in just two of the nine.) This again suggests that HYB meets our original objective.
We investigated five workloads from two universities. Do the results apply to non-educational settings? We also ran the production proxy in replay mode with a 120,000 reference proxy server trace from America Online, removing any references to servers in domain aol.com. The results were inconclusive. This may be due to the fact that the trace file represented several minutes of traffic from a proxy in San Francisco, while we replayed the trace on a proxy in the opposite side of the United States. Hence "local" accesses to San Francisco users would be "remote" accesses during our replay, and this might have biased the workload. Investigation into this workload is continuing.
Some new directions for cache research are apparent:
The modifications for Harvest proxy cache (version 1.4 patch level 3) that permit use of the four replacement algorithms LRU, LFU, SIZE, and HYB as well as the WebJamma application are available from http://www.cs.vt.edu/nrg/.
Edward A. Fox suggested running multiple replacement algorithms in parallel. Tommy Johnson implemented WebJamma. Anawat Chankhunthod from USC answered questions on Harvest. Dan Aronson provided the America Online traces. Andy Wick helped keep the Sun proxy machine running. Members of the VT NRG provided helpful comments on the manuscript. National Science Foundation grant NCR-9627922 partially supported this work.
[ABRA95] Marc Abrams, Charles Standridge, Ghaleb Abdulla, Stephen Williams, and Edward A. Fox, "Caching Proxies: Limitations and Potentials," 4th Inter. World Wide Web Conference, Boston, Dec. 1995. <URL http://www.w3.org/pub/WWW/Journal/1/abrams.155/paper/155.html>
[ARLI96] Martin F. Arlitt and Carey L. Williamson, "Web Server Workload Characterization: The Search for Invariants," ACM SIGMETRICS 96, Philadelphia, April 1996.
[BOLO96] Jean-Chrysostome Bolot, Philipp Hoschka, "Performance Engineering of the World Wide Web," WWW Journal 1, (3), 185-195, Summer 1996. <URL: http://www.w3.org/pub/WWW/Journal/3/s3.bolot.html>.
[CHAN] Anawat Chankhuthod, Peter Danzig, Chuck Neerdaels, Michael Schwartz, and Kurt Worrel, A Hierarchical Internet Object Cache, USC, Univ. of Colorado, Bolder (5 Dec. 1996), <URL ftp://ftp.cs.colorado.edu/pub/cs/techreports/schwartz/HarvestCache.ps.Z>.
[JAIN] Raj Jain, The Art of Computer Systems Performance Analysis, John Wiley & Sons, 1991.
[MALP95] Radhika Malpani, Jacob Lorch, and David Berger, "Making World Wide Web Caching Servers Cooperate," 4th Inter. World Wide Web Conference, Boston, Dec. 1995. <URL http://www.w3.org/pub/WWW/Journal/1/lorch.059/paper/059.html>
[PAXS96] Vern Paxson, "End-to-End Routing Behavior in the Internet," ACM SIGCOMM96, Stanford, CA, Aug. 1996, 25-38. <URL http://www.acm.org/sigs/sigcomm/sigcomm96/papers/paxson.html>
[STEV96] W. Richard Stevens, TCP/IP Illustrated, Vol. 3, Addison-Wesley,1996, Section 10.5.
[WILL96] Stephen Williams, Marc Abrams, Charles Standridge, Ghaleb Abdulla, and Edward A. Fox, "Removal Algorithms in Network Caches for World Wide Web Documents," ACM SIGCOMM 96, Stanford, CA, Aug. 1996, 293-305. <URL http://ei.cs.vt.edu/~succeed/96sigcomm/>
[WOOS96] Roland Wooster, Optimizing Response Time, Rather than Hit Rates, of WWW Proxy Caches, M. S. thesis, Computer Science Dept., Virginia Tech, Dec. 1996. <URL http://scholar.lib.vt.edu/theses/materials/public/etd-34131420119653540/etd-title.html>.
![[Larger graph]](1_BW.gif){kind=link}
![[Larger graph]](2_BW.gif){kind=link}