Noritaka OSAWA and Toshitsugu YUBA
Graduate School of Information Systems
The University of Electro-Communications
1-5-1 Chofugaoka, Chofu-shi, Tokyo 182, Japan
{osawa,yuba}@is.uec.ac.jp
This paper proposes and evaluates a character or symbol code system called EPICS for internationalization of the WWW. EPICS integrates a variable-length coding system using 16-bit units and a smart virtual machine that executes inputs as instructions and is dynamically customizable. EPICS enhances the interchangeability of data. The variable-length coding system provides a huge code space. This huge space can include not only standardized code sets but also user-specific codes. The smart virtual machine allows us to define and modify instructions during runtime. Customization makes it possible for a sender to express his intentions in data and for a receiver to process the data depending on his needs. This customization also enables one to send compressed data and decompression programs incrementally and efficiently without predefined decompression algorithms. The length of an English document encoded in EPICS is shorter than that in UCS-2. The length of a Japanese and English document in EPICS is shorter than that in UTF-8.
Use of the World Wide Web (WWW) is becoming wide spread. The WWW is used by people in a lot of nations and the number of WWW users is growing rapidly. Therefore multilingual processing has become more important. In addition to scientists and engineers, a lot of people use it as a media for exchanging information. Business users use the WWW on not only the Internet but also intranets. On intranets, company-specific or personal symbols are needed in order to communicate with each other efficiently. It is desirable that those symbols can be exchanged with people outside intranets. There are problems to be solved.
Unicode[16] and ISO 10646[6] are expected to promote the handling of a lot of characters that have been standardized. However, we think that static character code sets like Unicode are not sufficient for internationalization of the WWW and the multilingual WWW. Existing character code standards intentionally avoid the specific handling of private or personal characters or symbols. They specify only code regions of private characters. Thus existing standards do not promote the international circulation of data to support humane studies and interdisciplinary studies which use user-specific symbols. However more and more researchers in those fields of study are using the WWW. Therefore a new framework to process and exchange user-specific symbols easily is needed since standardization of user-specific symbols is impractical. The framework should not require centralized registration. We chose a method that decreases the possibility of overlapping code points by using a huge code space.
This paper proposes a dynamic symbol (character) code system capable of handling general symbols in addition to currently used characters. It is called EPICS (Efficient, Programmable and Interchangeable Code System). EPICS is programmable and is also a universal symbol code system that enables us to exchange data efficiently and flexibly. Programmability of EPICS enables us to exchange compressed WWW data without a special decompression program. It will be shown that EPICS can be more efficient than UCS-2 in English text and can be as efficient as UTF-8 in text which includes Japanese and English. Not only characters in plain text but also tags in rich text can be included in EPICS. In this paper, a character and a symbol represent the same thing.
EPICS is a symbol (or character) code system that integrates a variable-length (multi-byte) code system called EPIC (Extensible Process-Internal Code)[12], whose unit is 16 bits, and a smart virtual machine[14] called EpicVM.
EPIC was originally designed to be used in an easy-to-use programming language that handles multilingual characters. When the programming language interpreter system was developed, 16 bit wide characters were not as popular. Therefore EPIC was designed for internal use. However, 16 bit wide characters are becoming popular because of the wide character (wchat_t) in the C programming language [7] and Unicode. Although a symbol in EPICS is a multi-byte character, EPICS can be used efficiently not only as codes for exchange but also internal processing because of the encoding design of symbols.
EpicVM is a smart virtual machine whose instructions are customizable dynamically. When we proposed PivotVM[14], we categorized it into a smart virtual machine. A smart virtual machine is a generic term and does not represent a specific virtual machine.
EPICS provides a framework where not only standardized character code sets but also symbols for research and user-specific symbols can be included without overlapping code points. Various types of symbol processing like sorting and searching can be done using a general software tool in the framework. For example, if one writes a text searching program for EPICS, the program can handle both standardized symbols and user-specific symbols. Special tools for ancient and user-specific symbols are not needed. EPICS reduces the work necessary for making software tools for symbol processing.
EPICS pays serious attention to both intentions of an information sender and requirements of a receiver. The sender can use arbitrary symbols and specify alternatives for these arbitrary symbols in EPICS. In other words, a sender can send his intentions to a receiver. The receiver can normalize data depending on his needs. The receiver may use alternative symbols that are specified by a sender, or may ignore the alternatives and map them to other symbols. We think normalization depends on the users' requirements. A single canonical mapping as in Unicode is not suitable in all situations.
EPICS allows a user to define a code sequence at a code point. When a symbol is inputted, a specified code sequence is invoked. For example, if a user specifies normalization of external user-specific symbols, the inputted external symbols are converted to normalized symbols. Not only mapping of 1 symbol to 1 symbol but also mapping of 1 symbol to a string is possible. This function accomplishes naturally the expansion of compressed data using dictionary-based coding like the LZ78 algorithm[17] if a routine that generates a string is specified at a code point. EpicVM can not only expand a symbol code to a string but also support more general programming because it is a virtual machine. By utilizing EpicVM, symbol images, font images and so on can be defined and transferred.
A unit of EPICS is a 16 bit long or wide character. A wide character in the C programming language and Unicode is becoming more and more popular. Processing of 16 bit characters is not a problem now.
We refer to a unit of 16 bits as EPICU. The most significant bit is
BIT 16 in EPICU and the least significant bit is BIT 1. The two most significant
bits in a unit indicate if the unit is the head of a symbol or the tail
of it. If BIT 16 is 0 in an EPICU, the EPICU is the tail of a symbol. An
EPICU whose BIT 15 is 0 is the head of a symbol. If both BIT 16 and 15
of an EPICU are 0, the EPICU is a symbol itself. This coding makes locating
boundaries of a symbol easy and efficient. We show the format of EPICU
in Table 1. Table 2 shows character
formats composed of between 1 and 3 units. Figure 1
also shows extension methods of EPICS.
| MSB | LSB | |||||||||||||||
| BIT position | 16 | 15 | 14 | 13 | 12 | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
| Tail EPICU | 0 | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X |
| Head EPICU | X | 0 | X | X | X | X | X | X | X | X | X | X | X | X | X | X |

Figure 1: Relationship between Most Significant
Bits and Symbol Length.
If BIT 16 is 1, each point in EPICU has successive units. If BIT 16
is 0, there are no more units.
Locating boundaries of a character is important in editor and viewer programs. In multi-byte codes of ISO 2022, it may be impossible to distinguish whether a byte is the first byte or the last byte in a 2 byte code on the basis of only the data of the byte. Incremental confirmation is needed from a confirmed point in the worst case. In EPICS, a header unit, an intermediate unit or a tail unit can be easily distinguished on the basis of data of the unit alone.
EPICS pays attention to string matching. Existing string matching algorithms
can be naturally applied to data encoded in EPICS when a unit is 16 bits.
Special handling depending on the length of a code is not needed. Pattern
matching using regular expressions can also be applied easily where 16
bit data is one unit.
Some people who have made programs that handle ISO 2022 believe that the use of variable-length codes makes programming difficult. However, the main reason for the difficulty of handling ISO 2022 is not variable length but state management of ISO 2022 characters. Handling of ISO 2022 needs extra state management because a code point is multiplexed by different code sets. EPICS assigns different symbols to unique code points and thus does not require extra state management.
In the C++ programming language, 'a smart pointer' [15] helps C/C++ language programmers write programs that handle EPICS in the usual way. A smart pointer makes it possible to use EPICU in the C++ language like 'char' type in the C programming language. From our experiences when variable-length codes and smart pointers are used to make multilingual programming (script) language systems[12][13], handling of EPICS using smart pointers is as easy as that of fixed-length codes. In languages that do not allow pointer arithmetic, like the Java language[3], programmers do not need to be aware of the length of a character code.
Variable-length coding using 16-bit units makes a very huge code space available. A huge code space with variable-length coding makes overlapping of code points of user-specific symbols less likely. Even if a registry administration of symbols does not exist, the possibility of overlapping code points would be made sufficiently low by using a sufficiently long code value and an appropriate hashing function that determines the prefix part of a code value.
We do not think surrogate characters in Unicode expand a code space sufficiently. One million code points made by surrogate pairs are too few to keep user-specific symbols from overlapping and interchangeable without explicit coordination.
A symbol code space of EPICS can be divided into subspaces. There are standardized character set subspaces, EpicVM subspaces, user-specific subspaces and temporary use subspaces. Symbol code values composed of one or two EPICUs are used for standardized characters and EpicVM instructions. 3-EPICU symbols are reserved for future standardized characters. Symbol code values composed of 4 or more EPICUs can be utilized for user-specific or temporary symbols. However, we recommend the use of symbols whose length is 5- or more EPICU for user-specific symbols.
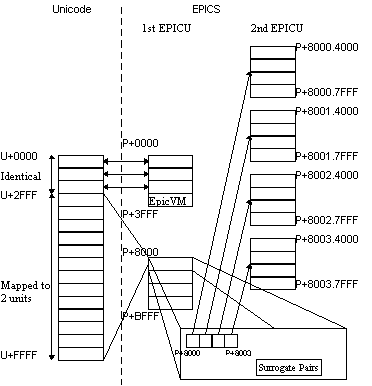
Following Unicode standard, the character code value of Unicode is represented by U+nnnn where nnnn is a four digit number in hexadecimal notation. A symbol code value of EPICS is represented by "P+" and 4-digit hexadecimal numbers with dots as separators. For example, an EPICS symbol composed of 1 EPICU is represented by P+nnnn, and a 2-EPICU symbol is represented by P+mmmm.nnnn.
Some parts of EPICS are based on Unicode. Lower code values of Unicode
are identical to code values of EPICS except unified CJK (Chinese, Japanese
and Korean) misc. characters. The relationship between Unicode and EPICS
is shown in Table 3 and Figure
2. For example, codes between U+0000 and U+2FFF correspond to codes
between P+0000 and P+2FFF respectively, and the code region between U+3000
and U+3FFF are mapped to P+8000.7000 and P+8000.7FFF.
| Unicode range | EPICS range |
| U+0000 -> U+2FFF | P+0000 -> P+2FFF |
| U+3000 -> U+3FFF | P+8000.7000 -> P+8000.7FFF |
| U+4000 -> U+7FFF | P+8001.4000 -> P+8001.7FFF |
| U+8000 -> U+BFFF | P+8002.4000 -> P+8002.7FFF |
| U+C000 -> U+D7FF | P+8003.4000 -> P+8003.57FF |
| Surrogate Pairs | P+9800.4C00 -> P+9B00.4FFF |
| U+E000 -> U+FFFD | P+8003.6000 -> P+8003.7FFD |
Character code sets registered at ECMA (European Computer Manufacturers'
Association) based on ISO 2022[5] are also mapped
into EPICS for compatibility. The value of a final character to designate
a coded character set is added to P+8100, and the result is used as the
prefix of a symbol. Examples are shown in Table 4.
Although ISO 2022 based characters can be included in EPICS strings, we
recommend the use of mapped versions of Unicode characters instead of mapped
versions of ISO 2022 based characters unless special intentions are involved.
| ISO 2022 | EPICS | |
| Character Set | Final Character | prefix |
| JIS X 0208 | 4/2 | P+8142 |
| CNS 11634-1 | 4/7 | P+8147 |
The code region between P+3000 and P+3FFF is used and reserved for EpicVM instructions and integer representation. EpicVM will be described in the next section.
The code region between P+3000 and P+3CFF is available for user-defined EpicVM instructions. Not only a code point in that region but also a code point in other unused regions can be used for a user-defined EpicVM instruction, however, unassigned code points of 1-EPICU symbol exist only in the above code region. The code region between P+3D00 and P+3DFF is used for exception handlers. The code region between P+3E00 and P+3EFF is used for predefined EpicVM instructions.
The code region between P+3F00 and P+3FFF represents the range of integers
between -128 and 127. Integer representation can be extended to hold a
larger value based on Table 5 and Table
6.
| Integer | EPICS range |
| 8-bit signed integer (8 bits) | P+3F00 -> P+3F7F |
| 22-bit signed integer (8+14 bits) | P+BF00.4000 -> P+BFFF.7FFF |
| 36-bit signed integer (8+14+14 bits) | P+BF00.C000.4000 -> P+BFFF.FFFF.7FFF |
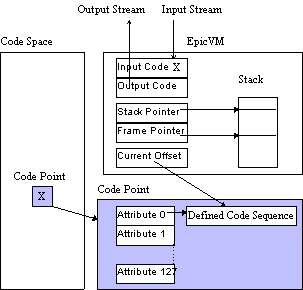
EpicVM is a smart virtual machine and is also a stack-based virtual machine. It is a new type of virtual machine. EpicVM decodes an input symbol as an instruction and executes it. EpicVM allows one to define or modify its instructions using instructions that have been defined during runtime. On the other hand, a usual virtual machine like Smalltalk bytecode machine[2] and Java virtual machine[8] have a fixed instruction set, and they do not allow one to change instructions dynamically.
The internal structures of EpicVM are shown in Figure 3. EpicVM has a small number of registers. They are an input code register, an output code register, a stack pointer, a frame pointer and a current offset pointer. EpicVM has a data stack that a program manipulates. A unit on the stack is a symbol whose length is variable. This is different from other usual stack-based machines.
Each code point has a maximum of 128 attributes. Each attribute can
contain a symbol or a code sequence (a routine). Attribute 0 of a symbol
is usually used to store a code sequence to be invoked when the symbol
is inputted.
EpicVM allows one to define a sequence of program codes at a code point. Jumps in the sequence are restricted to relative jumps. Absolute jumps cannot be made on EpicVM. The range of a relative jump must be within the defined sequence. If the target address of a jump is out of range, an exception is raised. An exception causes a corresponding exception handler to be invoked. An exception handler is defined at a fixed code point. A user can define the exception handler. Codes in a defined sequence may be instructions. In other words, instructions at a code point can call already defined instructions. This makes it possible to invoke instructions as functions or procedures without absolute jumps. When an instruction is invoked, registers are saved on a system stack. Saved values are restored to the registers when control returns from the instruction.
Most instructions of EpicVM are general in a stack-based virtual machine like Smalltalk-80 bytecode machine[2] or Java virtual machine[8]. However, instructions to define or modify an instruction or an attribute are specific to a smart virtual machine like EpicVM. Basic instructions includes add, sub, compare, branch, push-in, push-sp, push-fp, put, get, define and so on. Add, sub and compare represents addition, subtraction and comparison of two values on the stack respectively. branch is a relative-jump instruction. Push-in, push-sp and push-fp represent pushing the value of input register, stack pointer and frame pointer onto the stack respectively. Put and get are instructions to put and get an attribute at a code point respectively. Define is an instruction to define a new instruction. The general format to define a new symbol or instruction is as follows.
define <symbol-code-value> <length-in-byte> <code-string>
Let us define a string "EpicVM" at P+3120. The code sequence
to define the string is shown in Table 7. When P+3120
is inputted after this definition, the code P+3120 is expanded to "EpicVM".
When an input symbol is not defined as an instruction, a default handler is invoked conceptually. A default handler is defined at a fixed code point (P+3DFF). In plain EpicVM, code sequences are not defined at code points except for EpicVM instructions and integer representations. The default handler simply passes the input symbol to the output. Conceptually the default handler contains the following code sequence.
push-in pop-out
The sequence pushes an input symbol to the stack and pops the stack top to the output. In an actual implementation, the above code sequence does not need to be executed. If EpicVM knows that default handler is unchanged and an instruction sequence is not defined at an input symbol code point, it may simply output the input symbol. In other words, the overhead of default processing of an input symbol is only to check if the symbol is defined or not. The overhead is very low because the checking can be performed using hashing, or with computational complexity of O(1). EpicVM does not slow down the processing of usual symbols at a client.
Use of variable-length codes may make the number of bytes per symbol longer. Under such conditions, data compression by defining codes in EPICS increases the density of data. A sender can choose an appropriate algorithm for data contents if the sender sends a decompression program with compressed data. For example, a sender can send a decompression program like LZ78[17] at the head of data and follow it with compressed data.
It is also possible for a sender to gradually send program fragments and compressed data that uses defined codes, and for a receiver to expand compressed data gradually. This method requires code definitions to be sent explicitly and its compression ratio may be worse than that of LZ78 when a decompression program is installed on the receiver side. However, using this method, one can choose an algorithm suitable for data. One does not need to send a program at the head of transmission but it is necessary to send a code definition just before the code is invoked. This method reduces the latency of recovering symbols from compressed data on a stream-type communication which protocols on the WWW usually use. Moreover, when transmission is aborted, this method can reduce the transfer of unused parts of a decompression program.
We have made a prototype program which compresses data written in EPICS,
and produces compressed data and incremental decompression routines in
EPICS. A draft (epics.txt) of this paper
written in English and HTML, and a manuscript about PivotVM[14]
(pivot-vm-j.txt) that includes Japanese
and English are used as sample texts. Table 8 shows
the length of compressed text in EPICS and the length of the text in other
formats. The length of epics.txt
encoded in EPICS is shorter than the length of the text encoded in UCS-2.
The length of pivot-vm-j.txt in
EPICS is shorter than the length in UTF-8. Although EPICS supports a huge
code space, EPICS is efficient. It is possible to exchange encoded data
efficiently without special decompression programs. Our compression program
is a prototype. We think the compression ratio could be improved if the
compression program is better tuned.
It is difficult to standardize ancient characters which are not used in daily life but are being studied. Examples of ancient characters are hieroglyphs in Egypt and pictographs in China. If researchers have different opinions about identities of symbols, standardization is impossible or at least difficult. If most researchers are able to agree with each other in the future, ancient symbols will be standardized. However, researchers can not wait for full standardization. EPICS allows researchers who have different opinions about the identification of symbols to assign symbols to different code points and proceed with their studies. Once standardization has been completed, an EpicVM in EPICS can be customized to map old code points to standardized ones. Data encoded in EPICS does not need special conversion software nor special searching software.
Unicode uses combining characters. This is partly because the code space size of Unicode is insufficient. If all combinations are defined, they do not fit the 16-bit code space. Therefore Unicode uses an incomplete repertoire of composite characters. EPICS can have an infinite code space size although a practical limit should be imposed. Every combination of combining characters can be assigned to a different code point in EPICS. When composite characters are used, locating boundaries of characters becomes simple. Moreover rendering of a composite character is more systematic than rendering of combined characters.
Documents usually consist of not only characters but also language tags and formatting tags. All of them should be internationalized. Standard General Markup Language (SGML) [4] and Hyper Text Markup Language (HTML) [1] are examples of use of tags or markups in fancy text. However, tags in HTML are based on English words. We do not think that internationalization of SGML and HTML is enough.
We can assign a symbol code value in EPICS to every tag which is composed of characters in markup languages because the code space of EPICS is huge. Internationalization of tags can be accomplished using EpicVM which maps the symbols to character strings in a user's native language. Tags in binary representation and a special transformation program could accomplish the same internationalization as EPICS. However, EPICS can accomplish internationalization of tags in the same framework as that of the characters. Since the code space of Unicode is not huge, it is difficult to treat a lot of tags in various markup languages and software as characters in Unicode. Therefore, string processing such as string matching needs special handling of tags, and thus it complicates a document processing system for internationalization. EPICS simplifies the processing system.
Unicode is important as a base for multilingual processing. However, the encoding of Unicode is static and inflexible. A character set based on ISO 2022 is specified by each nation's government. Therefore, separation between languages and characters is insufficient. Thus an identical character can have different code points in different code sets. ISO 2022 uses a small code space and switches code sets mapped to the space. This complicates state management of characters. ISO 2022 is unsuitable for the internal processing of characters. ISO 2022 was standardized when computer resources were limited. Designation and invocation are main controls. We do not need to restrict control capabilities of a character code system because computational power and memory capacity have been enhanced recently. We think a simple and smart virtual machine should be included in a character code system standard.
Arena i18n [9][10] uses fixed-length internal codes. The unit is 4 bytes. 4-byte fixed-length codes are easy to handle within a program. However, when a code is exported outside the program, that encoding is inefficient and code conversion is probably needed.
Internal codes of Mule (MULtilingual Enhancement to GNU Emacs) [11] are mainly based on ISO 2022. Thus separation between languages and characters is insufficient. The length of a code is variable and the unit is a byte. A character code in a character set is prefixed with information identifying the character set. This type of encoding does not allow one to apply existing matching algorithms for fixed-width encoding to data simply using a byte as a unit because the existing matching algorithms do not recognize boundaries of a variable-length character properly.
In this paper, we have presented a new symbol code system called EPICS. We think that EPICS promotes efficient internationalization and multilingualism of the WWW without imposing fixed character sets on people. Moreover, EPICS makes compressed data transfer possible without installing special decompression programs at clients. EPICS is derived from a unique combination of a variable-length coding system and a smart virtual machine, EpicVM.
In EPICS, a variable-length coding system makes it possible to include various characters needed for internationalization efficiently. The huge size of the code space of EPICS allows one to use and to exchange user-specific symbols with little possibility of overlapping code points even if coordination is not performed. EpicVM allows one to send not only static characters but also dynamic programs. This programmability enables one to send compressed data with a decompression program incrementally and efficiently. Compression reduces the amount of network traffic and storage overhead on WWW.